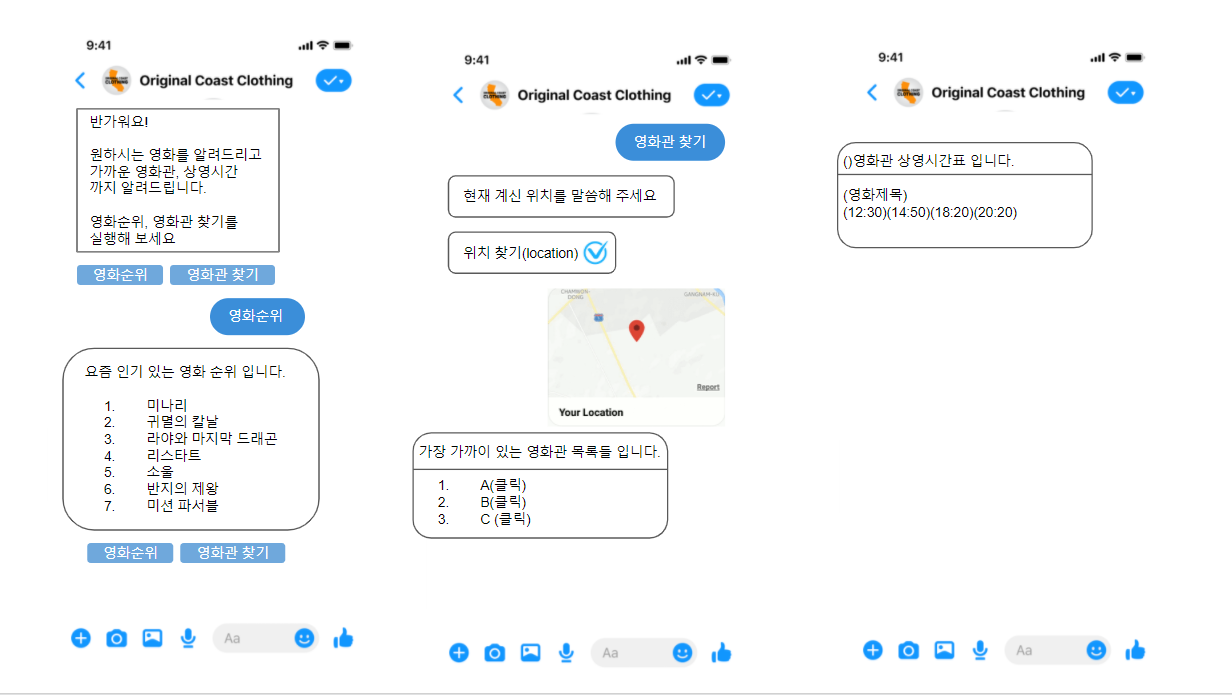
Placeb API 를 사용해서 현재 지금 위치 주변에 있는 CGV를 찾을 수 있었다.
이번 단계는 주변에 있는 CGV 중 선택을 하게 되면 그날의 영화제목과 영화시간을 얻기 위해 '크롤링'을 해보려고 한다.
