[Photogrammetry] 9-2. Ensemble Classification - Bagging & Boosting
Photogrammetry (Cyrill Stachniss)
Reminder: Classification
- 개의 classes (), 그리고 features
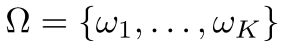
- 다음과 같은 식을 만족하는 function 를 찾는 것이 바로 classification이다.
즉, feature을 입력하면 class가 나오는 함수!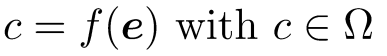
ex) 예를 들어 우리가 개와 고양이 분류기(binary classification)를 만든다고 해보자. 그렇다면 feature 는 동물의 눈색깔, 꼬리의 모양 등이 되겠고, 그 feature를 함수 에 넣으면 개인지 고양이인지 결과가 나오는 것이다!
Ensemble Methods
Ensemble method의 가장 큰 핵심은
multiple classifiers를 이용하고 더 강력한 classifier을 만들기 위해 이들을combine한다는 것이다!
흔히 우리는 앙상블을 집단 지성이라고 하기도 한다.
하나의 모델보다는 여러 모델들을 조합했을 때 더 좋은 결과가 나온다는 것이다.
앙상블의 방법은 대표적으로 2가지가 있다.
BaggingBoosting
예전에 앙상블에 대해 발표했던 내용을 사진으로 잠깐 복습하고 가겠다.


Bagging (Boostrap Aggregating)
Bagging이란
: subsampled training data가 각각 학습된 여러개의 classifier를 합치는 것
: multiple training set에 강조
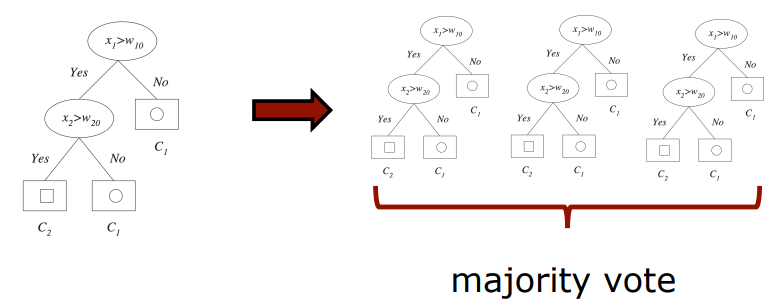
즉, (1) 하나의 데이터셋을 n개로 쪼개고 (2) n개의 모델이 학습을 하면, (3) 마지막에 합치는 것이다. (병렬적/독립적으로 학습)
ex) 10,000개의 데이터가 있다면 2,000개씩 5조로 나누어 5개의 모델이 병렬적으로 학습하는 것
수식으로 나타내면 다음과 같다.
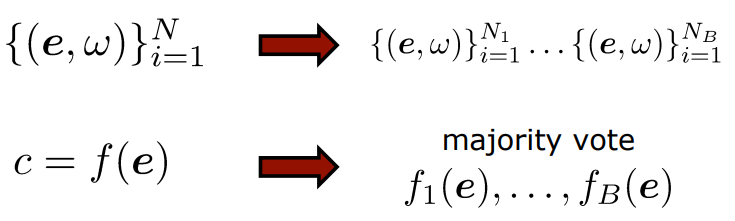 여기서 majority vote의 의미는,
여기서 majority vote의 의미는,
예를 들어 개와 고양이 분류기를 만들 때
1번째 모델 - 개, 2번째 모델 - 고양이, 3번째 모델 - 고양이, 4번째 모델 - 고양이, 5번째 모델 - 개
라고 분류했을 때, 다수결의 원칙에 따라 '고양이'라고 판별하는 것이다.
일반적으로 performance는 각각의 하나의 모델을 사용했을 때보다 여러개를 합쳤을 때 훨씬 좋다는 것을 확인할 수 있었다.
Boosting
Boosting이란
: 새로운 모델이 이전 모델이 잘못 분류한 training data에 중점을 두고 학습한다.
