DescEmb : Unifying Heterogeneous Electronic Health Records Systems via Text-Based Code Embedding
medical NLP paper review
목록 보기
3/8
Background
- EHR의 상당한 증가로 헬스케어(의료) 예측 분야에 상당한 발전을 이루었다. 하지만 이질적인 EHR 형식은 이 발전을 저해하는 장벽임. 그렇기에 Description-based Embedding(DescEmb)를 도입하여 이를 해결하고자 함.
Introduction
- 기존의 code-based 임베딩은 다양한 병원으로 부터 그리고 이질적인 형식의 EHR을 수집하여 모델을 트레이닝하는 것은 한계가 있음. 본 논문에서는 code-agnostic text-based representation을 해결책으로 제시.
- CodeEmb vs DescEmb : DescEmb는 Code description을 가지고 semantic적으로 접근하여 Neural Text Encoder를 통하여 임베딩.
- MIMIC-3, eICU 사용 (전혀 다른 medical code systems)
- CodeEmb의 가장 좋은 성능보다 뛰어난 성능을 보임.
Method
- CodeEmb가 코드를 바로 임베딩 후 prediction을 진행하는 반면, DescEmb는 여러 w로 구성된 d(text description)를 shared text Encoder에 넣어 나온 상태 z (Description Representations)을 가지고 Prediction을 진행.
- 텍스트 encoder B는 description을 z로 변환할 수 있는 적절한 모델 어느 것이나 사용해도 되고, 본 논문에서는 Bi-RNN, BERT 두가지를 사용.
- Value Embedding : description에 나타난 숫자들은 약의 복용량이나 혈압 등과 같이 아주 귀중한 정보를 가지는 경우가 많음. 따라서 DescEmb는 Description을 통해 Value Embedding을 진행할 수 있다는 장점이 있음. (4가지 방법을 제시, VA->DVA->DVA+DE(단점 보완과정), Value Concatenated)
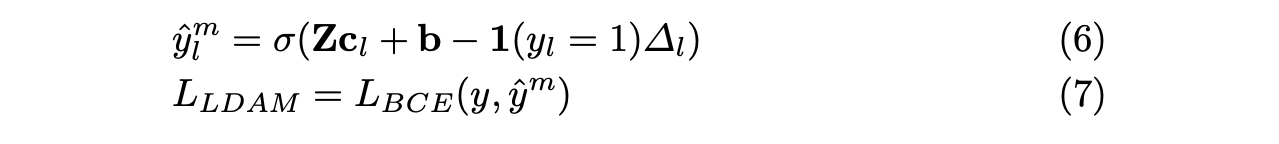
Data
- MIMIC-3, eICU, they are recored based on completely different code structures throughout the data.
Task for Experiments
- Readmission Prediction ( Binary Prediction )
- Mortality Prediction ( Binary Prediction )