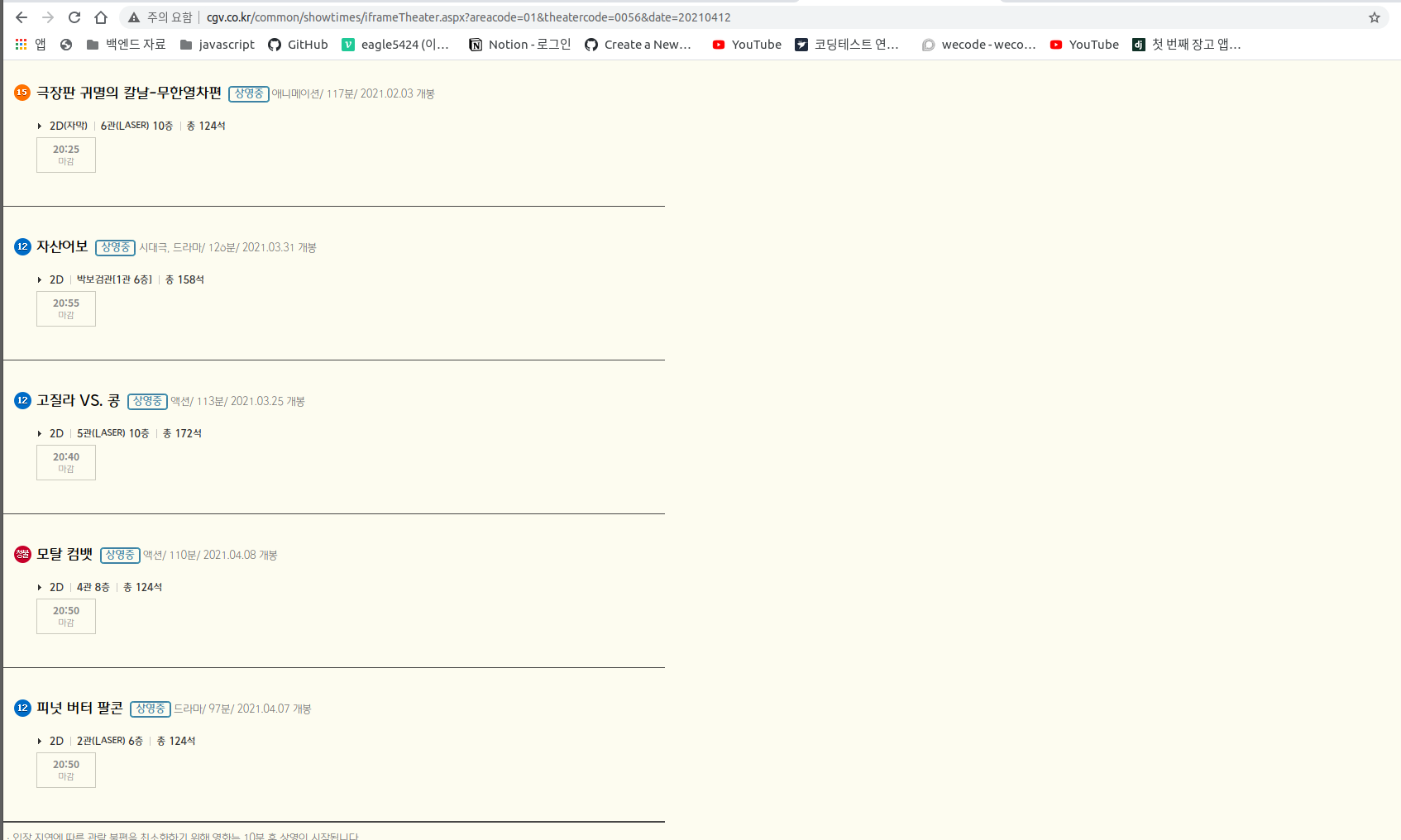
이 페이지를 크롤링 할 예정이다 우선 URL을 보게 되면
http://www.cgv.co.kr/common/showtimes/iframeTheater.aspx?areacode=01&theatercode=0056&date=20210412
theater code, date 라는 쿼리스트링을 볼 수 있는데
즉 theater code 란 각 CGV가 가지고 있는 코드이고 이걸 변경해줌으로써 접근이 가능하다 또한 date를 변경 해주게 되면 어떤 날짜 던지 가져올 수 있다!!
지금 위의 URL을 해석해 보자면 0056은 CGV 강남의 영화관 코드이고 21년 04월 12일 이니까 21년 4월 12일 의 CGV 강남의 영화시간표를 불러 올 수 있고, 이 웹페이지를 크롤링을 하면 우리가 원하는 데이터를 가져 올 수 있다.
코드
.png)
우선 크롤링을 위해 사용할 모듈은 'Beautiful soup'이다.
pip install beautiful soup
beautiful soup에 대해 간단히 말하면, HTML 및 XML 문서 를 구문 분석하기위한 Python 패키지입니다.
그럼 영화의 제목의 html을 보면
body > div > div.sect-showtimes > ul > li:nth-child(1) > div > div.info-movie > a > strong
가져올때는 개발자 도구 창에서 내가 원하는 html에서 오른쪽 마우스를 누르면 창이 나오는데 그 중 'COPY'를 보면 selector를 가져올 수 있다. 그 selectoer를 가져와야지 위의 형태로 가져올 수 있다.
