논문 : https://arxiv.org/pdf/1901.07291.pdf
이전보다는 간단하게 리뷰해보자!
Cross-lingual Language Model
Cross-lingual Language Model이 뭐지?
✔️ Cross-lingual Language Model
다언어 처리 가능 : 한 언어로 학습된 모델을 다른 언어에도 적용할 수 있음
Low-resource 언어에 대한 지원 : 영어와 같은 자원이 풍부한 언어에서 학습된 지식을 자원이 부족한 언어에 전달할 수 있음
효율적인 모델 : 하나의 모델로 여러 언어를 처리할 수 있기 때문에 효율적
✔️ 활용예시
기계 번역 (MT) : 영어를 일본어, 중국어, 아랍어 등등으로 번역하는 일
다국어 텍스트 분류 : 여러 언어로 된 텍스트들을 특정 카테고리에 분류하는 작업
NER : 다양한 언어의 텍스트에서 인명, 조직명, 지명 등의 정보를 자동으로 식별하는 작업
지금 우리가 흔하게 쓰는 chatGPT도 cross-lingual language model이다. 한국어, 중국어, 일본어, 영어 등 대부분의 언어에 대해서 학습하고, 작업을 수행한다.
Contributions
이 논문이 제시하는 contribution은 다음과 같다.
- XLM을 위한 새로운 비지도 학습 방법을 제시한다.
- 새로운 지도 학습 방법 제시
- 이전 cross-lingual model보다 더 좋은 성능을 보임
- low-resource language에 대한 perplexity의 개선을 보임
- 사전학습된 모델을 공개
Related Work
- Cross-lingual representations은 단일 언어 표현의 성능을 증가시킨다.
- 이번 논문에서 단일 언어 데이터를 사용함으로 병렬 데이터의 필요성이 줄어들었다.
Cross-lingual language models
이번 논문은 3가지 사전학습 방법을 제시한다.
기존의 Transformer 구조를 사용하되, pre-training의 방법을 3가지 제시한다.
2가지는 단일언어 데이터만 사용하는 비지도 학습 방식이고
나머지 하가지는 병렬 데이터를 사용하는 지도 학습 방식이다.
Shared sub-word vocabulary
Byte Pair Encoding을 총해 공유 어휘 단어장을 만들어 모든 언어를 처리하다.
단일 언어 corpora에서 랜덤으로 선택된 문장을 BPE 방법으로 나눈 것으로 학습한다.
저자원 언어에 대해서는 토큰수를 늘리고 고자원 언어에 대해서는 토큰수를 줄인다. 즉 고자원 언어에 대한 편향을 완화시킨다.
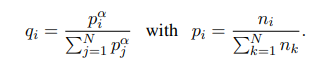
는 0.5로 설정한다고 한다.
Causal Language Modeling(CLM)
이전 단어들을 기반으로 현재 단어의 확률을 모델링하는 Transformer 언어 모델을 훈련한다
를 통해 구한다.
Masked Language Modeling(MLM)
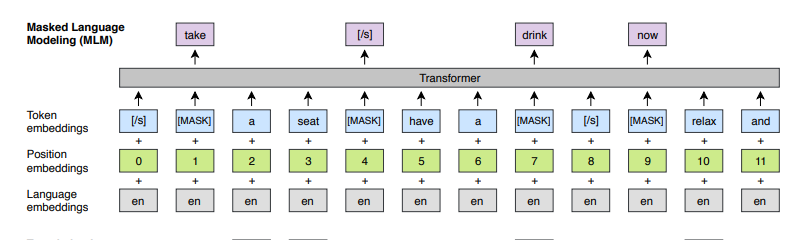
BPE token의 15%를 샘플링한뒤
- 80%는 MASK
- 10%는 다른 토큰으로 대체
- 10% 변경하지 않음
BERT에서 사용한 MLM와 다른 점은 문장의 pair 대신에 임의의 수의 문장의 텍스트 스트림을 사용한다는 점이다.
토큰 사이의 불균형을 해소하기 위해서 빈도의 제곱근에 반비례하는 가중치를 가진 다항분포에 따라 텍스트 스트림의 토큰을 샘플링했다고 한다.
Translation Language Modeling(TLM)
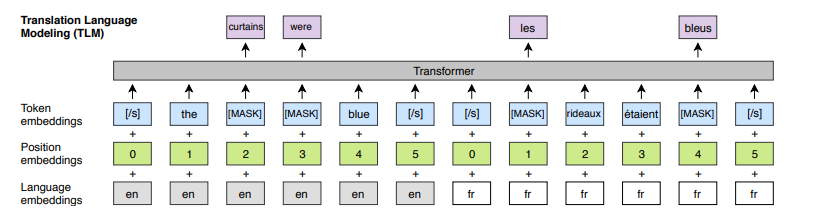
CLM, MLM은 비지도 학습 방법이고 단일 언어 데이터를 사용한다.
TLM의 경우에는 병렬 문장을 연결해서 사용한다.
