이번 논문은 2022년 6월에 Apple🍏에서 낸 논문이며 CVPR 2023입니다. 이해가 되게 아주 세심하게 잘 작성되어 있어서, 편하게 읽기 좋았습니다. 뭔가 아이폰같은 느낌의 논문이였습니다. 기본에 충실하면서 간단한데도 섬세한 느낌이랄까요...😆
https://arxiv.org/pdf/2206.04040.pdf
https://github.com/apple/ml-mobileone
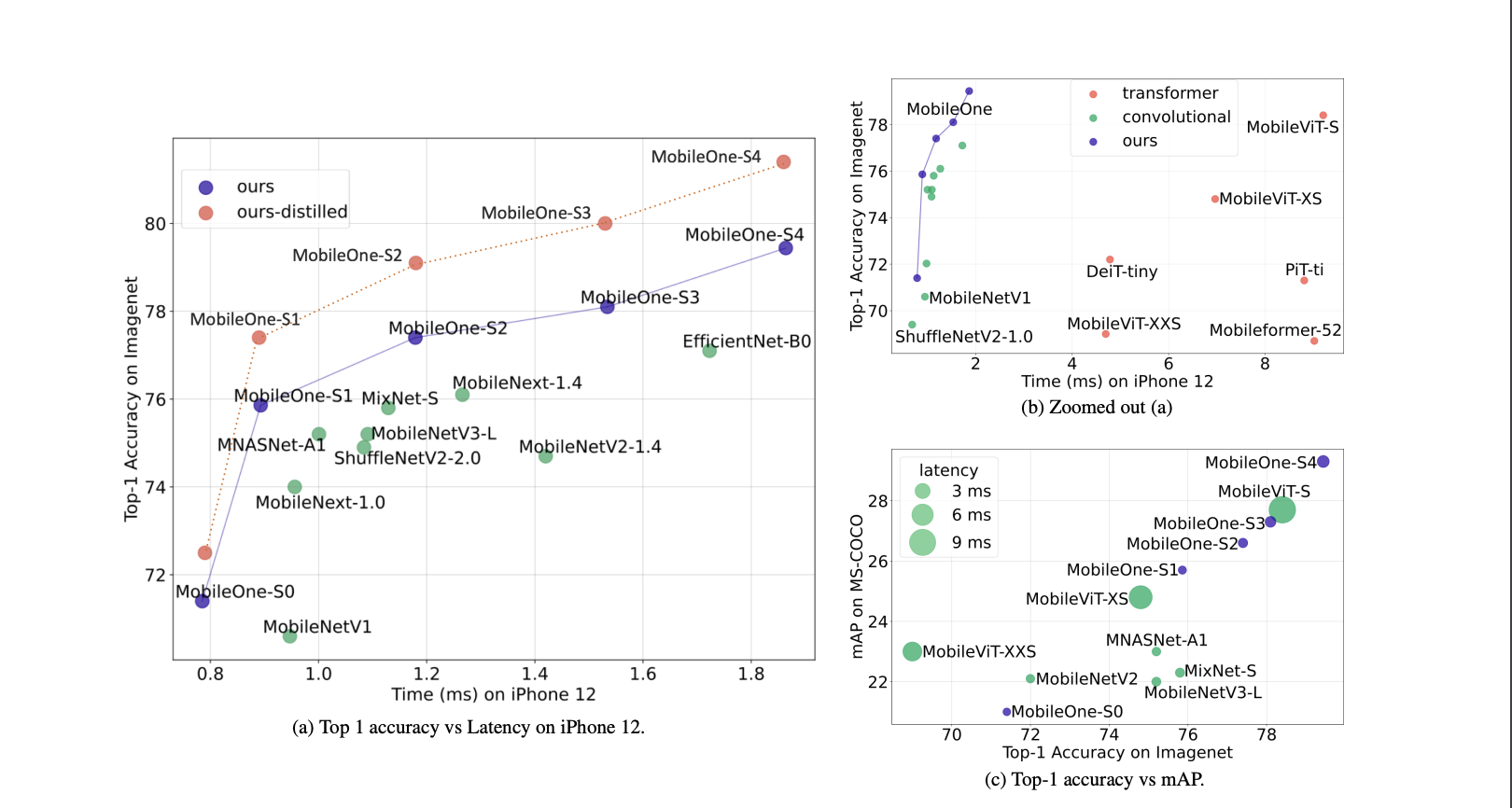
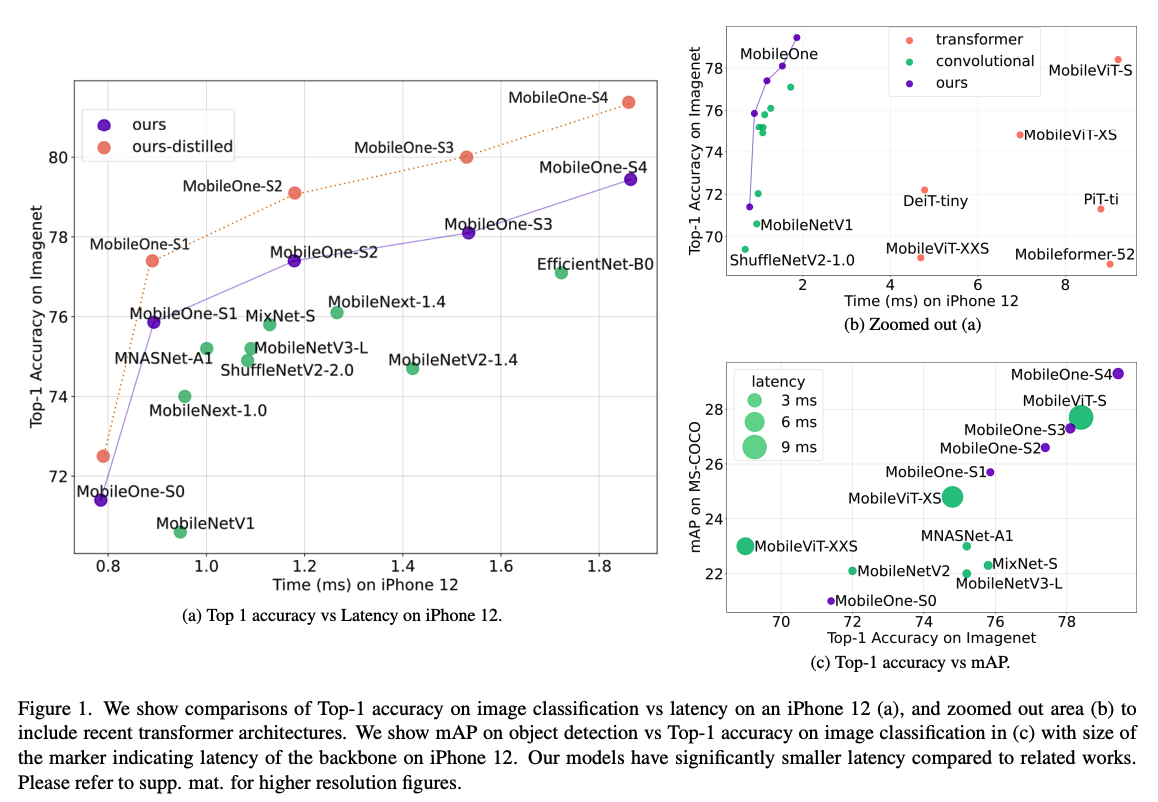
저자들은 기존의 효율적인 NN들의 구조적 그리고 최적화면에서의 bottleneck에 대해서 분석하면서 이런 병목들을 줄였고, 그렇게해서 MobileOne을 개발했다고 합니다. 제목에서도 볼 수 있듯이 (Iphone 12 기준) 1ms의 inference time을 가지면서 높은 성능을 유지합니다. 심지어, transformer 계열인 Mobileformer보다 38배나 빠른데 비슷한 성능을 낸다고 합니다.😲 ("애플이 애플했다")
문장을 쓸때 너무 딱딱하게 쓰는 것 같아서, 이모티콘도 붙이고 주절주절하다 보니 서두가 길어지는 것 같은데, 다시 정신 차리고 리뷰해보겠습니다. ㅎㅎ
Introduction
모바일 디바이스를 위한 deep-learing architecture(Mobileformer, MobileNet V2 와 V3, ShuffleNetV2, MobileViT)들이 많이 나왔는데, 이들은 대부분은 FLOPs와 파라미터 수를 줄이는 방법을 택했죠. 하지만, 이런 metrics는 latency와 완전한 상호작용을 하는 건 아니죠. 예를 들어, parameter sharing은 FLOPs을 높이지만 model size는 줄이고, skip-connection이나 branching 같은 파라미터가 적은 연산들은 오히려 memory를 많이 잡아 먹습니다.