: multiple classifier에 강조
즉, (1) 첫번째 모델은 일단 모든 dataset을 그대로 학습하고, (2) 두번째 모델은 전체 데이터를 학습하되 첫번째 모델이 에러를 일으킨 데이터에 더 중점을 두고 학습한다. (3) 세번째 모델은 앞의 두 모델이 힘을 합쳐도 맞추지 못한 데이터에 중점을 두고 학습하는 것이다. (직렬적/순차적 학습)
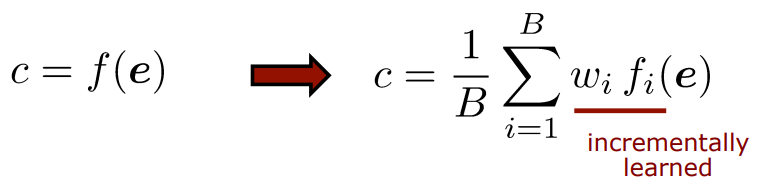
Random Forests
(Bagging with Decision Tree)
Random Forests = Bagging with Decision Trees
- 다양한 multiple decision tree를 하나의 forest로 합친다.
Previous Lecture: Decision Trees for Classification
이전 시간에 배웠던 decision tree 잠깐 복습하는 시간
Decision Tree
: 분류(Classification)와 회귀(Regression) 모두 가능한 지도 학습 모델 중 하나이다.
:split node는 feature 공간에서 나누는 역할을 하고,leaf node는 classification 결과를 알려준다.
:불순도를 최소화(혹은 순도를 최대화)하는 방향으로 학습
: tree는 training data에 기반한분할 정복(divide-and-conquer) 알고리즘
[용어정리]
-
split node와leaf node란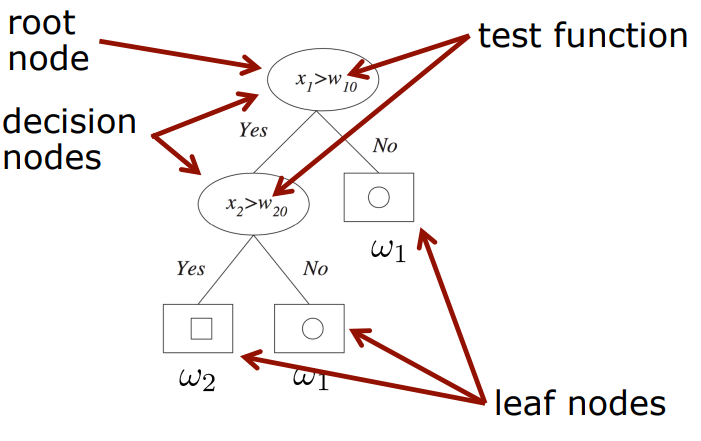
-
불순도(impurity)란
해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지를 뜻한다.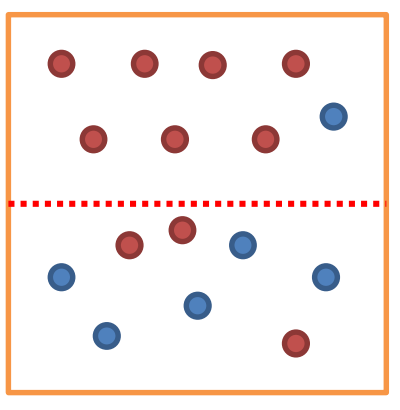 다음 그림에서 위쪽 범주는 불순도 낮고, 아래쪽 범주는 불순도가 높다.
다음 그림에서 위쪽 범주는 불순도 낮고, 아래쪽 범주는 불순도가 높다. -
엔트로피는 불순도(Impurity)를 수치적으로 나타낸 척도이다. (엔트로피가 높다는 것은 불순도가 높다는 뜻이고, 엔트로피가 낮다는 것은 불순도가 낮다는 뜻) -
분할 정복 알고리즘이란?
: 그대로 해결할 수 없는 문제를 작은 문제로 분할하여 문제를 해결하는 방법
[decision tree의 예시]
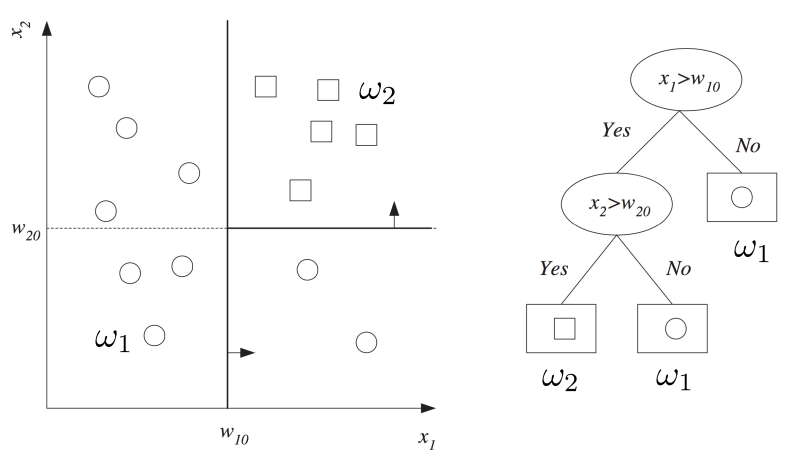 과 를 구별하는 decision tree는 다음과 같이 만들 수 있지.
