[Compression] Checkerboard Context Model for Efficient Learned Image Compression 리뷰
Image Compression
논문 제목
Checkerboard Context Model for Efficient Learned Image Compression (CVPR 2021)
URL: https://arxiv.org/abs/2103.15306
인용수 : 231회 (24.09.24 기준)
2018년에 제안된 Context Model은 압축 데이터의 비트스트림을 늘리지 않으면서도 성능을 향상시킬 수 있는 방법론이었다. 하지만 직렬 연산으로 인해 병렬처리가 불가능하여 계산 효율성에 큰 제약이 있다는 한계점이 있었다.
이 한계점을 극복한 방법이 Checkerboard Context Model(CCM)이며 이는 병렬처리가 가능하여 디코딩 속도를 크게 향상시킨(기존 대비 40배 이상) 논문이다.
해당 논문의 Unofficial Code 레포입니다.
https://github.com/JiangWeibeta/Checkerboard-Context-Model-for-Efficient-Learned-Image-Compression
요약
- 학습 기반 이미지 압축 연구에서 Autoregressive Model(2018)은 Rate-Distortion 성능을 향상키시는데 효과적이었다. 이 모델은 잠재 표현 간의 spatial redundancies을 제거하는 데 도움을 준다.
- 기존의 Autoregressive Model은 디코딩 과정에서 strict scan order가 필요하여, 병렬처리가 불가능하며, 이는 계산 효율성에 큰 제약이다.
- 본 논문에서는 병렬 처리가 가능한 Checkerboard Context Model(CCM)을 제안.
- 제안된 모델은 디코딩 속도를 40배 이상 향상시키면서, 유사한 Rate-Distortion 성능을 유지하는 성능을 보였다.
- 학습 기반 이미지 압축 연구에서 최초의 parallelization-friendly spatial context model 연구임.
Introduction
- 이미지 압축은 오랫동안 연구된 분야로, 공간적, 시각적, 통계적 중복성을 제거하여 더 컴팩트한 이미지 표현을 생성하는 것이 목표.
- 딥러닝 기반 이미지 압축이 등장하면서, Autoencoder, RNN, GAN 등 다양한 네트워크 구조가 이미지 압축에 적용되고 있다. 딥러닝 방법론들은 PSNR, MS-SSIM과 같은 정량 지표에서 전통적인 압축 방법인 JPEG2000, BPG보다 높은 수치를 보였다.
- SOTA 모델의 접근 방식의 공통적인 핵심은 엔트로피 모델링과 최적화 방법이다. 오토인코더 기반 구조를 사용하여 비선형 변환 코딩을 수행하며, 잠재 표현의 확률 분포를 추정함으로써 이러한 표현들의 엔트로피를 최소화할 수 있다. 이는 arithmetic encoding, range encoding 과같은 인코딩 방법을 사용하여 최종적으로 생성되는 코드 길이와 직접적인 상관관계를 가진다.
- Hyperprior 은 잠재 변수들의 공간적 상관관계를 설명하는 부가 정보를 제공.
- Context Model은 이미 디코딩된 잠재 변수들을 기반으로 디코딩 될 코드 확률을 예측하는 방식으로 동작하며, 더 정밀한 엔트로피 모델을 구축할 수 있다.
Context Modeling
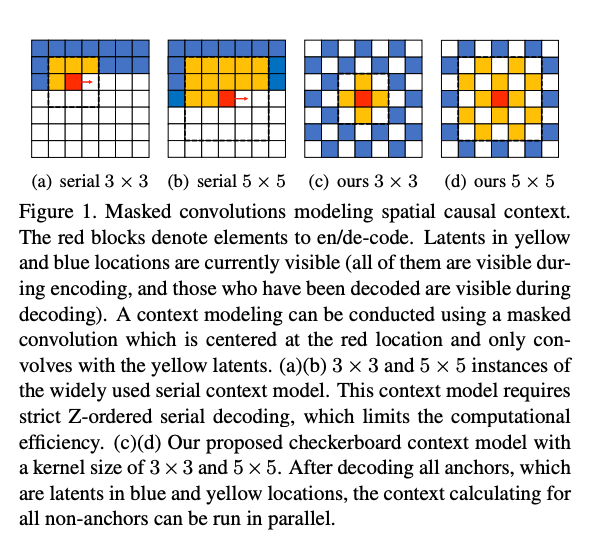
- (a) Serial 3x3, (b) Serial 5x5
- 3×3 크기의 컨볼루션 커널을 사용하여 순차적(serial)으로 디코딩하는 방법
- 빨간색 블록은 현재 인코딩/디코딩 중인 위치를 나타내고, 노란색 블록은 이 커널이 참조할 수 있는(이전에 복원된) 위치.
