[Compression] Window-based Channel Attention for Wavelet-enhanced Learned Image Compression 리뷰
Image Compression
논문 제목
Window-based Channel Attention for Wavelet-enhanced Learned Image Compression (ACCV 2024 Accepted)
URL: https://arxiv.org/abs/2409.14090
인용수 : 0회 (24.12.16 기준)
SOTA를 갈아치우고 있는 딥러닝 기반 압축 기법은 크게 세 종류라고 할 수 있습니다.
1. CNN 기반 모델
2. Transformer 기반 모델
3. Mixed CNN-Transformer 기반 모델
이렇게 총 세부류가 있으며, 모델 별 각각의 장단점을 가지고 있습니다. 이 외에도 2D Gaussian Splatting(GS), Implicit Neural Representation(INR), Diffusion 등의 Image Reconstruction 기법들도 이미지 압축 연구에 적용되어 디코딩 시간을 대폭 줄인 결과들이 존재했으나, 엄청난 모델 학습시간과 더불어 JPEG2000, BPG와 경쟁해야하는 성능 때문에 아직까진 SOTA에 다가가긴 무리가 있어보입니다.
오늘은 세 부류의 방법 중 Mixed CNN-Transformer 연구를 진행한 논문을 리뷰해보려 합니다. 제목은 Window-based Channel Attention for Wavelet-enhanced Learned Image Compression입니다. 이 논문은 Learned Image Compression with Mixed Transformer-CNN Architectures (LIC-TCM) 모델을 기반으로 연구를 진행하였습니다.
Abstract
- LIC 모델은 CNN, Transformer, Mixed CNN-Transformer를 base block으로 사용한다.
- 하지만 shifted window attention, Swin-Transformer 기반의 LIC 방법은 더 넓은 receptive fields를 모델링하 제한되기 때문에 큰 객체를 모델링하는 능력이 떨어짐.
- 문제점을 해결하기 위해 window partition을 channel attention에 통합하여 더 넓은 receptive fields와 global information을 캡쳐한다고 하며, 이를 Transformer 블록에 적용했다고 한다.
- 주파수 기반 다운샘플링을 위해 DWT (Discrete Wavelet Transform)를 사용하였고, 제안하는 Spatial-Channel Hybrid(SCH) framework에 적용하여 receptive fields를 더욱 확장했다고 함.
Introduction

압축의 서사는 생략하였음.
본 논문에서는 Swin-Transformer의 shifted window attention을 window-based channel attention으로 대체하여 기존 채널 어텐션 방법보다 확장된 receptive fields와 더 많은 global dependencies를 캡쳐한다. 위 그림1을 보면 (c)와 (d) 방법이 더 넓고 object와 유사한 ERF를 나타내는 것을 확인할 수 있다.
ERF의 색상은 값이 증가할 수록 파란색에서 빨간색으로 변한다.
다른 연구에서는 Discrete Wavelet Transform을 도입하여 receptive fields를 효과적으로 확장했다고 한다. DWT는 이미지를 다양한 주파수 특성을 가진 하위 이미지로 분해하며, 이는 수용 영역을 확장하기 위한 매개변수 없는 다운샘플링 방법으로 작동한다. LIC 분야에서도 DWT는 이미지의 세부 정보를 효과적으로 인코딩하고 LIC에서 비트 할당을 최적화하기 위해 연구된 사례들이 존재했다.
본 연구의 contributions은 아래와 같다고 한다.
- 지역 정보 학습을 위한 residual block과 space attention module, 전역 정보 학습을 위한 channel attention module을 포함하는 Space-Channel Hybrid(SCH) 프레임워크를 제안.
- 채널 어텐션에 window partition을 처음으로 합쳐서 더 많은 전역 정보를 포착하고 LIC를 위한 receptive fields을 효과적으로 확장함.
- SCH 프레임워크는 다양한 해상도를 가진 네 개의 데이터셋에서 SOTA급 성능을 보여줌.
