0. 개요
자료구조의 스택, 큐, 환형 큐, 힙, 트리, 그래프에 대해 알아보고 C++에서 직접 사용해보자.
1. 스택
- 후입 선출(Last In First Out-FIFO)
- 메모리가 새로 들어오는 데이터의 위치가 메모리 말단(일명 '탑 포인터')
#include<stack>
// 선언
stack<int> stack;
// 데이터 추가
stack.push(element);
// top 데이터 삭제
stack.pop();
// 스택 사이즈 반환
stack.size();
// 비어있는지 체크
stack.empty();
// stack1과 stack2 두 스택의 내용을 바꿈
swap(stack1,stack2);2. 큐
- 선입 선출 FIFO(First In First Out)
- 스택과 달리 front, back 원소에 접근 가능
#include <queue>
// 선언
queue<int> q;
// 데이터 추가
queue.push(element);
// front data 삭제
queue.pop();
// 제일 최상위 데이터 반환
queue.front();
// 마지막 데이터번환
queue.back();
// 사이즈 반환
queue.size();
// 비어있는지 확인
queue.empty();
// 두 큐의 내용 바꾸기
swap(queue1, queue2);3. 환형 큐
- 일반적으로 큐는 push와 pop을 반복하하다보면 큐는 점점 오른쪽으로 이동
- 큐 배열의 최대공간까지 밖에 사용할 수 없게된다.
- 이를 보완하기 위해 원형 큐를 이용하여 계속해서 공간을 활용할 수 있다.
- 최대 공간크기의 -1 의 다음 공간은 0으로 하여 연속적으로 저장할 수 있게 된다.
- 말이 너무 어렵다. 실습을 통해 알아보자
- 길이가 10인 배열로 원형 큐 구현하기
#include<iostream>
using namespace std;
class myQueue{
private:
int arr[10] = {0};
int front = 0, rear = 0;
public:
void push(){
if(((rear + 1) % 10) == front){
cout << "Queue is Full" << endl;
} else {
cout << "데이터를 입력하세요: ";
int data;
cin >> data;
rear = (rear + 1) % 10;
arr[rear] = data;
}
}
void pop(){
if(front == rear){
cout << "Queue is Empty" << endl;
return;
}
front = (front + 1) % 10;
}
void print(){
if(front == rear){
cout << "Queue is Empty" << endl;
return;
}
for(int i = (front + 1)%10; i != (rear + 1)% 10; i = (i+1)% 10){
cout << i << " : " << arr[i] << endl;
}
}
};
int main() {
int num;
myQueue q;
while (1) {
cout << "번호를 입력해주세요 1. push / 2. pop / 3. print / 4. 종료" << endl;
cin >> num;
switch (num) {
case 1:
q.push();
break;
case 2:
q.pop();
break;
case 3:
q.print();
break;
case 4:
return 0;
default :
cout << "잘못된 입력입니다." << endl;
}
}
return 0;
}정리를 해보자면 이렇다 일차원 배열로 생각했을 대 [1,2,3,4,5,6,7,8,9,10] 이 있다고 해보자 만약 저 배열이 원형으로 배치 되어 있다면 10 다음은 1일 것이고 1의 인덱스는
{(10의 인덱스 + 1)% 배열의 크기}
일 것이다.
그렇다면 1은 front, 10은 rear라고하고 위에 코드에서 다시생각하면 이해하기 슆다.
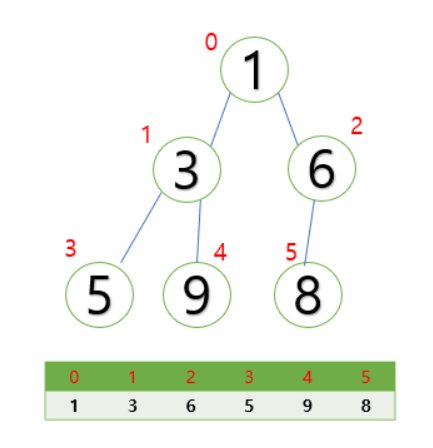
4. 힙 Heap
-
힙은 이진 트리 자료구조이다.
