Apache Impala?

아파치 임팔라(Apache Impala)?
Apache Hadoop을 실행하는 컴퓨터 클러스터에 저장된 데이터를 위한 오픈 소스 대규모 병렬 처리(MPP) SQL 쿼리 엔진 입니다.
빅데이터 분석을 In-Memory 기반 의 실시간 온라인 분석 까지 확대를 가능하게 한다.
Impala vs. Hive?
Impala와 Hive의 차이는 실시간성 여부 입니다.
Hive? 데이터 접근을 위해 MapReduce 프레임워크를 이용하는 반면에,
Impala? 응답 시간을 최소한으로 줄이기 위해 고유의 분산 질의 엔진 을 사용함.
=> 이 분산 질의 엔진은 클러스터 내 모든 데이터 노드에 설치되도록했다.
Impala와 Hive는 동일 데이터에 대한 응답 시간에 있어서 확연한 성능 차이를 보이고 있습니다.
-
단순 집계 (SUM, COUNT 등)
-
MPP: SQL로 바로 수행 → 수 초 ~ 수십 초
-
MapReduce_: Mapper/Reducer 작성 + Shuffle 단계 필요 → 수 분 이상
-
-
복잡한 Join 연산
-
MPP: 옵티마이저가 Broadcast Join, Hash Join, Sort-Merge Join 선택 → 빠름
-
MapReduce: Join은 여러 단계 MapReduce Job 필요 → 속도 매우 느림
-
-
반복 연산 (Machine Learning, Graph Processing 등)
-
MPP: 반복 연산에 최적화는 덜 되어 있음, 대신 Spark 같은 인메모리 엔진이 더 적합
-
MapReduce: 매 Iteration마다 디스크 I/O 발생 → 매우 느림
-
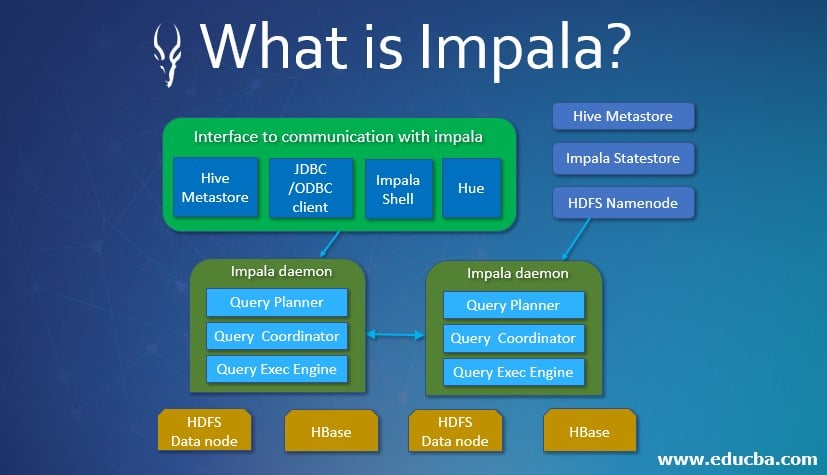
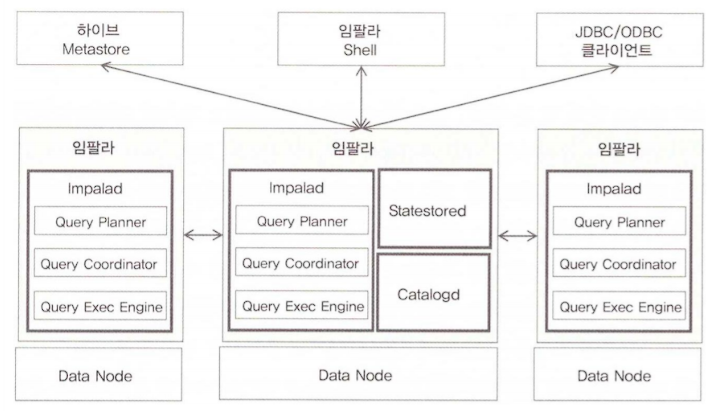
Apache Impala Architecture
Impala는 크게
1. Imapalad
2. statestored 로 구성되어 있음.
