https://arxiv.org/abs/2211.12905
https://gitee.com/mindspore/models/tree/master/research/cv/ghostnetv2
지난번 VanillaNet을 리뷰하면서 흥미로운 부분이 많았는데요. 그 저자가 GhostNet V2의 저자임을 확인했고, 자연스럽게 이 논문 또한 리뷰하게 되었습니다. 논문의 중심내용은 Ghostnet V1 + DFC layer인데 역시나 중국인이 쓴 논문이라 읽기는 어렵지 않았습니다. (가끔 오타가 있긴하지만요 🤪) 그리고, 논문이 기존 모델에 추가하는 것이 때문에 사알짝 스킵하는 느낌이 없진 않은데, 그래서인지 GhostNet도 같이 보고 싶어졌습니다..ㅎㅎ (TODO+1⭐️)
Introduction & Related Work
GhostNet은 1 x 1 convolution의 채널 반을 cheap한 operation들로 교체했습니다. 그리고, 오늘 소개할 GhostNet V2는 GhostNet을 기반으로 DFC attention이 추가된 모델입니다.
Preliminary
A brief Review of GhostNet
GhostNet은 mobile device에서 효율적인 inference를 위해 디자인된 모델입니다. 이 모델의 main contribution은 Ghost Module인데, 이 모듈은 cheap operation들로부터 더 많은 feature map들을 만듦으로써 original convolution을 대체합니다. 이 과정은 2개의 스텝을 따르는데, 아래와 같습니다.
- input feature:
- intrinsic feature:
위의 방법으로 GhostNet은 computational cost를 줄여주긴 하지만, reprentational ability는 약해질 수 밖에 없습니다. 그 이유는 지역적인 픽셀들간의 관계는 정확한 인식을 하기 위해서 아주 중요한데, GhostNet에서는 cheap한 operation(여기서는 3 x 3 depth-wise conv)에 의해서만 지역 정보들이 반정도밖에 파악되지 않기 때문입니다. 남은 feature들은 다른 pixel들간의 관계성없이 1 x 1 point-wise conv로 만들어지게 되고요.
GhostNet의 하나의 block은 두개의 Ghost Module을 쌓아서 만듭니다. MobileNet V2처럼, 처번째 Ghost module은 output channel수를 늘리기 위해서 레이어 확장시키고, 두번째 모듈은 shortcut에 맞추기 위해서 채널 수를 줄이는 inverted bottleneck 구조로 되어 있습니다.
Revisit Attention for Mobile Architecture
NLP에서 사용하는 attention을 CV에서도 사용하기 위해 만들어진 모델이 있다는 것은 대부분 알고 계실텐데요. ViT는 self-attention module과 MLP module을 쌓은 기본적인 transformet를 사용했고, Non-local neural networks 논문에서는 self-attention을 사용하여 non-local 정보를 잡아냈습니다. 근데, 이런 전형적인 attention module은 feature 사이즈에 대해 quadratic complexity를 가지는데 object detection나 semantic segmentation과 같은 task에서의 high-resolution 이미지들에 맞추기 힘들어지죠.
이런 복잡도를 줄이기 위해서 이미지를 여러 window에 나누고 window안에서또 windows들을 겹쳐서 attention operation을 수행하는 방법에는 Swin Transformer와 MobileViT가 있습니다. 그치만 여전히 light-weight 모델들과 infence time면에서는 견줄 수 없을 정도로 느리죠. 실제로 Ghostnet에 MobileViT의 sef-attention을 도입해봤을때 속도가 두배가 되는 걸 볼 수 있었다고 합니다.