- 파란색 블록은 현재 디코딩 과정에서 참조할 수 없는 잠재 표현
- Z-ordered serial decoding이 필요하기 때문에 계산 효율성이 제한
- (c) Ours 3x3, (d) Ours 5x5
- 제안된 checkerboard context model을 사용한 방식
- 체커보드 패턴을 사용하여 참조할 블록을 선택한 후, 병렬 처리가 가능해짐.
- 파란색과 노란색 위치에 잠재되어 있는 모든 anchor를 디코딩한 후, 모든 non-anchor context (흰색) 계산을 병렬로 실행할 수 있음
Parallel Context Modeling
이전 2018년 논문에서 Context Model에 Masked Convolution을 사용하였다.
본 논문에서는 랜덤 마스크 모델을 사용하여 컨텍스트 모델을 분석한 후, 기존의 직렬 컨텍스트 모델을 대체할 새로운 병렬 컨텍스트 모델을 제안한다.
4.1 Random-Mask Model: Test Arbitrary Mask
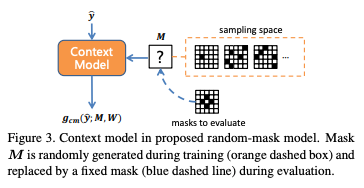
: Masked Convolution을 의미한다. 입력 y에 대해 마스크 M과 가중치 W를 사용하여 컨볼루션을 수행한다. 여기서 마스크 M은 훈련 중 랜덤하게 생성된다.
Sampling Space : 훈련 중 사용되는 마스크 패턴.
훈련 후 평가 단계에서는 임의의 마스크 대신, 'masks to evaluate'의 고정된 마스크를 사용.
Bit-rate saving ratio
: 마스크 𝑀에 대한 비트율 절약 비율
: 컨텍스트 모델을 사용하지 않았을 때의 비트율(BPP)을 의미한다. 즉, 이 값은 컨텍스트 모델이 없는 상태에서 인코딩했을 때의 비트율.
: 마스크 M을 사용하여 컨텍스트 모델을 적용했을 때의 비트율(BPP)이다. 이는 해당 마스크를 사용했을 때 인코딩된 데이터의 비트율.
훈련된 랜덤 마스크 모델을 사용하여 비트율 절약 비율 η(M)을 계산하여 마스크 M이 나타내는 컨텍스트 모델링 패턴을 분석했다.
4.2 How Distance Influences Rate Saving
serial context model은 현재 디코딩 중인 잠재 변수의 엔트로피를 정확하게 추정하기 위해 이미 디코딩된 이웃 잠재 변수를 참조하여 Bit-rate를 save함.
5x5 mask의 경우 총 12개의 잠재 변수(노란색)가 추정에 참조된다.
앞서 언급한 랜덤 마스크 모델을 기반으로 24개 (노랑+파랑)의 서로 다른 단일 참조 마스크(각 마스크는 한 위치만 1로 설정되고 나머지는 0으로 설정됨)의 η값을 계산하여 가까운 위치의 잠재 변수가 비트율 절약에 훨씬 더 기여한다는 것을 발견함.

이웃한 잠재 변수가 훨씬 더 많은 비트율을 절약하며, 2개 이상의 요소가 떨어져 있는 이웃은 비트 절약에 거의 영향을 미치지 않는다는 것을 보였다.
4.3 Parallel Decoding with Checkerboard Context
Checkerboard Context Model은 네 개의 가장 가까운 이웃을 참조하며, 3x3, 5x5 serial context model 보다 성능이 우수함을 발견함.