과 를 구별하는 decision tree는 다음과 같이 만들 수 있지.
decision tree에 대한 내용을 복습을 했으니 이제 decision tree 여러개를 합친 random forest를 공부해보자!
Random Forest Learning (Bagging)
(STEP1)training data를 랜덤하게 쪼갠다. (Booststrapping단계)
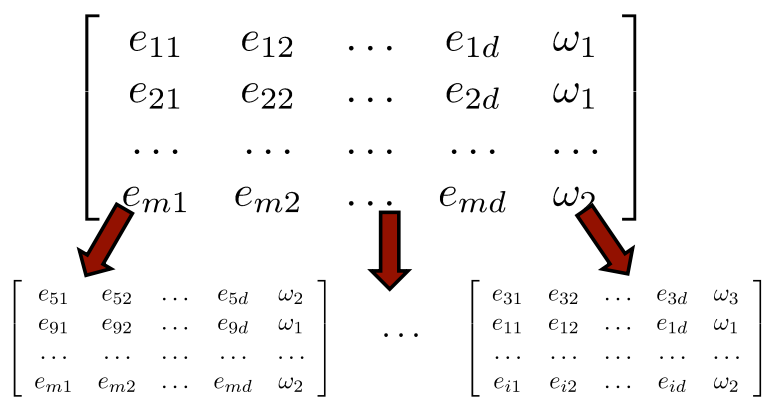 전체 행렬에서, 하나의 행이 하나의 image에 대한 feature와 class를 말해준다. 따라서 m개의 image가 있는 것이고, 몇개의 image들만 골라 subset를 만드는 것이다.
전체 행렬에서, 하나의 행이 하나의 image에 대한 feature와 class를 말해준다. 따라서 m개의 image가 있는 것이고, 몇개의 image들만 골라 subset를 만드는 것이다.
(STEP2)training data subset에서 랜덤하게 feature 차원을 수정한다.
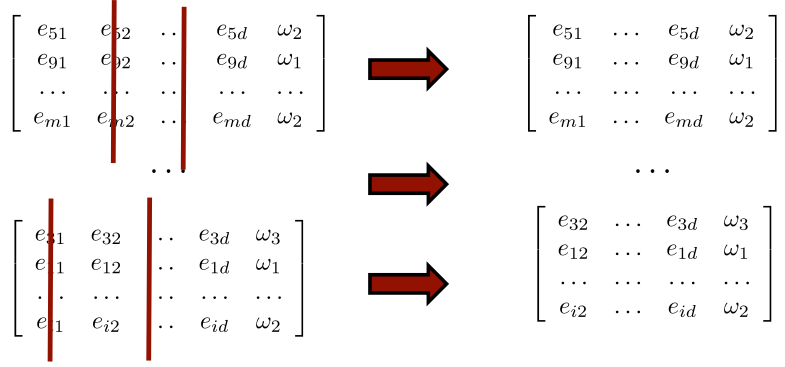 즉 몇개의 features를 버리는 일인데, 이것을 하는 이유는 서로 다른 decision tree(모델)을 만들기 위하여 하는 일이다.
즉 몇개의 features를 버리는 일인데, 이것을 하는 이유는 서로 다른 decision tree(모델)을 만들기 위하여 하는 일이다.
예를 들어 a,b,c,d 노드를 가진 decision tree가 있을 때, 첫번째 모델에서는 a,c만 사용하고 두번째 모델에서는 b,c만 사용한다면 이 모델은 학습한 것이 다르므로, 서로 다른 모델이라고 할 수 있다.
이 예를 또 다시 개와 고양이 분류 모델에 적용해보자면,
첫번째 모델은 눈의 색깔을 분류해주는 모델
두번째 모델은 꼬리의 유무를 분류해주는 모델
...
이런 모델 여러개로 만드는 것이다.
또한 어떤 feature가 classification하는데 중요한 역할을 하는지 알 수 있겠지.
(STEP3)training data로 만들어진 각각의 subset에 대하여 standard decision tree를 학습한다.
