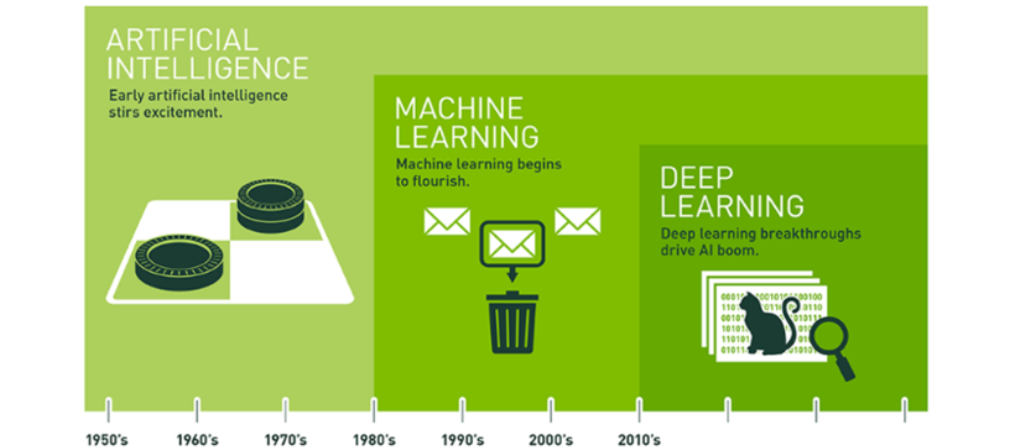
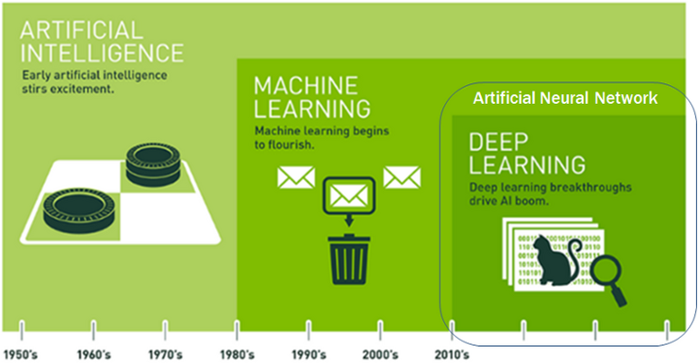
안녕하세요! 올해들어 본격적으로 Data Science를 공부를 시작하면서, 항상 구글링을 하며 접하게 되는 블로그 글들을 보며, 막연하게 나도 저런 블로그를 가져보고 싶다라고 생각만 하다가, 여름방학을 맞이해 직접 계획에 옮기기로 결심했으나.. 계절학기로 인해 미루고 미루다가 이제서야 첫 글을 작성하게 되네요 ㅠㅠ(반성중)
지난 한학기동안 공부한 ML, 추천시스템, NLP 등에 대한 복습과 함께 앞으로 공부하게 될 강화학습, CV, 알고리즘 등에 대해서도 꾸준하게 연재할 계획입니다.
.
.
.
.
ML 1) What is Machine Learning?
ML 포스팅은 한학기동안 머신러닝 스터디를 하며 공부한 내용을 바탕으로 하였으며,

O’Reilly Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition을 기반으로 하고 있습니다.
1편) What is Machine Learning?
