ML 6) Ensemble
ML 포스팅은 한학기동안 머신러닝 스터디를 하며 공부한 내용을 바탕으로 하였으며,

O’Reilly Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition을 기반으로 하고 있습니다.
1편) What is Machine Learning?
2편) Linear Regression, Gradient Descent
3편) Regularization, Logistic Regression
4편) SVM
5편) Decision Tree
6편) Ensemble
7편) Dimension Reduction
앙상블 학습(Ensemble Learning)
여러 개의 예측 모델을 생성하고, 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법
강력한 하나의 모델을 사용하는 대신 보다 약하더라도 모델 여러개를 조합하여 더 정확한 예측에 도움을 주는 일종의 집단 지성을 이용하여 문제를 해결하는 방식
앙상블 학습 유형
1) Voting 2) Bagging 3) Boosting 4) Stacking
1) Voting
여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
서로 다른 알고리즘을 여러 개 결합하여 사용
- Hard voting
다수의 분류기가 예측한 결과값을 최종 결과로 선정 - Soft voting
모든 분류기가 예측한 레이블 값의 결정 확률 평균을 구한 뒤 가장 확률이 높은 레이블 값을 최종 결과로
결합하는 모델들이 서로 독립적일수록(즉, 서로 다른 모델을 사용할 수록), 높은 성능
서로 다른 종류의 오차를 만들기 때문에 이 오차를 최소화하는 ensemble 효과 극대화
2) Bagging!
voting과 bagging의 차이
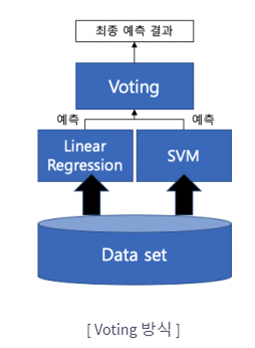 Voting – 동일한 데이터셋에 대해 서로 다른 알고리즘
Voting – 동일한 데이터셋에 대해 서로 다른 알고리즘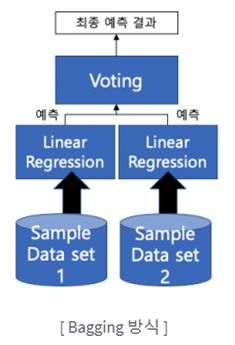 Bagging – 같은 알고리즘을 사용하지만, Train dataset을 분할(무작위, 중복 허용)
Bagging – 같은 알고리즘을 사용하지만, Train dataset을 분할(무작위, 중복 허용)
(중복을 허용하지 않는 경우를 페이스팅(Pasting)이라고 함)
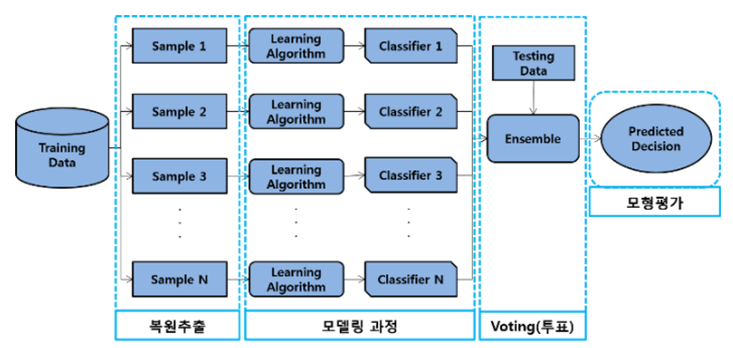 개별 모델의 편향과 분산은 앙상블을 통해 감소 – 병렬 연산을 통한 효율성 up
개별 모델의 편향과 분산은 앙상블을 통해 감소 – 병렬 연산을 통한 효율성 up
Out-of-Bag 평가
반복 추출 방법을 사용하기 때문에 같은 표본이 한 데이터에서 여러분 추출될 수도, 혹은 한번도 추출되지 않은 데이터(out-of-bags) 샘플도 존재함
N개의 표본을 단순확률 반복추출하게 될 경우
각 데이터가 뽑힐 확률
N이 충분히 크다면 위의 식은 다음의 상수값으로 수렴
즉, 37%의 선택되지 않은 샘플들을 oob샘플들이라고 부르며, 이 샘플들은 각각의 분류모델마다 모두 다름.
이 37%의 분류모델을 validation에 활용할 수 있으며, 각 모델의 oob 샘플에 대한 평가를 평균내어 score로 활용
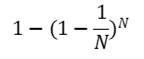
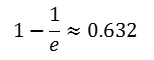
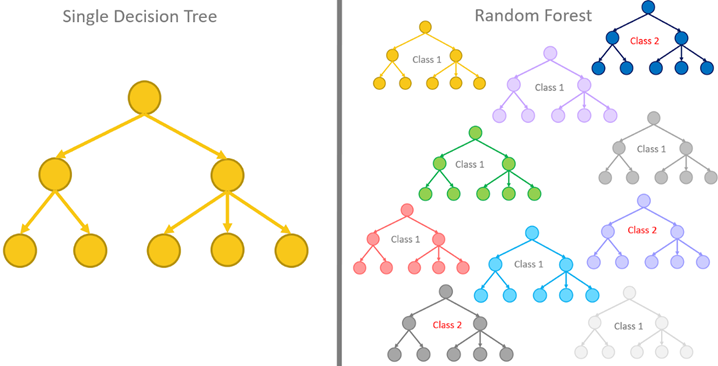
3) Random Forest
배깅(페이스팅)을 적용한 Decision Tree의 ensemble
트리의 노드 분할 시 전체 특성 중에서 최선의 특성을 찾는 대신 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 방식으로 무작위성을 더 부여함
- 각 트리의 다양성을 높여, 편향은 늘어나지만, 분산을 낮추어 전체적으로 모델의 성능 개선
Feature Importance
랜덤 포레스트의 장점 – 특성의 상대적 중요도를 측정하기에 용이함
특정한 특성을 사용하 노드가 평균적으로 불순도를 얼마나 감소시키는 지를 확인하여, 점수화
확률값으로 변환(중요도 전체합이 1이 되도록)