MobileOne의 저자들은 on-device에서의 구조적 그리고 최적화적인 면에서의 병목을 중요하게 봄으로써 정확도를 높이는 동시에 latency가 적은 모델을 목적으로 하였습니다. 목적에 맞게 세가지 포인트를 보시면 되는데요. 두번째 요소를 해당 저자는 키포인트로 봅니다.
- 구조적 아키텍처를 분석하기 위해, Iphone상에서 CoreML을 이용한 NN들을 실행하여 벤치마크 했습니다.
- 최근 백본들을 모바일에서 실행하며, 지연이 많은 곳인 activation과 branching에서의 성능 병목을 분석하였습니다.
- 최적화 병목을 줄이기 위해, train-time과 inference-time을 나누었습니다.
- train-time에 선형적으로 over-parameter된 모델을, inference할때는 선형적 구조들을 re-parameterizing합니다.
- 최적화 병목을 더 줄이기 위해, 이미 작은 모델이 과도하게 정규화 되는것을 train하는 동안 다이나믹하게 regularization 완화합니다.
그리고, 저자는 표를 세개나 한번에 보여주면서, MobileOne은 Iphone 12에서 했서 1ms의 성능을 보였지만, CPU나 GPU에서는 일반적으로 높은 성능과 빠른 속도를 보여준다고 자부합니다.👍
Methods
Metric Correlations
모델을 비교할때 흔하게 사용하는 지표가 parameter 수와 FLOPs인데, 현실에서 저희 같이 실시간으로 on-device에서 빠르게 사용하기 위한 판단지표로는 뭔가 부족하다는 것을 많이 느끼셨을 겁니다. 그래서, 저자들은 일단 기존 모델들을 분석부터 했습니다.

그들은 위 표를 통해서 파라미터 수가 많은 모델들이 latency가 적은 것을 확인했고, Mobilenet이 다른 모델들과 비슷한 FLOPs임에도 더 빠른 걸 확인했죠.
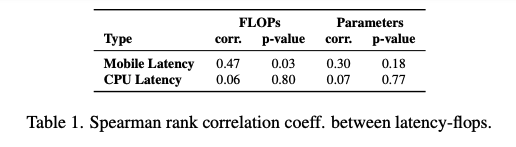
그리고, 위의 spearman rank를 비교를 통해서, latency는 mobile에서 FLOPs와는 상관이 있는데, 파라미터 수는 그닥 상관이 없음을 발견했습니다. 특히 CPU는 더 상관이 없다고 합니다.
Key Bottlenecks
Activation Functions

activation 함수들 또한 iphone 12에서 비교를 해봤는데, 성능향상에 도움을 준 새로운 활성함수들이 정확도 개선을 높였을진 모르지만, latency를 아주 많이 발생시키는 것을 발견했습니다. 그래서, 저자들은 ReLU를 쓰기로 했습니다.
Architectural Blocks

runtime 성능에 영향을 주는 것은 memory access와 parallelism정도 인데요. Memory access cost는 각각의 branch에서 다음 텐서까지 가는데 저장을 하기 때문에, activation같은 multi-branch 구조에서 병목이 생기기 때문에 최대한 적게하는 것이 좋다고 합니다. 또한, global pooling같은 경우의 synchronization도 속도를 느리게 하는 원인이되는 것을 확인하였다고 합니다.
그래서, 저자들은 inference할때 branch를 사용하지 않았고, Squeeze-Exite Block을 가장큰 variant로 제한해서 사용하면서 성능을 올렸다고 합니다.
