KNN(최근접 이웃방법)에 대하여 알아보자
해당 데이터와 가장 가까이 있는 K개의 데이터를 확인하여 새로운 데이터 특성을 확인하는 방법
- 지도학습 알고리즘 중 하나
- k는 홀수를 쓰는게 보편적
(k가 짝수면 1:1 대응이 될 수 도 있기 때문) - 회귀와 분류 모두 사용 가능
그림을 이용하여 KNN의 동작원리를 알아보자
동작과정 1
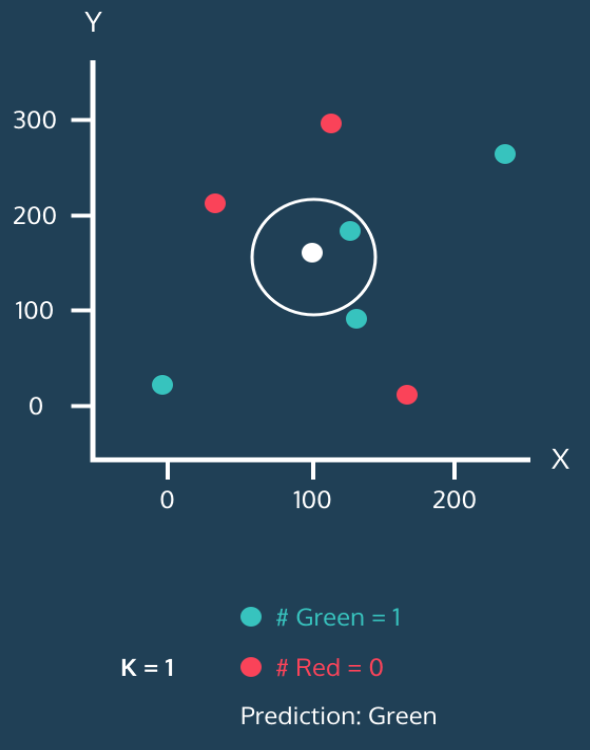
step 1
➡️K=1 이므로 하얀색 원을 중심으로 가장 가까운 1개의 점을 포함해야한다.
step 2
➡️Green 점 1개가 포함된다.
step 3
➡️Green =1 Red = 0 이므로 하얀색 원은 Green 으로 예측 할 수 있다.
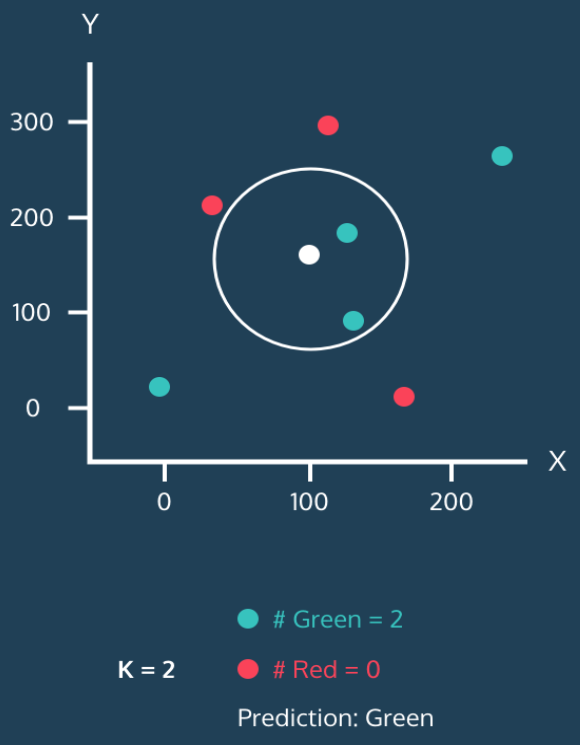
동작과정 2
step 1
➡️K=2 이므로 하얀색 원을 중심으로 가장 가까운 2개의 점을 포함해야한다.
step 2
➡️Green 점 2개가 포함된다.
step 3
➡️Green =2 Red = 0 이므로 하얀색 원은 Green 으로 예측 할 수 있다.
