medical NLP paper review
1.BEHRT : Transformer for Electronic Health Records(EHRs)
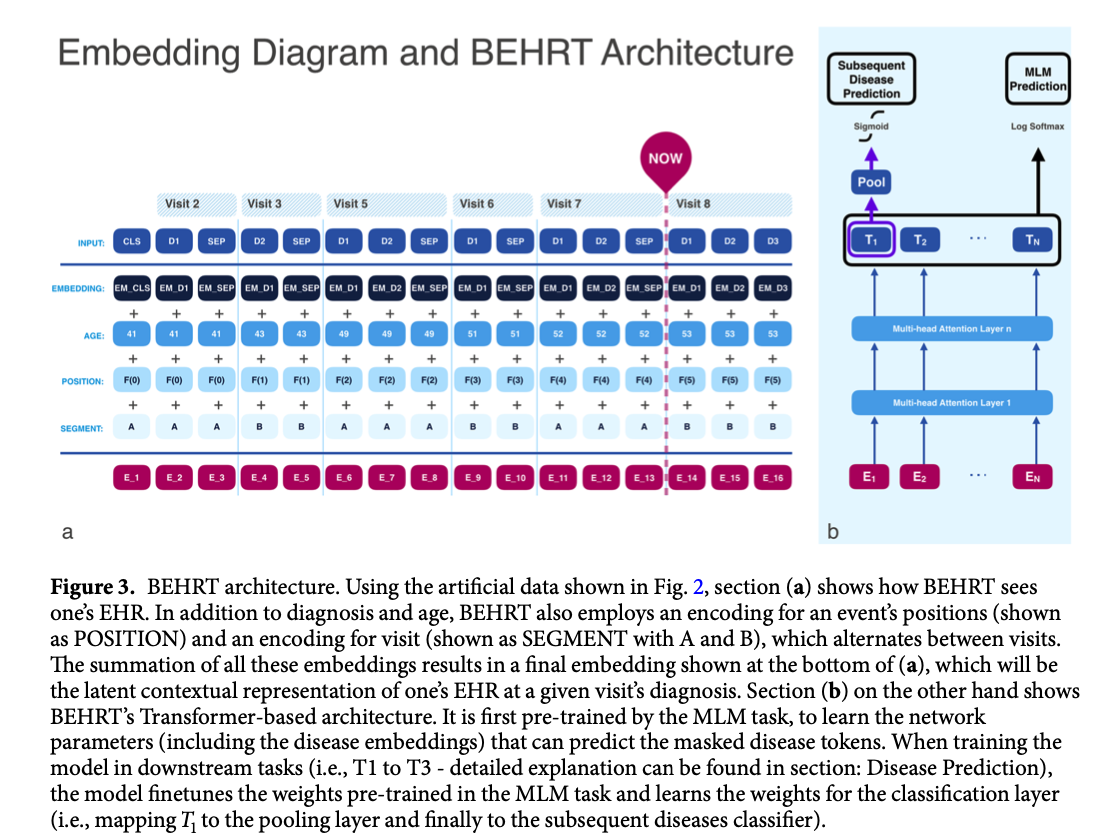
Introduction 최근 딥러닝의 발전과 EHR와 같은 Biomedical data의 증폭은 다양한 의료분야에서 personalised predictions쪽으로 엄청난 발전을 가져옴. 이러한 발전은 events간의 Long-term dependency를 포착할
2.Med-BERT : pre-trained contextualized embeddings on large-scale structured electronic health records for disease prediction
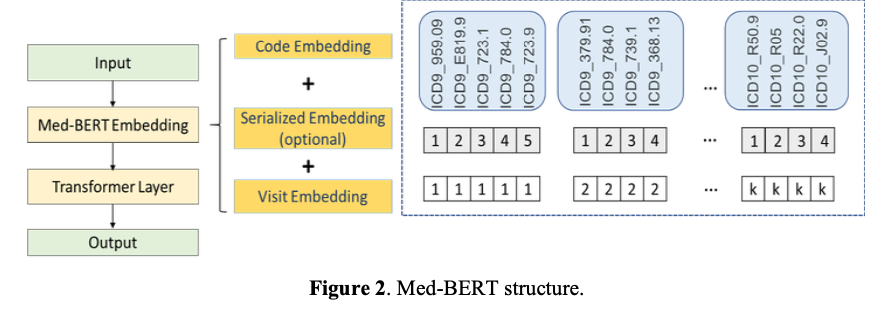
전자 의료 기록은 text와 유사하기에, transformer의 bidirectional encoder 구조로 nlp분야의 많은 발전을 가져온 pre-training BERT에서 EHR을 가지고 fine tuning 시키면 EHR기반 predictive modeling
3.DescEmb : Unifying Heterogeneous Electronic Health Records Systems via Text-Based Code Embedding
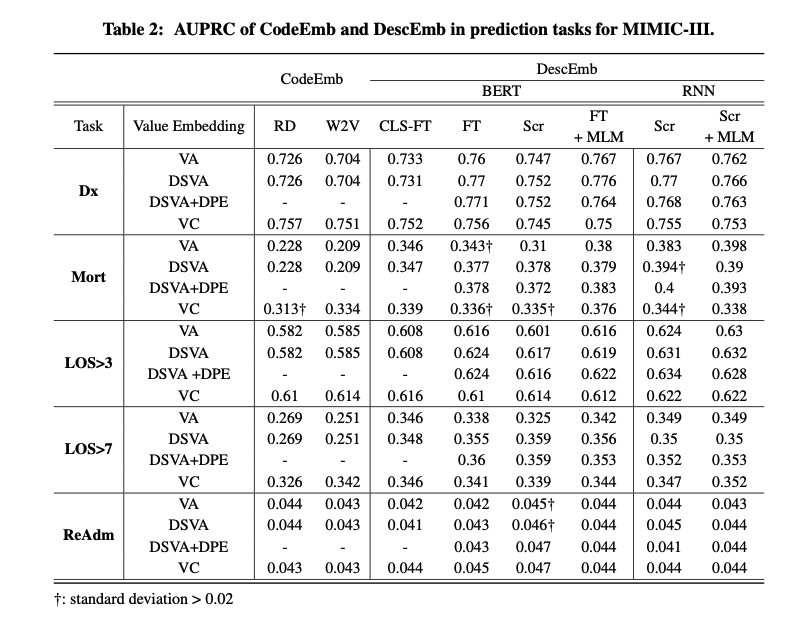