-
index 0은 최상단 노드
-
i 번째 노드의 자식 노드는 i 2 + 1번째 노드와 i 2 + 2번째 노드가 된다.
-
i 번째 노드의 부모 노드는 (i-1)/2 번째 노드가 된다.
-
부모노드는 항상 자식 노드보다 작거나 같다./크거나 같다.
-
이러한 구조는 Min Heap이라고 부른다.
-
부모가 자식보다 항상 큰 규칙을 가지면 Max Heap이 된다.
-
이러한 규칙을 유지하며 원소의 추가/제거 과정을 거치면 루트 노드에 있는 원소 값은 Min Heap에서는 최소값이, Max Heap에서는 최대값이 된다.
-
원소의 추가/제거 과정이 O(logN)의 복잡도
-
조회 O(1)으로 효율적인 구조
-
Heap 자료구조를 응용한 대표적인 사례가 Priority queue(우선순위 큐)이다.
-
push/pop이 가능한 자료로 꼭 Heap으로 구현할 필요는 없지만 Heap으로 구현하는 것이 시간복잡도 면에서 큰효율을 낸다.
왜 효율을 내는지는 아래의 Reference를 참조하라
// 큐와 우선순위 큐의 비교
#include <iostream>
#include <queue>
using namespace std;
int main() {
queue<int> qu;
qu.push(1);
qu.push(9);
qu.push(5);
int sz = qu.size();
for(int i=0;i<sz;i++){
cout << qu.front() << ',';
qu.pop();
}cout << '\n';
priority_queue<int> p_qu_l;
p_qu_l.push(1);
p_qu_l.push(9);
p_qu_l.push(5);
sz = p_qu_l.size();
for(int i=0;i<sz;i++){
cout << p_qu_l.top() << ',';
p_qu_l.pop();
}cout << '\n';
priority_queue<int, vector<int>, greater<int>> p_qu_g;
p_qu_g.push(1);
p_qu_g.push(9);
p_qu_g.push(5);
sz = p_qu_g.size();
for(int i=0;i<sz;i++){
cout << p_qu_g.top() << ',';
p_qu_g.pop();
}cout << '\n';
return 0;
}
- 우선순위 큐는 기본적으로 Max Heap, 즉 원소를 pop하면 큰 수부터 내림차순이 된다. 오름차순으로 하고 싶은 경우에는 원소에 전체적으로 음수를 취해주거나 우선순위 큐를 선언함에 있어 인자를 넣어 Min Heap을 만들어 주면 된다.
- pair와 함께 사용하여 비교우선순위는 pair의 첫번째 요소로 먼저 비교하고 그 두번째 요소로 비교하는 방식이 많이 사용된다.
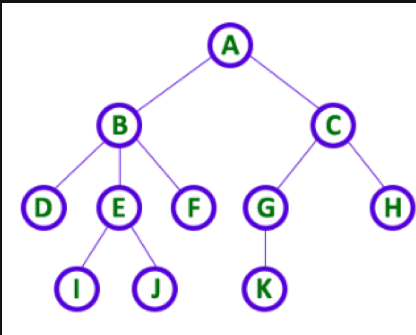
5. 트리
- 트리는 자료구조의 한 종류로써, 트리의 각 요소를 노드라고 부른다.
- root: 트리 맨위에 있는 노드
- edge: 노드와 노드 사이의 연결 선
- parent: 자신보다 하위 노드를 가지고 있는 노드의 경우 parent
- child: parent의 하위 노드
- sibling: 같은 부모노드들을 가지고 있는 노드들
- leaf: 자식 노드를 가지지 않은 노드
- internal node: 적어도 하나 이상의 자식 노드를 포함하는 노드
- level: 루트부터 레벨0
- height: 레벨의 역순
- path: 노드와 노드 사이간에 나타나는 노드와 엣지의 순서
- degree: 해당 노드가 포함하는 자식노드의 개수
- subtree: 노드의 각 자식은 재귀적으로 하위 트리를 형성한다.
