강의 내용 복습
(01강) 딥러닝 기본 용어 설명 - Historical Review
basic
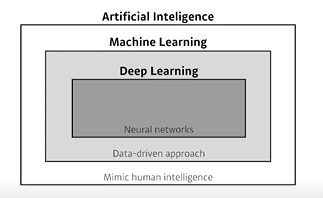
Artificial Inteligence = 인간의 지능 모방
Machine Learning = 무언가를 학습하고자 할 때 데이터를 통해 알고리즘은 만드는 것
Deep Learning = 모델이 neural network
-
딥러닝의 핵심요소
- 모델에 학습시킬 데이터
- 데이터를 변환할 모델
- 모델의 질을 향상시킬 손실함수
- loss를 최적화하는 방향으로 파라미터를 조절하는 알고리즘
논문을 볼 때 이 4가지 요소를 보면 어떤 contribution이 있는지 이해하기 쉽다.
-
Data
데이터는 해결하려고 하는 문제의 종류에 따라 다르다.

-
Model
데이터가 주어졌을 때 내가 알고자하는 형태로 바꾸어주는 것. 같은 데이터가 주어져도 모델에 따라 결과가 다르다.
-
Loss
해결하고자 하는 문제의 형태에 따라 모델의 파라미터를 업데이트 하기 위한 기준으로 loss function 정의한다. 이는 우리가 원하는 방향의 근사치일 뿐, loss 의감소가 문제의 해결을 말하지는 않는다.
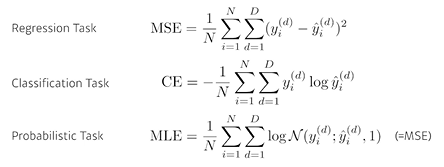
-
Optimization Algorithm
데이터, 모델, 손실함수가 정해져있을 때 loss를 어떻게 줄일지에 대한 방법. 모델이 학습하지 않은, 또는 실제 환경에서 잘 작동하도록 하기 위한 알고리즘과 함께 사용한다.
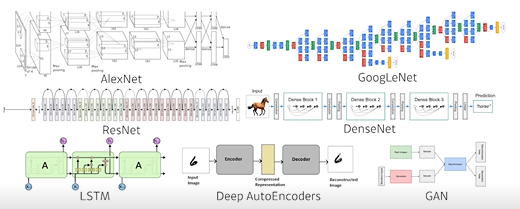
Historical Review
-
2012 AlexNet
224 X 224 이미지 분류를 위한 모델. Image Net 에서 2012년 DL을 이용하여 처음으로 우승을 한 이후 DL을 제외한 방법으로 대회에서 우승한 적이 없다. -
2013 DQN
알파고를 만든 알고리즘 - 강화학습을 이용하여 DeepMind에서 발표한 게임을 푸는 방법론을 말한다. -
2014 Encoder/Decoder
nlp 문제를 처리하기 위한 방법론. 다른 언어로 되어있는 문장이 주어졌을 때 또 다른 언어로 번역해준다.
단어의 시퀀스가 주어졌을 때 어떤 언어의 벡터로 인코딩하고 그 벡터를 목적 언어로 디코딩하여 기계번역한다. (machine translation) -
2014 Adam Optimizer
학습하고자 하는 모델이 있을 때 optimizer는 여러가지가 있지만 Adam을 적용하면 대부분 결과가 제일 잘 나온다.
논문에서 SGD를 쓸 경우 학습과정에서 learning rate을 점차 줄이는 것을 볼 수 있는데, 왜 그렇게 하는지에 대한 설명은 없다. 하지만 이유는 그렇게 하지 않으면 성능이 그만큼 안나오기 때문.
특히 컴퓨터 리소스가 부족한 상황에서도 Adam은 왠만하면 잘 된다는 실험결과를 보여준다. -
2015 Generative Adversarial Network
이미지, 문장을 만들어내는 모델.