Related Work
Learned Image Compression
CNN-based Models
- LIC 방법은 Ballé가 end-to-end LIC model을 최초로 구축했고, 이를 VAE 아키텍쳐와 Hyperprior 모듈을 도입하여 확장함.
- Minnen은 auto-regressive 모듈을 도입하여 엔트로피 모델링을 개선하였고, Cheng은 Single Gaussian Model (SGM)을 Gaussian Mixture Model (GMM)로 대체하고 simplified attention module을 도입했다.
- He는 checkerboard context model을 제안하여 병렬 컴퓨팅을 가능하게 해서 기존 auto-regressive 모듈의 계산비용을 크게 줄였다.
- Minnen은 channel-wise context을 도입하여 기존 auto-regressive 보다 계산 비용을 줄였다.
Transformer-based Models
- Transformer는 컴퓨터 비전 작업에서도 그 장점이 입증되어 LIC 연구에도 적용되고 있다.
- Swin-Transformer, parallel bidirectional Transformer, window-based attention mechanism, multi-head attention 등을 통해 공간 및 채널 간 dependency를 모델링하였음.
- Liu는 efficient parallel Transformer-CNN Mixture (TCM) block을 통해 CNN의 지역적 모델링 능력과 Transformer의 비지역 모델링 능력을 결합하였음.
Channel Attention
채널 어텐션은 주로 특징 채널 간의 상관관계에 집중하여, 공간 차원에 걸쳐 각 채널의 중요도를 모델링하는 메커니즘임.
기존 연구들은 전체 특징 맵의 공간 차원을 압축하여 채널 어텐션 맵을 얻었지만, 이는 과도한 정보 손실을 유발해서 채널 정보 표현의 다양성을 제한한다고 저자는 주장함.
본 연구에서는 window partition을 채널 어텐션 모듈에 도입하여 더 다양한 전역 정보를 학습할 수 있도록 했다고 한다.
Wavelet Transform for Deep Neural Networks
iwave 모델은 학습된 CNN을 필터로 사용하여 wavelet-like transform을 구현한 모델을 도입했고, iwave++을 통해 정보 손실 없이 이미지를 웨이블렛 계수로 변환하는 방식을 제안했다.
컴퓨터 비전 태스크에서는 수용 영역을 확장하기 위한 효율적인 방법으로 Haar Wavelet을 도입한다고 한다. 그 이유는 단순하면서도 효율적인 특성을 가지고 있기 때문이다.
이전 연구에서도 Haar DWT는 "정보 손실 없이 수용 영역을 효과적으로 확장하고 컨볼루션 기반 다운샘플링보다 수용 영역을 더 빠르게 확장하는 데 도움이 된다"라는 연구가 있었다고 한다.
Method
Method Overview
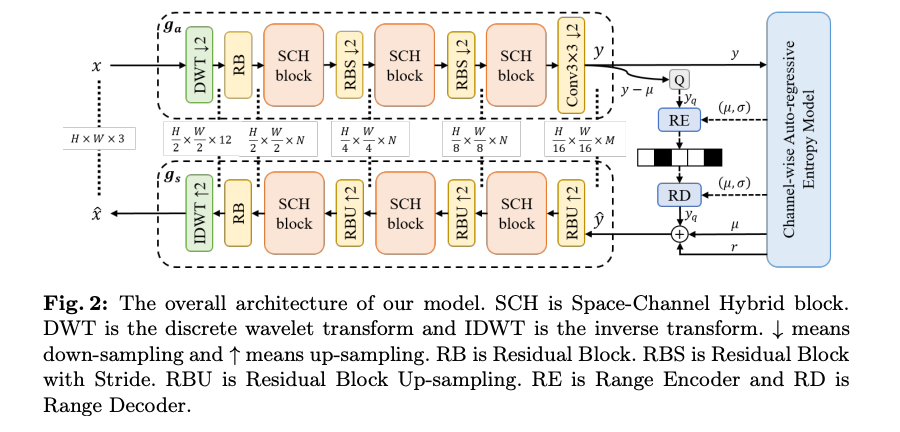
위 그림 2는 Space-Channel Hybrid(SCH) 프레임워크의 전반적인 구조이다.
