2012년 발표된 AlexNet 논문을 읽고 정리한 글입니다.
1. Introduction
짧게 저자들이 언급한 논문의 contribution만 정리했습니다.
-
논문의 저자들은 역사상 가장 큰 합성곱 신경망(convolutional neural networks)을
ImageNet에 대해 학습시키고 이제껏 공개된 어느 결과 보다 가장 우수한 결과를 보였습니다. -
본 논문의 모델은 특이하고 새로운 구조들을 많이 포함하고 있습니다.
이를 통해 모델의 성능과 학습 속도를 개선할 수 있었습니다. -
모델의 크기로 인해 overfitting이 중요한 문제였는데
저자들은 이를 방지하기 위하여 몇몇의 효과적인 기술들을 도입하였습니다. -
본 논문의 모든 실험 결과들로 비추어 보았을때 GPU의 성능이 증가하고
충분한 양의 데이터셋이 주어진다면 본 논문의 결과가 향상될것이라고 주장합니다.
(our results can be improved)
2. The Dataset
ImagNet 데이터셋은 다양한 해상도(variable-resolution)의 이미지들로 이루어져 있으나 모델은 고정된 해상도의 입력을 받아야 하기 때문에 256 X 256 해상도로 이미지들을 다운샘플링 하였습니다.
저자들은 다운샘플링 이외에 다른 전처리 과정(pre-process)을 진행하지 않았습니다.
3. The Architecture
본 논문에서 제안된 모델의 구조는 아래 그림(Figure 2.)과 같습니다.
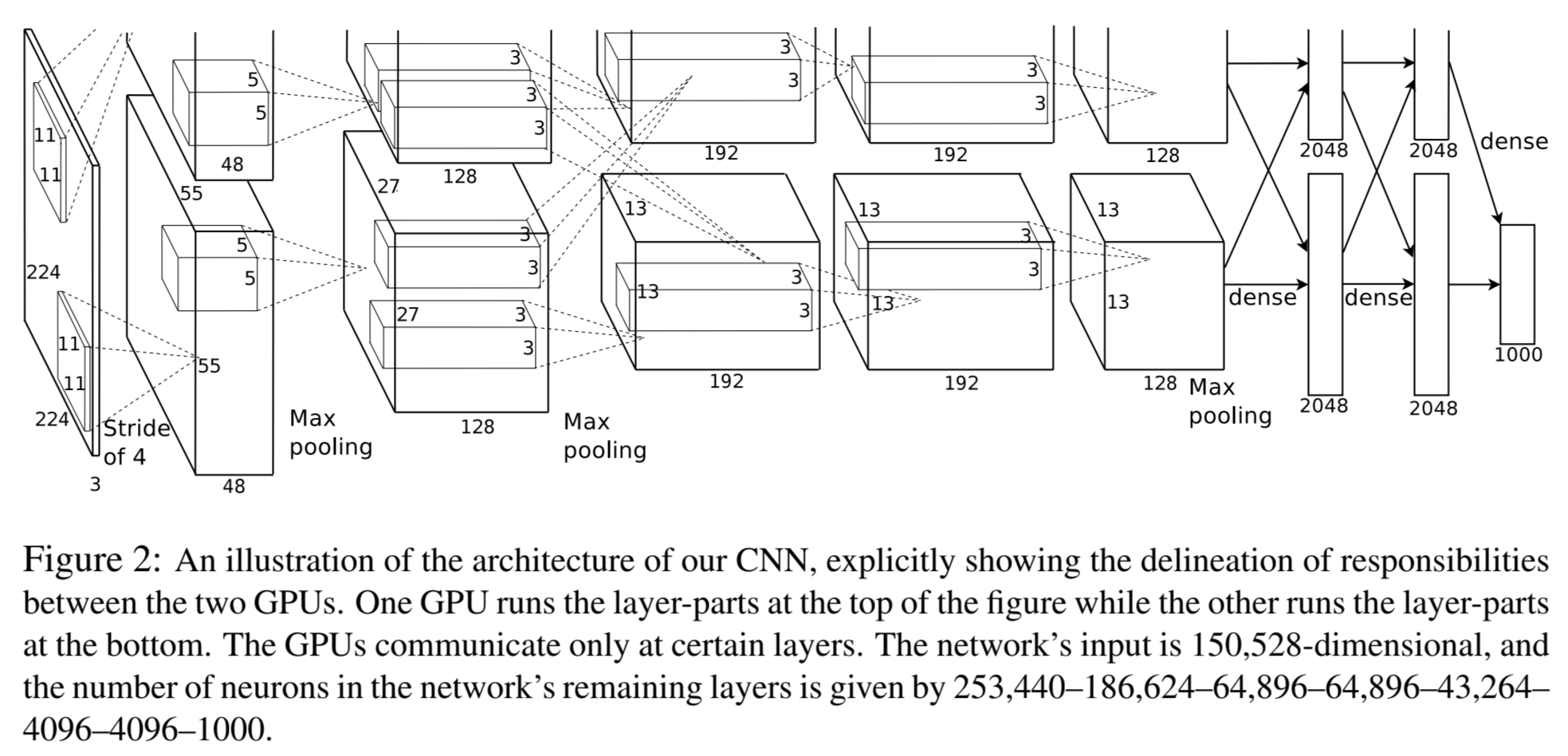
모델은 5개의 convolultional 레이어와 3개의 완전 연결층(fully-connected layer) 총 8개의 학습가능한 층들로 이루어 져 있습니다. 다음 섹션들에서 가장 중요한 순서대로 소개합니다.
