목표
- 이번에는 기존 시리즈와는 다르게 기사요약이 아닙니다.
- 애플의 M1칩의 성능과 M1칩이 엄청 뛰어난 성능을 가질 수 있었던 이유에 대해 알아보려 합니다.
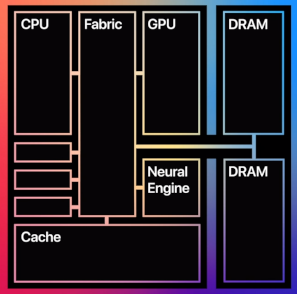
본론 1 :: Apple M1 칩 소개

CPU
- ARM의 big.LITTLE 기술을 활용해서 8코어를 구성했습니다.
- big.LITTLE은 무겁고 복잡한 프로그램을 돌릴 때는 성능이 좋은 CPU(빅 클러스터)를, 간단한 프로그램을 돌릴 때는 낮은 성능을 가진 CPU(리틀 클러스터)를 사용해 전력 소모 효율을 높이는 기술입니다.
- ARMv8 기반의 Apple 독자 CPU인 Firestorm이 빅 클러스터로, Icestorm이 리틀 클러스터로 각각 4코어씩 활용됩니다.
- Firestorm과 Icestorm 모두 거대한 L1, L2 캐시가 사용됩니다.
11세대 인텔 CPU와 Zen3 AMD CPU보다 큽니다.- 단순 캐시 크기가 큰 것이 무작정 좋은 것은 아닙니다.
- 캐시 크기가 커지면, 읽어야 하는 라인 개수가 증가해 탐색 시간이 증가합니다.
- 한 번에 읽는 라인 개수 (연관성, associativity)가 증가하면, 탐색 시간은 줄어들지만, 후술할 '적중률' 이라는 지표가 감소합니다.
- 캐시의 성능 평가 지표는 다양하지만, 일반적으로 캐시 크기와 연관성의 호응에 따른 캐시 적중률 (Cache hit ratio)로 평가됩니다.
- M1 칩의 큰 L2 캐시는 모든 코어가 공유할 수 있습니다.
- M1 칩이 큰 캐시를 사용할 수 있었던 이유는 두 가지입니다.
- 5nm EUV 공정을 사용한 첫 AP이기 때문입니다.
- 더 세밀한 리소그래피 장비를 사용했으니 남는 공간이 더 많아졌습니다.
- M1 칩에 남는 공간이 있었기 때문입니다.
- TSMC의 N5 공정에도 다이 크기가 120mm²로 큰 편입니다.
- 남는 공간을 캐시와 peripheral를 위해 사용했습니다.
- 5nm EUV 공정을 사용한 첫 AP이기 때문입니다.
- 단순 캐시 크기가 큰 것이 무작정 좋은 것은 아닙니다.
GPU
- Apple은 자사의 GPU 아키텍처 또는 칩 이름을 공개하지 않고 있습니다.
- M1칩에 도입된 건 A13부터 사용됐던 '3세대 디자인 GPU 아키텍처'이며 A13와 A14에 4코어가 탑재됐고 M1에는 8코어가 탑재됐습니다. (MacBook Air 기본형에는 7코어 탑재)
- 2.6TFLOPS의 FP32 연산성능, 82GTex/s의 텍스쳐 성능과 41GPix/s의 ROP 성능을 가졌다고 밝혔습니다. 이는 GTX1050Ti ~ GTX1650 급 성능입니다.
- 해당 데스크톱 GPU가 16~12nm 공정에서 생산된 반면, 이번 GPU는 5nn 공정에서 생산되는 만큼 전력 효율 면에서 큰 개선이 있을 것이라 예상할 수 있습니다.
RAM
- LPDDR4x-4266 메모리는 다음과 같은 장점이 있습니다.
- 총 4개의 32-bit 채널을 이용해서 128bit 통신을 4266MT/s로 빠른 속도
- I/O전압을 절반 (1.12~0.61V)으로 줄여 적은 전력 소모
- 사이즈가 작음
본론 2 :: Apple M1 칩의 성능이 좋은 이유
2.1. Unified Memory Architecture (UMA)
CPU와 GPU가 서로 다른 메모리 또는 메모리 영역을 사용하고 있다는 사실은 많이 알려져 있습니다. GPU를 사용하려면 다음과 같은 과정을 거칩니다.
- 메모리를 GPU 메모리로 보냅니다.
- GPU가 instruction을 수행합니다.
- GPU는 연산 결과를 다시 메인 메모리로 보냅니다.
안타깝게도 data가 회당 2번씩 이동하므로 delay가 발생합니다.
Apple은 CPU, GPU, NPU가 동시에 같은 곳에 접근할 수 있는 메모리 구조인 UMA를 채택했습니다. 마치 자기 자신에 속한 메모리에 접근하는 것처럼 같은 주소에 접근해서 사용할 수 있습니다. 이러한 시도는 과거 인텔의 eDRAM에서도 볼 수 있습니다.
UMA 뿐만 아니라 Apple은 high-bandwidth memory를 사용해서 속도 증가를 꾀했습니다. (HBM과 착각하면 안 됩니다.) 일반적인 메모리보다는 높은 클럭의 메모리를 사용했다는 의미입니다.
