논문 : https://arxiv.org/pdf/2106.09685.pdf
Abstract
We propose Low-Rank Adaptation, or LoRA, which freezes the pretrained model weights and injects trainable rank decomposition matrices into each
layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks
사전 학습된 모델 가중치를 frozen 하고 학습 가능한 rank 분해 행렬을 트랜스포머 각 계층에 주입한다.
Introduction
자연어 프로세싱의 맣은 어플리케이션은 하나의 큰 규모의 사전훈련된 모델을 다양한 down stream의 어플리케이션을 fine-tuning하는 것이 일반적이다.
이러한 방법의 단점은 기존 모델과 마찬가지로 새로운 모델도 많은 파라미터들을 가지고 있는 것이다. 이러한 방법은 매우 "inconvenience"하다. 왜냐하면 GPT-3의 경우 1750억개의 파라미터를 가지고 있기 때문이다.
그래서 기존 모델에 external module과 같은 Adapter를 추가하는 방법이 제안되었다. (Houlsby 2019 정리한 블로그)
Adapter 단점
- 이러한 Adapter를 추가할수록 추론시간(inference latency)가 증가한다.
=> 모델의 depth를 증가시키고 모델의 usable sequence length를 줄이기 때문이다.
- 여기서 adapter와 시퀀스 길이의 관계에 대해 알아보자.
- 변환기(Transformer) 기반 모델에서 입력 시퀀스의 길이는 모델이 소비하는 메모리 양과 직접적으로 관련이 있다.
- Adapter를 추가하면 추가 계산이 필요하기 때문에 모델이 소비하는 메모리 양이 증가한다.
- 입력 시퀀스가 증가하면 모델이 소비하는 메모리 양이 증가한다.
- 메모리 양은 한정적이다.
- 따라서 Adapter를 추가하면 모델에 input되는 입력 시퀀스가 줄어든다.
- fine-tuning baseline을 맞추지 못한다. 즉 모델의 퀄리티와 효율성의 trade-off가 존재한다.
Low intrinsic diension
Li의 Measuring the Intrinsic Dimension of Objective Landscapes에 따르면 학습된 과도하게 파라미터가 많은 모델이 실제로는 낮은 고유 차원에 있다는 것을 보여준다.
여기서 논문 저자들은 가설을 세웠다고 한다.
모델 adaptation 동안의 가중치의 변화 또한 low "intrinsic rank"를 가지고 있다고 가정하자.
이 의미는 모델이 작업에 대해서 적응(Adaptation)을 수행할 때 가중치 변화가 상대적으로 단순한 구조를 가지고 있다는 것이다.
=> 우리는 기존 사전학습된 모델의 파라미터는 frozen하고 adatation 동안, rank decomposition matrices를 optimizing 함으로써 모델의 neural network를 학습시킬 것이다.
GPT-3를 예를 들어서 full rank(rank가 12,288)일 때에도 아주 작은 rank를 사용한 것으로 충분했다고 설명한다.
필요한 용어 설명
트렌스포머 아키텍처를 사용할 것이다.
-
input과 output의 dimension size는 이다.
-
self-attention module의 query, key, value, output projection matrices는 로 작성한다.
-
W or 는 사전학습된 모델의 가중치이다.
-
는 Adaptation동안 축적된 gradient update이다.
-
r은 LoRA module의 rank를 의미한다.
-
Adam 최적화를 사용하고
-
모델의 최적화를 위해서 MLP feedfroward dimension은
x 이라한다.
-을 모델의 4배로 차원을 설정함으로써 각 층에서 더 많은 정보를 처리하도록 한다.
Problem statement
기존의 pre-trained 된 autoregressive language model을 라고 하자.
여기서 x는 task의 context이고 y는 target이다.
이러한 pre-trained model을 요약, 기계번역, MRC, NL2SQL 등의 downstream 으로 적용시킨다고 하자.
예를 들어서 요약 작업에서는 는 기사 내용이 되고, 는 해당 요약이 된다.
Full fine-tuning을 하는 동안은 사전학습된 모델의 초기 가중치 에 가중치 업데이트를 한 를 더한다. 는 다음 조건부 언어 모델의 목표(objective)를 최대화하려 한다.
