(추가자료)
https://www.youtube.com/watch?v=-C6d83rXm1I
https://github.com/mlvlab/SPoTr
1. Introduction
Point Cloud: 자율주행, 로봇공학, 증강현실 분야에 쓰임
지금까지 진행된 연구에는 무엇이 있을까?
Point Cloud 특징
불규칙한 구조(irregular structure)를 가진 순서 없는 점들의 집합(unordered set of points)이기 때문에 CNN에 적용하는건 매우 어려웠다.
#1
- point cloud를 규칙적 구조(regular structure)로 바꾸는 연구
- ex)- multi-view images에 투영
- voxelization (point cloud를 Voxel로 변환)
- 불규칙한 구조는 그대로 두는 대신, point space에 적용할 Convolution 연구
그러나 Convolution 기반의 방법들에서는
long-range dependency를 포착하는게 어려웠다.
#2
Transformer가 long-range dependency 문제를 해결해줬고 2D 이미지 처리까지 확장되었다.- 초기 연구들은 Convolution layer을 Self attention으로 대체했지만, 픽셀의 개수에 대한 self-attention의 2차 계산 비용(quadratic computational cost)을 구하는 것이 매우 복잡했다.
- 이런 문제를 해결하기 위해, (1) 인근 지역에서만 self-attention을 하는 연구 (2) 줄어든 query와 key 집합에서 self-attention을 근사화하는 연구가 진행되었다.
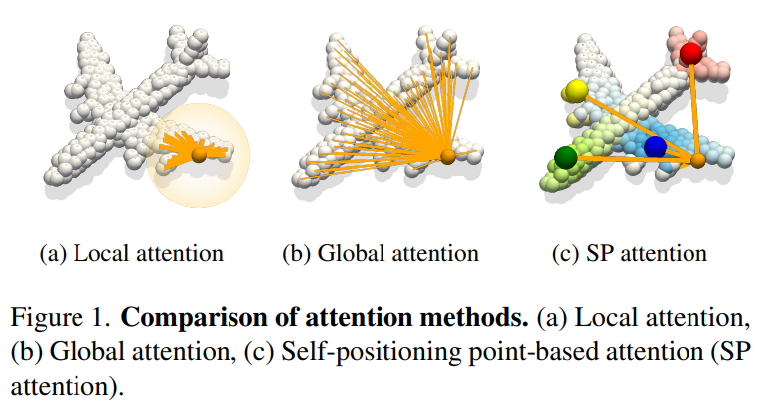
Point Clould에 대해서는
Local attentionGlobal attentionSP attention: 본 논문이 제안하는
- reduced complexity로 local 과 global shape contexts를 모두 포착하는 것- (1) local structure을 알기 위해
local points attention(LPA) - (2) global information을 알기 위해
self-positioning point-based attention(SPA)
- 이때, 전체를 다 하는게 아니라 small set of Self-Positioning points(SP points)로 global attention을 진행한다.
- (1) local structure을 알기 위해
SPoTr: Self-Positioning pointed-based Transformer
(사용한 Dataset)
- ScanObjectNN
- SN-Part
- S3DIS
(Contribution 정리)
- We design a novel Transformer architecture (SPoTr) to tackle the
long-range dependency issuesand thescalability issueof Transformer for point clouds - We propose a global cross-attention mechanism with flexible self-positioning points (SPA). SPA aggregates information on a few self-positioning points via disentangled attention and non-locally distributes information to semantically related points
- SPoTr achieves the best performance on three point cloud benchmark datasets (SONN, SN-Part, and S3DIS) against strong baselines.
- Our qualitative analyses show the effectiveness and interpretability of SPA.
3. Method
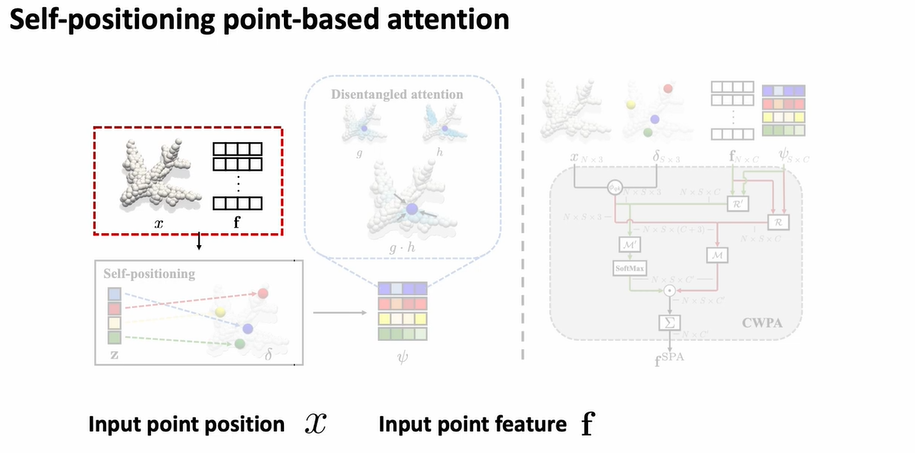
우선 input point position 와
input point feature 가 주어졌을 때
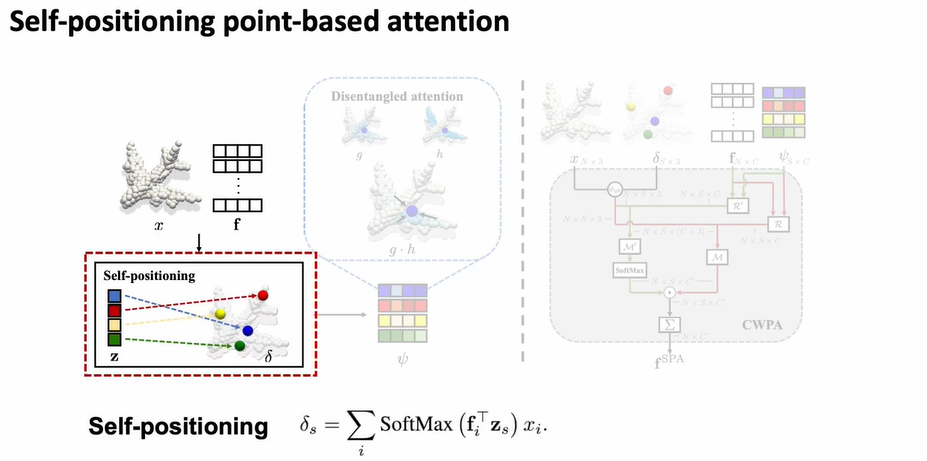
Self-positioning의 위치를 softmax함수를 이용해 계산한다.