예를 들어서 영어->프랑스어인 경우를 생각해보자.
영어의 빈칸을 맞춰야한다고 하자. 이를 위해 영어 주변의 문장 또는 프랑스어 표현을 통해서 영어의 빈칸을 유추할 수 있다.
그러니까 입력에는 영어+프랑스어 가 동시에 들어가는 것이다.
이때 프랑스어의 position은 다시 0부터 세팅이 된다.
Experiments
training details
Transformer 아키텍처를 사용했다.
- Adam 최적화
- learning rate : 1e-4 ~ 5e-4
- CLM and MLM
- 256 token
- mini batch size : 64
- TLM
- mini batch 4000 tokens
- 기계 번역에서는 오직 6 layer만 사용
- min batch 2000 tokens
XNLI fine-tuning
- mini batch size : 8 or 16
- 256 words
- 80k BPE splits
- 95k의 단어장
- 12 layers
- Adam
- learning rate : 5e-4 ~ 2e-4
더 자세한 실험 환경은 논문 참조 부탁..
Data preprocessing
✔️ Data preprocessing
- 단일 언어 corpus는 WikiExtractor2를 통해 Wikipedia에서 수집
- 병렬 언어 데이터를 수집하기 위해서 각 언어마다 다른 곳에서 데이터를 수집
- 예: 프랑스어, 스페인어 등은 MultiUN(유엔 연설 병렬 courpus), Hindi는 IIT Bombay corpus에서 데이터 추출
- 모두 Token으로 만든다.
Cross-lingual language model pretraining
여러가지 실험 과정과 결과를 보자.
Cross-lingual classification
XLM은 일반적 목적의 크로스-언어 텍스트 표현을 제공한다고 한다.
pretraining 된 XLM을 cross-lingual classification benchmark에 fine-tuning 했다고 한다.
이때 XNLI 데이터셋을 사용했다고 한다.
- NLI는 전제가 주어졌을 때, 두 문장의 유사도를 통해 가설이 참, 거짓, 중립 중 선택하는 작업
- 다국어 token으로 pretraining 된 transformer의 첫번째 hidden state에 선형분류기를 추가한다.
- 영어 NLI dataset에 fine-tuning을 한다.
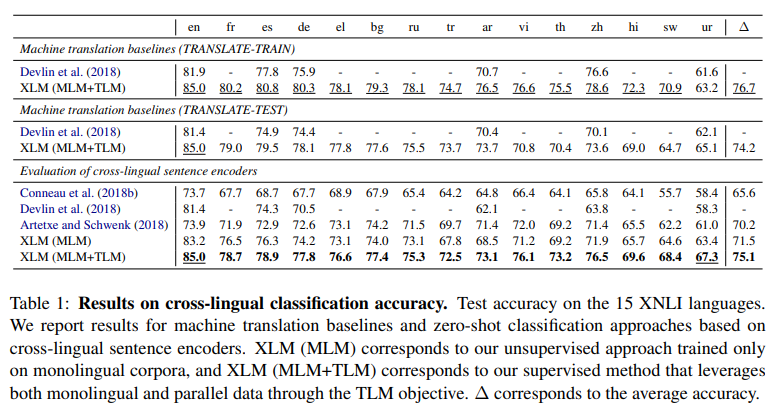
두 언어의 번역이 잘 되는지 확인하기 위해서 baseline을 추가했다.
- TRANSLATE - TRAIN 은 English MultiNLI train set을 -> 각 언어로 번역해서 fine-tuning한 것이다. 즉 fine-tuning을 한 뒤 각각의 언어로 다시 test를 한 것이다.
- TRANSLATE - TEST 는 각 언어 XNLI의 test set을 -> English 번역한 것을 test한 것이다.
결과는 다음과 같았다.
- MLM 방식으로만 XLM을 훈련한 경우 71.5%의 평균 정확도를 보였다.
- TLM 방식으로 XLM을 추가 훈련한 경우 75.1%의 정확도를 보였다.
- Swahili 와 Urdu 같은 low-resource 언어의 경우에도 6.2%, 6.3% 증가율을 보였다.
- 영어에서도 83.2%->85.0%로 점수가 높아졌다.
- 최근 모델인 Artexe 보다도 11.1%가 높다고 한다.
Baseline과도 비교해보자.
- XNLI의 각각의 training set에 fine-tuning 한 경우(TRANSLATE-TRAIN)의 지도 학습 모델이 ZERO-SHOT 접근보다 1.6% 높았다. (75.1 => 76.7)
- 이는 XLM 모델의 consistency와 XLM은 어떤 언어에서든 강한 성능을 보여줌을 의미한다고 한다. (사실 이해가 안되는데 어떻게든 사족을 붙인 느낌이다.)
- BERT와 비슷하게 TRANSLATE-TRAIN은 TRANSLATE-TEST보다 2.5% 높고 ZERO-SHOT은 TRANSLATE-TEST보다 0.9% 높았다.