- LOS (length of stay) Prediction ( Binary Prediction )
- Diagnosis Prediction ( Multi-label Prediction )
Result
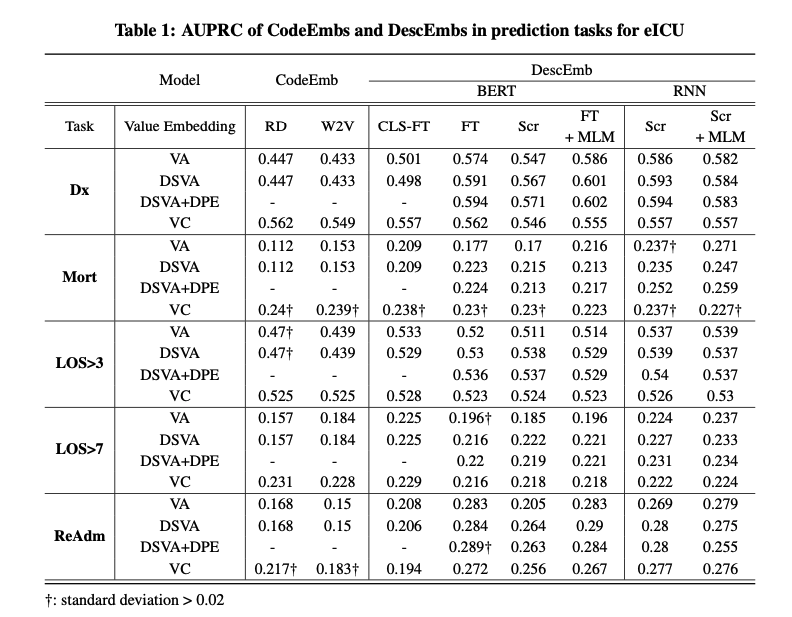
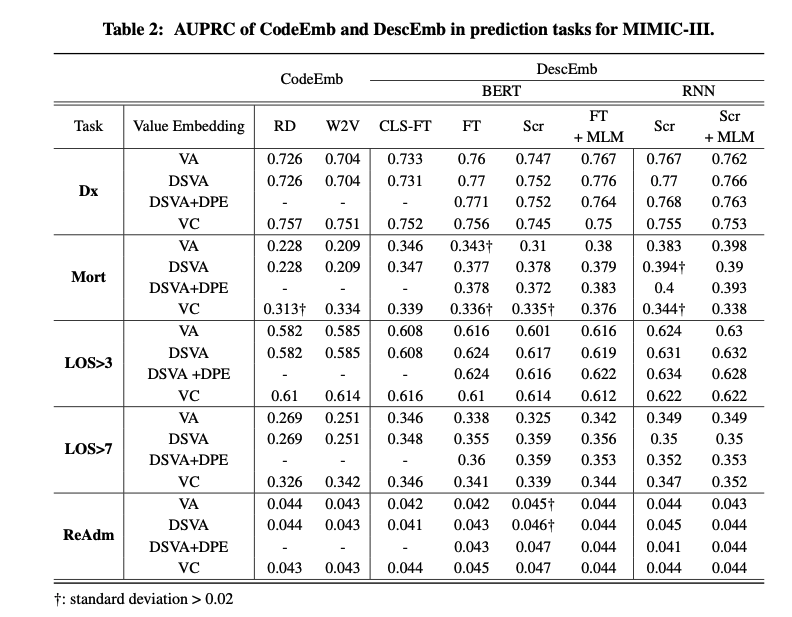
- pre-training at code-level is insufficient to fully capture the semantics of each code and sometimes harms the performance.
- 반면, all pre-trained DescEmb models은 안정적으로 모든 테스트에서 높은 성능을 보여주었고 이는 the robustness of pre-training at description-level을 의미한다고 할 수 있음.
- CodeEmb을 zero-shot, few-shot으로 transfer setting한 descemb가 좋은 성능을 냄. 특히 LOS테스크에서 small few-shot한 모델이 좋은 성능을 보임. 이는 DescEmb가 아주 작은 데이터를 가진 병원에서도 유사한 성능을 내면서 다른 병원으로 전이 될 수 있음을 의미. ( DescEmb의 code-agnostic nature덕분에, zero-shot and few-shot transfer learning performance를 향상시킬 수 있다. )
- CodeEmb에는 VC가 가장 좋은 방법이었고, DescEmb에는 DSVA+DPE가 가장 좋은 방법.
- DescEmb를 이용한 pooled learning의 효율성 덕분에, DescEmb는 large scale predictive models의 새로운 영역을 개척했다고 할 수 있음.

타인에게 영감을 주는 것을 애정합니다. 그래서 책을 내고 싶습니다. 이 꿈을 위한 조각들을 아카이빙합니다.
Great article on unifying heterogeneous electronic health records systems through text-based code embedding! The innovative approach of DescEmb holds significant promise for improving interoperability in healthcare data. For more insights into healthcare data management, check out this informative article: https://www.cleveroad.com/blog/healthcare-data-storage/.