DLAC : Description-based Label Attention Classifier for Explainable ICD-9 Classification
medical NLP paper review
Introduction
- ICD-9 coding => text classification problem. 이 task에 대해서 이 논문에서 description-based label attention classifier(DLAC) 제안.
- DLAC는 transformer-based encoders를 적용한 모델.
- Research Question
a. Which transformer-based encoder is best suited for ICD-9 coding?
b. How does our proposed description-based label attention classifier perform on ICD-9 coding?
c. To which extent can the DLAC provide explainable predictions for ICD-9 codes?
Method
-
input : each tokenized discharge summary
-
Structure of DLAC
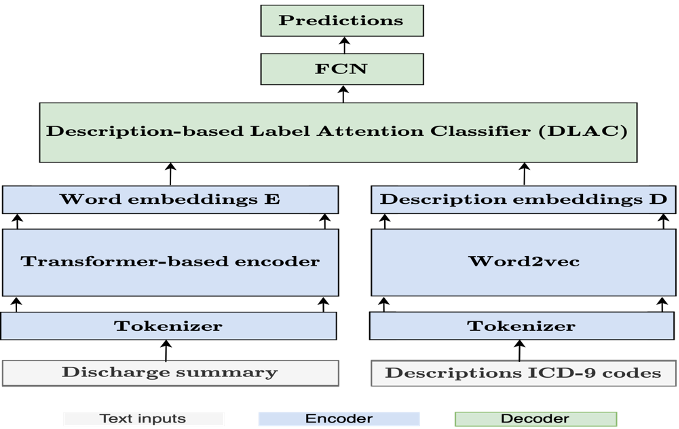
-
Description-based Label Attention
a. Discharge summary -> transformer-based encoder : E
b. Descriptions ICD-9 codes -> Word2vec : D
c. Attention Matrix : A = softmax(EU @ D^T)
d. contextual embedding matrix : C = E^T @ A
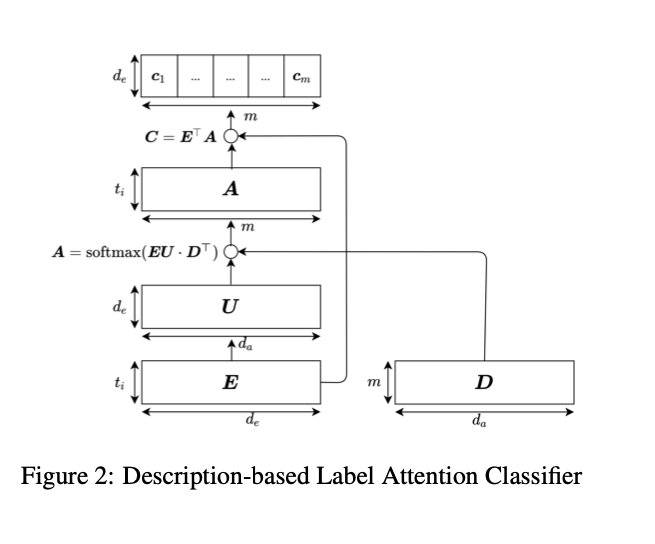
-
Classification
a. 위에서 도출해낸 C(label specific contextual embedding)를 FCN에 feed하고 sigmoid 함수를 적용함. Train과정에서 loss함수는 BCE를 사용함. -
Transformer-based Encoders
a. DLAC는 Encode에 대해 agnostic하므로, 여러가지 transformer-based encoder를 사용하여 실험을 진행함.
b. BERT_BASE, hierarchical BERT_BASE, Longformer_BASE 세가지를 이용하여 실험을 진행.
c. Longformer 모델 같은 경우, 인풋 길이 제한의 한계를 극복할 수 있음.( by offering a sparsified self-attention mechanism ) (BERT => up to 512 tokens, Longformer => up to 4096 tokens)
Data
- MIMIC-3 이용 ( MIMIC-3-50 ) : discharge summaries containing 50 most frequent ICD-9 codes
- Preprocessing : lowercase all tokens, remove punctuations, remove numerical tokens-only.
