
Lgbm의 등장배경
: XGBoost의 장점을 그대로 활용하면서, 학습시간을 단축시키자!

전통적인 Gradient Boosting Algorithm의 경우, 각 변수마다 가능한 모든 분할점에 대한 information gain을 평가하려면, feature 즉, data instance를 모두 살펴봐야하는데 이를 위해 많은 시간이 소요됨
따라서, 이문제를 해결하기 위해 LightGBM에서는 2가지 방식을 제안함
LGBM의 Main Concept
- GOSS(Gradient-based One-side Sampling)
- EFB(Exclusibe Feature Bundling)
GOSS(Gradient-based One-side Sampling)

- 개별적인 data는 서로 다른 gradient를 가지고 있으며, information gain 즉, 어느지점을 splilt을 계산해야할지를 판단하는 기준이 됨 (gradient가 클수록 중요함)
- Large gradient를 가진 객체들은 keep, gradient가 작은 객체들은 randomly drop
- 개별적인 객체들에 대해서 gradient를 기준으로 해서 gradient가 가장 높은 값부터 낮은 값까지 sorting
하이퍼 파라미터 a, b - Large gradient에 대해서는 Top a X 100% instance는 전부 보존
- Smll gradient에 대해서는 Random b X 100% instance
1-a / b > 1 이 되는 a와 b를 선택하는 것을 권장함
A = 0.1, b = 0.9(상위 10퍼센트는 보존, 하위 90%는 샘플링)
- 1-a / b = 0.9 / 0.9 = 1
A = 0.05, b = 0.5(상위 5퍼센트는 보존, 하위 50%는 샘플링)
- 0.95 / 0.5 > 1

GOSS 알고리즘의 특징
1) 하이퍼 파라미터 a와 b를 통해 topN, randB 세팅
2) 데이터 개체들의 loss값 즉, gradient 절대값에 따라 데이터 개체들을 sorting
3) 상위 100a% 개의 개체를 추출함
4) 나머지 개체들 집합에서 100b% 개의 개체를 무작위로 추출함
5) 정보 획득을 계산할 때, 위의 2-3 과정을 통해 추출된 Sampled Data를 상수( 1−a.b)를 이용하여 증폭시킴
Usedset <- topSet + randSet을 통해 객체수를 효과적으로 감소시킴.
EFB(Exclusibe Feature Bundling)
- 모든 feature들을 전부 다 탐색하는 비효율성을 줄이는 방법
- feature space가 sparse한 경우에 굉장히 많은 feature 들이 almost exclusive하다는 가정
- Ex) One-hot encoding - 어떠한 2개의 조합도 0이 아닌 값을 동시에 가질수가 없음
실질적으로 one-hot encoding이 아니더라도, 하나의 객체에 대해서 2개이상의 변수들이 0이 아닌 값을 동시에 가질 가능성이 매우 낮은 변수들이 상당히 많이 존재함
아주 가끔은 존재하겠지만, 대부분의 경우에는 exclusive하다는 가정하에서 feature들을 bundling 즉, 묶어줌! 으로써 모든 feature들을 전부 다 탐색하는 비효율성을 해결
Greedy Bundling
현재 존재하는 feature set들에 대해서 어떠한 feature들을 하나의 bundle로 묶을 것인지를 결정
Merge Exclusive Features
bundling되어야 하는, 선택된 변수들을 실제 하나의 변수로 바꿔 표현하는 알고리즘
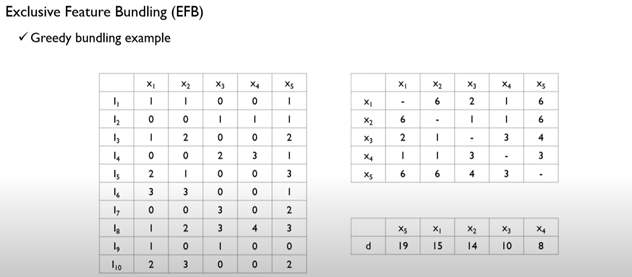
객체 x 변수 테이블 / 각 변수들간의 총 conflict 횟수를 edge로 하는 그래프 / 변수의 자유도
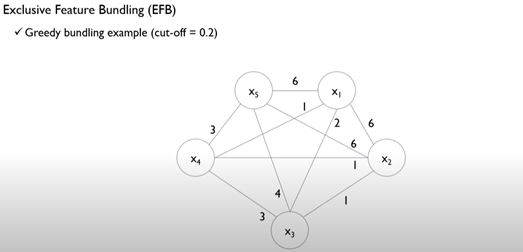
Cut-off : 0.2
총 객체의 수(10) * 0.2 = 2회 이상 conflict가 발생하면 bundle X
{x1,x4} {x2,x3} {x5}를 bundling
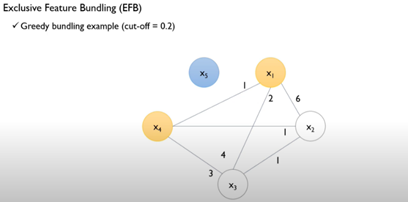
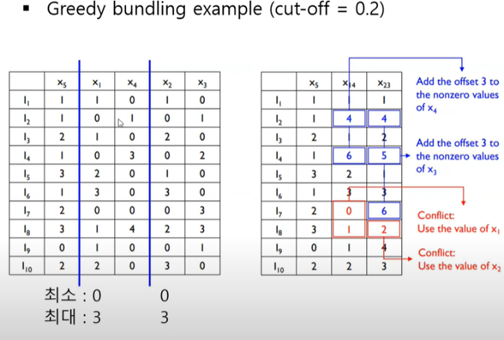
Bundle로 묶으려는 변수에서 기준 변수를 잡고, 기준이 되는 변수가 0일 경우 기준이 되지 않는 변수에 기준변수의 최대값을 더해줌
Conflic가 발생한 변수에 대해서는 기준 변수의 값 그대로 적용

