[Compression] Channel-Wise Autoregressive Entropy Models for Learned Image Compression (ChARM) 리뷰
Image Compression
논문 제목
Channel-Wise Autoregressive Entropy Models for Learned Image Compression (ICIP 2020)
URL: https://arxiv.org/abs/2007.08739
인용수 : 386회 (24.12.18 기준)
이 논문은 STF,WACNN 모델이나 LIC-TCM 모델과 같은 여러 SOTA 방법론에 자주 사용되는 엔트로피 모델(컨텍스트 모델)입니다. 기존의 AutoRegressive 모델의 Complexity를 줄이기 위해 나온 방법이 Channel-Wise Autoregressive Entropy Model과 Checkerboard Context Model등이 있습니다.
tmi - ELIC의 SCCTX (Space-Channel Context Model)이나 MLIC++의 MEM++ (Multi-reference Entropy Model)은 Checkerboard Context Model을 기반으로 만들어졌습니다.
컨텍스트 모델은 Channel-Wise AutoRegressive와 Checkerboard 이렇게 두 엔트로피 모델이 자주 사용되고 있다정도로 알고 계시면 될 것 같습니다.
- AutoRegressive (AR)
- 느림
- 초기모델
- Checkerboard (Ckbd)
- AR보다 40배 빠름
- AR 방법들 보다 성능이 조금 떨어짐 (성능과 속도는 trade-off)
- 세 방법 중 제일 빠름
- Channel-Wise AutoRegressive (ChARM)
- 성능 준수
- AR보다 빠른 속도
컨텍스트 모델의 속도비교
Ckbd (2021) > ChARM (2020) > AR (2018)
이 정도만 알아두시면 딥러닝 기반의 이미지 압축 (LIC)의 논문은 충분히 이해가 가능할겁니다.
속도 비교는 최초 제안된 방법을 기준으로 했기 때문에, 각종 변형 방법들은 성능이 바뀔 수도 있습니다.
Abstact
- 딥러닝 기반 이미지 학습은 entropy-constrained autoencoder 형태를 가지며, forward 와 backward adaptation을 사용하는 엔트로피 모델을 가진다.
- 하지만 엔트로피 모델은 serial processing을 필요로 하여 GPU/TPU를 효율적으로 사용하지 못하는 문제가 있음.
- 이를 보완하기 위해 channel-conditioning과 latent residual prediction(LRP)을 도입하여 성능 개선과 직렬처리 최소화 아키텍쳐를 제안.
Channel-Conditional Entropy Models
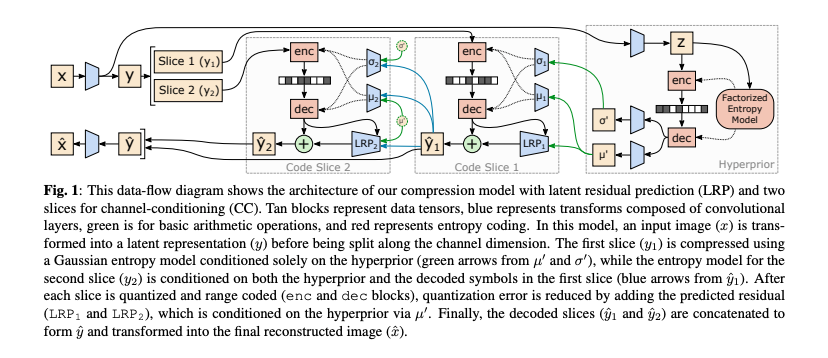
이 모델은 Balle의 Hyperprior 아키텍쳐를 기반으로 구성되었다고 한다. 이 모델은 hyper-latent 텐서를 생성하도록 학습하고, 이는 side information으로 압축 및 전송된다.
여기서 이 텐서를 사용해서 입력 이미지를 나타내는 심볼의 엔트로피 파라미터를 예측하는 방식으로 학습된다.