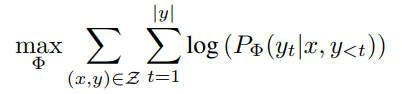
-
여기서 는 모델 파라미터 를 사용해서 입력 x와 이전 단어들 Y<t가 주어졌을 때 단어 의 확률을 계산한다. 이 확률을 최대화하는 것이 objective이다.
-
log로 변환하면 확률의 곱을 덧셈으로 편하게 바꿀 수 있다.
-
외부의 합 은 데이터셋 Z에 대해 전체적으로 좋은 성능을 내도록 하는 것이다.즉, 모든 가능한 (x,y) 쌍에 대해 로그 우도를 더하여 모델이 데이터셋 전체에서 가능한 한 좋은 예측을 하도록 한다.
하지만 이러한 방법의 단점은 값이 너무 크기 때문에 challenging 하다는 점이다.
따라서 우리는 parameter-efficient한 접근을 채택하여 훨씬 적은 파라미터 셋인 를 통해 다음의 식을 목표로 삼는다.
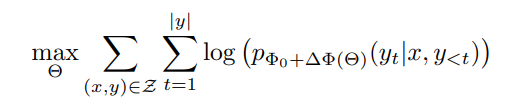
이다.
= 이다.
는 compute하고 memory-efficient하다.
GPT-3에서 는 기존 파라미터인 의 0.01%밖에 되지 않는다고 한다.
Aren't existing solutions good enough?
기존의 방법도 충분히 좋지 않냐고 물어 볼 수 있다.
기존방법은 크게 두가지가 있다.
- Adding Adapter
- Optimizing some forms of the input layer activations
이러하 방법은 둘다 한계점들을 가지고 있다고 한다. 특히 large-scale과 latency-sensitive 생성 시나리오에서 문제가 있다고 한다.
Adapter Layers Introduce Inference Latency
Inference Latency는 시스템이 결과를 출력하는데 걸리는 시가을 의미한다.
다양한 종류의 adapter가 있지만 여기서는 original design인 Houlsby 2019의 Adapter를 채용했다.
Adapter의 경우 매우 작은 파라미터만 사용하기 때문에 issue가 없는 것처럼 보일 수 있다. 하지만 large neural networks의 경우 대기 시간을 줄여야 하기 때문에 하드웨어 병렬성에 의존한다.
- 하지만 Adpater를 사용하면 순차적으로 처리되어야 하기 때문에 온라인 inference 설정에 차이가 발생할 수 있다. 온라인 inference 의 세팅에는 batch ize가 보통 1로 설정되기 때문이다.
Table 1을 보면 Adapter를 사용한 경우 지연 시간이 증가한 것을 확인할 수 있었다.
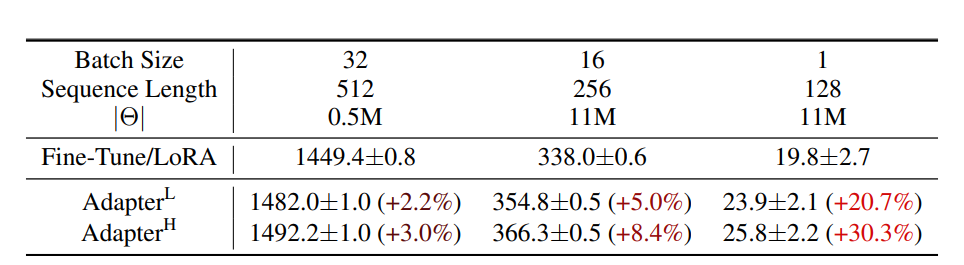 (Table 1)
(Table 1)
Batch size가 오른쪽으로 갈수록 줄어든다. 따라서 입력되는 length의 길이도 줄어든다. 는 Adapter 층에서 학습 가능한 파라미터 수를 의미한다.는 각각 다른 방법의 어댑터 튜닝을 의미한다.
- 이러한 문제점은 모델을 공유해야할 때 더 많은 문제가 발생한다.
- 왜냐하면 추가적인 Depth는 어댑터 매개변수를 여러번 중복 저장하지 않는 한, 더 많은 동시성 GPU operations를 요구하기 때문이다.