구조를 살펴보면 입력 이미지 를 DWT 모듈을 통해 네 개의 서로 다른 주파수 성분을 가진 하위 서브밴드로 분해하고, 이를 채널 차원으로 재배열한다. 그림 2의 채널이 12개인 이유도 3채널의 서브밴드 4개가 채널로 concat되기 때문에 12채널의 shape이 된다.
이후 Inverse DWT(IDWT)을 통해 네개의 하위 서브밴드를 다시 3채널 이미지로 복원하는 프로세스로 진행된다.
다운샘플링과 업샘플링을 위해 각각 Residual Block with Stride (RBS) 및 Residual Block Up-sampling(RBU)를 사용한다. 두 연속된 residual block 사이에는 SCH 블록을 배치하여 공간적 지역 정보와 채널 기반 전역 정보를 학습한다고 한다.
제안 프레임워크의 주요 특징은 SCH 블록, Window-based Channel Attention 및 DWT 모듈이다.
Space-Channel Hybrid Block
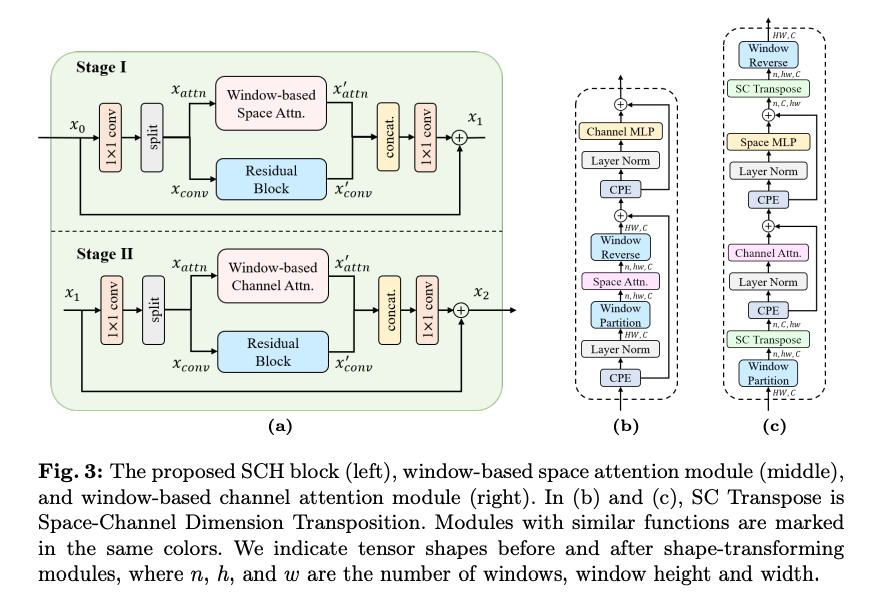
LIC-TCM 모델의 TCM 블록에서 영감을 받아서 Space-Channel Hybrid (SCH) 블록을 디자인 했다고 한다.
주요 특징은 Convolutional Positional Encoding (CPE)를 사용하였고, Swin-Transformer의 shifted-window attention을 window-based channel attention으로 교체했다고 한다.
위 그림 3-(a)에 나타난 것 처럼 SCH 블록은 두 단계로 구성된다.
두 단계의 수식은 다음과 같다.
Stage I
- 입력 텐서는 1x1 컨볼루션을 거진 후 채널 차원으로 균등하게 2개의 텐서로 분할된다.
- window-based space attention module을 통해 transformer-based local spatial information을 학습.
- 나머지 텐서는 Residual Block을 통해 CNN-based local spatial information을 학습.
- 두 결과를 채널 차원으로 concat한 후 1x1 컨볼루션을 통해 두 정보를 fusion 시킨다. 이 과정에서 skip connection을 추가하여 gradient descent을 원활하게 함.