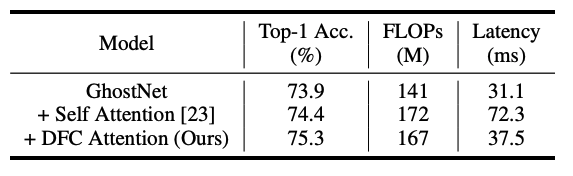
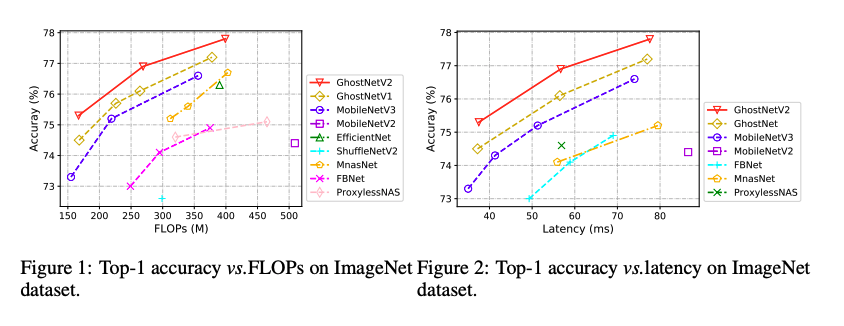
그리고, DFC Attention을 사용했을때는 약간의 infernece 시간만 늘려서 정확도를 높였습니다. 그럼 다음 파트에서부터 본격적으로 GhostNet V2의 메소드들을 보죠.
Approach
DFC Attention for Mobile Architecture
우선은 attention 모듈을 개발할때 다음과 같은 목적들을 가졌다고 합니다.
- Long-range: lightweight CNN들은 computational cost를 줄이기 위해서 작은 conv filter를 이용하는데, 이때 representation ability를 보강또는 강화해줄 만한 long-range 지역 정보를 잡아내는 attention이 필요합니다.
- Deployment-efficient: inference time에 확실하게 효율적이여야 합니다.
- Concept-simple: 다양한 task에서의 일관성을 유지하기 위해서 너무 섬세한 디자인은 피하고 개념적으로 단순해야합니다.
Swin Transformer나 MobileViT 같은 모델의 self-attention은 long-range면에서는 좋지만 Deployment-efficient면에서 부족합니다. 그리고 그들과 비교했을때, FC layer는 고정된 weights로 사용하기에 간단하고 쉬울 뿐만 아니라, global한 receptive field로 attention map을 만들 수 있죠. 자세한 과정은 아래와 같습니다.
feature 가 주어졌을때, 로 보여집니다. FC layer를 바로 실행하여 attention map을 만듭니다. - : element-wise multiplication, : FC layer의 learnable wieghts, : 생성된 attention map
위의 식은 learnable weights들과 모든 token들을 합침으로써 global 정보들을 잡아낼 수 있고, self-attention보다 훨신 간단하죠. 그러나 여전히 feature size에 대한 복잡성()을 줄이긴 힘들죠. 예를 들어서, GhostNet의 4번째 레이어는 56*56=3136개의 token을 가지고, 복잡성이 높아질 수 밖에 없습니다. 사실, CNN의 feature map은 low-rank이기 때문에, 모든 다른 지역 위치에 있는 input token과 output token들을 연결할 필요가 없습니다. 피쳐의 2D shape은 FC layer 계산을 줄이는데, 이걸 위의 식에 적용하면 아래와 같이 분해되고, 수직 수평적으로 모아서 표현이 가능합니다.
- : transformation weights
위의 두 식을 통해서 input인 original feature 는 순서대로 피처를 적용받게 되고, long-range정보를 잡아낼 수 있게 됩니다. 이 과정의 연산을 decoupled fully connected(DFC) attention이라고 했습니다.