Directly Optimizing the Prompt is Hard
Prefix tuning은 sequence 길이의 일부를 고정하기 때문에 작업을 위해 훈련되는 길이가 줄어든다고 한다.
Our Method (LoRA)
그래서 이 논문이 제안하는 방법은 어떠한 dense layer에 특정 weights를 추가하는 것이다.
Low-Rank Parametrized Update Matrices
기존 neural network 모델의 weight는 full ranks를 가진다.
pre-trained language models have a low “instrisic dimension” and can still
learn efficiently despite a random projection to a smaller subspace
위 문장을 해석하면, 사전 학습된 모델을 specific task에 적용할 때, low instrisic dimension을 가진다고 한다. 그리고 더 작은 subspace로 무작위 투영에도 불구하고 효율적으로 학습을 할 수 있다는 것이다.
-> instrisic dimension은 모델이 실제로 정보를 표현하는데 필요하는 차원의 수이다.
-> random projection은 고차원 데이터를 보존하면서 저차원으로 차원의 수를 줄이는 것이다.
이 문장은, 사전 학습된 언어 모델이 원래의 고차원 공간에서 많은 정보를 유지하면서도, 차원 축소 기법을 통해 더 낮은 차원의 공간으로 데이터를 효과적으로 압축할 수 있다는 것을 의미한다.
그래서 low Intrinsic rank를 제안한다.
- 사전 학습된 모델의 weigth matrix를 라고 하자. 이는 (d,k) dimension을 가진다.
- 또한 (d,k) dimension이다.
- = + BA로 low-rank decomposition으로 표현한다. 이때 B는 (d,r)이고 A는 (r,k) 차원을 가진다. 여기서 r은 d,k보다 작은수이다.
- 은 그대로 두고 A와 B만 학습시킨다.
로 나타낼 수 있다.
이 표현을 이렇게 그림으로 나타낸다.
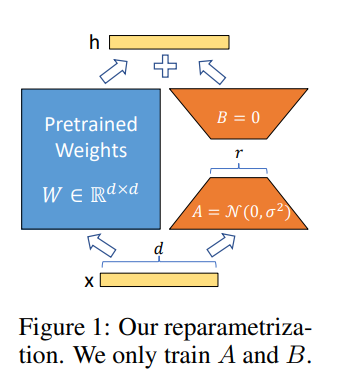
A에는 랜덤 가우시안 초기화를 적용하고 B에는 0로 초기화를 한다고 한다. 그래서 는 훈련 시작때는 0으로 초기화된다고 한다.
- 는 /r로 규모를 조정한다고 한다.
- 는 상수이다. Adam으로 최적화를 진행할 때, 는 학습률과 같이 작동한다고 한다. 맨처음에 를 세팅하고 튜닝하지 않는다고 한다. r을 변경할때 를 고정해야 하이퍼파라미터를 다시 튜닝하기 편하기 때문이라 한다.
장점
- A Generalization of Full Fine-tuning
- Adaptation 동안 전체 rank에 대해 누적 기울기 업데이트가 필요없어진다.
사전 학습된 weight 행렬의 rank r을 세팅함으로써 전체 fine-tuning을 한 것과 거의 비슷해진다는 의미이다. - Adapter-based model은 MLP와 유사한 구조가되고
- Prefix-based model은 long input sequence를 넣을 수 없는 구조가 된다.
- Adaptation 동안 전체 rank에 대해 누적 기울기 업데이트가 필요없어진다.
- No Addtional Inference Latency
- 를 계산하는 것이기 때문에 계산 속도가 빠르다. 그리고 원래의 가중치인 를 보존하기 때문에 로 바꾸는 것도 가능하다. 이는 추가적인 대기시간을 증가시키지 않는다.
Applying LoRA to Transformer
트랜스포머 구조에 어떻게 적용할까?
트랜스포머에는 self-attention moudle 4가지가 있다.
또한 두개의 weight matrix가 MLP에도 있다.
여기서는 를 x 의 하나의 차원으로 다룬다고 한다.
논문에서는 downstream task를 위해서 오직 attention weights만 adapting했다고 한다. 그리고 MLP 모듈을 freeze 한다고 한다.
부록에서는 다른 attention type에 대해서도 연구했다고 한다.