Generator 와 Discriminator를 이용하여 모델을 학습하고 데이터를 생성한다. -
2015 Residual Networks
왜 딥러닝이냐 에 대한 답을 주는 논문.
네트워크를 너무 깊게 쌓으면 test시 모델 성능이 잘 나오지 않는 문제가 있었다. Resnet 에서 네트워크를 더 깊게 쌓아도 성능이 잘 나오는 방법을 제시했다. -
2017 Transformer
Attention is all you need
attention, transformer 구조 -
2018 BERT (fine-tuned NLP models)
양방향 Transformer를 사용한 모델.
자연어 처리는 Language model을 사용하여 이전의 문장 다음에 어떤 문장이 나올지 예측한다.
도메인(뉴스, 스포츠, 영화리뷰)에 따라 다른 데이터를 사용해야 하는데, BERT는 위키피디아 와 같은 큰 말뭉치로 미리 학습을 시킨다음 목적에 맞는 작은 데이터로 fine tunning을 시켜 좋은 성능을 낸다. -
2019 BIG language models
OpenAI의 GPT3
fined tunned NLP model이며, 굉장히 많은 파라미터(1750억개)를 사용한다. -
2020 Self Supervised Learning
대표적인 논문 : SimCLR
한정된 학습데이터가 주어졌을 때 , 주어진 학습데이터 외에 라벨을 모르는 비지도학습데이터를 사용하여 학습에 같이 활용한다. visual representation : 컴퓨터가 사진을 더 잘 이해할 수 있는 vector로 바꾸는 방법으로, 학습 데이터 외의 다른 데이터를 사용한다.
(02강) 뉴럴 네트워크 - MLP (Multi-Layer Perceptron)
신경망(Neural Networks)
동물의 뇌에서 일어나는 생뭉학적 뉴럴 네트워크를 모방하여 컴퓨터 시스템으로 구현한 것에서 시작한다. 지금의 nn,DL은 굉장히 많이 발전하여 초기와는 많이 다르기 때문에, 왜 그렇게 동작하는 지에 초점을 맞추어 공부하자.
NN은 함수를 모방하는 function approximator
-
Linear Neural Networks
- Data :
- Model :
- Loss :
선형 라인에 대한 기울기(w)와 절편(b) 모델
x에서 로 가는 mapping을 찾는 것이 목적인데, 이를 선형으로 한정짓고 w,b를 찾는 것.loss는 mean squared loss function 모델의 출력값과 정답의 차이를 말한다.
back propagation을 사용하여 파라미터가 어느 방향으로 움직였을 때 loss가 작아지는지를 w,b에 대한 편미분을 이용하여 찾는다. 이후 각 파라미터를 업데이트하는데 이를 gradient descent라고 부른다.
linear하지 않은 , n차원에서 m차원으로 가는 모델을 찾고 싶다면 행렬을 사용한다.
행렬곱에 대한 해석은 두 벡터 공간에 대한 변환이다.
- nonlinear function
x라는 입력에서 y로 가는 표현력을 극대화하기 위해 단순히 선형결합을 n번 반복하는 것이 아니라 activation function을 이용해 nonlinear 변환을 하면서 네트워크를 깊게 쌓는다.- avtivation function
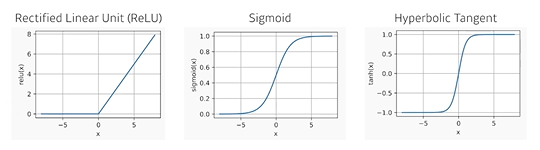
- avtivation function
Multi-Layer Perceptron
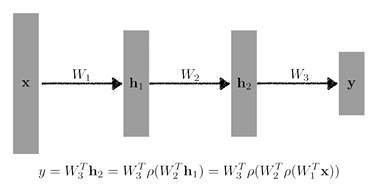
- loss function
- MSE for regression
데이터에 이상치가 크다면 loss 가 이상치에 민감하게 반응하여 제대로 문제를 풀 수 없음
- CE for Classification
분류 문제의 output은 one-hot vector로 표현되고, target의 dimension만 1이고 나머지는 0이다.