Hyperprior 모델은 일반적으로 scale로 매개변수화된 conditional Gaussian model을 사용하거나 scale과 mean을 함께 사용하며, 가장 효과적인 모델은 hyperprior (forward-adaptation)과 spatially autoregressive model (backward-adaptation)을 결합하여 엔트로피 파라미터 와 를 예측한다.
이렇게 컨텍스트 모델을 사용하면 공간적 상관관계를 더 잘 모델링할 수 있지만 대표적인 spatially autoregressive(AR)방법의 경우 심볼단위를 직렬 처리하면서 디코딩 시간이 느려지고 GPU와 TPU의 병렬처리능력을 충분히 활용하지 못하게 된다.
이 문제를 해결하기 위해, 본 논문에서는 channel-conditioning(CC) 모델을 제안했다. 이 모델은 잠재 텐서를 채널 차원으로 N개의 거의 동일한 크기의 슬라이스로 나누고, 각 슬라이스의 엔트로피 파라미터를 이전에 디코딩된 슬라이스에 조건화한다.
그림1은 CC의 아키텍쳐이며, 파란색 화살표는 가 에 condition으로 사용되는 것을 나타내며, 더 많은 슬라이스를 포함하는 모델에서는 가 ,에 condition으로 적용된다.
따라서 CC 모델은 공간차원이 아닌 채널 차원에 따라 autoregressive를 수행한다고 할 수 있다.
Latent Residual Prediction (LRP)
오토인코더 모델은 픽셀값을 실수 값으로 이루어진 latent값 y로 변환하도록 학습되며, 이 latent는 무손실 압축 이전에 양자화된다. 이 과정에서 residual error가 발생하며 이는 양자화된 latent 값이 픽셀 영역으로 다시 변환될 때 추가적인 distortion으로 나타낸다.
residual error는 아래 수식과 같다.
Latent residual prediction은 하이퍼프라이어 및 이미 디코딩된 슬라이스를 기반으로 이 양자화 오차를 줄이는 것을 목표로한다. 예측된 residual 값은 슬라이스 단위로 양자화된 latent 값에 추가되며, 이를 통해 LRP는 distortion을 줄이고 엔트로피를 감소시키는 두 가지 방식으로 개선된 결과를 얻을 수 있다.
이는 이후 슬라이스를 인코딩하는 데 사용되는 엔트로피 파라미터가 LRP를 포함하는 이전 슬라이스에 conditioned되기 때문이다.
Training with Rounded Latent Values
모든 압축 모델은 양자화로 인해 미분이 불가능해져서 gradient가 0 또는 무한대가 되는 문제를 겪으며, gradinet기반 최적화를 방해하는 문제가 있다.
일반적으로 quantization noise를 추가해서 gradient를 유지하는 방법을 사용한다. 이를 위해 uniform noise를 추가하거나,straight-through gradients(STE)를 사용해서 실제 양자화 대신 신호를 그대로 통과시키는 방식을 사용했었다.
이 논문에서는 uniform noise를 추가하는 방식을 사용했다. 수식은 아래와 같다.
최종 제안하는 mixed approach는 synthesis transform(디코더)에 전달될 때는 노이즈 텐서를 반올림(round)된 텐서로 대체한다.
정리하면 엔트로피 모델 학습을 위해서는 uniform noise를 추가해서 gradient 기반의 학습이 가능하게 했고, 디코더에서는 round 기반 양자화 텐서를 사용하는 혼합 접근법을 사용했다. 이 접근법의 비교 실험에서 가장 최적의 방법이었다고 한다.
Experimental Results
이 논문에서는 CC, LRP, round-based training을 사용을 통해 얻는 효과를 평가했다.