MobileOne Architecture
MobileOne Block
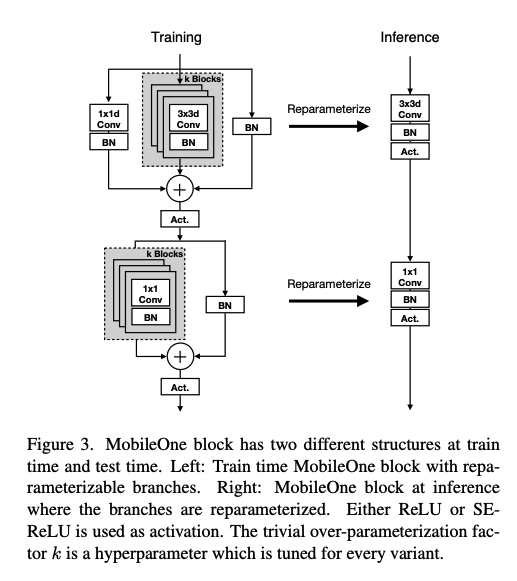
MobileOne block은 AcNet, Diverse branch block, Repvgg, Expandnets에서 사용한 block들과 비슷한데, 차이점은 depthwise와 pointwise 레이어들을 열거한데에 있습니다. 추가로, 정확도를 높여줄 확실한 over-parameterization을 넣어줬습니다. 이때 over-parameterization factor k는 1에서 5까지 Table 4에 나온 것처럼 적용했습니다.
기본 블럭은 1 x 1 pointwise와 3 x 3 depthwise를 쓰는 Mobilenet V1을 썼고, inference time때 reparameter할 수 있는 batch normalization과 Repvgg에서 나온 skip connection을 추가합니다.
그리고 인퍼런스할때는 앞부분에서 언급된것과 같이, reparameterization을 통해서, 어떤 branch도 사용하지 않게 합니다.
reparameterization
- inference할때, conv와 BN은 linear 연산이기 때문에, 하나의 conv로 바꿀 수 있습니다.
- 기존 conv에서
- BN의 mean , 표준 편차 , scale , bias 라고 할때,
- 새로운 conv는 가 될 수 있습니다.
- skip connection에서의 BN은 Repvgg에서 나온 것처럼 후에 K-1개의 0으로 패딩되는 identity 1 x 1 kernel의 conv로 바꿀 수 있습니다.
- 각각의 branch가 다 접히고나면(논문에서 변환되는 것을 접힌다고 표현), M개의 branch가 있던 모델이 를 가진 conv로 바뀌게 되는겁니다.

위의 테이블을 보면, reparameterizable branch의 유무에 따라서 성능 차이가 있다는 것을 알 수 있습니다.
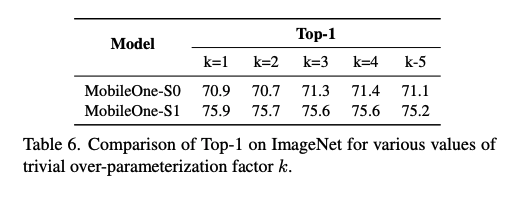
Table 6에서 볼 수 있듯이, over-parameterization factor k에 따라서 성능 또한 달라집니다.
Model Scaling

MobileOne에서는 MobileNet V2와 비슷한 depth scaling을 합니다. Table 7에서는 5개의 다른 width scale을 보여줍니다. 그리고, 저자들은 mobile에서 사용하는 목적에 맞지 않게 FLOPs와 memory소모가 커질 수 있어, input resolution의 scaling up을 사용하지 않았습니다.
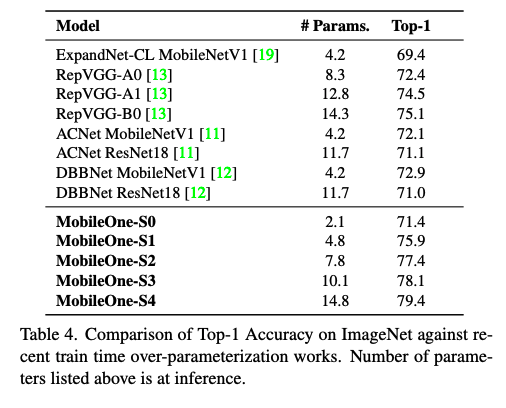
인퍼런스할때, MobileOne은 multi-branch 구조가 아니기 때문에, 데이터가 이동될 때 드는 cost가 없는데, 이 점은 model parameter를 과격하게 조절할 수 있는 부분에서 MobileNet V2이나 EfficientNet보다 좋다는 것이 확실하죠. 그리고 MobileOne-S1이 over-parameterization 을 썼던 RepVGG-B0보다 세배 작은데 성능이 더 좋다고 합니다.