해당 차원에 대한 출력값을 다른 라벨의 차원에 비해 키우는 것이 목적이기 때문에 CE가 직동한다.
왜 분류문제에 CE를 쓰는지에 대한 글 - MLE for Probabilistic
결과에 대한 불확실성도 함께 제시하고자 할 때 사용
- MSE for regression
Pytorch
간단한 MLP 실습 진행
실습 과정에서 공부해볼만한 내용
- weight initialization
class MLP(nn.Module):
def _init_(self, ...):
...
def init_param(self):
nn.init.kaiming_normal_(self.lin_1.weight)
nn.init.zeros_(self.lin_1.bias)
...
... 위와 같이 layer의 parameter를 nn.init.~ 를 사용하여 초기화 해줄 때 가 있다.
이 코드가 무엇을 뜻하는지 알려면 먼저 가중치 초기화를 왜 하는지에 대해 알아야 한다.
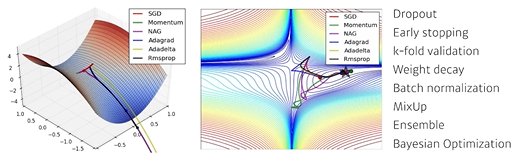
최적화(optimization) 에서 가중치의 초깃값에 따라 local minimum에 빠지느냐 global minimum을 찾느냐가 결정되기도 한다. 아무리 좋은 optimzer를 쓰더라도 가중치의 초깃값을 잘못 설정하면 global minimum에 수렴하기가 쉽지 않다.
딥러닝 모델은 거대한 feature space를 가지고 있기 때문에 올바른 초기값을 설정하는 것은 어렵다. 그래서 조금 다른 목적으로 사용된다.
- forward시에는 전달되는 값이 너무 너무 작아지거나 커지지 않도록
- backward시에는 gradient값이 너무 작아지거나(gradient vanishing) 너무 커지지 않도록(gradient exploding)
가중치의 값을 적절히 초기화를 해야한다.
코드를 보면, nn.init.kaimingnormal과 같이 uniform, normal 분포로 가중치를 초기화하는데, 그 이유는 symmetric breaking을 위해서이다. 이에 대한 간단한 설명을 보고 아래에서 코드로 확인해보겠다.
가중치를 모두 균일한 값으로 초기화한다면 어떻게 될까?
back propagation에서 모든 가중치의 값이 똑같이 갱신되기 때문에 학습이 제대로 이루어지지 않는다. 따라서 가중치는 무작위로 설정해야 한다.
가중치의 초기값에 따라 은닉층의 활성화값들이 어떻게 변하는지를 관찰해보겠다. 활성화함수로 sigmoid를 사용하는 5층 신경망에 무작위로 생성한 입력 데이터를 넣어 각층의 활성화값 분포를 히스토그램으로 그려본다.
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def ReLU(x):
return np.maximum(0, x)
def tanh(x):
return np.tanh(x)
input_data = np.random.randn(1000, 100) # 1000개의 데이터
node_num = 100 # 각 은닉층의 노드(뉴런) 수
hidden_layer_size = 5 # 은닉층이 5개
activations = {} # 이곳에 활성화 결과를 저장
x = input_data
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
# 초깃값을 다양하게 바꿔가며 실험해보자!
w = np.random.randn(node_num, node_num) * 1
# w = np.random.randn(node_num, node_num) * 0.01
# w = np.random.randn(node_num, node_num) * np.sqrt(1.0 / node_num)
# w = np.random.randn(node_num, node_num) * np.sqrt(2.0 / node_num)
a = np.dot(x, w)
