[Photogrammetry] 9-1. Introduction to Neural Networks - Part 1: The Basics
Photogrammetry (Cyrill Stachniss)
Neural Network
NN에 대한 기본지식을 간단히 정리하고 시작하기
머신러닝 기술 중 하난인
NN은 주로 다음 사진과 같이 image classification이나 semantic segmentation을 할 때 사용한다.
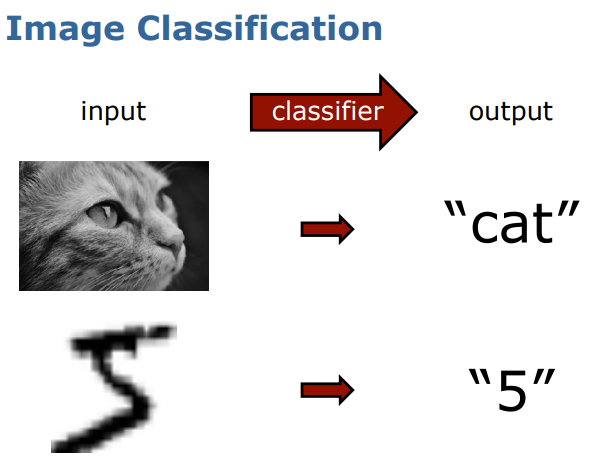

처음 아이디어는 1950-60년에 제안되었고, 2000년대부터 관심을 받기 시작했다. 딥러닝은 2010년부터 부상했고, image tasks를 위한 CNN은 2012년부터 시작되었다.
Part1 Neural Networks Basics
이 강의에서는 biological neuron과 artificial neuron에 대해 설명하고 있다.
Biological Neuron
뇌의 가장 기본 단위이고,
-
외부 세계나 다르뉴런으로부터 input을 받는다
-
signal을 변형하고 전달한다
-
signal을 다른 neuron에 전달하고 또한 근육에 운동명령을 한다
Artificial Neuron
이번에는 artificial neural network의 기본단위이고,
- input을 받고
- 정보를 변형하고
- output을 만든다
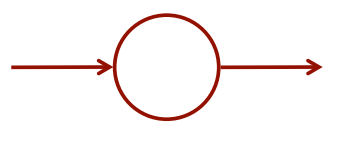
...
즉 두 neuron은 서로 다르기는 하지만 동일한 특징을 갖고 있는 것이다.
이를 정리하여 뉴런의 정의에 대해 다시 얘기할 수 있을 것이다.
Neuron
뉴런이란,
(STEP1) sensor나 다른 neuron으로부터 inputs/activations를 받고
(STEP2) 정보를 combine/transform 한 다음에
(STEP3) output/activation을 만들어 내는 것이다.
Neurons as Functions
뉴런을 함수로 이해하면 다음과 같이 표현할 수 있다.
Neural Network
다음은 뉴럴 네트워크 구조에 대해 설명한다.
뉴럴 네트워크는 많은 뉴런들이 연결된 것이고, node는 각각의 뉴런를 부르는 말
맨 왼쪽은 input 맨 오른쪽은 output을 의미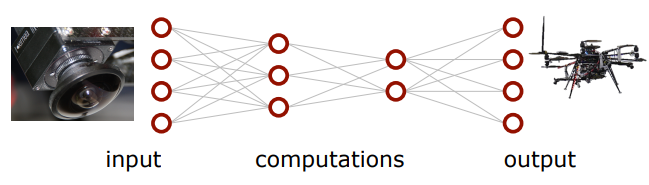
Neural Network as Functions
NN을 함수로 이해하면 다음과 같다.
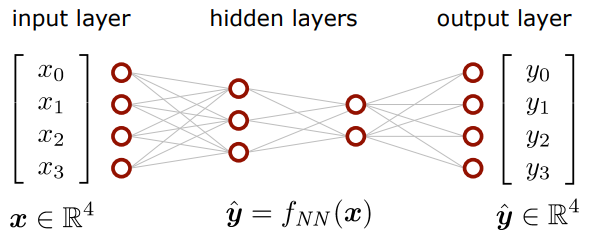 input의 차원이랑 output의 차원은 아예 관련이 없다. (이것은 하나의 예시일뿐)
input의 차원이랑 output의 차원은 아예 관련이 없다. (이것은 하나의 예시일뿐)
이때 우리는 hidden layer에 있는 f의 종류에 따라 수많은 NN을 정의할 수 있는데 ..!