- 대표적인 사용예시: 컴퓨터 파일 매니저 시스템(디렉토리 내부 디렉토리 및 파일들)
- 자식노드가 최대 두개까지 있는 트리를 이진트리라고 부른다.
#include <bits/stdc++.h>
using namespace std;
class Node {
public:
int data;
Node* left;
Node* right;
// Val is the key or the value that has to be added to the data part
Node(int val)
{
data = val;
// Left and right child for node will be initialized to null
left = NULL;
right = NULL;
}
};
int main()
{
//create root
Node* root = new Node(1);
/* following is the tree after above statement
1
/ \
NULL NULL
*/
root->left = new Node(2);
root->right = new Node(3);
/* 2 and 3 become left and right children of 1
1
/ \
2 3
/ \ / \
NULL NULL NULL NULL
*/
root->left->left = new Node(4);
/* 4 becomes left child of 2
1
/ \
2 3
/ \ / \
4 NULL NULL NULL
/ \
NULL NULL
*/
return 0;
}- Array나 Linked List에서는 삽입이나 삭제를 수행하는 데 O(N) 시간 소요
- 트리는 편향 트리가 아닌 이상 일반적으로 삽입/삭제 수행 시 O(logN) 시간 소요
6. 그래프
- 객체 간의 연결 관계를 표현할 수 있는 자료구조
- 트리와 다르게 계층적인 구조를 가지고 있지 않음
- 트리도 그래프의 일종

1) 종류
- 무방향그래프: 방향성이 없는 그래프. 간선을 양방향으로 간주
- 뱡향 그래프: 방향성이 있는 그래프, 일방통행
- 가중치 그래프: 간선에 가중치 값이 있는 그래프
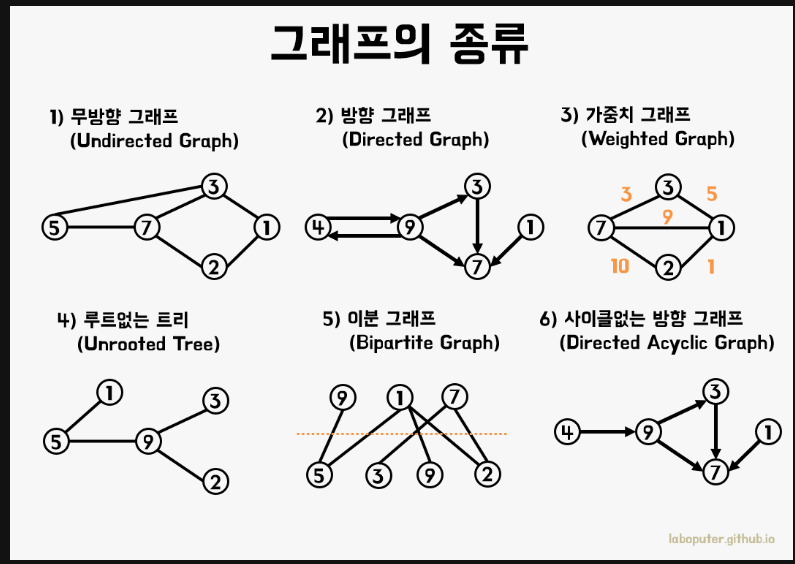
- 정점(vertex): 노드
- 간선(edge)
- Adjacent Vertex: 직접 연결된 정점
- Degree: 차수
2) 표현방법
- 인접리스트: 특정 정점 기준으로, 실제 연결된 인접정점을 값으로 가짐
ex) 지하철 노선도 - 인접행렬: 2차원 배열을 사용하여 모든 정점들 간 연결 여부를 값으로 가짐
ex) 소셜 네트워크 관계도
#include <iostream>
#include <vector>
using namespace std;
// 인접 리스트 : 실제 연결된 애들만 넣어줌.
void CreateGraph_AdjacencyList()
{
struct Vertex
{
int data;
};
vector<Vertex> v(6); // 정점 6개 생성.