# 활성화 함수도 바꿔가며 실험해보자!
z = sigmoid(a)
# z = ReLU(a)
# z = tanh(a)
activations[i] = z
# 히스토그램 그리기
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1) + "-layer")
if i != 0: plt.yticks([], [])
# plt.xlim(0.1, 1)
# plt.ylim(0, 7000)
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()-
가중치를 표준편차가 1인 정규분포로 초기화 할 때 각 층의 활성화값의 분포
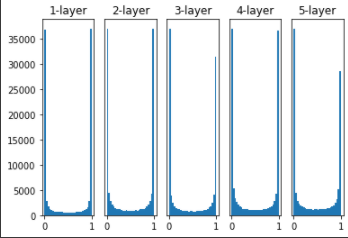
sigmoid 함수는 출력이 0또는 1에 가까워지면 미분이 0으로 다가가기 때문에 데이터가 0과 1에 치우쳐 분포하게 되고, 역전파의 기울기 값이 감소하다가 사라지게 된다. 이것을 기울기 소실 (gradient vanishing)이라고 부르며, 층이 깊어지는 딥러닝 에서는 심각한 문제이다.
-
가중치를 표준편차가 0.01인 정규분포로 초기화 할 때 각 층의 활성화값의 분포
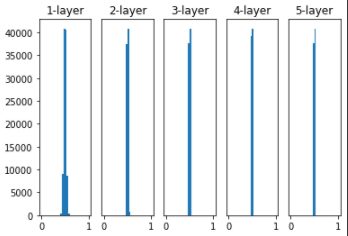
활성화 값들이 0.5로 치우치게되면 뉴런이 거의 같은 값을 출력하고 있다는 것이므로 모델의 표현력을 제한하게 되어 문제가 된다.
-
Xavier 초깃값 (활성화함수가 선형일 경우 : sigmoid, tanh)
앞계층의 노드가 n개이면 표준편차가 인 분포를 사용하는 것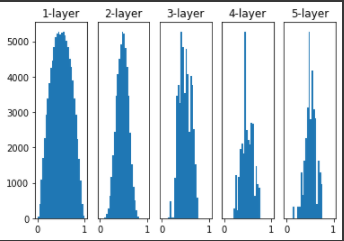
층이 깊어지며 형태가 일그러지긴 하지만 각 층에 흐르는 데이터가 적당히 퍼져있으므로 sigmoid 함수의 표현력을 제한하지 않고 학습이 잘 이루어진다.
-
He 초깃값 (활성화 함수가 비선형인 경우 : ReLU, leaky ReLU)
앞계층의 노드가 n개이면 표준편차가 인 분포를 사용하는 것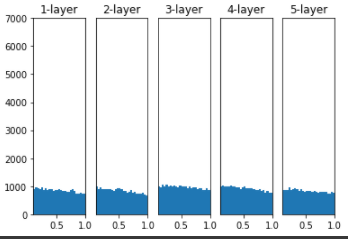
모든 층에서 분포가 균일하기 때문에 역전파에서도 적절한 값이 나온다
pytorch를 이용한 가중치 초깃값 설정에 대한 더욱 다양한 모듈은 공식문서를 참고한다.
과제 수행 과정 및 결과
- MNIST 데이터셋 분류하는 간단한 MLP
피어 세션
- 저번주 선택과제에 대한 토의
- 통계학 스터디 계획 세우기
- ResNet의 residual connection에 대한 토의
학습 회고
keep
강의에서 토의할만한 내용이 나오면 다른 책, 게시글을 찾아 공부해서 단순 강의만 배우지말고 더 업그레이드 시키기
problem
- pytorch 기본기 부족하여 앞으로 더 어려운 내용이 나오면 강의를 따라가기 힘들것
- transformer, ResNet 등 앞으로 배우게 될 모델 기본 지식이 부족
- 강의하면서 모르는 내용 아는 척 넘어가지 말 것
try
- pytorch 공식문서 참고하여 공부하기
- 기본 원리 예습해오기
- 멘토님들께서 올려주시는 강의 자료 들어가서 보기