동작과정 3
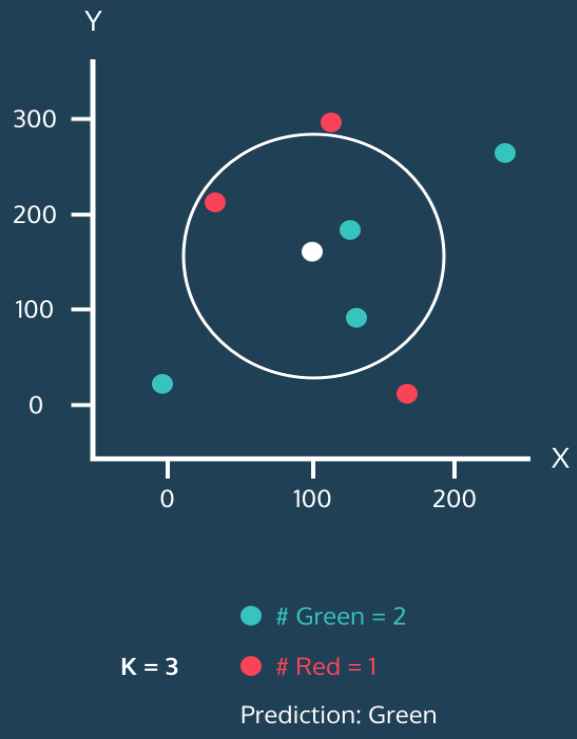
step 1
➡️K=3 이므로 하얀색 원을 중심으로 가장 가까운 3개의 점을 포함해야한다.
step 2
➡️Green 점 2개와 Red 점 1개가 포함된다.
step 3
➡️Green =2 Red = 1 이므로 하얀색 원은 Green 으로 예측 할 수 있다.
동작과정 4
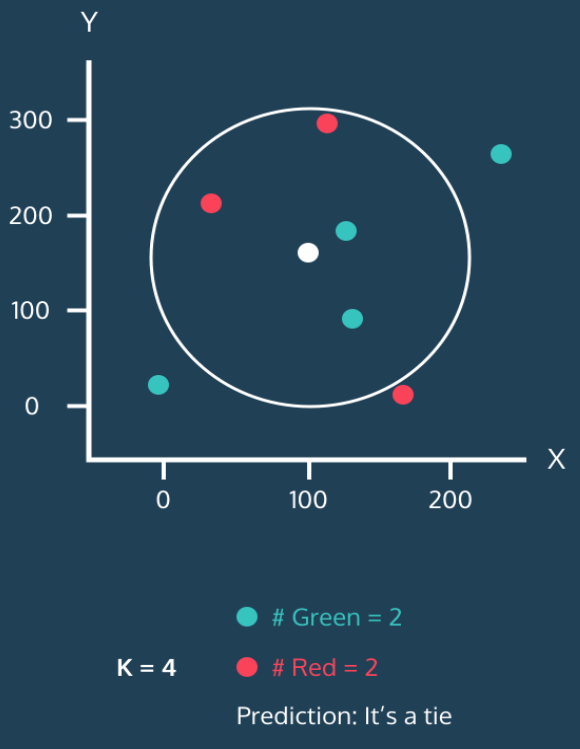
step 1
➡️K=4 이므로 하얀색 원을 중심으로 가장 가까운 4개의 점을 포함해야한다.
step 2
➡️Green 점 2개와 Red 점 2개가 포함된다.
step 3
➡️Green 점과 Red 점의 개수가 같으므로 추가적인 방법을 이용하여 예측한다.(K의 개수를 홀수로 지정하는 이유)
동작과정 5
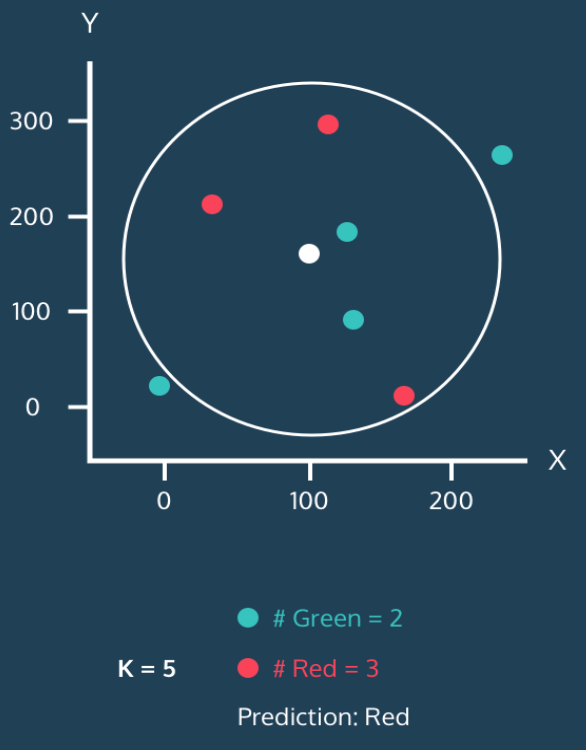
step 1
➡️K=5 이므로 하얀색 원을 중심으로 가장 가까운 5개의 점을 포함해야한다.
step 2
➡️Green 점 2개와 Red 점 3개가 포함된다.
step 3
➡️Green =2 Red = 3 이므로 하얀색 원은 Red 으로 예측 할 수 있다.