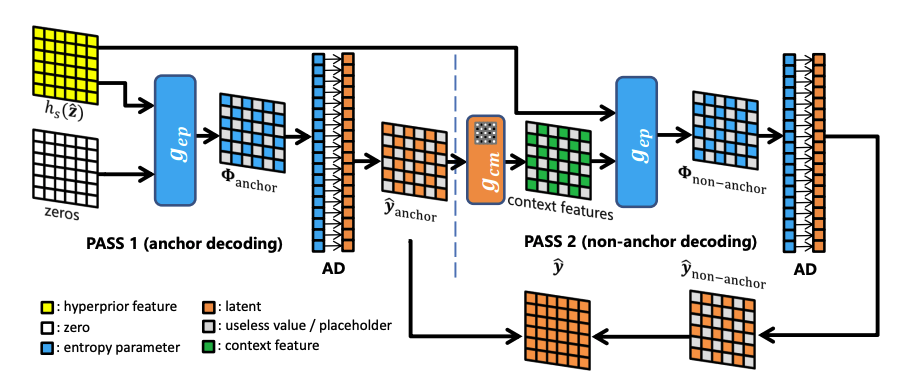
병렬 디코딩을 위해 잠재변수의 절반(Figure 1에서 흰색 및 빨간색으로 표시된 것)을 Hyperprior와 Checkerboard contex만을 사용하여 인코딩/디코딩함.
나머지 절반의 잠재변수는 Hyperprior 기반으로 하여 처리됨.
이를 위해 모든 anchor의 context 특성을 0으로 설정하고, entropy parameter Φ 계산을 spatial location conditioned form으로 변경함.
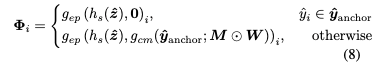
여기서 은 checkerboard 모양의 mask M을 condition으로 한 masked convolution이며, 는 앵커들의 집합이고, 는 잠재변수 내에서 i 번째 요소의 인덱스이다.
mean-scale gaussian entropy model을 사용하는 방법에서는 엔트로피 파라미터 이고, GMM을 사용하는 방법에서는 가 ,, 의 K그룹으로 구성됨.
앵커들이 보이면, 모든 비앵커의 컨텍스트 특성은 masked convolution을 통해 병렬로 계산될 수 있습니다. 앵커의 디코딩도 병렬로 실행되므로, 디코딩을 위한 엔트로피 파라미터 계산은 two-pass로 수행할 수 있으며, 이는 직렬 컨텍스트 모델보다 훨씬 효율적이다.
4.3.1 Encoding Latents in One Pass
여기서 One Pass란 엔트로피 파라미터 를 순차적으로 계산하지 않고 병렬로 얻는 것을 의미.
는 non-anchor를 모두 0으로 설정한 잠재변수로 정의된다.
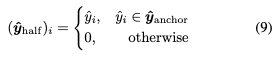
0으로 설정하면 binary mask M이 Checkerboard 모양이되므로,를 식에 대입하면 다음 식이 나오게 된다.
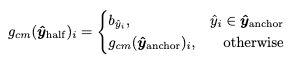
여기서 는 각 위치에서 대응하는 bias항임.
와 유사하게 는 앵커 위치에만 b벡터가 채워지고 나머지는 0인 feature map이 된다.
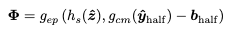
인코딩(및 학습) 동안 모든 잠재 변수 는 visible하므로, 비앵커를 0으로 설정한 를 으로 부터 쉽게 생성한 다음, one-pass로 context model과 parameter network를 사용해서 모든 entropy parameter 를 병렬로 계산할 수 있다.
최종적으로 과 를 flatten하고 재정렬한 후, anchor와 non-anchor를 순차적으로 bitstream에 인코딩한다.
4.3.2 Decoding Latents in Two Passes
디코딩의 시작은 Hyper latent 가 비트스트림에서 산술디코더(AD)를 통해 복원됨. 그 다음 Hyperprior feature인 가 계산된다. 이후 전체 latent 를 얻기 위해 two pass로 디코딩 진행.
첫 번째 디코딩
1.앵커의 엔트로피 파라미터 가 context feature를 0으로 설정한 상태에서 식(8)을 따라 계산.
2. 이 엔트로피 파라미터로 앵커의 conditional probability 가 결정됨.
3. 의 절반에 해당하는 앵커가 산술 디코더에 의해 디코딩됨.
4. 디코딩된 앵커가 다음 pass에서 non-anchor를 디코딩하는데 사용.
두 번째 디코딩
- non-anchor의 컨텍스트 특성을 제안된 체커보드 컨텍스트 모델을 사용하여 병렬로 계산
- Hyperprior feature와 context feature를 결합하며 non-anchor의 엔트로피 파라미터 계산.
- 산술 디코더가 나머지 절반의 을 디코딩하여 전체 잠재 변수 을 얻게됨.
- 이를 통해 reconstruct된 이미지 를 얻는다.