Unsupervised Machine Translation
사전 훈련된 cross-lingual language 단어 임베딩의 품질이 비지도학습 기계번역 모델에 큰 영향을 준다.
WMT14 English-French, WMT16 English-German, WMT16 English-Romanian 번역을 포함해서 평가했다.
그리고 인코더와 디코더 두 구조에서 진행했다.
- MLM, CLM, random 초기화 셋 중 하나를 선택한다.
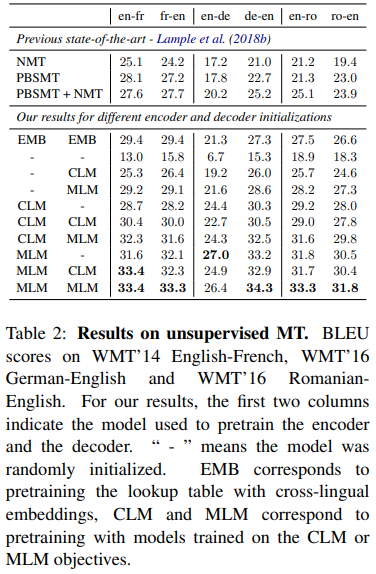
Bleu 점수를 나타낸다.
- EMB는 cross-lingual embeddings의 lookup table을 pretraining.
- '-'는 model이 random 하게 초기화 된 것
- CLM, MLM은 각각 CLM, MLM 목적에 맞게 학습시킨 것이다.
결과를 더 자세히 보자.
- 우선 NMT 보다 훨씬 좋은 성능을 보여준다.
- 독일어->영어를 보면 가장 좋은 성능인 34.3 점을 보여준다.
- MLM 방법이 CLM 방법보다 좋은 성능을 보여준다.
- Encoder 에서 사전 학습한 모델이 Decoder에서 사전 학습한 것보다 더 좋은 성능을 보여주었다.
Supervised Machine Translation
지도학습을 통한 기계번역의 영향을 또한 평가했다.
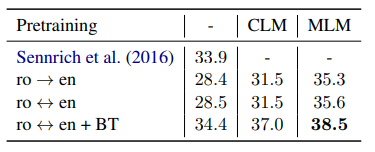
단방향보다 양방향으로 학습한 모델이 더 좋은 성능을 보였다.
back-translation은 데이터 증강기법으로 데이터를 늘릴 때 사용하는 방법이다.
- 사전 학습에 사용된 언어모델과 동일한 단일 언어 데이터로 학습되었다고 한다.
MLM 방법으로 학습한 것이 가장 좋은 BLEU 점수를 보엿다.
bidirectional model이 back-translation과 함께 학습된 모델이 제일 좋은 성능(38.5)을 보였다.
Low-resource language modeling
어휘 상당 부분을 두 언어가 공유하는 경우, 저자원 언어가 고자원 언어의 데이터를 활용하는 것이 유리하다.
예를 들어서 네팔어가 10만 문장이 있고, 힌디어가 60만 문장이 있을 때, 두 언어는 80%이상의 공통 BPE를 가지고 있다고 한다.
이때는 cross-lingual을 하는 경우 네팔어의 perplexity 상당히 개선이 되었다고 한다.
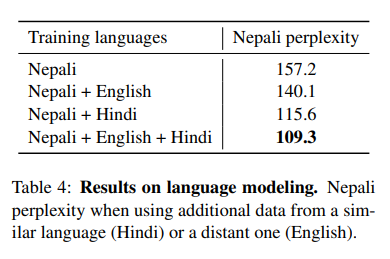
네팔언어만 학습한 경우 157.2이다.
- 하지만 영어와 함께 학습한 경우 모호성이 140.1점으로 떨어졌다.
- 힌디어와 함께 학습한 경우 115.6점으로 많이 떨어졌다.
- 영어와 힌디어와 함께 학습한 경우 109.3점으로 제일 많이 떨어졌다.
모호성은 n-gram anchor point로 계산했다고 한다.
Unsupervised cross-lingual word embeddings
이 논문에서는 shared vocabulary를 사용하기도 했지만 XLM의 lookup table를 통해 word embedding을 얻었다고도 한다.
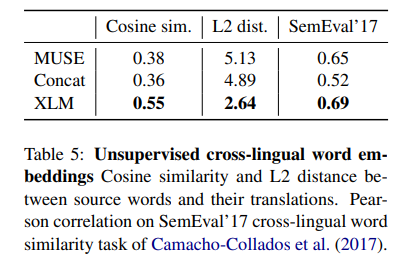
XLM이 MUSE와 Concat보다 더 좋은 성능을 보였다.
흥미로운 점은 cross-lingual word embedding의 공간에서 word translate pair가 XLM에서 제일 가까웠다고 한다.
- XLM의 임베딩은 sentence encoder와 함께 train되어서 이러한 가까움을 강화시킨 것 같다.
- MUSE와 Concat의 경우는 fastText를 기반으로 한 것에 반해