Different Types of NNs
 우리는 이러한 수많은 NN 중에서 MLP에만 집중할 것이다.
우리는 이러한 수많은 NN 중에서 MLP에만 집중할 것이다.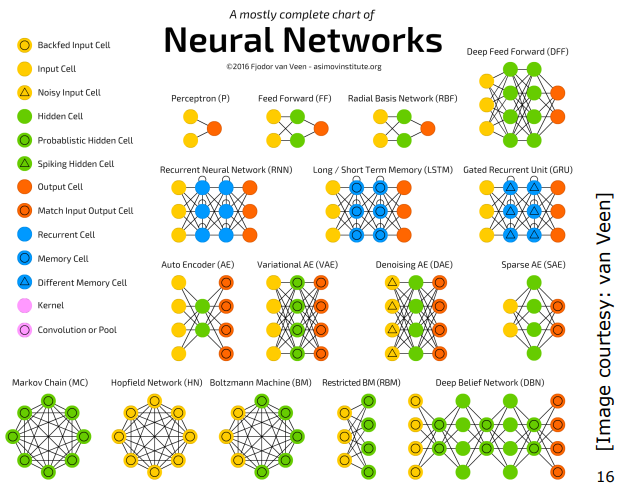
MLP(Multi-layer Perception)
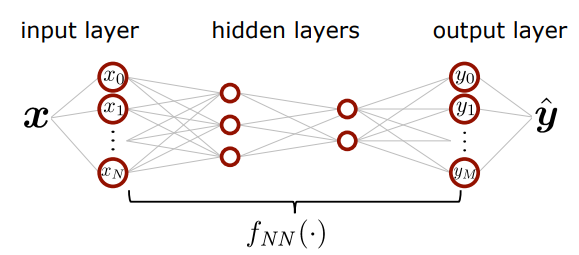
Image Classification Example
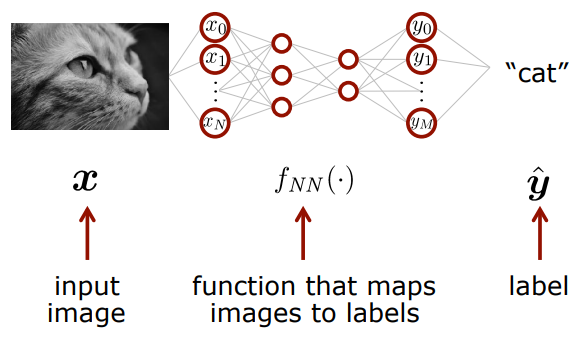 계속 어렵지 않은 설명을 하고 계신다. 고양이 사진을 넣어서 cat이라는 결과값을 갖기 위해서는 input에 고양이 사진에 대한 정보를 넣으면 NN의 결과값이 cat이 되는 것이다.
계속 어렵지 않은 설명을 하고 계신다. 고양이 사진을 넣어서 cat이라는 결과값을 갖기 위해서는 input에 고양이 사진에 대한 정보를 넣으면 NN의 결과값이 cat이 되는 것이다.
.
.
.
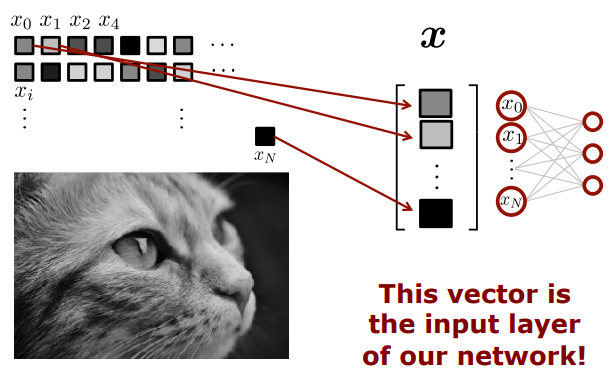
What's the Network's Input?