Training
일반적으로 큰 모델들보다 작은 모델들이 overfitting을 방지하기 위해서 regularization을 덜 하죠. 학습 초기에 weight decay를 하는 것이 중요한데, 완벽히 weight decay regularization을 없애기 보다는, 저자들은 학습과정에 따라 weight decay regularization에서 생기는 loss을 annealing하는 것이 더 효과적임을 찾아냈습니다. MobileOne 학습에는 cosine schedule을 썼고 그에 맞게 weight decay를 annealing 하였습니다.
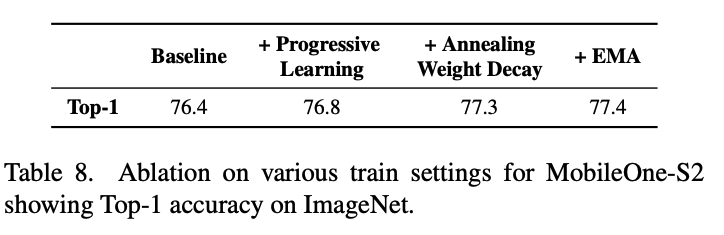
그리고, Efficientnetv2에서 사용한 progressive learning carriculum을 사용해서 성능을 향상시켰다고 합니다.
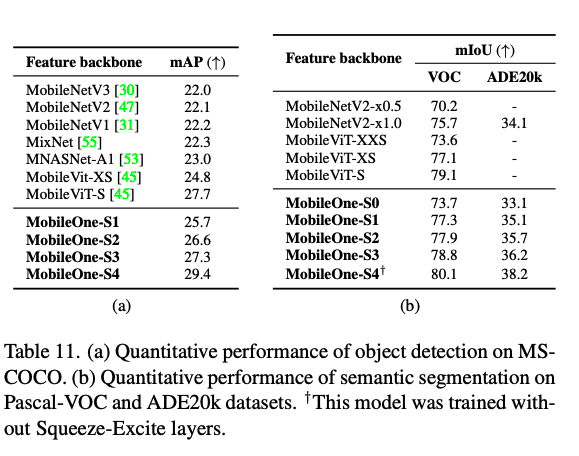
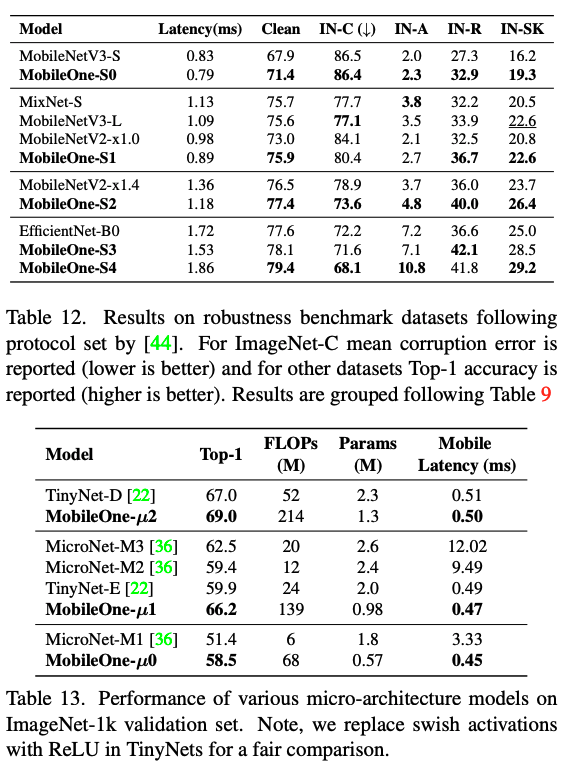
Experiments
다음은 다양한 테스크에서의 MobileOne의 성능들을 보여줍니다.