- Training : 8066, Validation : 1573, test : 1729
Experiments
- 인코더로 BERT, hierarchical BERT, Longformer 사용.
- baseline classifier로 LRC 사용, LRC는 DLAC와 다르게 description embeddings D 을 취하지 않음.
- Adam optimizer 사용.
- lr = 1.41*10^(-5), batch size = 64, dropout p = 0.1, early stopping 적용.
Result
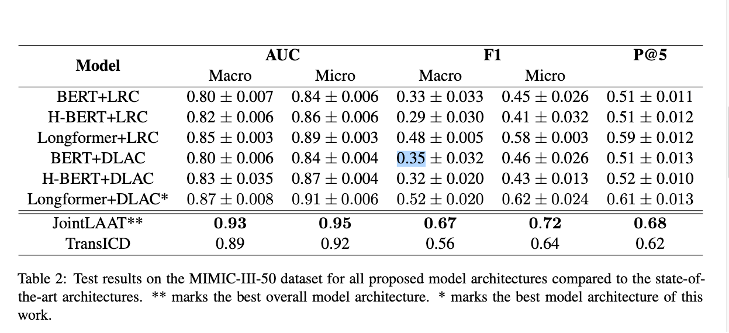
- Longformer+DLAC 모델이 이번 실험에서 진행했던 구조들 중 가장 우수한 성능을 냄.
- Answer for Research Questions
Which transformer-based encoder is best suited for ICD-9 coding?
- LRC classifier와 접목시킨 transformer-based encoder 중 Longformer가 가장 우수한 성능을 냈는데, 이는 긴 문장이 대부분을 차지하는 discharge summaries를 길이 제한을 가진 BERT가 중요한 정보를 제대로 취하지 못함을 보여줌.
- H-BERT+LRC가 F1 Macro, Micro 모두에서 BERT+LRC보다도 좋지 못한 성능을 보였는데, 이는 k개의 청크를 mean pooling을 이용하여 집계하는 방법이 차선책이므로 모델이 입력에 대해서 풍부한 feature representations을 생성하지 못함을 시사함.
How does our proposed description-based label attention classifier perform on ICD-9 coding?
- Longformer+DLAC model이 ICD-9 coding에서 우수한 성능을 보여줌과 동시에, DLAC가 LRC보다 위에 시행했던 모든 실험에서 우수한 성능을 보임.
- 하지만, CNN-based model인 Joint-LAAT에 비해서는 낮은 성능을 보였고, TransICD와 같이 transformer-based architectures중 현존하는 가장 우수한 모델보다는 아주 미세한 차이로 낮은 성능을 보임.
- 이런 결과는 MIMIC-3-50 데이터는 큰 구조를 학습시키기에 충분히 큰 데이터를 가지지 않다는 사실에 기인함. 그렇기에 아직까지 Transformer-based model은 more lightweight CNN-based model에 성능이 미치지 못한다고 할 수 있음.
- 여기서 포인트는, DLAC는 encoder와 agnostic한 classifier이기 때문에, 다른 모델과 결합되어 성능을 향상 시킬 수 있음.
To which extent can the DLAC provide explainable predictions for ICD-9 codes?
- LRC와 다르게 DLAC는 attention scores을 이용하여 explainable predictions을 제공할 수 있음. 즉 DLAC는 각 ICD-9 code prediction에 대하여 상위 어텐션 스코어들을 다룰 수 있음.
Conclusion
- Longformer encode가 long and noisy input sequences such as discharge summaries 를 processing하기에 가장 적합한 모델임을 밝힘.
- 본 논문에서 제시한 DLAC는 다양한 transformer-based encoders에 결합되어 사용할 수 있고, 이 때 흔한 decoder구조인 LRC보다 뛰어난 성능을 낼 수 있음.
- 특히 fuzzy, long texts를 다루어야 할 때, 이 모델을 유용함. 일례로, predicted ICD-9 codes에 대해서 explain-ability가 필요한 discharge summaries를 다루어야 하는 상황을 들 수 있음.