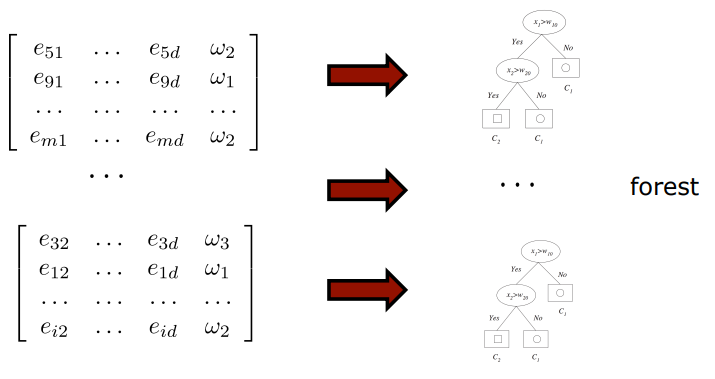
(STEP4)학습이 끝난 후에 모든 tree(모델)에 대하여 test sample에 대한 결과를 합친다.
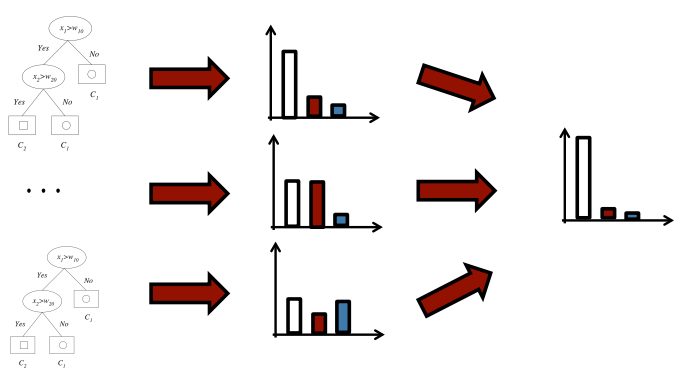
Properties of Random Forest
- overfitting을 줄일 수 있다.
: 하나의 모델이 모든 training dataset을 다 보는 것이 아니므로
: 하나의 모델이 overfitting되었다 해도 다른 모델은 아닐 수도 있고 이런 것들이 합쳐지면 overfitting 가능성이 낮아짐- 상대적으로 정확한 classification 결과를 얻을 수 있다.
- parallelize 하기가 쉽다. => fast
: 각각의 모델 학습은 병렬적으로 이루어지기 때문에
 다음 예시는 body part classfication (Kinect)인데
다음 예시는 body part classfication (Kinect)인데
1 million의 test image를 1000개의 core cluster을 이용하면 하루밖에 걸리지 않는다는 것을 알 수 있다 XD 매우 빠르다.
현재 classification을 할 때 종종 사용되고 있다고 한다.
AdaBoost
Boosting with AdaBoost
inaccurate classifier을 합쳐서 accurate strong classifier 만드는 것
어렵지 않은 이야기이지. 그저그런 성능을 내던 모델 여러개를 합치면 더 강력한 classifier을 만들 수 있다고 계속 예기했으니까!
여기서
inaccurate rule이란 : 'weak' classifier
accurate rule이란 : 'strong' classifier
AdaBoost
- 이런 문제를 해결하는 가장 유명한 알고리즘
- 'weak' classifier 가 여러개로 합쳐진 앙상블이 주어지면,
weighted majority voting scheme을 이용하여 'strong' classifier인 이 얻어진다.
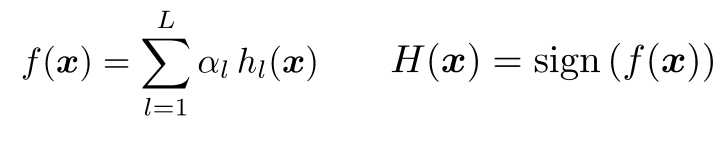 여기서 sign이라는건 +또는 -를 의미한다.
여기서 sign이라는건 +또는 -를 의미한다.
Why is AdaBoost Interesting?
- 'best features' 알려준다.
- 'best threshold' 알려준다.
AdaBoost는
feature selection방법이라고 할 수도 있다.
- AdaBoost는 non-linear classifier이다
- Generalizes well : majin을 최대화 함
(각 샘플에서의 분류기까지의 거리 중 최솟값을 majin이라고 함, 마진이 크도록 분류기를 만들면 안전지대가 넓어져서 더 좋음 :D)
(예를 들어 +,-를 분류하는 경계를 만들 때 둘 사이에 분류기가 최대한 멀게 위치하도록 만든다는 뜻) - implement하기 쉽다.
