[Compression] Joint Autoregressive and Hierarchical Priors for Learned Image Compression 리뷰
Image Compression
논문 제목
Joint Autoregressive and Hierarchical Priors for Learned Image Compression (NIPS 2018)
URL: https://arxiv.org/abs/1809.02736
인용수 : 1231회 (24.09.23 기준)
해당 논문은 Learned Image Compression에서 대부분 사용하는 구조인 Context Model을 제안했다. 현재 나온 SOTA 모델에 사용되는 다양한 Context Model을 이해하기 전 왜 & 어떻게 사용되는지 알아야하기 때문에 이 논문은 연구를 위해 반드시 읽어야하는 논문이다.
요약
- 학습 기반 이미지 압축 모델은 Autoencoder를 사용하고, hierarchical entropy model (AE+Hyperprior)구조가 더 나은 성능을 보였음.
- Autoregressive Model을 hierarchical prior model에 결합하여 압축 성능을 향상시킴
Introduction
- 학습 기반 이미지 압축 방법들은 Transform Coding 방식에 기반함. 이 방식은 이미지를 잠재표현으로 변환 후 양자화하고, 이를 무손실 압축(엔트로피 코딩)한다. 주로 CNN이 사용되며, 전통적인 선형변환보다 더 압축할 수 있다.
- 학습 기반 이미지 압축 모델은 오토인코더 (Autoencoder) 구조를 따른다. 오토인코더는 데이터를 잠재 표현으로 인코딩하고, 디코더가 이를 다시 이미지로 복원한다. 목표는 잠재표현의 엔트로피를 줄이는 것이다.
- 최근에는 계층적 엔트로피 모델(hierarchical entropy model)-Hyperprior이 도입되어 잠재 표현에서 더 많은 구조를 활용하여 성능을 개선하고, end-to-end training과 joint optimization이 가능함.
- 해당 논문에서는 Autoregressive model과 Hierarchical Entropy model을 결압하여 이미지 압축 성능을 향상시켰다. Autoregressive model은 높은 계산 비용이 들지만 정확한 확률 분포를 학습할 수 있다.
Rate-Distortion Optimization
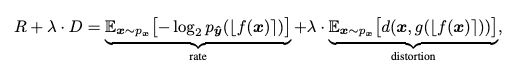
최적화를 위한 수식은 다음과 같다. 크게 Rate (Bit-Rate)와 Distortion(이미지 정량지표 : MSE,MS-SSIM Loss)로 구성된다.
모델 구조
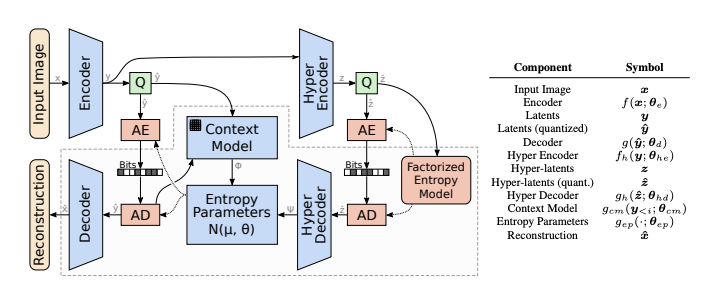

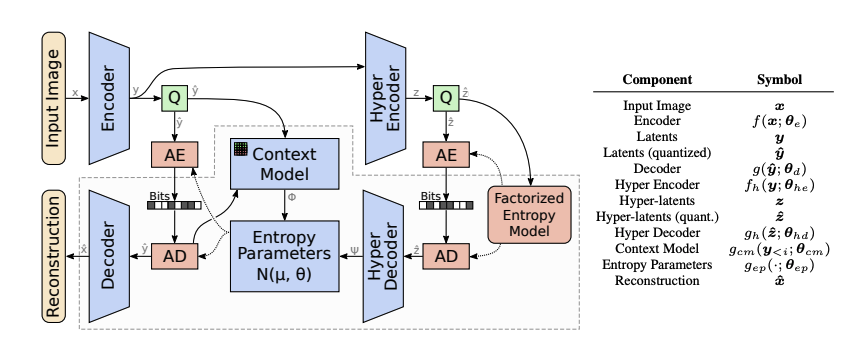
-
이 논문에서 제안된 모델은 두 가지 Network로 구성된다. 첫 번째 네트워크는 오토인코더로 이미지를 잠재표현으로 변환 후 이를 양자화한다. 두 번째 네트워크는 확률 모델을 학습하여 양자화된 잠재표현을 엔트로피 코딩에 사용할 수 있도록 한다.
-
Context Model은 Autoregressive model을 기반으로하여, 이미 복원된 잠재 변수들로부터 나머지 잠재 변수의 값을 예측한다. 이와 결합된 Hyperprior(Hyper Encoder 및 Hyper Decoder)는 컨텍스트 기반 예측을 보완하는 정보를 학습함.
두 모델 (Context & Hyperprior)의 데이터는 Entropy Parameters Network에 의해 결합되어, Conditional Gaussian entropy model의 mean과 scale parameters를 생성한다. -
양자화된 잠재표현 는 Hyperprior 와 이미 복원된 잠재표현 에 따라 Conditional Gaussian Distribution으로 모델링된다.
수식은 아래와 같다.