3.1 ReLU Nonlinearity
기존 방식은 뉴런의 출력을 tanh 함수나 sigmoid 함수와 같은
saturating nonlinearities 함수에 통과시켰습니다.
그러나 이러한 활성화 함수를 사용하면 경사 하강법을 이용한 훈련에서
non-saturating nonlinearities 함수보다 훈련 속도가 느립니다.
따라서 논문의 저자들은 ReLU 함수를 사용합니다.
아래 그림(Figure 1.)은 활성화 함수에 따른 모델의 훈련 속도(수렴 속도) 입니다.
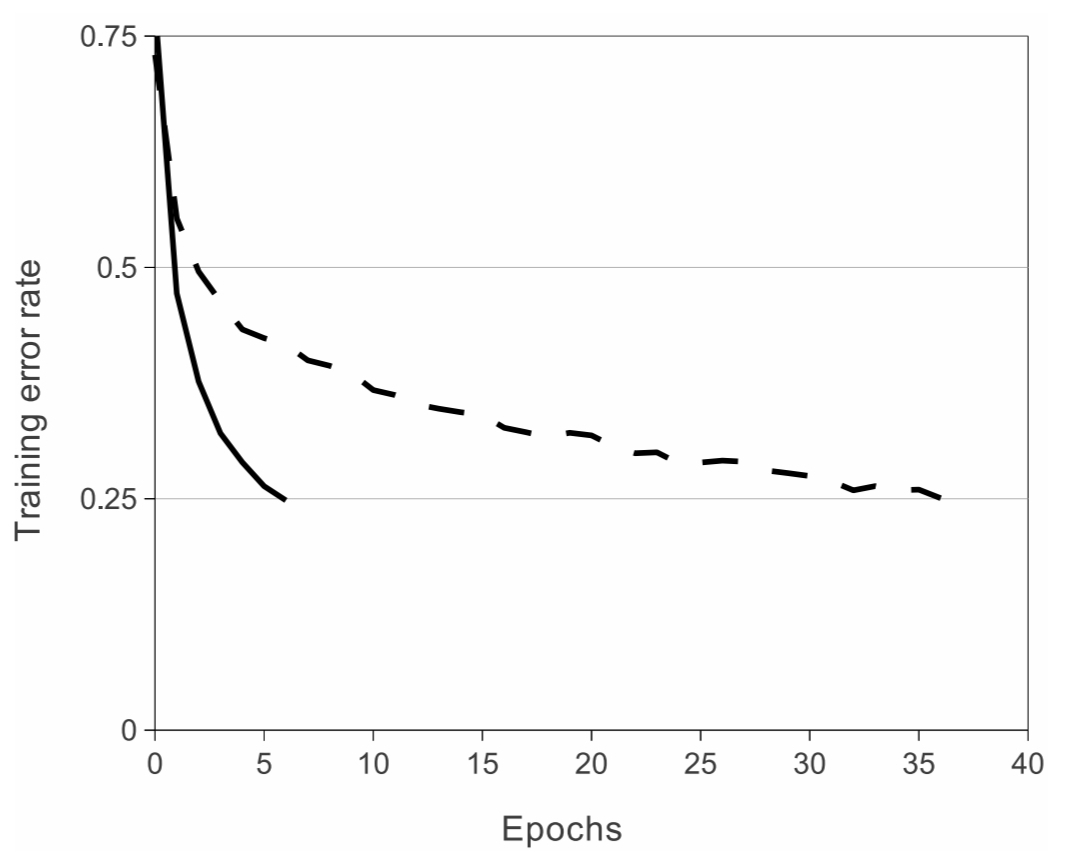
실선이 ReLU(non-saturating nonlinearities), 점선이 tanh(saturating nonlinearities)
활성화 함수를 사용한 모델 입니다.