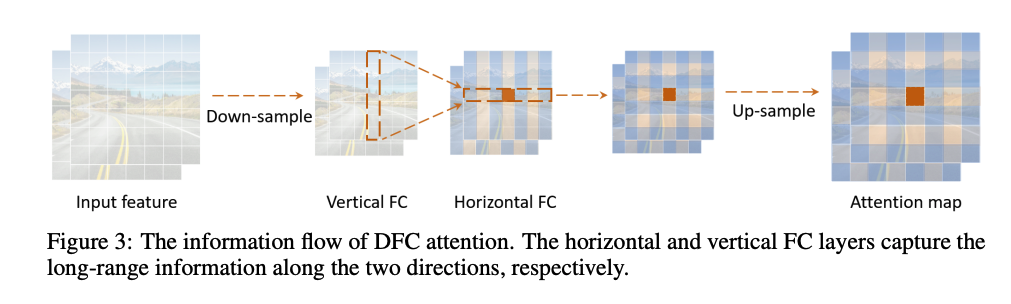
이렇게 수직 수평으로 나눔으로써의 장점은 복잡도를 로 줄일 수 있다는 거죠. attention 전체에서는 사각형으로 나뉜 부분들의 모든 패치들이 집중된 패치에 연산 집중을 할 수 있게됩니다. DFC attention에서는 하나의 patch가 수직 수평 라인에서의 패치들에 의해 합쳐지고 다른 패치들은 다른 패치들의 수직 수평에 있는 패치들과 연산하면서 집중된 token과의 직접적이지 않은 관계성을 가지게 됩니다. 따라서 하나의 패치의 계산은 사각형 지역에 있는 모든 패치들과 이루어지게 되는거죠.
수직 수평으로 나눠 계산하는 과정에서는 transformation weights의 한 부분을 공유함으로써, tensor reshaping이나 tranposing같은 연산을 안하게 되어 inference 속도를 향상시키는 편한 연산을 하게 됩니다. 이러면 다양한 크기의 input 이미지들을, 각각 두개의 depth-wise 연산의 kernel 사이즈를 1 x , x 1이라고 할때, 의 복잡도로 연산 가능하죠. 그리고 이런 연산법은 TFLitedhk ONNX에서 잘 되는 것을 확인했다고 합니다.
GhostNet V2
Enhancing Ghost Module
앞부분에서 Ghost Module의 피쳐 반만 다른 픽셀들과 상호작용을 하여 지역 정보를 가져오는데에 손해를 볼 수 있기 때문에, DFC attention을 도입하여 Ghost Module의 output feature Y가 다른 지역 픽셀들과의 long-range dependence를 가지게 했죠.
input feature가 두개의 브랜치로 보내는데, 하나에서는 Ghost Module에서 output feature Y를 만들고, 다른 한쪽에서는 DFC module에서 Attention Map 를 만들어냅니다. 전형적인 self-attention들은 linear transformation layer에서 input feature를 attention map을 연산하기 위한 query와 key로 변환하는 것처럼, 1 x 1 conv를 이용하여 모듈의 input X를 DFC의 input Z로 변환합니다. 그리고 모듈의 마지막 output 은 두 브랜치의 output으로 만들어지는 거죠.

위의 그림처럼 정보가 합해지는 겁니다. Ghost Module과 DFC attention은 같은 인풋에 대해 병렬적으로 다른 관점에서 정보를 추출하게 되고, 그럼 그 통합된 아웃풋은 element-wise해지는 겁니다.
Feature downsampling
Ghost module이 아주 효율적인 연산이긴 하지만, DFC와 병렬적으로 연산하게 되면, 추가적인 cost가 드는 건 강연합니다. 따라서 논문에서는 수평 수직으로 down-sampling을 통해서 feature size를 줄여서 DFC 모듈이 작은 feature에서 이루어질 수 있도록 했다고 합니다. 디폴트로, 그 줄여지는 사이즈는 오리지널의 반이라고 합니다. (75% FLOPs를 줄였습니다.)
그리고 ghost module과 통합될때는 다시 upsampling을 합니다. 이 과정에서 저자들은 naive하게 average pooling하고 bilinear interpolationdmf downsampling과 upsampling을 썼습니다. 그리고 sigmoid를 바로 하면 latency가 늘어나기 때문에, down sampling된 feature에 적용했습니다. 참고로, sigmoid가 특별한 영향을 주지 않는다것도 확인했다고 하네요.
GhostV2 bottleneck
GhostNet은 두 Ghost module을 포함시키는 inverted residual bottleneck을 채택하였습니다. 첫번째 모듈에서 더많은 channel로 확장된 feature을 만들고, 두번째에서는 채널 수 를 줄여 output feature를 얻죠. 이런 inverted bottleneck 자연스럽게 모델이 "표현력"과 "수용력"을 가지게 합니다. 그리고 DFC는 이 두가지 중 "표현력"을 개선해주는 것이고, 그래서 DFC attention에서 확장된 feature를 multiply해주는 것 입니다.