Practical Benefits and Limitations
실용적인 혜택은 무엇일까? 일단 중요한 점은 메모리와 저장 공간을 줄였다는 점이다.
- VRAM의 공간을 2/3으로 줄였다.
- task 사이를 LoRA의 weight를 swapping 하면서 switch할 수 있다.
하지만 한계점도 존재한다고 한다.
- 다양한 작업을 한번에 처리하는 것이 어려워진다. 각각 다른 작업들이 다른 A,B를 사용하기 때문이다.
- 추론 지연 문제를 해결하기 위해서 A,B를 기존 가중치에 흡수해야한다.
- 추론 지연 시간이 문제가 되지 않는 상황에서는 동적으로 LoRA 모듈을 선택해서 기존 가중치에 흡수하지 않는 방법도 있다.
Experiments
실험을 어떻게 진행했는지 알아보자!
크게 RoBERTa, DeBERTa, GPT-2, GPT-3 에서 실험을 진행했다고 한다.
Baselines
- Fine-tuning(FT): 가장 흔한 방법이다. 미세 조정하는 동안은 모델은 처음 pre-trained model의 가중치를 물려받고, gradient를 업데이트하는 동안 가중치가 변경된다. 간단한 방법은 오직 몇개의 layer만 update하는 방법이다. Top layer들을 보통 fine-tuning 한다.
- Bias-only or BitFit: 오직 bias 매개변수만 fine-tuning한다.
- Prefix-embedding tuning: 추가 임베딩을 삽입한다. 추가 임베딩들은 훈련 가능한 word embeddings 이며 모델의 단어장에 있지 않다.
- Prefix-layer tuning: 이건 Prefix-embedding tuning의 확장이라 한다. 다른점은 모든 transformer layer에 activations을 수행한다는 점이다.
- Adapter tuning
- Houlsby의 어댑터는 self-attention module과 residual connection사이에 adapter layer를 추가했다. ->라고한다.
- Lin (2020)의 Adapter는
- Pfeiffer (2021)의 Adapter는
- AdapterDrop이라는 것도 있는데 이를 라고 하자.
RoBERTa Base/Large
RoBERTa로 실험 비교해보자.
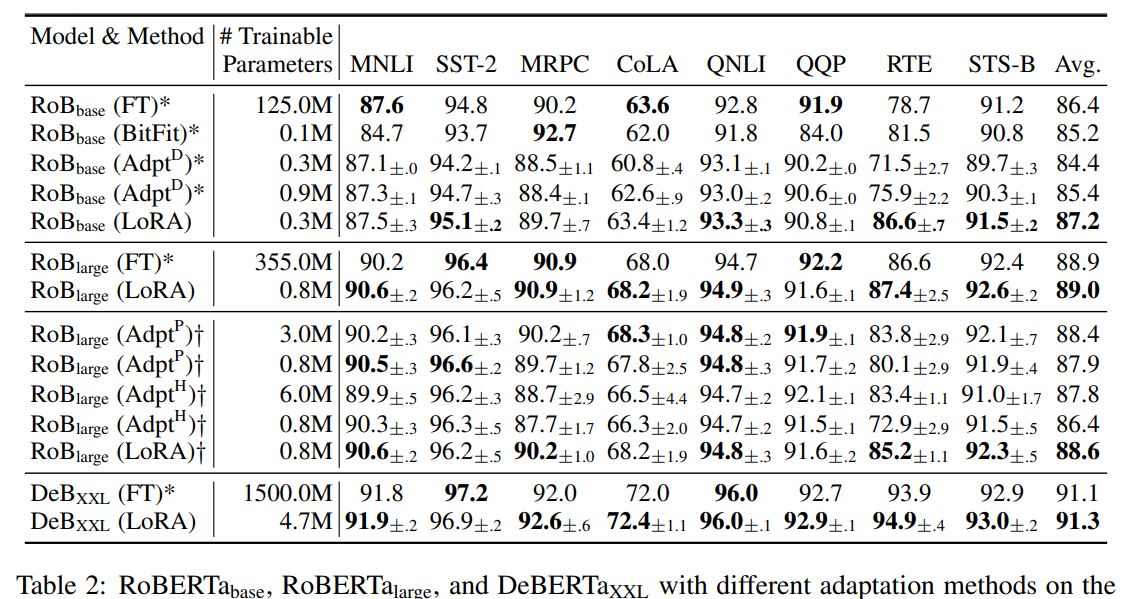
십자가는 Houlsby의 실험 세팅과 유사하게 나타낸 것이라 한다.