// 0 1 2
// [vector<int>][vector<int>][vector<int>]...
vector<vector<int>> adjacent; // 2차원 배열.
adjacent.resize(6);
adjacent[0] = { 1, 3 }; // 0번 정점은 1, 3번 정점과 연결되어 있음.
adjacent[1] = { 0, 2, 3 }; // 1번 정점은 0, 2, 3번 정점과 연결되어 있음.
adjacent[3] = { 4 }; // 3번 정점은 4번 정점과 연결되어 있음.
adjacent[4] = { 5 }; // 4번 정점은 5번 정점과 연결되어 있음.
// Q) 0번->3번 연결되어 있나요?
bool connected = false;
// 정점이 가지고 있는 값들을 하나씩 조사.
int size = adjacent[0].size();
for (int i = 0; i < size; i++)
{
int vertex = adjacent[0][i];
if (vertex == 3)
connected = true;
}
}
// 인접 행렬 : 메모리 소모 심하지만, 빠른 접근 가능.
void CreateGraph_AdjacencyMatrix()
{
struct Vertex
{
int data;
};
vector<Vertex> v(6);
// 연결된 목록을 행렬로 관리
// [X][O][X][O][X][X] 0 -> 1, 3
// [O][X][O][O][X][X] 1 -> 0, 2, 3
// [X][X][X][X][X][X] 2 -> x
// [X][X][X][X][O][X] 3 -> 4
// [X][X][X][X][X][X] 4 -> x
// [X][X][X][X][O][X] 5 -> 4
vector<bool> v(6, false);
vector<vector<bool>> adjacent(6, vector<bool>(6, false));
adjacent[0][1] = true;
adjacent[0][3] = true;
adjacent[1][0] = true;
adjacent[1][2] = true;
adjacent[1][3] = true;
adjacent[3][4] = true;
adjacent[5][4] = true;
// Q) 0번 -> 3번 연결되어 있나요?
// 정점을 인덱스로 사용하여 바로 접근 가능.
bool connected = adjacent[0][3];
// 가중치 그래프를 인접 행렬로 만들기. (정점간 연결되어 있지 않은 경우 = -1)
// 값을 가중치로 사용하면 됨.
vector<vector<int>> adjacent2 =
{
{ -1, 15, -1, 35, -1, -1},
{ 15, -1, 5, 10, -1, -1},
{ -1, 5, -1, -1, -1, -1},
{ 35, 10, -1, -1, 5, -1},
{ -1, -1, -1, 5, -1, 5},
{ -1, -1, -1, -1, 5, -1},
};
}3) 그래프의 탐색
- 깊이 우선 탐색(DFS)
특정 정점을 기준으로, 한 방향으로 쭉 탐색 후 다시 돌아와서 나머지 방향을 탐색, 모든 정점을 방문할 때 사용 - 너비 우선 탐색(BFS)
특정 정점을 기준으로, 인접 정점들부터 쭉 탐색.

7. 위의 내용들은 겉핥기일 뿐이다.
- 저 개념들을 안다한들 프로그래밍 언어로 활용할 수 없다면 잉여지식이다.
- 이제부터가 진짜다.
- 정렬, 탐색의 알고리즘을 C++로 풀면서 더 자세히 알아보자.
Reference
- 원형 큐
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kartmon&logNo=221508786090
https://dadidadi.tistory.com/8 - 힙
https://doorrock.tistory.com/13 - 트리
https://velog.io/@kon6443/Data-Structure-%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-C-%ED%8A%B8%EB%A6%AC
https://thinking-developer.tistory.com/70

좋은 지식 나누어요