그렇다면 여기서 살짝 의문이 생기지! 고양이 사진을 어떻게 input값으로 넣을 수 있을 것인지!
STEP1. 사진은 픽셀로 이루어져있기 때문에 각 픽셀의 밝기값을 구한다. 우리는 총 (N+1)개의 밝기값(intensity value)을 갖게 되는 것이다

STEP2. (N+1)개의 밝기값을 크기가 (N+1)인 하나의 벡터로 표현한다. 그러면 이 벡터가 바로input layer가 되는 것이다.
What's the Network's Output?
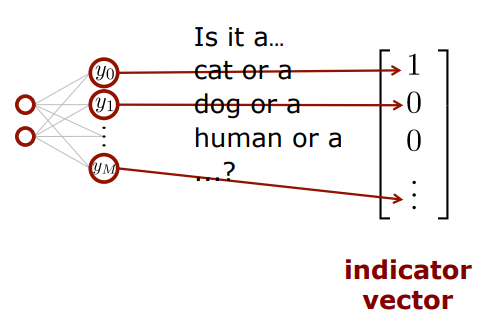 이 경우는 고양이 사진이니까 첫번째 label 값이 1이고 나머지는 0인 것이겠지
이 경우는 고양이 사진이니까 첫번째 label 값이 1이고 나머지는 0인 것이겠지 실제세계에서는 오직 하나의 label값에 대해 확신하는게 쉽지 않기 때문에 가능성으로 표기하기도 한다.
실제세계에서는 오직 하나의 label값에 대해 확신하는게 쉽지 않기 때문에 가능성으로 표기하기도 한다.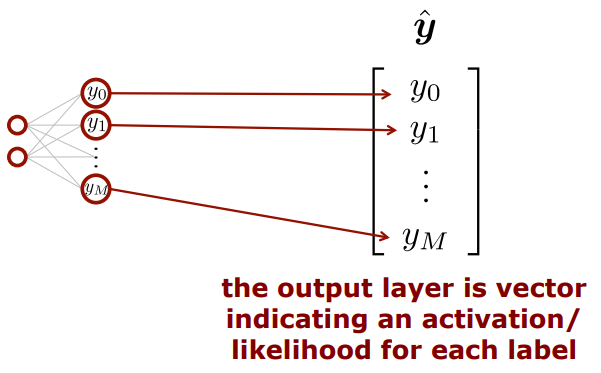 정리하면
정리하면 output layer은 다laybel을 보여주는 벡터라고 생각할 수 있다.
Image classification
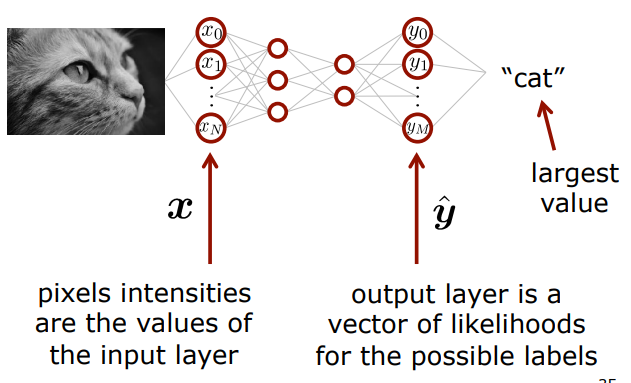 즉, image classification의
즉, image classification의
input에 픽셀의 밝기값을 일렬로 벡터로 표현한 것이고,
output은 각각의 항목의 label 값으로 표현한 것이다.
앞과 뒤, 즉 input과 output을 보았으니 이제 hidden layer을 뜯어보러 가자:D
MLP, Let's Look at a Single Neuron
MLP에서 하나의 노드(neuron)만 한번 알아가보자.