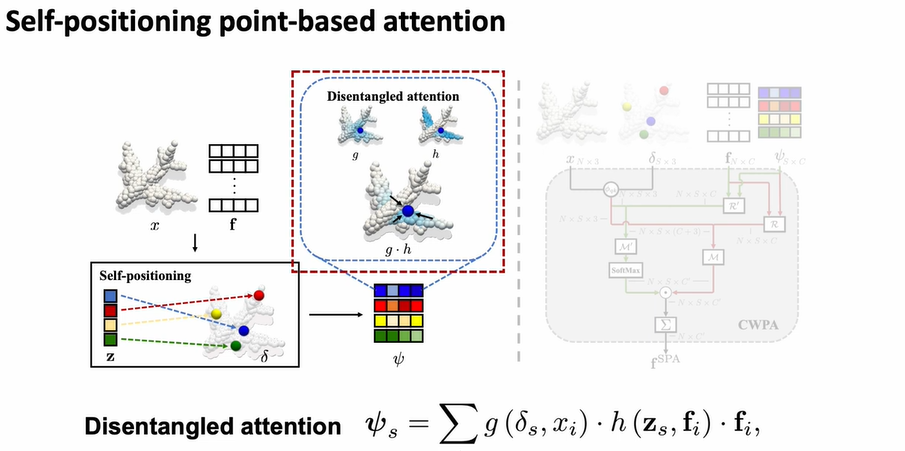
그리고 Self-positioning의 feature을 다음과 같은 식을 이용해 계산한다.
- 연산을 할 때 와 커널을 이용하는데
는 spatial proximity를 고려하고 는 semantic proximity를 고려함
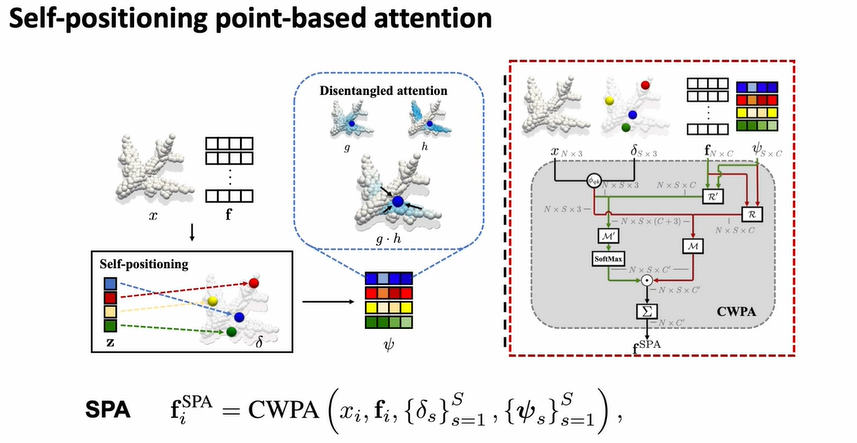
그 후, SP 포인터의 feature와 위치, 원래 가지고 있던 input의 feature와 위치로 SPA(Self-positioning point attention)을 구성하게 됨.
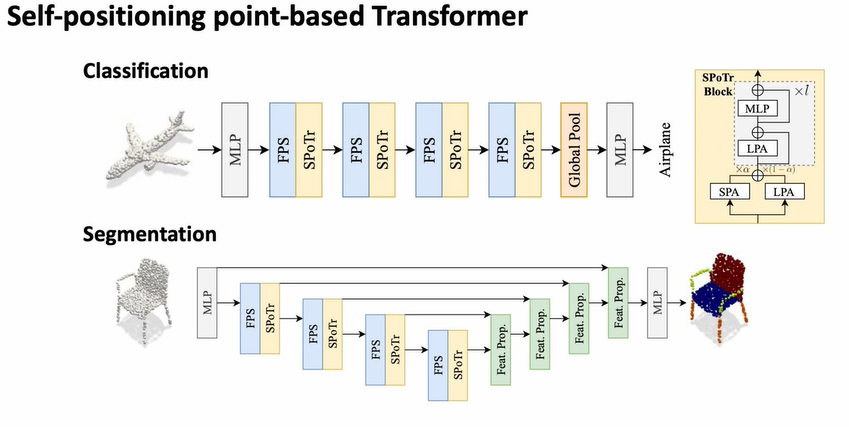
Classification과 Segmentation의 아키텍처는 다음과 같음

정리된 글은 https://dusruddl2.tistory.com/로 이동