2018년에 발표된 'CBAM: Convolutional Block Attention Module' 논문을 읽고 정리한 글입니다. 논문의 저자분들이 한국분들 이셔서 공식 블로그를 한글로 편하게 볼수도 있습니다.
논문 원문 보러가기 / 저자분의 공식 블로그
1. 논문의 목적
최근 연구에서는 합성곱 신경망(이하 CNNs)의 성능을 향상 시키기 위해서
네트워크의 세 가지 중요한 특성인 depth, width, cardinality를 증가시켜 왔습니다.
VGGNet이나 ResNet 같은 경우 depth를 증가시켰고, GoogLeNet은 width를 증가시켰으며,
ResNeXt는 cardinality를 증가시켰습니다.
본 논문의 저자들은 이러한 세가지 특성 외에 어텐션을 활용하여
representation power를 증가시키는 방법을 연구 하였습니다.
2. 모델의 구조
CBAM 모델의 전체적인 구조는 아래 그림과 같습니다.
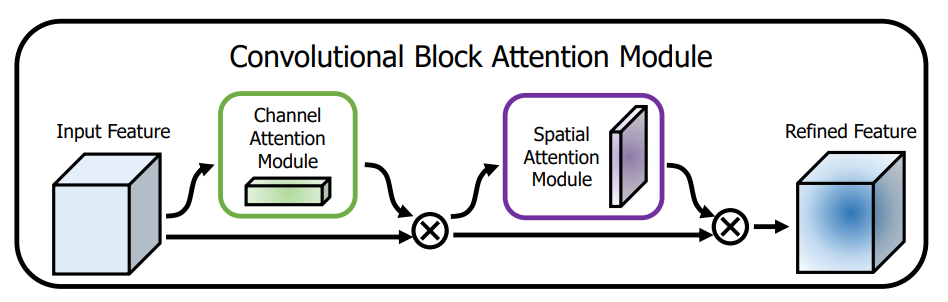
channel attention과 spatial attention을 순차적으로 수행하고 있는 모습입니다.
각각의 어텐션은 병렬적으로 수행이 가능하지만 논문에서 주장하는 바에 따르면
병렬적으로 계산하기 보다 순차적으로 계산하는게 성능이 더 좋았다고 합니다.
또한 두 어텐션 매커니즘의 수행 순서도 channel attention을 먼저 수행하는 것이
성능이 조금 더 좋았다고 합니다.
모델의 전체적인 구조를 수식으로 나타내면 다음과 같습니다.
이때 는 element-wise multiplication 입니다.
2.1 Channel Attention Module
channel attention module은 '무엇'('what')에 집중합니다.
채널 어텐션 모듈의 구조는 아래 그림과 같습니다.
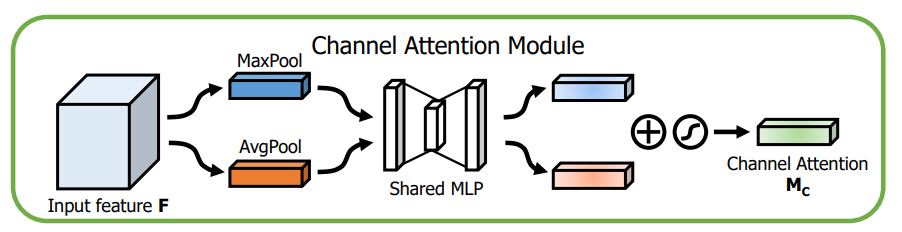
이전 연구에서의 CNNs의 어텐션 모듈에서 사용한 Average Pooling과 함께
Max Pooling 또한 사용하였습니다.
논문의 저자들은 Max Pooling 또한 독특한 객체의 특징들(distinctive object features)
에 관해 중요한 단서들을 가진다고 주장합니다.
때문에 저자들은 두가지 pooling층을 동시에 사용하는것이 Average Pooling층만
사용하는것 보다 성능이 더 좋은것을 실험적으로 보였습니다.
두가지 pooling 레이어를 통과한 뒤 공유된 MLP 레이어를 통과합니다.