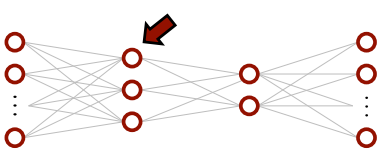
Perceptron(Single Neuron)
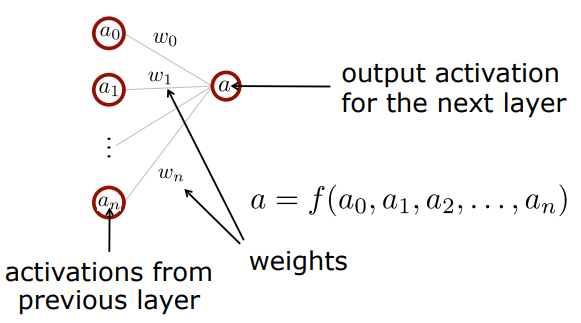 여기서
여기서 weight의 크기는 이전 layer의 activation이 다음 layer의 activation에 얼마나 영향을 주는지를 나타낸다. 따라서 그 값이 크다면 영향을 많이 주는 것이고 작다면 적게 주는 것이다.
Function Behind a Neuron

activation function의 역할
: 활성화 함수가 필요한 이유는
모델의 복잡도를 올리기 위함인데, 출력값이 비선형(nonlinear)적으로 나오므로 선형분류기를 비선형분류기로 만들 수 있다.
신경망에서는 activation function으로 비선형함수만을 사용하는데 그 이유는 선형함수를 사용하면 신경망의 층을 깊게 쌓는 것에 의미가 없어지기 때문이다. 즉, hidden layer가 없는 네트워크로도 똑같은 기능을 할 수 있다는 뜻이다.
ex)
식으로 나타내면 다음과 같다.

자 이제 본격적으로 activation function에 대해 알아보자.
Step Activation Function
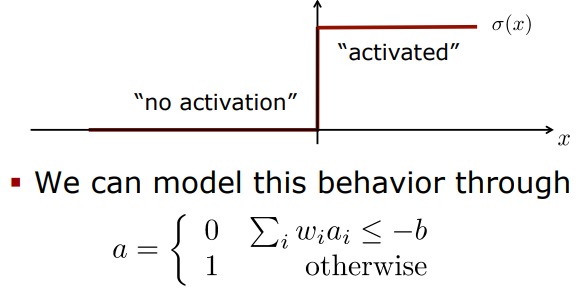 하지만 다음과 같은 non-smooth function은 가중치를 학습시킬 때 미분을 사용하는데 이는 gradient를 구할 수 없다는 치명적인 단점이 있다.또한 0과 1과 같은 극단적인 값을 전달하기 때문에 데이터의 정보 또한 손실시켰다.
하지만 다음과 같은 non-smooth function은 가중치를 학습시킬 때 미분을 사용하는데 이는 gradient를 구할 수 없다는 치명적인 단점이 있다.또한 0과 1과 같은 극단적인 값을 전달하기 때문에 데이터의 정보 또한 손실시켰다.
Sigmoid Activation Function
많이 쓰이는 활성화함수(smooth) = logistic function
함숫값을 0-1사이로 나오도록 설정한다. 입력이 중요하면 큰 값을, 중요하지 않으면 작은 값을 출력하는 것이다. 이처럼 sigmoid를 사용하면 step보다 데이터의 정보를 보존할 수 있다.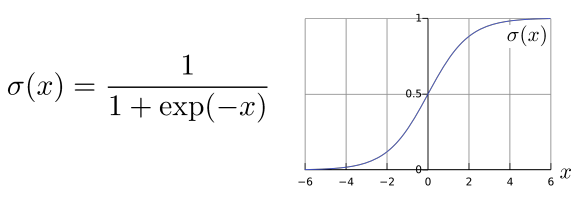
하지만 sigmoid도 단점이 있어서 최근에는 잘 사용하지 않는데 바로 'gradient vanishing'(기울기소실) 문제이다.
layer가 깊어지면 깊어질수록 오차역전파 수행시에 gradient가 소실되는 문제가 발생한다.