K-Means에 대하여 알아보자
KNN 에 대해서 알아보자
- 비지도학습의 군집화로 널리 사용
- K 는 묶을 그룹의 수
- Means 는 데이터로부터 그 데이터가 속한 그룹의 중심까지의 평균 거리를 의미(이 값을 최소화 하는게 K-Means)
- 반복적인 접근을 함
그림을 이용하여 K-Means의 동작원리를 알아보자
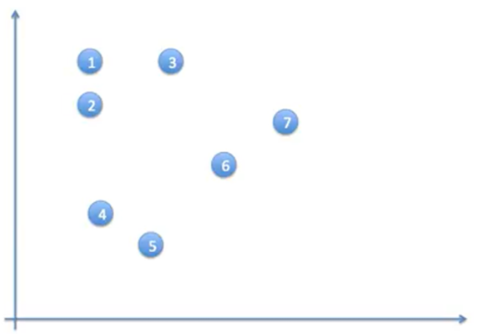
동작과정 1
➡️어떠한 정보도 없는 데이터가 주어짐
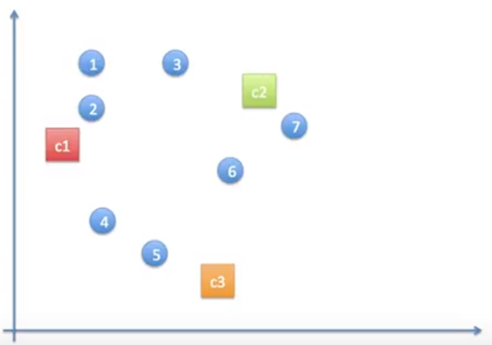
동작과정 2
➡️랜덤으로 중심될 점 c1,c2,c3를 잡음
동작과정 3
➡️점 하나씩 랜덤으로 지정한 중심점에 비교하여 가장 가까운 중심점으로 묶음
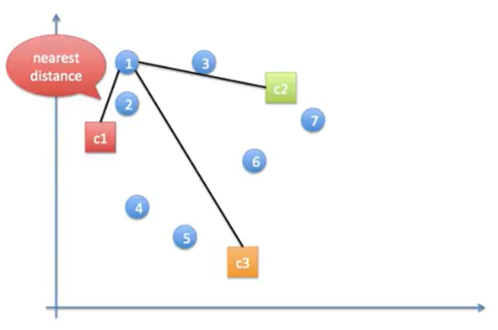
동작과정 4,5
➡️랜덤으로 지정했던 중심점을 묶은 점들의 중심점으로 갱신함
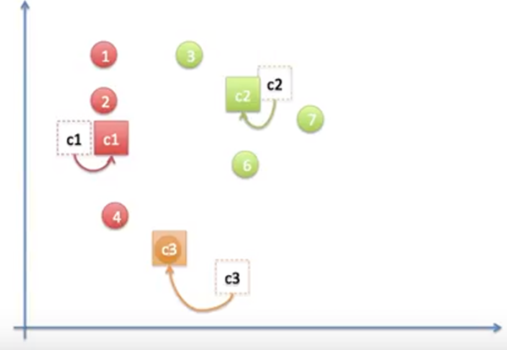
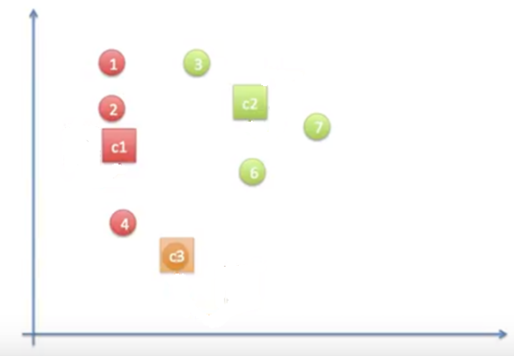
동작과정 6
➡️그림1~5까지의 과정을 다시 반복함. 중심점이 바뀌었으므로 묶음 또한 바뀜.
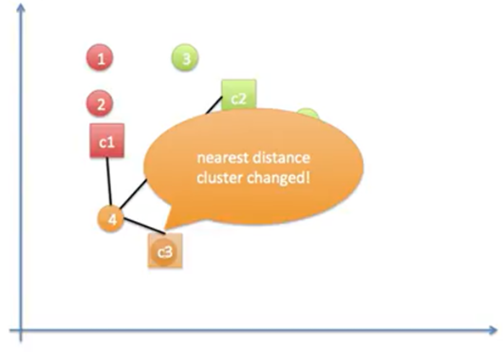
동작과정 7
➡️더이상 중심점이 갱신되지 않으면 종료.