2017년 발표된 'Attention Is All You Need' 논문을 읽고 정리한 글입니다.
'Attention Is All You Need' 원문 보러가기
1. 논문의 목적
논문의 저자들이 주장하는 바에 따르면 hidden state인 를
입력값인 와 이전 hidden state인 를 이용하여 계산하는
순환 신경망의 본질적인 특징 때문에
순환 신경망은 sequence lengths가 긴 입력에 취약합니다.
이를 해결하기 위해 어텐션 매커니즘이 도입 되었지만
몇몇의 경우 순환 신경망과 결합되어 사용되어 졌기에
근본적인 문제는 여전히 남아 있었습니다.
문제를 해결하기 위하여 논문의 저자들은 어텐션 매커니즘만을 사용한
모델을 고안하였습니다.
2. 모델의 구조
트랜스포머 모델의 구조는 아래 그림과 같습니다.
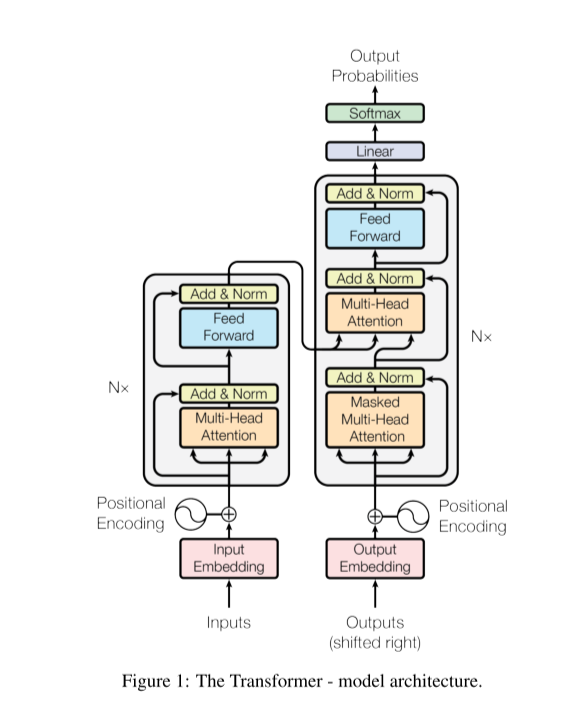
성능이 뛰어난 대부분의 모델들이 encoder-decoder 구조를 가지고 있기에
트랜스포머 모델 또한 이 구조를 따랐습니다.
트랜스포머 모델의 특징 중 하나가 바로 입력값의 차원과 출력값의 차원이
서로 같기에 여러개의 encoder-decoder 층을 쌓을 수 있는 점입니다.
2.1 Scaled Dot-Product Attention
그림으로 먼저 표현 하자면 아래와 같습니다.
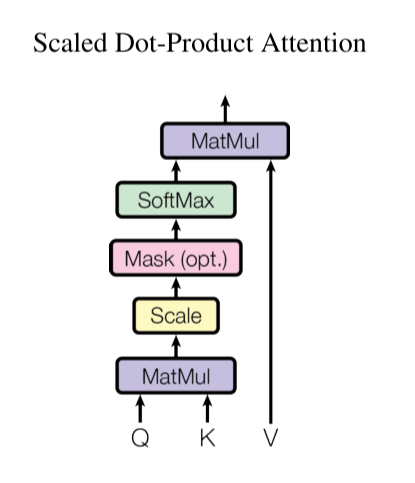
그리고 이를 수식으로 표현하면 다음과 같습니다.
is keys of dimension
query 값과 전치시킨 key 값에 dot-product를 수행하고
이를 key 차원의 제곱근으로 나누어 줍니다.
그 다음 softmax에 통과 시켜 어텐션 분포를 구한 뒤
계산한 어텐션 분포와 value 값에 dot-product를 수행합니다.
이때 key 차원의 제곱근으로 나누어 주는걸 논문에서는 scaling 이라고 표현 합니다.