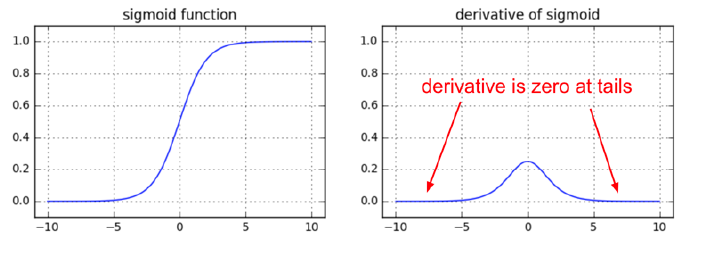 sigmoid의 기울기는 양끝으로 갈수록 0에 수렴하게 되므로, 나중에는 가중치가 갱신되지 않거나 학습이 중단되는 현상이 발생한다.
sigmoid의 기울기는 양끝으로 갈수록 0에 수렴하게 되므로, 나중에는 가중치가 갱신되지 않거나 학습이 중단되는 현상이 발생한다.
ReLU Activation Function
가장 많이 쓰이는 활성화함수 ReLU(Rectified linear unit)
sigmoid나 tanh보다 손실함수의 수렴속도가 6배 정도 빠르다.
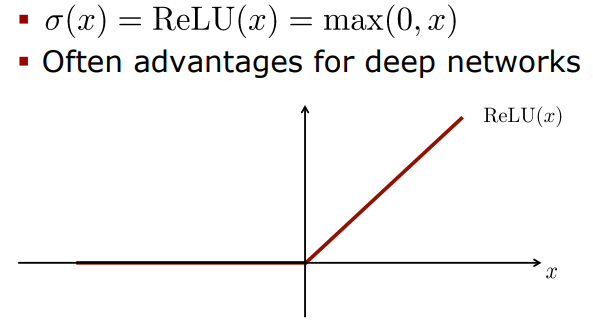
Common Activation Functions
 정말 많은 activation function이 있지만 ReLU를 가장 많이 이용 :D
정말 많은 activation function이 있지만 ReLU를 가장 많이 이용 :D
For All Neurons..
Let's use a Matrix Notation
지금까지 우리는 하나의 neuron에 대해서 잘라서 생각했는데 실제로는 수많은 노드가 존재한다. 따라서 우리는 이를 행렬로 표현하는데
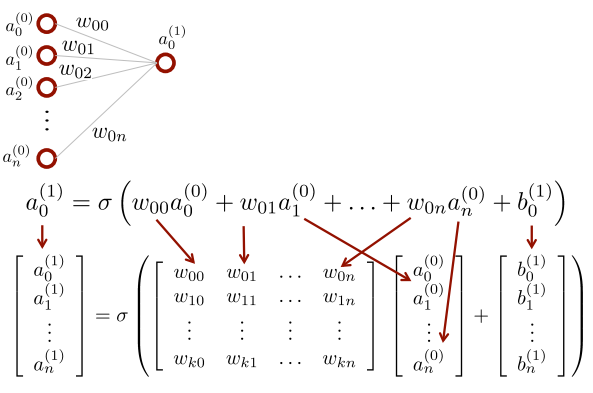 일단 한층에 대해서만 나타낸다면... layer1은 layer0에 의해서 만들어지는 것
일단 한층에 대해서만 나타낸다면... layer1은 layer0에 의해서 만들어지는 것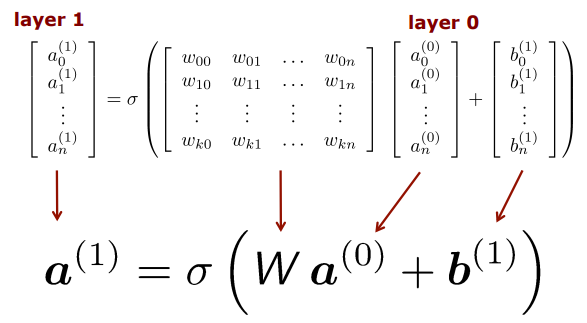
그리고 이를 더 많은 layer에 대해 반복한다면 ...