Prerequisite
- 'weak' classifier은 아무리 weak라도 랜덤으로 추리한 것보다는 당연히 더 나은 성능을 가져야 한다.
- binary classification 문제에서는 error<0.5이어야 한다.
Possible Weak Classifiers
Decision stump
: 노드가 여러개 있는 것이 아니라 하나만 있는거
: decision tree의 하위버전
decision tree
: 여러개의 노드가 있는 것
SVM(Support Vector Machine)
: best separating hyperplane을 찾는 알고리즘
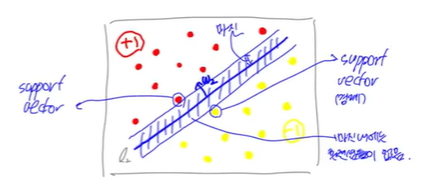
...
Decision Stump
- decision tree의 소형 버전(하나의 node와 두개의 leaf를 가지는 모양을 의미)
- hyperplane(초평면)에 의해 정의된 linear classifier과 똑같다.
- plane(평면)은 j-th 축에 직교한다. (threshold 와 교차함)
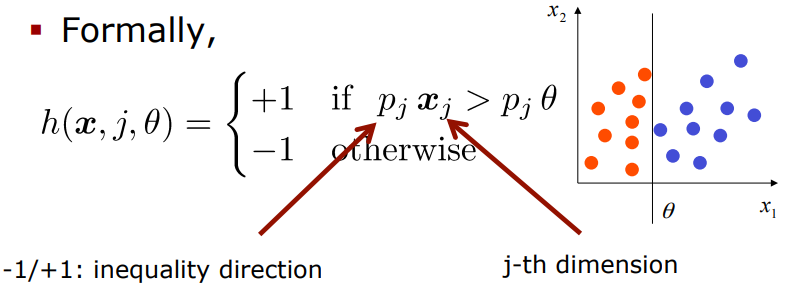
- weighted data에 대해 decision stump를 train한다.
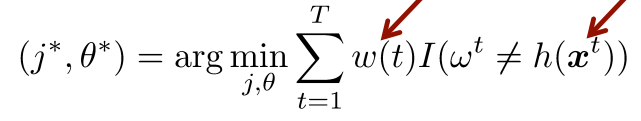
- 각각의 dimension j = 1,...d에 대해서 최적의 파라미터 를 찾고, 그리고 weighted error가 최소가 되는 를 선택한다.
(위의 그림에서는 과 가 있었겠지만, 최소가 되는 아이는 바로 이었던 것이지)
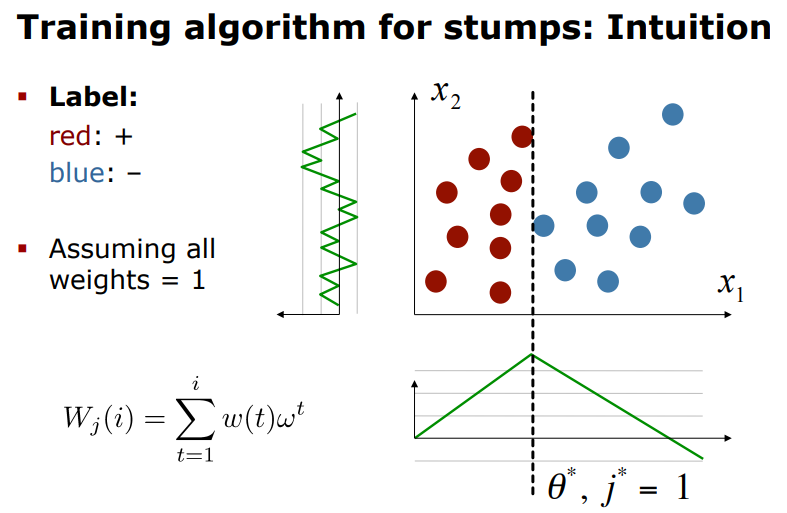
Decision Stump Training Algo.

AdaBoost Algorithm
 무슨 수식인지 전혀 이해가 안돼서 영상 찾아봤는데 도움을 많이 받았다. 시간 나면 정리하겠다.
무슨 수식인지 전혀 이해가 안돼서 영상 찾아봤는데 도움을 많이 받았다. 시간 나면 정리하겠다.
https://www.youtube.com/watch?v=LsK-xG1cLYA
~43분