2.2. 치밀한 설계능력
대다수 프로그래밍 언어는 위에서 아래로 순차적으로 실행됩니다. 명령어 수준에서 CPU는 코드에서 병렬성을 발견해서 반드시 순차적으로 실행할 필요가 없는 명령어는 병렬로 수행해서 수행속도 증가를 꾀합니다. 이것이 비순차적 명령 실행(Out-of-Order Execution, OoOE)입니다.
- 예를들어, x = 5, y = 10 일때 아래와 같은 식이 있다고 합시다.
- B값을 구하기 위해서는 반드시 A를 먼저 구해야 합니다.
이처럼 어떤 값을 먼저 구해야만 다음 값을 알 수 있는 경우를 의존성이 있다 라고 표현합니다. - 하지만, A와 C는 바로 구할 수 있기 때문에 A와 C를 병렬로 동시에 구합니다.
- 순차적으로 실행한다면 A, B, C 이렇게 3번의 연산시간이 소요됐지만,
OoOE를 이용하면 A|C, B 이렇게 2번의 연산시간만 소요됩니다.
OoOE는 사용하지 않는 곳이 없을 정도로 흔한 개념인데도 불구하고 왜 M1 칩의 OoOE는 빠를까요?
- M1 칩의 ARM core는 인텔/AMD의 CISC와는 다르게 RISC라는 고정길이 ISA(Instruction Set Architecture)를 사용합니다.
- M1 칩은 8개의 디코더를 사용합니다. 모든 명령어의 길이가 같기 때문에 따로 명령어를 검사하는 과정이 생략됩니다.
하지만 8개의 디코더와 RISC를 사용하는 것이 비결이라고 오해하면 안됩니다. 디코더 다양한 거 많이 쓰면 좋은 건 모든 제조사가 알고 있습니다. RISC가 모든 경우에서 항상 CISC보다 나은 것도 아닙니다. 하지만 그들이 쉽게 그 방법을 택하지 못하는 이유는 다이 크기와 소모 전력이 증가하기 때문입니다.
결국 핵심은 설계를 치밀하게 잘 해냈다는 점입니다. Apple은 한정된 공간에 8-Wide decoder를 넣는 데 성공했고 그것에 맞게 백엔드 확장과 소모전력 최소화를 이뤄냈습니다.
2.3. 한 회사에서 HW부터 SW까지
이 이유가 M1 칩의 좋은 성능의 가장 크리티컬한 원인입니다.
일반적으로 SoC 내부의 모든 칩을 기업에서 제조할 수 없습니다. 자사에서 만들 수 있는 제품은 만들어 넣지만, 그 외는 다른 벤더로부터 구매해서 조립하는 방식입니다. 예를들어, 삼성전자의 엑시노스에서 AP는 자사에서 만들지만, GPU는 ARM의 Mali 시리즈나 AMD의 RDNA를 사와서 끼워넣는 식입니다. 삼성이 GPU를 만들지 않기 때문이지요. 이때 문제가 발생합니다. SoC에 어떤 제품을 넣어야 하는지, 서로 호환이 되는지 등 벤더와 벤더 사이의 이해관계로 인해 문제가 발생할 가능성이 있습니다.
Apple의 M1 칩은 이야기가 다릅니다. 하드웨어부터 OS를 넘어 SW까지 모든 것을 전부 자사에서 제조합니다. 자사에서 모든 것을 컨트롤하니 HW부터 SW에 이르기까지 체계적인 최적화가 가능합니다. 아이패드 프로 5세대에 M1 칩을 도입했다는 것은 놀라운 최적화를 이뤄냈다는 증거입니다.
결론
Apple은 핸드폰-패드-노트북을 아우르는 강력한 외적 생태계를 가지고 있다는 데에 반대하는 사람은 없을 것입니다. 이번 M1 칩과 Apple의 행보가 시사하는 바는 뚜렷합니다. 제품의 매력과 브랜딩 파워로 외적 생태계를 갖추는 것뿐만 아니라 HW부터 SW까지 모든 것을 하나의 회사에서 해결하는 내적 생태계도 갖추는 것이 중요해 보입니다.
참고문헌
- 나무위키 - https://namu.wiki/w/Apple Silicon
- 나무위키 <타이거 레이크> - https://namu.wiki/w/인텔 코브 마이크로아키텍처#타이거 레이크
- 감마의 하드웨어 정보 <ARM big.LITTLE Processing의 목적과 유용성에 대하여> - https://gamma0burst.tistory.com/567?category=506536
- Quora <How is it that Apple was able to efficiently add 128KB L1d cache on an M1 CPU core but Intel/AMD still uses smaller 32/48 KB L1D cache on their cores?> - https://www.quora.com/How-is-it-that-Apple-was-able-to-efficiently-add-128KB-L1d-cache-on-an-M1-CPU-core-but-Intel-AMD-still-uses-smaller-32-48-KB-L1D-cache-on-their-cores
- Superuser <Why has the size of L1 cache not increased very much over the last 20 years? > - https://superuser.com/questions/72209/why-has-the-size-of-l1-cache-not-increased-very-much-over-the-last-20-years#
- Anandtech <The iPhone 12 & 12 Pro Review: New Design and Diminishing Returns> - https://www.anandtech.com/show/16192/the-iphone-12-review/2
- How-To Geek <How “Unified Memory” Speeds Up Apple’s M1 ARM Macs> - https://www.howtogeek.com/701804/how-unified-memory-speeds-up-apples-m1-arm-macs/