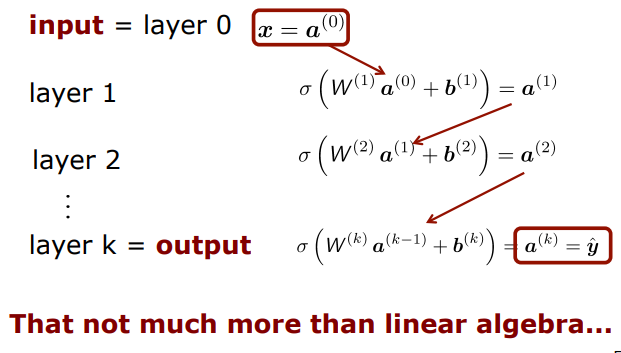
Feedforward Networks
MLP는 순전파(feedforward network)
정보가 왼->오 방향으로 간다는 뜻이다
Example: Handwritten Digit Recognition
(INPUT) Images to Digits
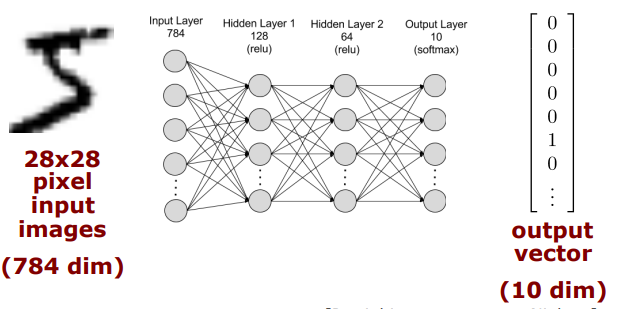
(1st Layer)
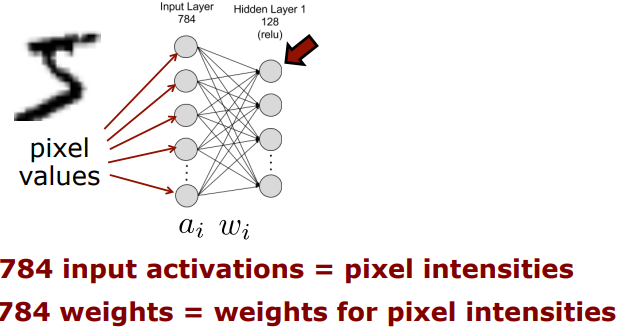 그림에서 표시한 저 뉴런의 기준으로 본다면
그림에서 표시한 저 뉴런의 기준으로 본다면
=> 784개의 input activation, 그리고 784개의 weight
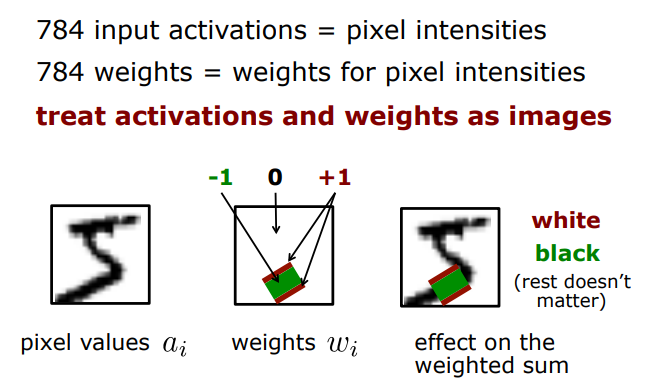 weight에서 red 부분은 하얀색과 대응되었을 때 좋고, green은 검은색과 대응되었을 때 좋고, 나머지는 상관이 없다(weight=0이므로)는 것을 의미한다. 그 이유는 intensity value를 생각해보면 하얀색은 225이고 검은색은 0이기 때문에 +1(red)은 하얀색과, -1(green)은 검은색과 대응되어야 한다.
weight에서 red 부분은 하얀색과 대응되었을 때 좋고, green은 검은색과 대응되었을 때 좋고, 나머지는 상관이 없다(weight=0이므로)는 것을 의미한다. 그 이유는 intensity value를 생각해보면 하얀색은 225이고 검은색은 0이기 때문에 +1(red)은 하얀색과, -1(green)은 검은색과 대응되어야 한다.
