통합 정리 : A Unified Review of Deep Learning for Automated Medical Coding ( 사례별 논문 정리 )
medical NLP paper review
목록 보기
8/8
Introduction
- 최근 딥러닝 발전으로 medical coding을 위한 구조가 많이 나오고 있지만, unifed view가 부족한 상황
- 본 논문에서 다음 4개의 항목으로 나누어 unified framework 제시
a. encoder modules for text feature extraction
b. mechanisms for building deep encoder architectures
c. decoder modules for transforming hidden representations into medical codes
d. the usage of auxiliary information. - medical text를 다루고 automated 코딩하는데 있어 문제점
a. Noisy and Lengthy Clinical Notes
b. large-scale Imbalanced Medical Codes
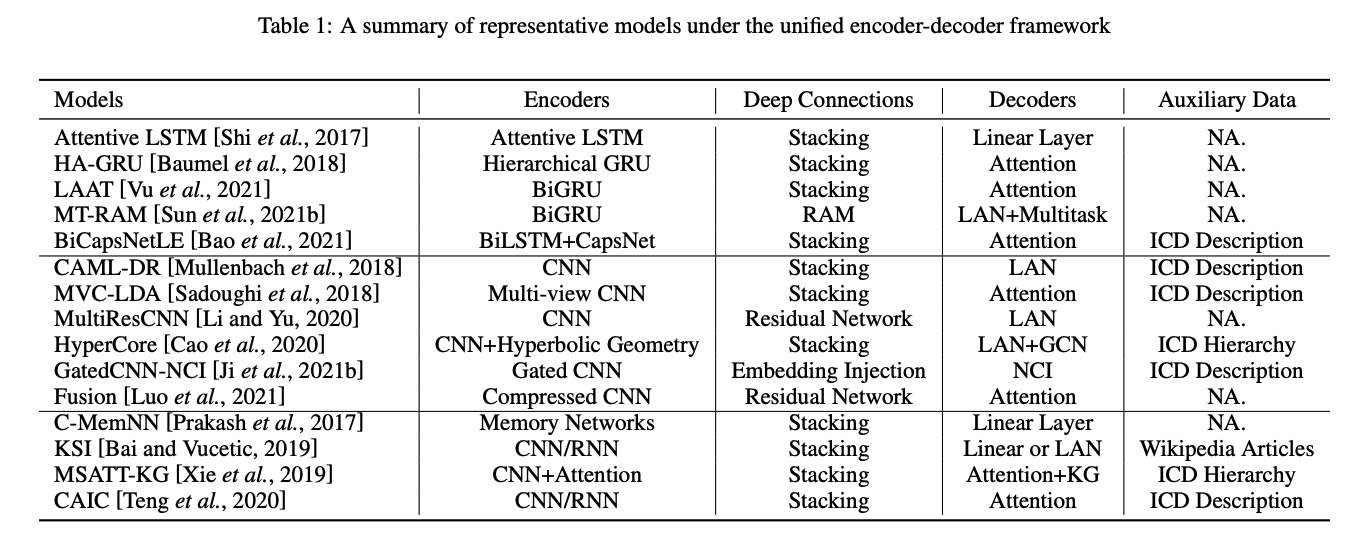
A Unified Encoder-Decoder Framework
- Encoder Modules
Recurrent Neural Encoders
- Attentive LSTM network [Shi et al.,[2017]]
- simplified gated recurrent unit with bi-direction[Mullenbach et al.[2018]]
- HA-GRU [Baumel et al,[2018]], HLAN[DONG et al, [2021]]
Convolutional neural encoders
- TextCNN[Kim,[2014]]
- CAML[Mullenbach et al, [2018]]
it combines multiple-filter CNN-based text encoders and an attention decoder- DCAN[Ji et al, [2020]]
- MultiResCNN[LI and Yu, [2020]]
- MVC-LDA[[Sadoughi et al,[2018]]
- Gated CNN encoder [Ji et al, [2021]] : uses an LSTM-style gating - mechanism to control the information flow.
- Fusion model [Luo et al, [2021]] : Compressed CNN module that applies an attention-based soft-pooling over the features of word convolution, which reduces the # of word representations.
Neural Attention Mechanism
- TransICD[Biswas et al,[2021]] : apply transformer text encoder and structured self-attention to learn representations.
- BERT-XML[Zhang et al,[2020]] : combines BERT encoders with multi-label attention.
- Longformer[Feucht et al,[2021]] : better than BERT.
- 아직까지 long documents and keywords를 인코딩 할 때의 BERT의 한계 때문에 아직은 CNN, RNN based 모델들보다 높은 성능을 내진 못함. (Gas et al,[2021])
Hierarchical Encoders
- Shi et al, 2017 : hierarchical encoder
- Dong et al, 2021 : attention networks with label-wise word-level and sentence-level representations
- Ji et al, 2021 : BERT text encoder가 long clinical notes에 대해서 경쟁력있기 위해서 BERT + hier 결합시킴.
- 이 또한 아직까지 a), b)보다 높은 성능을 내지는 못함.
- Building Deep Architectures
stacking different neural blocks into Depp networks
- recalibrated aggregation module with multiple convolutional layers, [Sun et al 2021]
- densely connection convolutional layers and multi-scale feature attention : MSATT-KG [Xie et al,[2019]]
- capsule neural network upon the BiLSTM layer : BiCapsNetLE[Bao et al,[2021]]
Embedding injection
- [ji et al,[2021]]
Residual Connection
- 스킵 커넥션을 도입해서 vanishing gradient 현상을 막아주는 효과를 냄.
- 이는 아주 깊은 neural network architectures를 만들 수 있게 해줌.
- MultiResCNN [Li and Yu,[2020]] : combine residual learning with concatenation of multiple channels with different convolutional filters.
- DCAN, Fusion 논문
- Decoder Modules
Fully Connected Layer
- Attentive LSTM[Shi et al,[2017]]
- C-MemNN[Prakash et al,[[2017]]
Neural Attention Decoders
- Label-wise Attention Network(LAN)
- CAML[Mullenbach et al,[2018]]
- DCAN[Ji et al,[2020]]
- MultiResCNN[Li and Yu,[2020]]
- LAAT[Vu et al,[2021]]
- TransICD[Biswas et al,[2021]]
Hierarchical Decoders
- de Lima et al,[1998]]
- JointLAAT[Vu et al,[2021]]
Multitask Decoders
- MT-RAM[Sun et al,[2021]] : ICD and CCS code prediction
- MARN[Sun et al,[2021]]
- Usage of Auxiliary Information (external Knowledge sources)
Wikipedia Articles
- Prakash et al, 2017 : C-MemNN
- KSI[Bai and Vucetic,[2019]]
Code Description
- CAIC[Teng et al,[2020]]
- GatedCNN-NCI[Ji et al,[2021]]
- BiCapsNetLe[Bao et al,[2021]]
- DLAC[Feucht et al,[2021]]
Code Hierarchy
- MSATT-KG[Xie. et al,[2019]]
- HyperCore[Cao et al,[2020]] : GCN
Data
- MIMIC database is popular data source.
- CodiEsp ( in Spanish )
- Private in-house patient notes.
Discussion
- Clinical Relatedness : 아직 불완전함 => can be clinical knowledge infusion into the neural encoders
- Class Imbalance and hierarchical Decoding
- Long-term Dependency and Scalability
- Interpretability
- Updated Guidelines and Data Shift

타인에게 영감을 주는 것을 애정합니다. 그래서 책을 내고 싶습니다. 이 꿈을 위한 조각들을 아카이빙합니다.