3.2 Training on Multiple GPUs
단일 GTX 580 GPU가 3GB의 메모리 용량을 가지고 있기 때문에 모델의
최대 크기가 한정되고 120만개의 훈련 샘플(training examples)들을
학습시키기에는 GPU의 용량이 부족합니다.
때문에 저자들은 두개의 GPU를 병렬로 사용하였습니다.
저자들이 사용한 병렬 구조(parallelization scheme)는 각 GPU에
커널 혹은 뉴런의 반개(half)를 배치하고 추가적인 트릭을 사용하는 구조입니다.
여기서 추가적인 트릭은 모델의 특정 층에서만 GPU끼리 서로 통신하는 것입니다.
(the GPUs communicate only in certain layers)
예를들어 3번째 층의 커널은 2번째 층의 모든 커널맵을 입력으로 받지만
4번째 층의 커널은 오직 같은 GPU에 있는 3번째 층의 커널맵을 입력으로 받습니다.
논문에 따르면 이러한 구조로 GPU를 병렬사용 했을 때 top-1 / top-5 에러 비율이
각각 1.7% / 1.2% 감소했다고 주장합니다.
3.3 Local Response Normalization
ReLU를 사용하여 입력에 대해 normalization을 수행하지 않아도 되지만
신경망에 큰 입력이 주어지고 saturating nonlinearities 함수를
활성화 함수로 사용할 경우 saturating gradient problem이 발생합니다.
그럼에도 불구하고 논문의 저자들은 normalization scheme이
모델의 일반화에 도움을 주는것을 발견했다고 주장합니다.
는 번째 커널로 계산된 활성화값 입니다.
또한 는 동일한 공간적 위치에서 n개의 인접한 커널 맵에 대해 계산합니다.
그리고 은 특정 층의 kernel 개수 입니다.
상수 는 하이퍼파라미터로 논문에서 사용한 값은 다음과 같습니다.
논문에서 제안한 normalization 구조를 사용했을때 top-1 / top-5 에러 비율이
각각 1.4% / 1.2% 감소했다고 주장합니다.
3.4 Overlapping Pooling
일반적으로 pooling을 수행할 때는 중복(overlap)되지 않게 수행하지만
논문에서는 3x3 크기와 2픽셀의 간격으로 중복되게 pooling을 수행합니다.
저자들은 이를 통해 top-1 / top-5 에러 비율이 각각
0.4% / 0.3% 감소했고, 모델의 과적합(overfit)을 방지할 수 있었다고 주장합니다.
3.5 Overall Architecture
두번째, 네번째, 다섯번째 합성곱 레이어의 커널들은 같은 GPU의 이전 커널맵을
입력으로 받습니다.
반면, 세번째 합성곱 레이어의 커널은 이전 커널맵 모두 입력으로 받습니다.
Response-normalization 층은 첫번째와 두번째 합성곱 레이어 뒤에 배치됩니다.
또한 3.4에서 설명한 overlapping max pooling을 response-normalization 뒤에,
다섯번째 합성곱 층 뒤에 배치합니다.
ReLU 활성화 함수는 모든 합성곱, 완전 연결층에 적용됩니다.
첫번째 합성곱 층은 224x224x3 입력 이미지를 크기가 11x11x3인
96개의 커널로 연산을 수행합니다. (stride=4)
정리를 위해 자료조사를 해보니 https://learnopencv.com/understanding-alexnet/ 에서는 224x224의 이미지 크기가 논문상의 오류라고 합니다. 실제로 output 크기를 계산해 보면
입니다.
두번째 합성곱 층은 크기가 5x5x48인 256개의 커널로 연산을 수행합니다.
이때 병렬 GPU 연산을 위해서 5x5x96 크기인 커널이 반으로 나뉘어 연산을
수행해야 하기 때문에 5x5x48의 크기를 갖는 128개의 커널이 GPU에 각각 들어가게 됩니다.
(이후에도 마찬가지)
세번째 합성곱 층은 크기가 3x3x256인 384개의 커널로 연산을 수행합니다.
네번째 합성곱 층은 크기가 3x3x192인 384개의 커널로 연산을 수행합니다.
다섯번째 합성곱 층은 크기가 3x3x192인 256개의 커널로 연산을 수행합니다.
3개의 완전 연결층은 각각 4096개의 뉴런을 가지고 있습니다.
4 Reducing Overfitting
과적합(overfitting)을 줄이기 위한 두가지 주요한 방법을 아래에서 설명합니다.
4.1 Data Augmentation
과적합을 줄이기 위한 가장 일반적이고 쉬운 방법은
이미지 데이터를 인위적으로 많이 생성하는 것입니다.