각각 다른 GLUE benchmark에서 조사해서 NLU의 성능을 파악했다.
여기서 별표는 이전 논문에서 발표한 실험을 인용한 것이다.
- LoRA를 다른 어댑터와 평가하기 위해서 동일한 batch size를 사용했다고 한다.
- MPRC, RTE, STS-B에 대해서는 사전 학습된 모델로 모델을 초기화한다고 한다.
DeBERTa XXL
더 최근에 나온 BERT의 더 큰 larger model이다.
GPT-2 medium/large
LoRA의 성능이 표에서 알 수 있듯 굉장히 좋은 성능을 보였다. NLU에서 성능이 좋았으니, NLG성능에서도 좋은지 알아보았다.
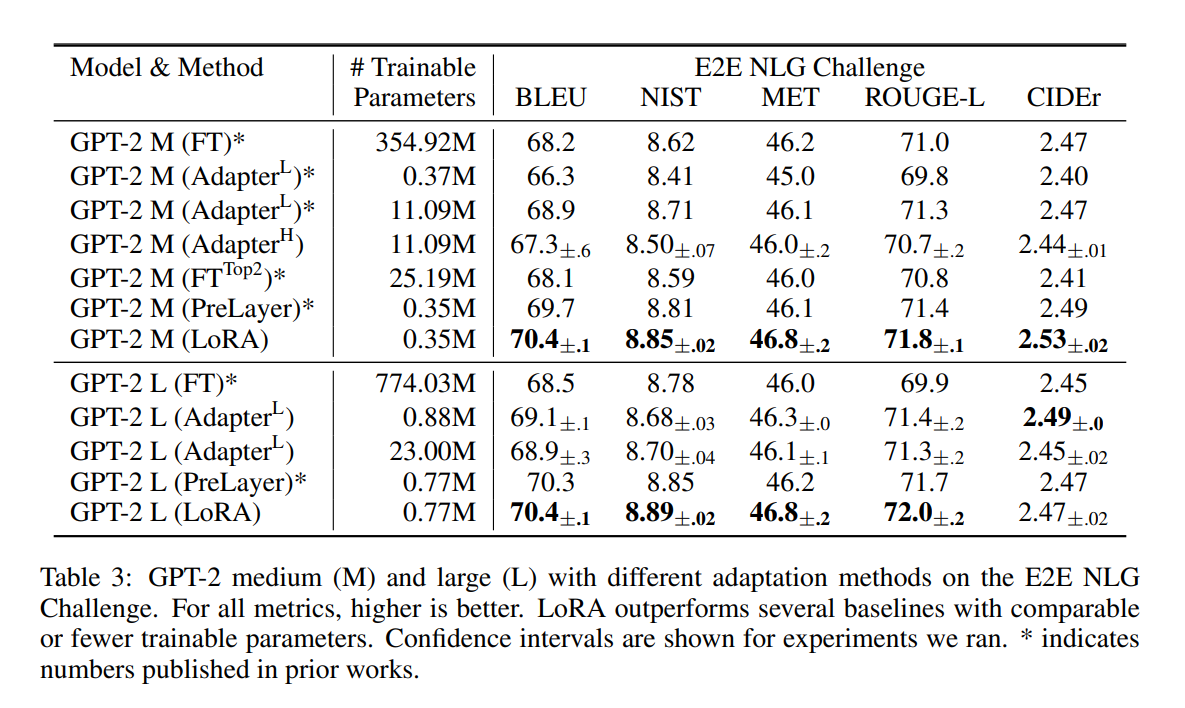
'*'은 이전 논문에서 발표한 숫자들이다.
LoRA의 성능이 압도적으로 좋았다.
GPT-3
1750만개의 파라미터로 확장해보았다. training 하는데 많은 비용이 들기 때문에, 오직 random seed에서만 한번 작업을 수행했다고 한다.