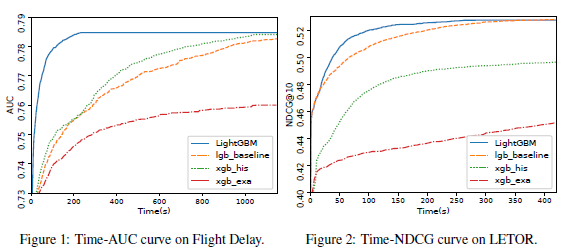
성능 비교표
XGBoost vs LightGBM
Level-wise tree growth vs Leaf-wise tree growth
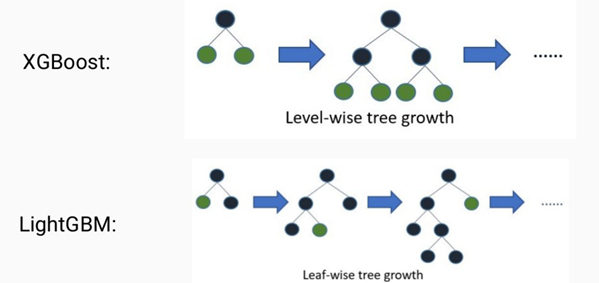
두 방식이 궁극적으로 추구하는 tree model의 성능은 동일함. 다만, 그 tree를 찾아가는 방식에서의 차이점!
Level-wise tree growth, where you find the best possible node to split and you split that one level down. This strategy will result in symmetric trees, where every node in a level will have child nodes resulting in an additional layer of depth.
XGBoost의 경우, split하기 위한 best possible node를 찾으며, 전체적인 트리의 깊이를 줄이고 균형있게 만들기 위해서 root 노드와 가까운 노드를 우선적으로 순회하여 level-wise한 성장
In LightGBM, the leaf-wise tree growth finds the leaves which will reduce the loss the maximum, and split only that leaf and not bother with the rest of the leaves in the same level. This results in an asymmetrical tree where subsequent splitting can very well happen only on one side of the tree.
이와 달리 LGBM의 경우, loss 변화가 가장 큰 노드에서 분할하여 성장하는 leaf-wise한 성장. 비대칭적인 트리를 생성하지만 loss 변화를 기준으로 분할하기 때문에 level-wise에 비해 예측 오류손실이 작거나 빠르게 도달
수평적 분할이 아닌 수직적 분할을 통해, 빠른 학습시간을 보이지만, 데이터셋이 적은 경우 overfitting의 위험