논문의 저자들은 두가지 데이터 증강기법(data augmentation)을 사용하였습니다.
- Random Crop & Horizontal Reflections
- Altering the intensities of RGB
4.2 Dropout
논문의 저자들은 과적합을 줄이기 위한 두번째 방법으로 dropout을 적용하였습니다.
적용되는 위치는 완전 연결층(fully-connected layers)의 처음 두 층에 적용하였습니다.
Pytorch Implementation
논문에서는 병렬 GPU를 사용했지만 저는 단일 GPU를 사용하겠습니다.
또한 Details of learning 섹션에서 가중치 초기화에 대한 내용이 있지만
생략하겠습니다.
구현할 AlexNet의 구조는 아래 그림과 같습니다.
논문의 Figure 2. 에서 보여지는 각 합성곱층의 커널맵 크기를 충족하기 위해서
적절한 padding과 stride 조정이 있습니다.
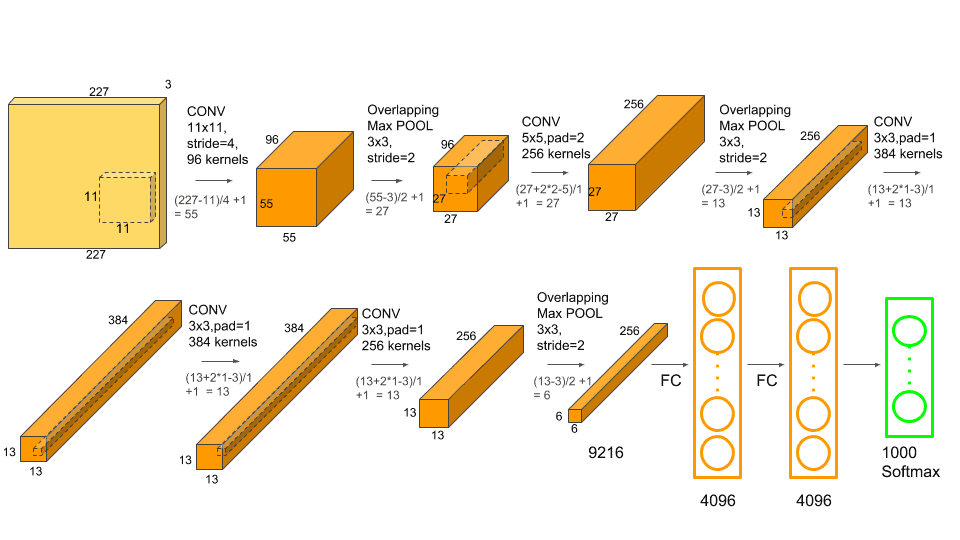
아래 코드는 pytorch로 구현한 AlexNet 입니다.
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, dropout=0.5, norm_size=5, norm_alpha=1e-4, norm_beta=0.75, norm_k=2):
super().__init__()
self.size = norm_size
self.alpha = norm_alpha
self.beta = norm_beta
self.k = norm_k
self.dropout = dropout
self.num_classes = num_classes
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4), nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=self.size, alpha=self.alpha, beta=self.beta, k=self.k),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=self.size, alpha=self.alpha, beta=self.beta, k=self.k),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=self.size, alpha=self.alpha, beta=self.beta, k=self.k),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(p=self.dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=self.dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, self.num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x다음 명령어를 통해 ImageNet validation 데이터셋을 다운로드 합니다. (colab기준 명령어)
colab에서 다운로드 하려니 속도가 느려 개인적으로 다운로드 받았습니다.
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar -P /content/image_net아래 코드는 ImageNet 데이터셋 훈련 코드 입니다.
transform = transforms.Compose([
transforms.RandomResizedCrop(227),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.ColorJitter(hue=0.2),
])
train_dataset = datasets.ImageNet('/content/ImageNet2012', split='val', transform=transform)
train_loader = data.DataLoader(train_dataset, shuffle=True, batch_size=128)
from tqdm.notebook import tqdm
EPOCHS=90
model = AlexNet().to('cuda')
criterion = nn.CrossEntropyLoss().to('cuda')
optimizer = optim.Adam(params=model.parameters(), lr=1e-4)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
train_loss=[]
for i in tqdm(range(EPOCHS)):
model.train()
step_loss = 0
step_per_epochs = 0
for imgs, classes in train_loader:
imgs, classes = imgs.to('cuda'), classes.to('cuda')
output = model(imgs)
loss = criterion(output, classes)
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
step_loss += loss.item()
step_per_epochs += 1
train_loss.append(step_loss / step_per_epochs)코랩 무료환경에서 1epoch 당 대략 15~17분정도 소요됩니다.
(50,000개 validation 데이터셋 기준)