Stage II
Stage I과 차이점인 window-based channel attention module을 통해 global channel-wise dependencies를 학습.
Window-based Channel Attention Module
이 섹션은 요약하면 아래와 같다.
1. Transformer의 어텐션 모듈은 입력 형태를 LxC로 정의함. (L은 시퀀스 길이, C는 채널 수)
2. 하지만 이미지 압축은 다양한 입력 크기를 처리해야해서 L이 고정된 값이 아님. 그렇기 때문에 채널 크기가 변경되면 linear projection과 MLP 설계가 어려움.
제안하는 window-based channel attention module의 공식은 아래와 같다.
위 모듈을 그림3 (c)와 같다.
Advantages
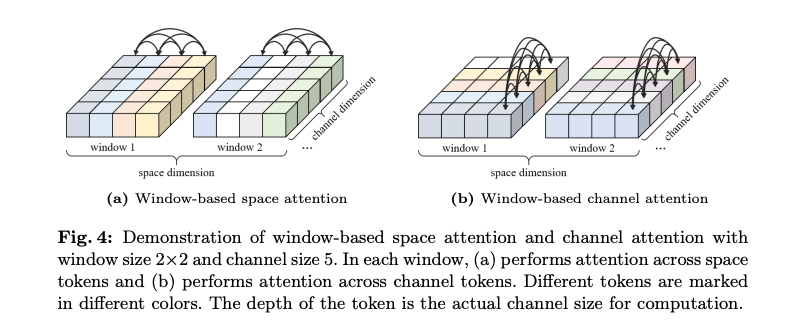
제안된 window-based channel attention은 넓은 receptive field를 통해 global information를 효과적으로 포착한다. 그림 4에 따르면 각 채널 토큰은 윈도우 내에서 전역적 특성을 포함하고, 이는 특징 맵에 대한 global view을 제공합니다.
그림 1에서 제안 모듈이 가장 큰 ERF를 가지며, gradient는 텍스처와 잎, 가지의 가장자리(edge)에 집중됐다. 이는 해당 모듈이 전역 정보를 성공적으로 포착했음을 증명함.

그림 5에서는 제안된 어텐션 모듈과 DaVit의 어텐션 맵 차이를 보여준다. a,b,c는 제안 모듈이며, d,e,f은 DaViT의 어텐션 맵이다. 이를 통해 제안 모듈이 더 큰 수용 영역과 다양한 채널 어텐션 맵을 제공하고,DaViT와 비교했을 때 더 풍부한 정보를 학습할 수 있음을 나타낸다.
Wavelet Transform Module

수용 영역을 더욱 확장하기 위해, 입력 이미지를 처리하기 위한 웨이블렛 변환 모듈을 도입함. 저자는 Haar Wavelet을 도입했고 선택한 이유는 그 단순성과 효율성 때문이라고 한다. 네 개의 필터는 다음과 같이 정의된다.
은 원본 이미지 의 low-frequency approximation을 출력하는 sum-pooling 연산을 수행한다. 반면, 다른 필터들은 고주파 정보를 얻는 것을 목표로 한다.
저주파는 원본 이미지의 다운샘플링된 특징이 있고, HL와 LH는 이미지의 수평 및 수직 디테일을 나타내며 두 방향의 edge 특징을 보인다. HH는 이미지의 대각선 성분을 나타낸다.
웨이블릿 변환은 이미지를 서로 다른 주파수 성분으로 분해하므로, 신경망이 주파수 상관 관계를 학습하도록 유도하고 더 복잡한 텍스처를 학습하는 데 도움을 준다고 한다.
웨이블릿 변환은 frequency-dependent down-sampling의 역할을 하여 모델의 수용 영역을 확장하는 데 기여한다. 웨이블릿은 residual blocks, space attention modules, channel attention modules의 학습을 보완한다고 하고, 주로 채널 어텐션에서 전역 정보 학습을 지원한다고 함. 그리고 웨이블릿은 학습 파라미터가 아니기 때문에 효과적이라고함.