여기서 와 는 각각 Hyperprior Decoder, Context Model, Entropy Parameter Network에서 예측된다.
- Hyperprior는 잠재표현의 global한 정보를 제공하고, Context Model은 인접한 잠재 표현들 간의 Local한 Dependency를 학습한다.
Loss Function
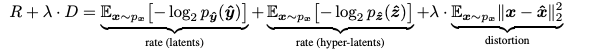
논문에서 사용한 손실함수는 다음과 같다.
Layer Detail

각 층의 디테일을 살펴보면 네트워크 전반적으로 CNN을 사용했고, 비선형성을 위해 활성화 함수는 GDN/IGDN, Leaky ReLU를 사용했다. (Hyperprior논문에서는 ReLU를 사용했었다.)
더 개선된 활성화 함수를 사용한 특징이 있었다.
Experimental Results
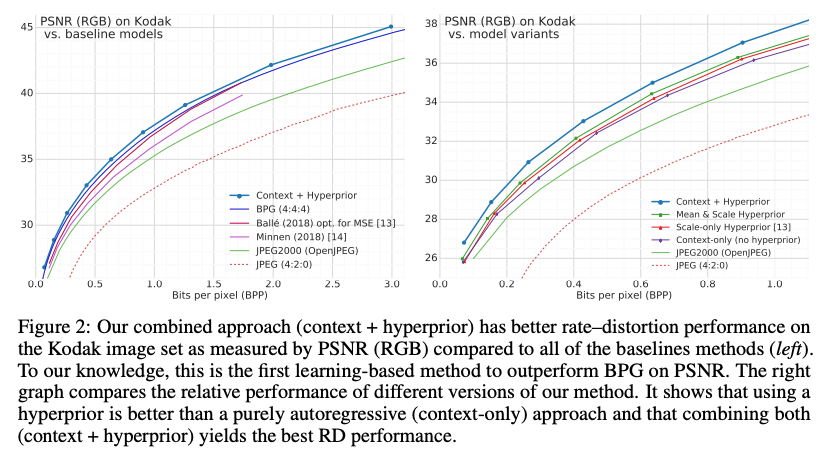
논문에서 Ablation Study를 통해 AE+ Hyperprior, AE+ Context Model, AE+ Hyperprior + Context Model 조합으로 실험을 진행하였고, 두 네트워크를 모두 사용한 모델이 성능이 가장 좋게 나타났다.
또한 Hyperprior 논문에서는 BPG보다는 성능이 떨어졌지만, 본 논문에서는 딥러닝 방법론이 전 통적인 압축방법인 BPG보다 정량적으로 높은 수치를 보였다.
Discussion
Autoregressive Model과 Hyperprior는 상호보완적(complementary)이다.
Hyperprior 관점에서 엔트로피 모델을 개선하려면 더 많은 부가 정보(side information)가 필요함. 부가 정보는 총 압축 파일 크기를 증가시켜 이점이 제한된다.
반면 Autoregressive Model를 도입하면 예측이 casual context, 즉 이미 decoding된 정보를 기반으로 하기 때문에 속도 저하가 발생하지 않는다.Autoregressive Model 관점에서 볼 때 casual context에서만 제거할 수 없는 불확실성이 어느정도 존재할 것으로 예상된다.
그러나 Hyperprior는 압축된 비트스트림의 일부이며 디코더가 완전히 알고 있기 때문에 “look into the future”(미래를 내다본다)라고 할 수 있다. 따라서 Hyperprior는 Context에서 정확하게 예측할 수 있는 정보는 피하면서 Autoregressive Model의 불확실성을 줄일 수 있다.
실용적인 관점에서는 Autoregressive Model은 직렬적이라 병렬화를 통해 속도를 높일 수 없어 hierarchical model보다 바람직하지 않아 개선 연구 필요.
Context Model & Hyperprior 정리
Context Model
- 이미 복원된 잠재 변수들을 기반으로 아직 복원되지 않은 잠재 변수의 값을 예측
- 잠재 표현 간의 local dependency를 포착. 즉, 잠재 변수들 사이의 상관관계를 이용하여 더 정확한 확률 모델을 만들 수 있음. (ex : 한 픽셀 복원 시 그 픽셀의 이웃 픽셀 정보를 사용하여 해당 픽셀의 확률을 더 정확하게 예측)
- Bit-rate 증가 없이 성능 개선이 가능하며, 부가 정보(side information) 없이도 잠재 변수 간의 상호 의존성을 모델링할 수 있다는 장점이 있음.
- 병렬화가 어렵고 계산 비용이 높아 실행 속도 면에서 비효율적이다.
Hyperprior
- 잠재 표현의 전역적 정보(global information)를 모델링하는 데 사용.
- 잠재 표현의 Scale(분산)을 학습하여, 잠재 변수들의 분포를 더 정확하게 예측하는 데 도움을 준다.
- 주로 계층적 사전 모델(hierarchical prior model)에서 사용되며, 잠재 변수들 간의 상관관계가 단순한 모델보다 잘 반영됨.
- 미래의 정보를 사용할 수 있어, Context Model이 처리할 수 없는 불확실성을 줄이는 역할을 한다.
두 모델이 상호보완적으로 작동하여 이미지 압축 연구에서 복잡한 이미지 데이터의 잠재 표현을 더 정교하게 모델링할 수 있게되었다.