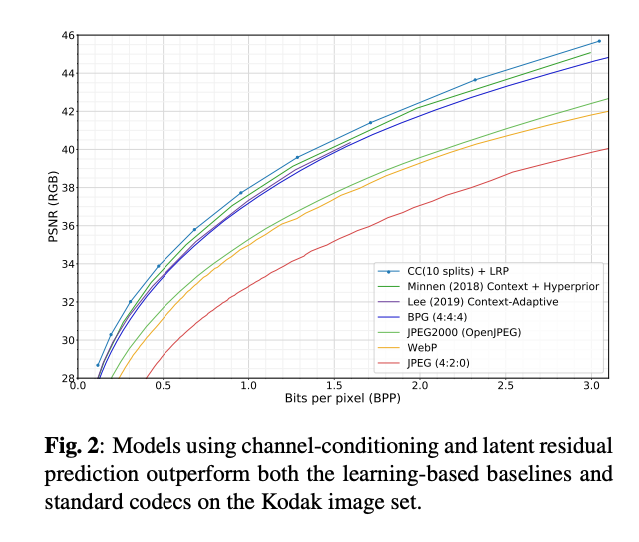
제안 방법이 전통적인 압축 방법 뿐만아니라 Hyperprior와 Context+Hyperprior 모델 보다 우수한 성능을 보였다.
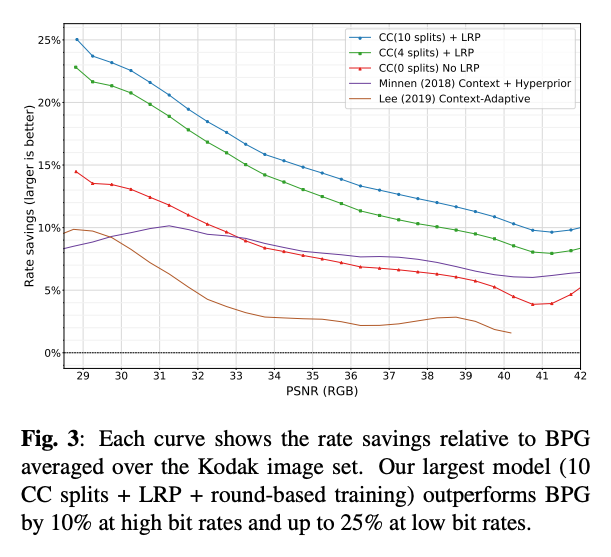
그림3은 다양한 이미지 품질 수준에서 BPG와 비교한 relative rate savings을 보여준다. 채널을 나누는 슬라이스의 개수가 많아질수록 성능으 향상되는 것을 알 수 있다.
Number of Channel-Conditional Slices
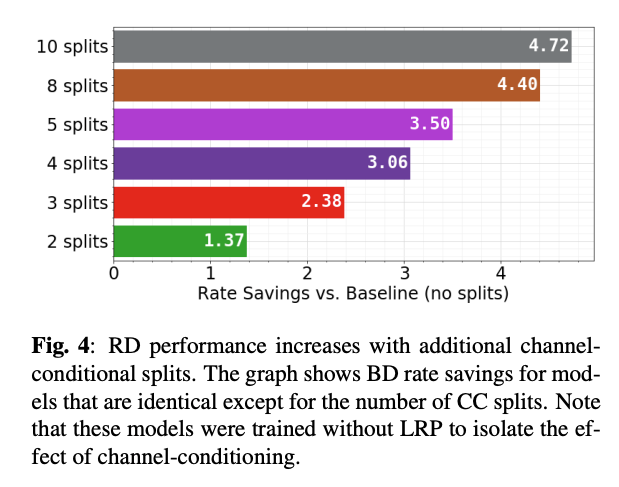
그림 4는 CC에서 슬라이수의 수가 증가함에 따라 rate saving이 증가하는 것을 보여준다. latent tensor를 더 많은 슬라이스로 분할하면 채널 간의 의존성을 더 잘 모델링할 기회가 늘어나서 엔트로피가 줄어든다고 한다. 하지만 이는 추가적인 계산 비용을 발생시키며, 슬라이스 수가 늘어날 수록 RD 성능에 대한 benefit이 점차 감소한다고 한다.