영화시간 html
body > div > div.sect-showtimes > ul > li:nth-child(1) > div > div.type-hall > div.info-timetable > ul > li > a > em
def get movies 는 많은 html에서
body > div > div.sect-showtimes > ul > li:nth-child(1)
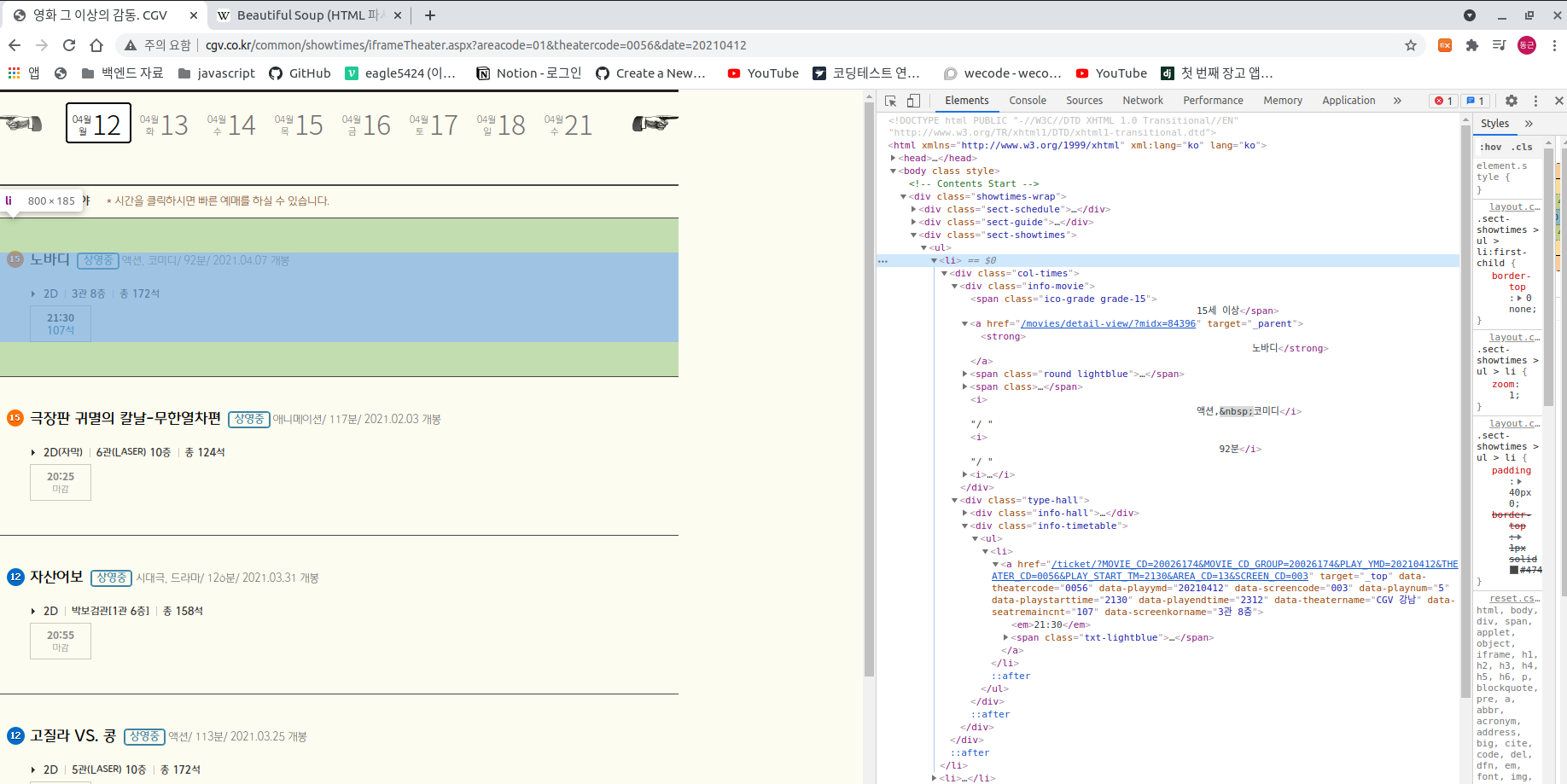
이정도를 가져오는데 코드를 보면
movies = soup.select('body > div > div.sect-showtimes > ul > li')
select('p') 이런식으로 사용하게 되면 'p' 와 같은 형태가 모두 가져오게 되는 것이다.