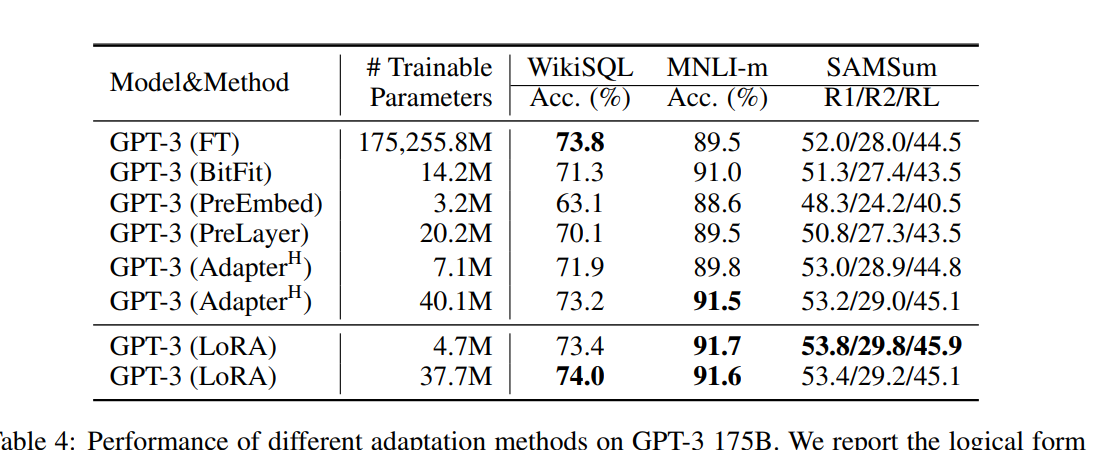
LoRA는 baseline 보다 모두 우수하거나 같은 성능을 보였다고 한다.
매개변수가 많다고 해서 성능이 더 우수한 것이 아니였다.
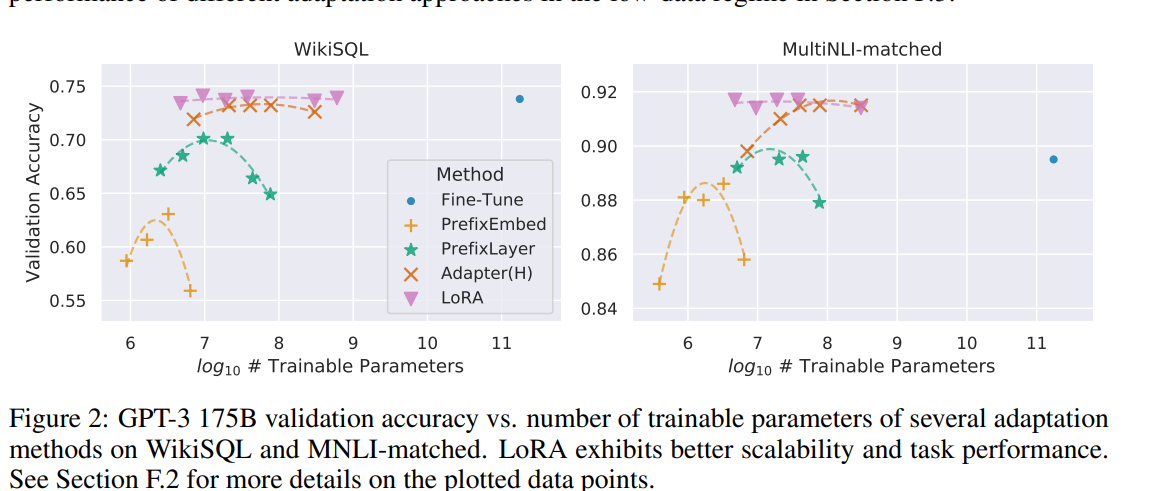
Figure2를 보면 PrefixEmbed, PrefixLayer에서 더 많은 훈련가능한 파라미터를 가질수록 성능이 떨어지는 현상을 보았다. -> 더 많은 특수 토큰을 사용하면 입력분포가 사전훈련 데이터 분포에서 더 떨어져서라고 주장하는데, 이 논문의 주제밖 내용이긴 하다.