Latent Residual Prediction
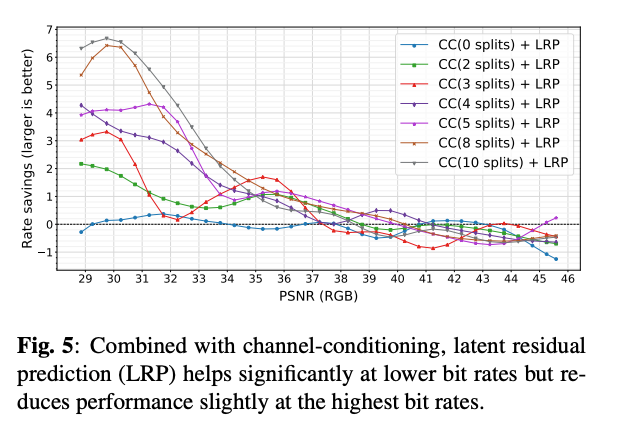
그림 5는 다양한 CC의 채널 분할 수에 따른 LRP의 효과를 보여준다.
결과를 해석하면 다음과 같다.
1. CC를 사용하지 않은 모델은 효과가 거의 없다.
2. 모든 CC 슬라이스 수에 대해서 LRP는 높은 bitrate 영역에서는 RD성능을 약간 저하시키지만, 낮은 비트레이트 영역에서는 향상을 보였다.
3. CC 슬라이스 수가 많을수록 LRP의 향상률이 증가하며, 10개의 슬라이스를 사용하는 모델에서 압축 성능이 6% 이상 개선되었다.
Rounding-based Optimization
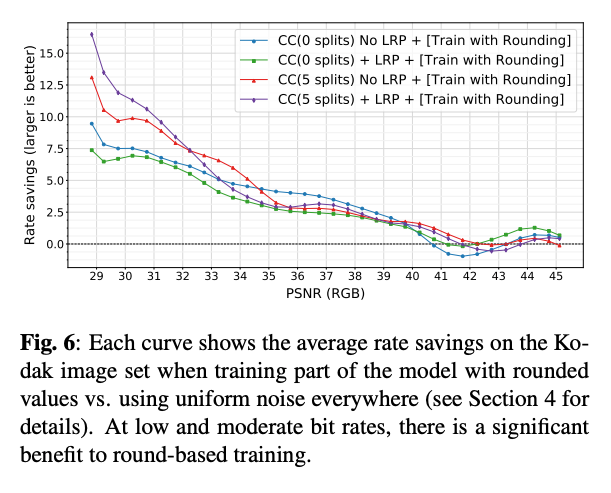
그림 6은 양자화된 텐서를 처리할 때 noise 와 round-based 방식을 혼합한 훈련의 결과이다.
- 모든 케이스에서 높은 이미지 품질에서는 round-based 훈련의 이점이 미미하지만, 낮은 bitrate에서는 큰 효과를 보였다.
- "CC(5 splits) + LRP" 모델의 경우, 낮은 bitrate에서 15% 이상의 saving을 보였다.
Discussion
- CC와 LRP, round-based training 결합을 통해 직렬처리 학습을 최소화하면서 context-adaptive 모델을 능가하는 아키텍쳐를 제안했다.
- 기존의 Hyperprior와 AR기반의 Context Model보다 높은 성능을 보임.
- 향후 연구에서는 channel-conditioning과 spatial context modeling을 결합하여 두 접근법이 상호보완적인지 확인할 계획이라고 함.
이 논문에서 AR기반의 컨텍스트 모델의 직렬 문제를 보완했다고했는데 정확한 인코딩 / 디코딩 속도 비교가 없어서 아쉽긴 했지만, 이미지 압축에서 아주아주 핵심적인 논문이기 때문에 꼭 코드와 같이 보시는걸 추천드립니다.