select_one 을 쓰면 한 개가 오게 된다. ^^
get_movies로 저 블록을 다 불러온 후 get_timetable로 내가 원하는 데이터를 가져오려고 했다.
moives에 있는 여러개의 블록을 for문으로 돌려 title, time 을 가져왔다.
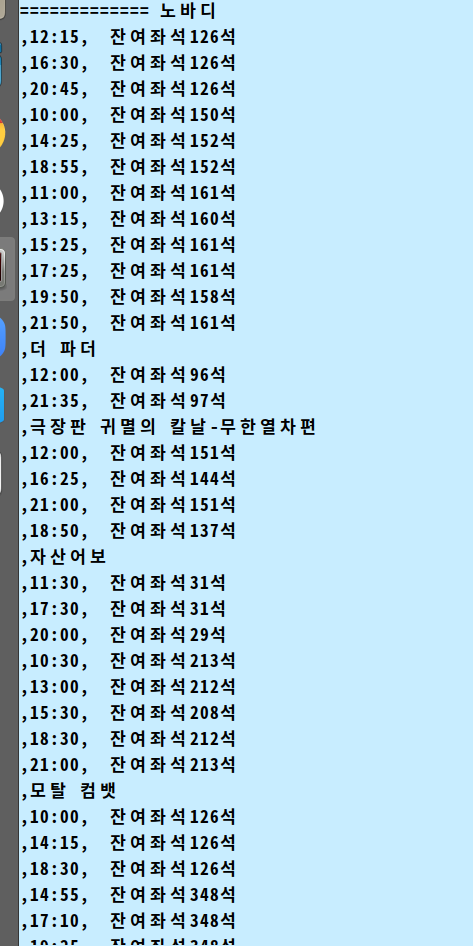
이런식으로 가져올 수 있다.
CGV 코드
cgv 코드는 각각 정리를 한 후에 데이터베이스에 저장 해 두고 사용자가 입력한 내용에 대해 가져오는 형식으로 코드를 구성했다.
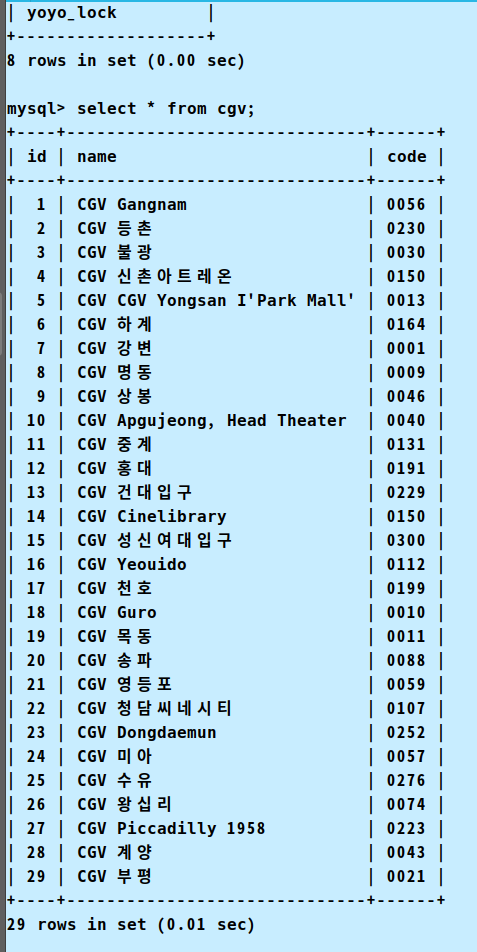
이제 원할때 마다 어떤 곳이던지 가져올 수 있다.
