https://codingopera.tistory.com/43
출처) 놀랍도록 설명을 너무 잘해주신 블로그
Transformer 란?
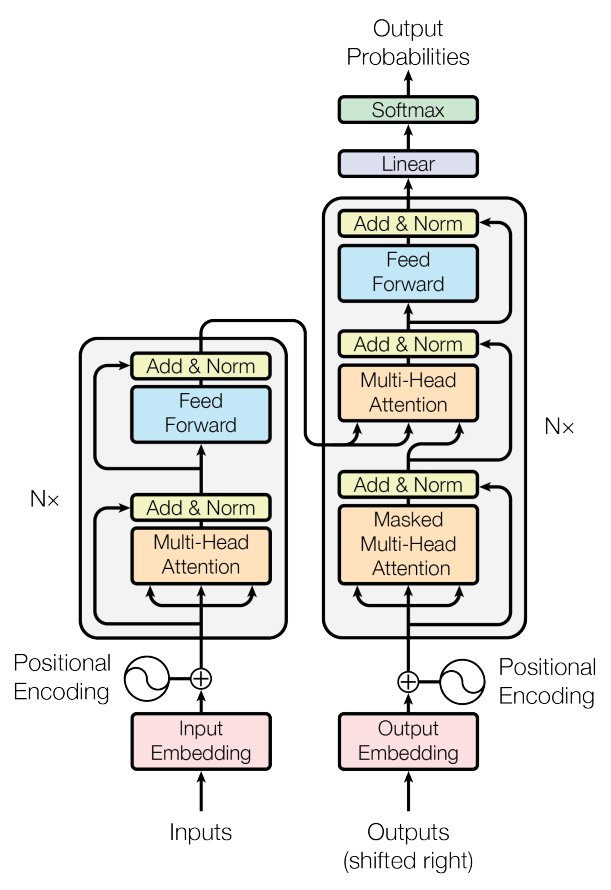
Transformer 모델은 RNN없이 Attention만으로 이루어진 encoder-decoder 구조의 seqence to seqence 모델
기존의 RNN모델의 가장 큰 단점은 네트워크를 계속 반복(순환) 업데이트하면서 연산 효율 떨어진다는 것이었습니다. 그러나 Transformer 모델을 사용하면 RNN을 사용하지 않아 연산 효율도 좋아지고, 뿐만 아니라 성능도 더욱 좋아집니다. 때문에 현재 지구상에서 가장 강력한 모델입니다.
1. Self Attention
Self Attention: 말 그대로 Attention을 자기 자신한테 취한다는 것입니다.
why? 문장에서의 단어들의 연관성을 알기 위해서
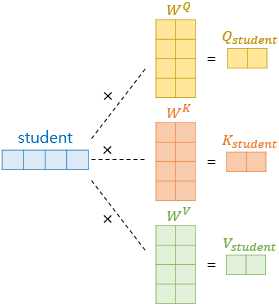
Self Attention에서는
Query(의문),Key(열쇠),Value(값)라는 3가지 변수가 존재합니다.
Self Attention의 에서 가장 중요한 개념은 Query, Key, Value의 시작 값이 동일하다는 점입니다. 때문에 Self를 붙이는 겁니다.
"Query, Key, Value의 기원은 같으나 최종 값은 학습을 통해 달라진다."라고 이해하시면 되겠습니다.
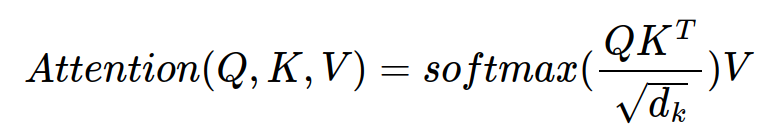
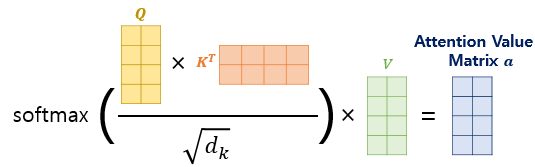 Attention 구하는 공식
Attention 구하는 공식

정리된 글은 https://dusruddl2.tistory.com/로 이동