EHR의 상당한 증가로 헬스케어(의료) 예측 분야에 상당한 발전을 이루었다. 하지만 이질적인 EHR 형식은 이 발전을 저해하는 장벽임. 그렇기에 Description-based Embedding(DescEmb)를 도입하여 이를 해결하고자 함.기존의 code-based
4.Clinical BERT : Publicly Available Clinical BERT Embeddings
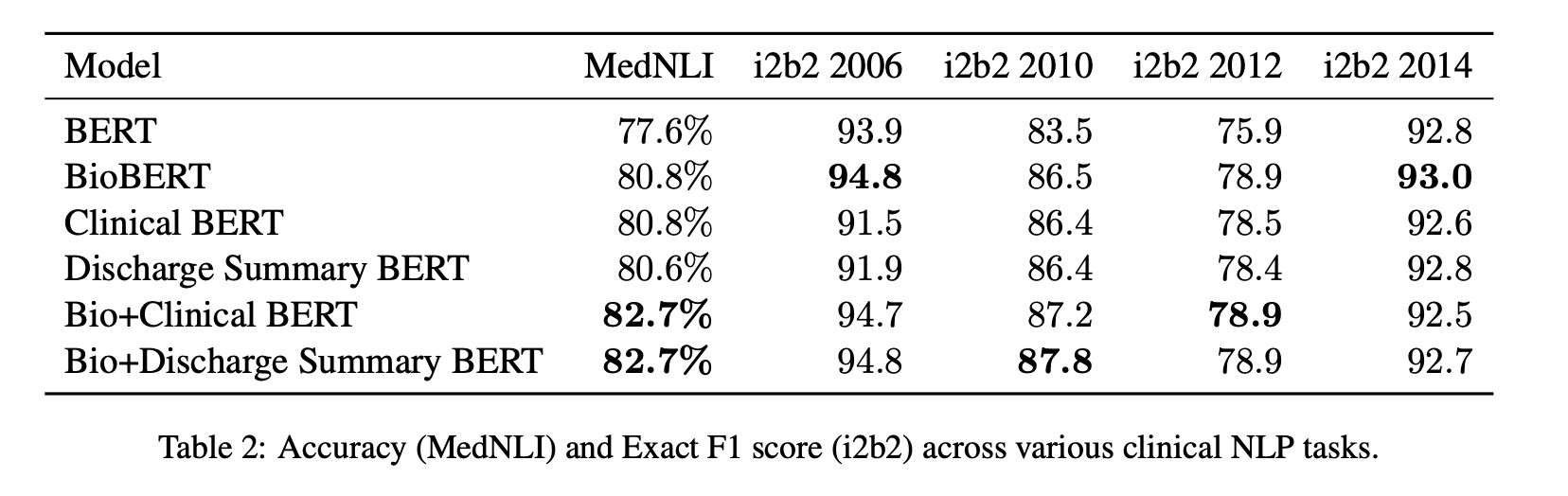
의료용 narratives은 일반적인 텍스트, 그리고 non-clinical, non-biomedical 텍스트와 차이가 있기 때문에, 의료용 task를 수행할 때 specialized clinical BERT model이 필요로 함.기존 BERT(original)에서
5.LAAT : A Label Attention Model for ICD Coding from Clinical Text
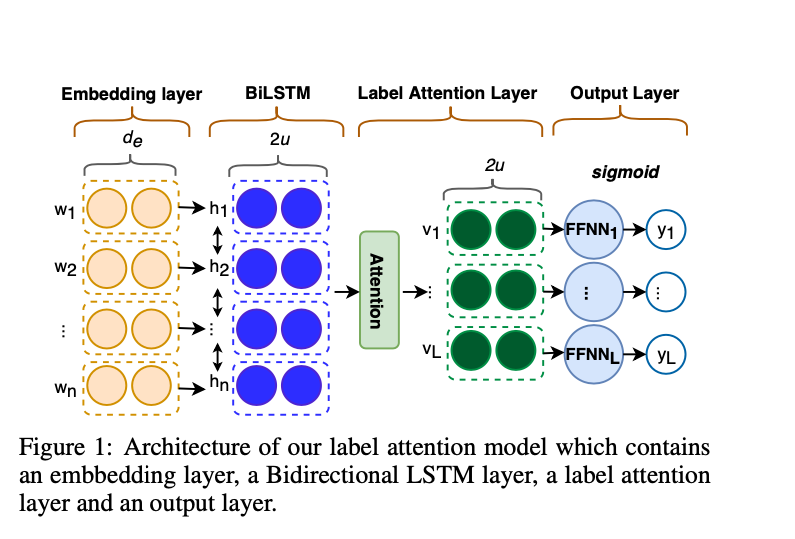
ICD coding : clinical notes들과 같은 patient's visit data를 ICD code로 classification하는 과정.수동 ICD coding은 사람에 따라 다른 판단을 할 수 있기에 prone to human errors하고, 많은