2편) Linear Regression, Gradient Descent
3편) Regularization, Logistic Regression
4편) SVM
5편) Decision Tree
6편) Ensemble
7편) Dimension Reduction
ML 분류
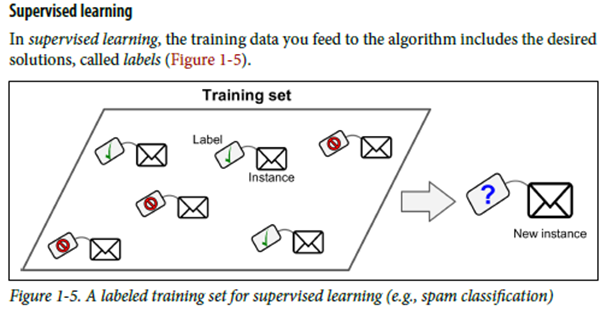
1) 지도학습 / 비지도 학습 / 준지도 학습 / 강화학습
- 학습 동안의 감독 형태나 정보량에 따라
2) 온라인 학습 / 배치 학습
- 입력 데이터의 스트림으로부터 점진적으로 학습 할 수 있는지의 여부에 따라
3) 사례기반 학습 / 모델 기반 학습
- 기존 데이터와 새 데이터 비교 / 훈련 데이터셋에서 패턴 발견 -> 새로운 예측 모델
1. Supervised Learning(지도학습)
Classification
ex) 스팸 메일 필터
Regression
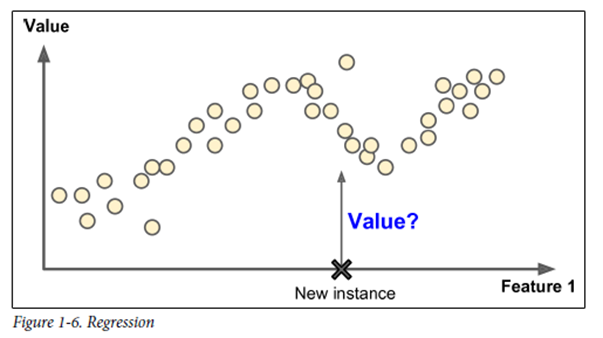
예측변수(Predictor variable)라 부르는 특성(feature)를 사용해 타킷 수치(taget)를 예측
ex)
- K nearest neighbors(KNN)
- 선형회귀(Linear Regression)
- 로지스틱 회귀(Logistic Regression)
- 서포트벡터 머신(SVM)
- Decesion Tree
2. Unsupervised Learning(비지도학습)
레이블이 없는 훈련데이터
군집(Clustering)
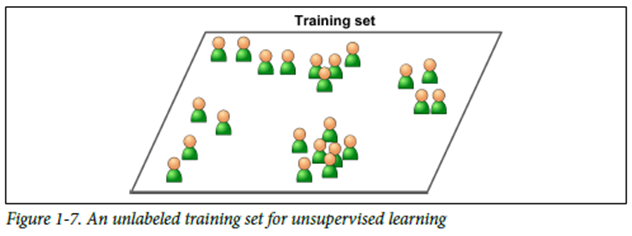
- K-means
- 계층군집분석
- 이상치 탐지, 특이치 탐지
- 원-클래스 SVM
- Isolation Forest
시각화, 차원축소
- PCA(주성분 분석)
- 커널 PCA
- 지역적 선형 임베딩(LLE – Locally linear Embedding)
- T-SNE(t-distributed stochastic neighbor embedding)
3. Reinforcement Learning(강화학습)
학습하는 시스템 – 에이전트
환경을 관찰해서 행동을 실행하고 그 결과로 보상 혹은 벌점을 받음
시간이 지남에 따라 가장 큰 보상을 얻기 위해 정책이라고 부르는 최상의 전략을 스스로 학습.
정책(Policy)를 통해 주어진 상황에서 에이전트가 어떤 행동을 선택해야 할지 정의!