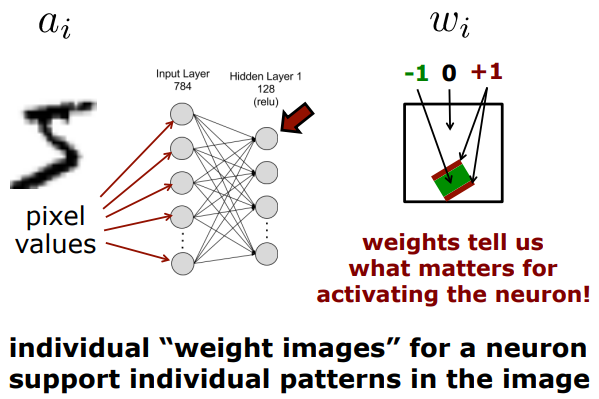 pixel과 weight를 convolution연산을 하여 얻어진 결과의 값이 높으면 유사도가 높은 것이기 때문에 그 픽셀값이 얼마나 중요한지 알려줌. 패턴을 발견했을 때 그 값이 높은 것.
pixel과 weight를 convolution연산을 하여 얻어진 결과의 값이 높으면 유사도가 높은 것이기 때문에 그 픽셀값이 얼마나 중요한지 알려줌. 패턴을 발견했을 때 그 값이 높은 것.
weight는 pattern의 모양을 알려주고,
bias는 얼마나 그 pattern이 중요한지 알려준다.
Weights & Bias = Patterns
 활성화함수는 image가 pattern과 일치했을 때 => 뉴런을 switch on 한다.
활성화함수는 image가 pattern과 일치했을 때 => 뉴런을 switch on 한다.
(2nd Layer)
- 2nd layer의 weights들은 어떤 1st layer pattern이 combined 해야 하는지 얘기해준다.
- layer가 더 깊어지면 깊어질수록 더 많은 pattern이 배열되고 합해진다.
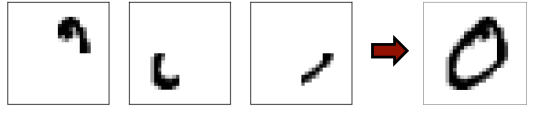
- 마지막 layer은 숫자를 구성하는 최종 패턴을 결정
No Manual Features
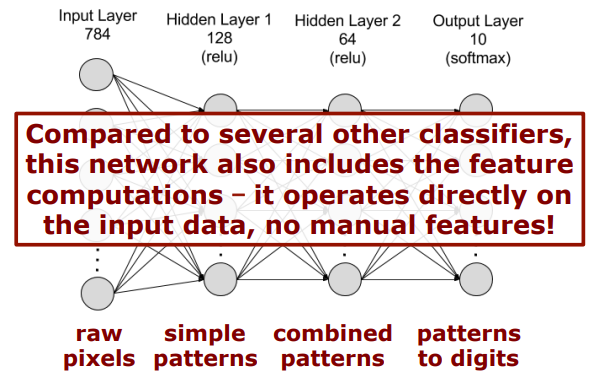 다른 classifier과 비교해봤을 때, 이 network는 feature을 계산하는 과정까지 포함하고 있다. manual features가 있는 것이 아니라 input data에 따라 그에 맞는 features도 달라진다는 것이지!
다른 classifier과 비교해봤을 때, 이 network는 feature을 계산하는 과정까지 포함하고 있다. manual features가 있는 것이 아니라 input data에 따라 그에 맞는 features도 달라진다는 것이지!
(<->RF:데이터에 따라 feature가 달라지는 것이 아니라 절대적인 기준이 있었음, 예를 들어 불순도가 적은 쪽으로 나눠야 한다든지)
이것은 이점도 있고 단점도 있는데,
일단 이점은 user이 어떤 feature가 좋을지 아닐지 고민할 필요가 없다는 것이다. 모델을 학습하면서 알아서 중요한 feature가 선택이 되기 때문에.
다만, 단점은 나의 background knowledge를 이용할 수 없다는 것이다. 아무리 user가 feature을 알더라도 이 모델을 학습할 때 적용할 수 없으니까
그러나 장점이 더 많은 모델
그럼 또 생기는 질문
How to Design a Neural Network?
network를 디자인할 때 structure과 parameter는 선택 대상이 되는데 그들을 어떻게 설정할까? 바로 학습을 통해서이다!
이는 다음 강의에서 이어서 다룬다.