6.TransICD : Transformer Based Code-wise Attention Model for Explainable ICD Coding

현재 문제점a. ICD codes를 clinical note에 수동적으로 부여하는 것은 아주 비효율적이며 많은 에러를 야기시킬 확률이 큼.b. 게다가 Training skilled coders작업은 많은 시간과 노력을 필요로 함.c. 위 두가지 이유로, automati
7.DLAC : Description-based Label Attention Classifier for Explainable ICD-9 Classification

ICD-9 coding => text classification problem. 이 task에 대해서 이 논문에서 description-based label attention classifier(DLAC) 제안.DLAC는 transformer-based encoders
8.통합 정리 : A Unified Review of Deep Learning for Automated Medical Coding ( 사례별 논문 정리 )
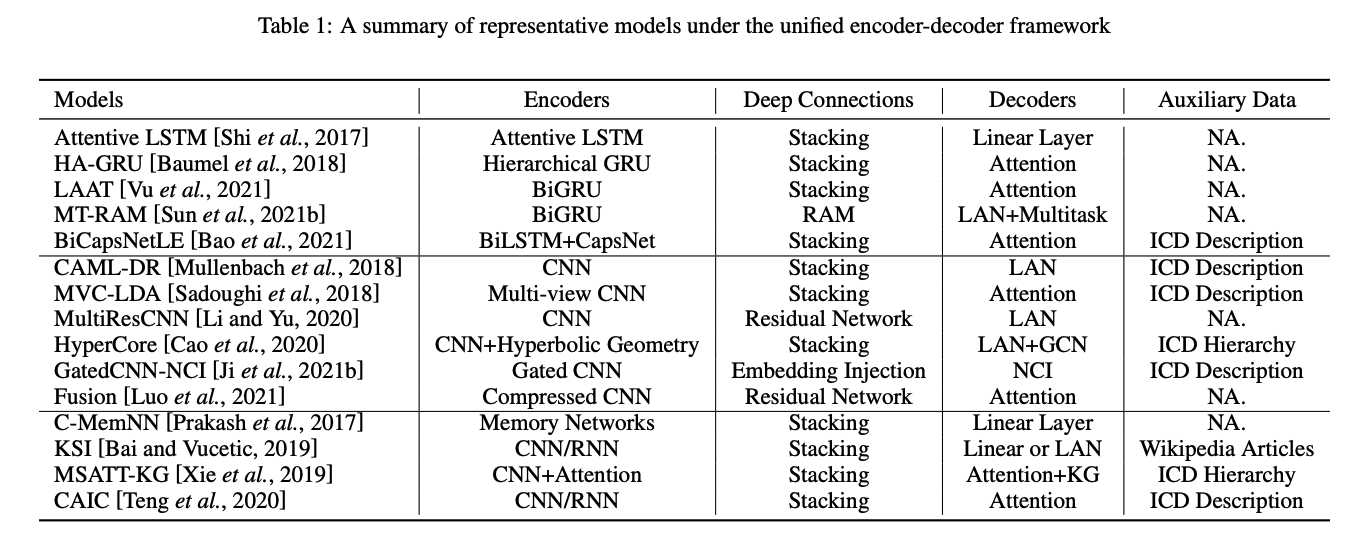
최근 딥러닝 발전으로 medical coding을 위한 구조가 많이 나오고 있지만, unifed view가 부족한 상황본 논문에서 다음 4개의 항목으로 나누어 unified framework 제시a. encoder modules for text feature extra