위의 그림이 GhostV2 bottleneck을 표현한 것 입니다.
Experiments
아래는 다양한 dataset과 다양한 task에서의 결과를 보여줍니다.
모델의 속도는 TFLite tool을 이용하고, arm-based 휴대폰에서 측정했을때 37ms라고 기록했습니다.

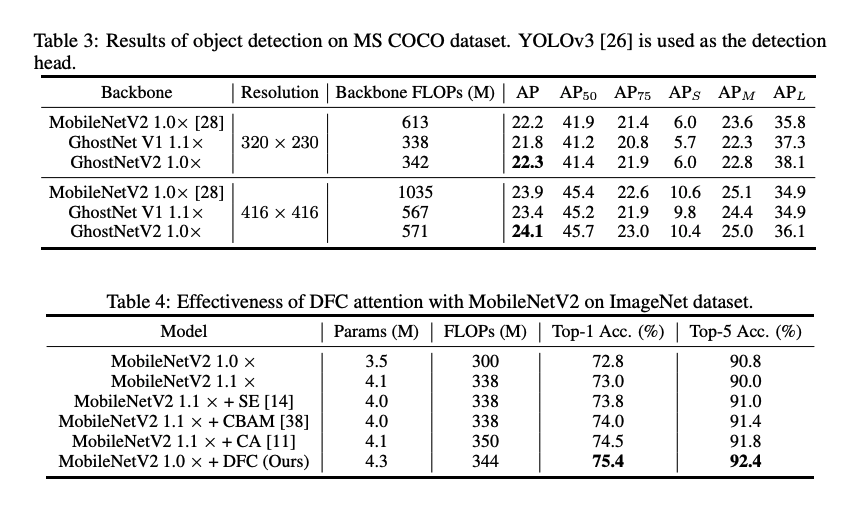
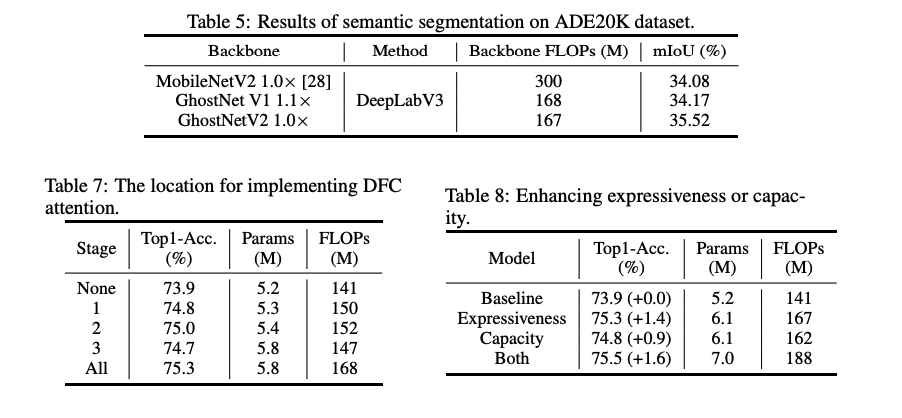
또한, DFC Attention의 kernel size와 DFC를 어디에서 하는지에 따른 결과는 아래와 같습니다.
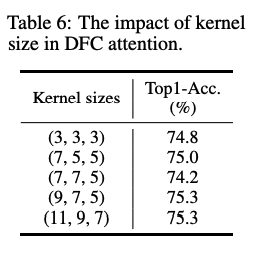
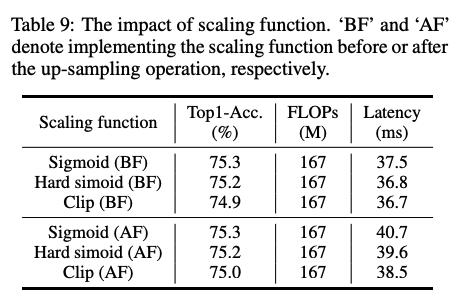
위에서 naively하게 upsampling, downsampling 방법을 채택했는데, 아래처럼 차이가 없기 때문인것으로 보입니다.