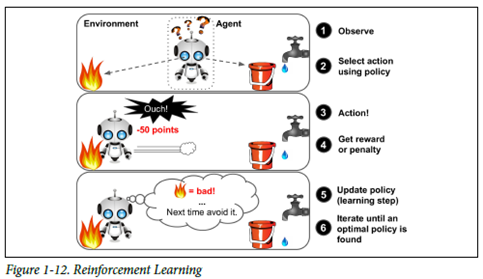
4. What to Consider in Machine Learing
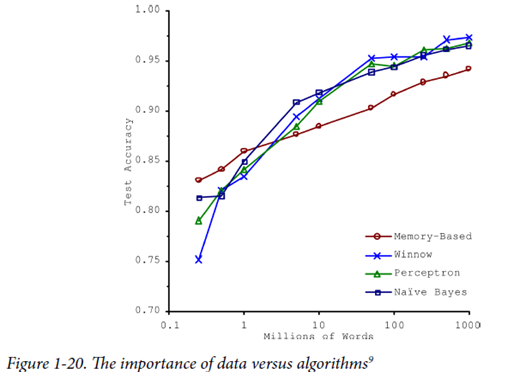
1. 데이터의 양
Trade off - 데이터의 양과 알고리즘 사이의 반비례 관계
시간과 돈을 알고리즘 개발에 쓰는 것과 데이터 확보에 사용하는 것 사이의 트레이드 오프 -> 데이터의 양이 증가함에 따라 Test Accuracy는 당연히 증가하지만, 그 과정에서 많은 시간과 비용이 들기 때문에, 적정선을 찾아야 함. 솔직히 지금 단계에서는 크게 와닿지 않는 개념이지만 실무에서는 중요할것 같다고 생각이 듭니다.
2. Train data의 대표성
일반화가 잘되기 위해선 일반화하기 원하는 새로운 사례들을 훈련 데이터가 잘 대표하도록 해야함!
대표성이 없는 훈련 데이터를 사용했을 경우, 모델이 정확한 예측을 하지 못할 수 있다! 이런 내용들을 접할 때마다 응통 표본추출이론 이런 수업을 들어보고 싶다는 생각이 들지만... 대체로 생각에만 머물게 되네요(ㅋㅋㅋㅋㅋ쿠ㅜㅜㅜ)
샘플링 잡음(Sampling noise) – 샘플이 적은 경우. 우연에 의한 대표성 없는 데이터로 학습하게 됨
샘플링 편향(Sampling bias) – 표본 추출 방법이 잘못되어 대표성을 띄지 못하는 경우
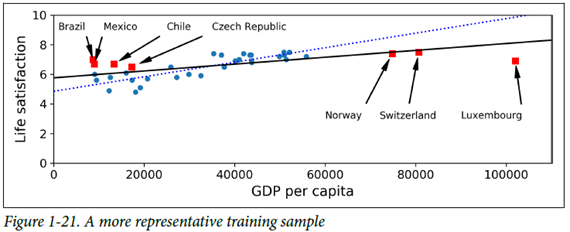
3. 데이터 전처리
훈련데이터에 에러, 이상치(Outlier), 잡음이 많은은 경우
따라서 데이터의 전처리가 필수적임!
4. 관련 없는 특성
특성 공학(Feature Engineering) : 훈련에 사용할 좋은 특성들을 찾는 과정
특성 선택(Feature selection) – 가지고 있는 특성 중에 훈련에 가장 유용한 특성 선택
특성 추출(Feature extraction) – 특성을 결합하여 더 유용한 특성 생성 ex) 차원축소 알고리즘
5. 훈련 데이터 과대 적합(Overfitting)
훈련 데이터에 있는 잡음의 양에 비해 모델이 너무 복잡할 때 발생하는 문제
데이터셋의 작은 잡음 패턴 하나하나에 과도하게 fit되기 때문에, 혹은 데이터셋 자체의 양이 부족하기 때문에 새로운 샘플이 들어왔을 때 이를 일반화하지 못하는 문제 발생! 해결방법은?