Impalad는 분산 질의 엔진 역할을 담당하는 프로세스
Impala statestore 프로세스는 각 데이터 노드에서 수행되는 Impalad에 대한 메타데이터를 유지하는 역할을 당담.
-
Impala Daemon(Impalad)
하둡의 데이터 노드에 설치되어 Impala의 실행 쿼리에 대한 계획, 스케줄링, 엔진을 관리하는 코어
-
Query Planner
Impala Query에 대한 실행 계획을 수립
- summary 정보 확인가능
1. hdfs scan은 얼마나 걸리는지?
2. aggregation은 얼마나 걸리는지? 등
=> step 별로 정보가 나온다.
- summary 정보 확인가능
-
Query Coordinator
Impala Job 리스트 및 스케줄링 관리
-
Query Exec Engine
Impala Query를 최적화해서 실행하고, Query 결과를 제공
-
-
Statestored
분산 환경에 설치되어 있는 Impalad의 설정 정보 및 서비스를 관리
-
Catalogd
Impala에서 실행된 작업들을 관리하며, 필요시 작업 이력을 제공
Impala SQL 처리 순서
1. SQL 요청
- 사용자가 Impala에서 SQL Query를 요청하면, 특정 노드(Impalad 중 하나)가 이를
Coordinator로서 받는다.
2. Query Planning
Coordinator노드가 쿼리 실행 계획(Query Planning)을 세움.EXPLAIN(실행 전 실행 계획)/PROFILE(실행 후 상세 실행 정보)/SUMMARY(PROFILE 간단 버전)명령어를 통해 실행 계획 및 단계별 시간 소요를 확인할 수 있다.
=> 이를 통해 병목 구간을 파악 가능하다.
3. Coordinator
Coordinator는 실행 계획을 분석 후 각 노드(Excecutor)에 작업을 분배한다.
4. Executor
- 각
Executor는 자신이 맡은 HDFS 블록 을 스캔하고, 필터링 / 조인 / 집계등의 작업을 수행한다. - 처리된 중간 결과는 다시
Coordinator또는 다른Executor에게 전달된다.
5. 통신 및 결과 집계
- 여러
Executor노드들이 통신을 통해 데이터를 주고 받음. - 최종적으로 모든 결과가
Coordinator로 모인다.
6. 결과 반환
Coordinator는 최종 결과를 클라이언트(사용자 툴)에 반환한다.📌 확장 시 고려사항 (100대 클러스터 기준)
ImpalaD는 기본적으로Coordinator + Executor역할을 동시에 수행
그러나 클러스터가 커지면(노드 수 ↑) 통신 비용이 커지므로- 일부 노드를
전용 Coordinator로 지정
=>Dedicated Coordinator Mode - 나머지는
Executor전용으로 운영하는 것이 효율적.
- Coordinator가 너무 많으면? → 통신 Cost ↑, 성능 저하
- Coordinator 수를 적절히 줄이면? → 더 나은 성능 가능. Dedicated Coordinator Mode
REF : https://impala.apache.org/docs/build/html/topics/impala_dedicated_coordinator.html
=> ES 도 있네용.
- 일부 노드를
이후
같은 MPP 계열로 Presto와 Trino가 있음.
- 신규 구축/클라우드 → Trino가 대세
- 기존 Hadoop + Cloudera 환경 → Impala 유지
저는 사실 K8S 환경을 좋아하다보니 Trino 에 대해서 다음번에 더 공부해보겠습니다.
ref :
1. https://kerpect.tistory.com/77
2. https://sunrise-min.tistory.com/entry/Impala%EC%9D%98-Architecture%EC%99%80-Components%EC%97%90-%EB%8C%80%ED%95%9C-%EC%A0%95%EB%A6%AC