Experiments
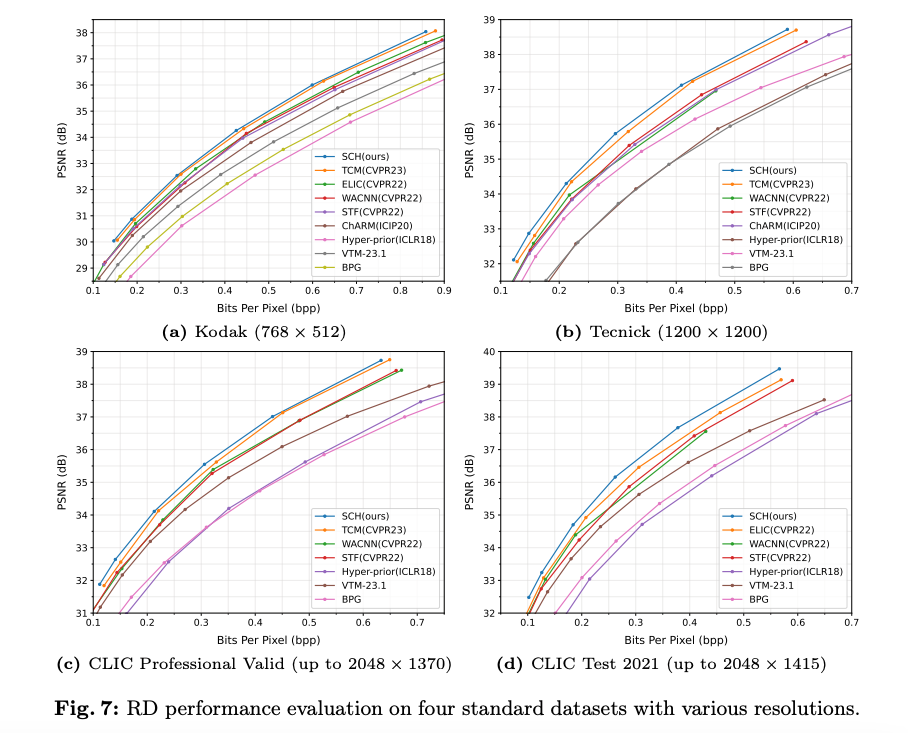
평가는 총 네 개의 벤치마크 데이터셋을 사용하였다. 학습데이터셋은 이미지넷 30만장을 RandomCrop으로 256x256으로 잘라서 사용했다고 한다.
RD 커브를 살펴보면 SCH는 baseline인 LIC-TCM 모델보다 성능이 높게 나타났다.

이미지의 정량 & 정성평가 결과를 살펴보면 SCH 모델이 가장 높은 압축 효율을 보였다.
Conclusion
- 이 논문에서 Space-Channel Hybrid (SCH) framework을 제안하였다. residual blocks과 space attention modules을 통해 local information learning을 수행하였으며 channel attention modules을 통해 global information learning을 수행한다.
- window-based channel attention module은 기존보다 넓은 receptive field를 가진다. 수용 영역을 더욱 개선하기 위해, 프레임워크에 Haar DWT 모듈을 통합하여 원본 이미지를 처리한다.
- 제안 방법이 기존 LIC 연구들과 비교하여 계산 비용 측면에서 경쟁력이 있지만, 여전히 모바일 장치에서 사용하기에는 비용이 너무 높은 문제가 있다.
- 향후에는 pruning, quantization, knowledge distillation, structural re-parameterization을 통해 해결할 수 있을 것으로 예상한다.
이 논문은 CNN-Transformer 모델과 웨이블릿을 사용하여서 비전에서 다룰 수 있는 모든 메커니즘을 다 섞은 방법론이라 흥미롭게 읽었다. 하지만 깃허브 주소를 제공하지 않아서 재현성이 어렵다는 문제가 있다.