- 파라미터 수가 적은 모델 선택(고차원 다항 모델보다는 선형 모델)
- 훈련 데이터에 있는 특성 수를 줄이거나, 모델에 제약을 가하여 단순화
- 훈련 데이터 추가
- 훈련 데이터의 잡음을 해결(오류 데이터, 이상치 데이터 제거)
규제(regularization) ex) 선형 모델의 경우 기울기를 0이 되도록 강제하면 평균에 가까워짐
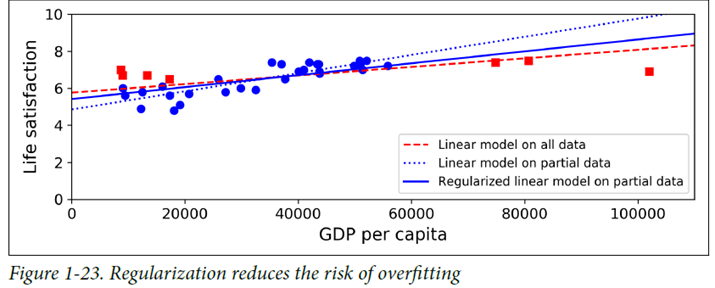
규제의 정도는 모델 설계자가 설정하는 하이퍼파라미터(Hyperparameter)
데이터에 완벽히 맞추는 것과 일반화를 위해 단순함을 강제하는 것 사이의 올바른 균형을 찾는 것이 중요!
6. 훈련 데이터 과소 적합(Underfitting)
모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 발생
해결방법
- 모델 파라미터가 더 많은 강력한 모델 선택
- 학습 알고리즘에 더 좋은 특성 제공(Feature Engineering)
- 모델의 제약을 줄임(규제 하이퍼파라미터 감소)
7. 테스트와 검정
Train data, Test data split을 통해 일반화 오류 즉, 새로운 샘플에 대한 오류 비율(Generalization error, out-of-smaple error)를 구함 -> 추정값
훈련오차가 낮지만 일반화 오차가 높다면 Overfitting 되었다는 뜻
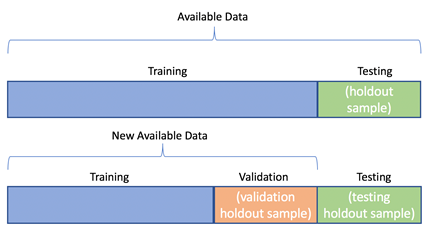
8. 하이퍼파라미터 튜닝과 모델 선택
일반화 오차를 테스트 세트에서 여러 번 측정했기 때문에 모델과 하이퍼 파라미터가 테스트 세트에 최적화된 모델을 만들게 되면, 실제 서비스 혹은 새로운 데이터에 잘 작동하지 않을 수 잇음
해결방법
홀드아웃 검증(Holdout validation)
훈련세트의 일부를 떼어내어 여러 후보 모델을 평가하고 가장 좋은 하나를 선택
이를 검증세트(Validation set)이라고 부름
다양한 하이퍼 파라미터 값을 가진 여러 모델을 훈련 -> Validation set에서 가장 높은 성능을 내는 모델을 선택 -> 홀드아웃 검증 과정이 끝났으므로, 이 최선의 모델을 사용해서 검증세트를 포함하여 다시 훈련하여 최종 모델 도출 -> 최종 모델을 테스트 세트에서 평가
- 교차 검증 (cross-validation)
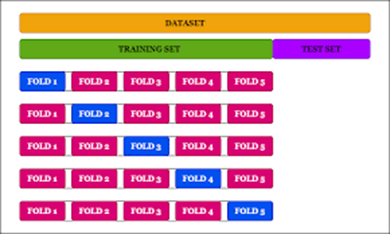
작은 검증 세트 여러 개를 사용해 반복적인 교차 검증 수행 -> 검증 세트마다의 모델의 평가를 평균내어 훨씬더 정확하고 객관적으로 모델 성능 측정 가능
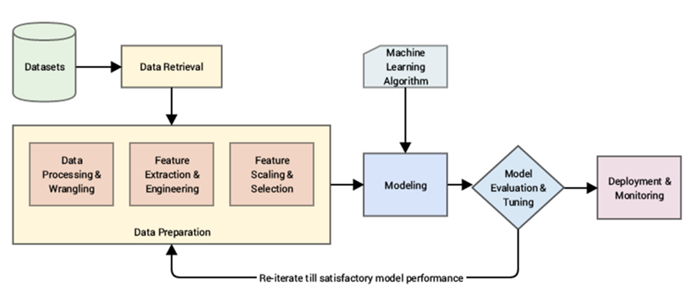
9. 머신러닝 Workflow