어텐션을 계산할 때 가 커질수록 의 크기도 커져 이는 softmax 함수 특성상
기울기 소실(gradient vanishing)을 야기하게 됩니다.
이를 방지하기 위해 scaling을 수행합니다.
2.2 Multi-Head Attention
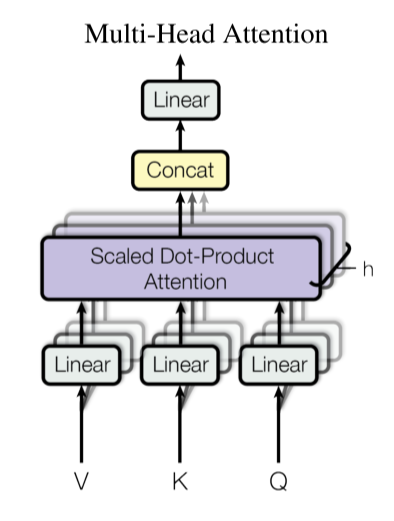
논문의 저자들은 어텐션을 단일적으로 계산하기 보다
한번에 계산하는 것이 효과적이라고 보았습니다.
이를 위한 Multi-Head Attention을 수식으로 표현하면 다음과 같습니다.
2.3 Applications of Attention
트랜스포머 모델은 멀티 헤드 어텐션을 세가지 다른 방법으로 사용합니다.
첫번째로는 encoder-decoder attention 입니다.
인코더-디코더 어텐션의 key와 value 값들은 인코더의 출력이 되고
query 값은 디코더의 selft attention layer의 출력값 입니다.
이를 통해 디코더가 매 순간(every position)
모델의 입력값에 집중(attention)할 수 있도록 합니다.
두번째는 인코더의 self-attention 입니다.
key, value, query 값들은 모두 인코더의 이전 층의 출력 입니다.
세번째, 디코더의 selft-attention은 두번째와 비슷하게
key, value, query 값들은 모두 디코더로 부터 비롯됩니다.
트랜스포머의 디코더 입력은 순환 신경망처럼 순차적으로 입력 되는것이 아니라
한번에 입력이 이루어 지므로 이때 왼쪽 편의 정보 흐름(leftward information flow)을
막을 필요가 있습니다. 이를 위해서 scaled dot-product 수행 시에 값으로
설정하여 마스킹 합니다. (by masking out (setting to ) all values in the input of the softmax)
2.4 Position-wise Feed-Forward Networks
트랜스포머 모델의 구조에서 각각의 인코더와 디코더는 완전 연결층을 가지고 있고
이 네트워크의 가중치는 서로 공유되지 않습니다. (each position separately and identically)
또한 완전 연결층은 두개의 선형 변환(linear transformation)을 가지고 있으며
활성화 함수로 ReLU를 사용합니다.
이를 수식으로 나타내면 다음과 같습니다.
2.5 Embeddings and Softmax
트랜스포머 모델은 다른 모델과 비슷하게 학습된 임베딩을 사용합니다.
또한 디코더의 출력을 다음 토큰의 확률로 변환하기 위해서
선형 변환(linear transformation)과 softmax 함수를 사용합니다.
2.6 Positional Encoding
트랜스포머 모델은 순환 신경망 혹은 합성곱 신경망을 사용하지 않아
위치에 대한 정보를 가지고 있지 않습니다.
이를 해결하기 위하여 논문의 저자들은 Positional Encoding을 도입 하였습니다.
논문에서 Positional Encoding을 위해 사용한 함수들은 다음과 같습니다.
논문에서는 sin 함수와 cos 함수를 사용하였지만 다른 함수를 사용해도
무방 하다고 합니다.
(There are many choices of positional encodings, learned and fixed)
3. 결론
트랜스포머 모델은 번역 수행 영역에서 순환 신경망 혹은 합성곱 층을 기반으로 한
다른 모델들 보다 훈련 속도가 매우 빨랐습니다.
또한 WMT 2014 English-to-German 그리고 WMT 2014 English-to-French 번역 수행 에서
SOTA(state of the art)를 기록했습니다.