이때 공유되는 MLP 레이어는 은닉층을 하나만 보유합니다.
MLP 레이어까지 통과하고 나면 두개의 출력 벡터들은
element-wise summation을 수행하게 됩니다.
이후 시그모이드 함수를 통과하여 채널 어텐션이 계산됩니다.
이를 수식으로 표현하면 다음과 같습니다.
2.2 Spatial Attention Module
채널 어텐션이 '무엇'('what')에 집중 했다면
Spatial Attention은 '어디'('where')에 집중합니다.
전체적인 구조는 아래 그림과 같습니다.
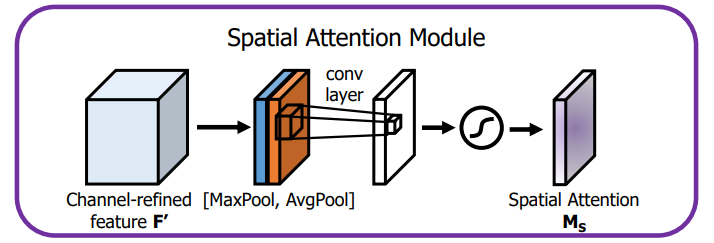
spatial attention을 계산하기 위해서는 우선 채널의 축(channel axis)에 대해
Average Pooling과 Max Pooling을 수행합니다.
그리고 효율적으로 계산하기 위해(to generate an efficient feature descriptor)
합성(concatenate)합니다.
그 다음 어떤 곳은 강조(emphasize)하고, 어떤 곳은 억제(suppress) 시키기 위해
합성곱 레이어를 통과합니다.
마지막으로 시그모이드 함수를 통과하며 Spatial Attention이 계산됩니다.
이를 수식으로 표현하면 다음과 같습니다.
이때 은 7x7 크기의 필터를 사용하는 합성곱 연산 입니다.
3. Network Visualization with Grad-CAM
P는 사진에 해당하는 클래스의 ground-truth에 대한 소프트맥스 함수의 출력값 입니다.
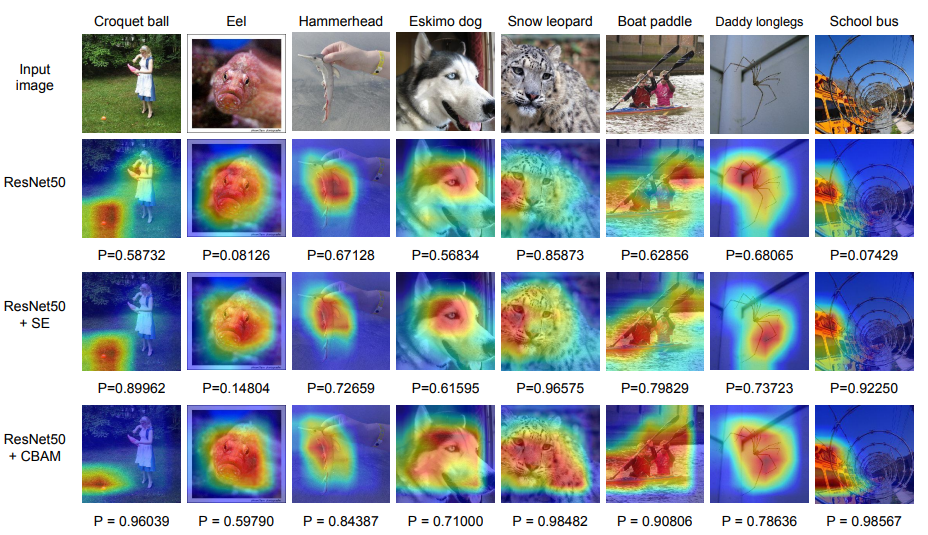
4. 결론
base line 모델의 성능을 CBAM을 사용함으로써 향상시킴에도 불구하고
전체적인 모델의 크기는 변화가 미미합니다.
(while keeping the overhead small)
또한 CBAM을 적용한 모델의 시각화를 통해
타깃 객체(target object)에 적절히 집중하는것을 확인하였습니다.