4.3.3 Structure and Analysis
Checkerboard Context Model 구조
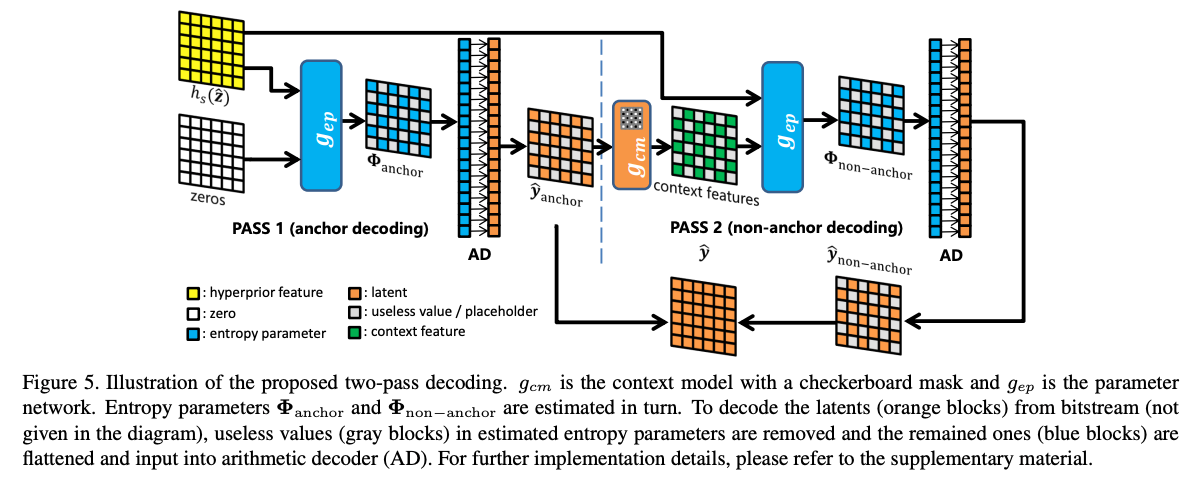
실험
모델 구조
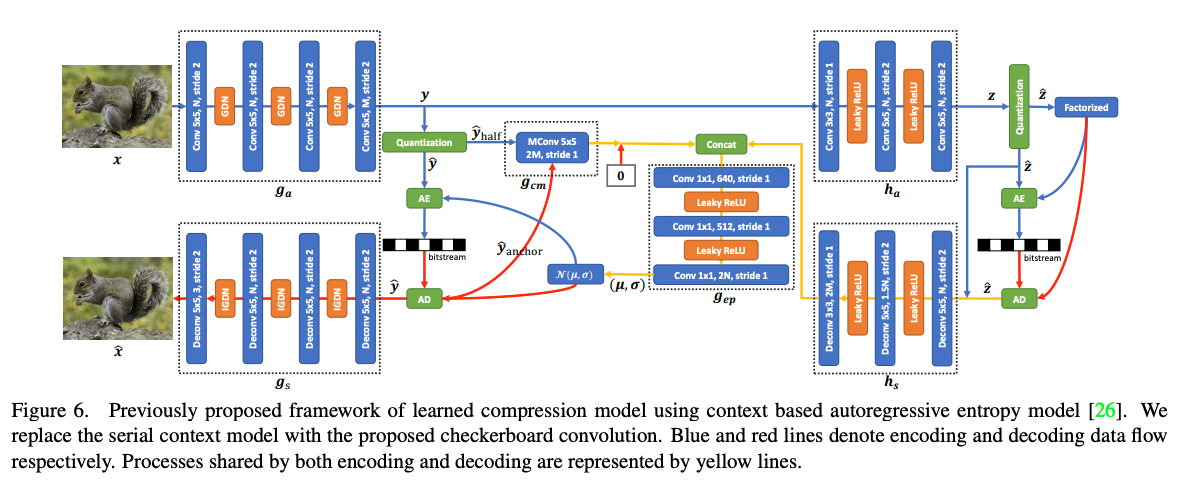
모델은 2018년 제안된 AE+Hyperprior+Context Model을 기반으로 디자인하였음.
데이터
ImageNet의 검증 데이터 중 가장 큰 8000개 이미지를 훈련데이터로 사용.
이 때 각 이미지는 백만 픽셀 이상임.
테스트 데이터셋은 Kodak과 Tecnick 데이터셋을 사용함.
훈련 시 모든 이미지를 256x256 패치로 randomcrop 진행.
실험 결과
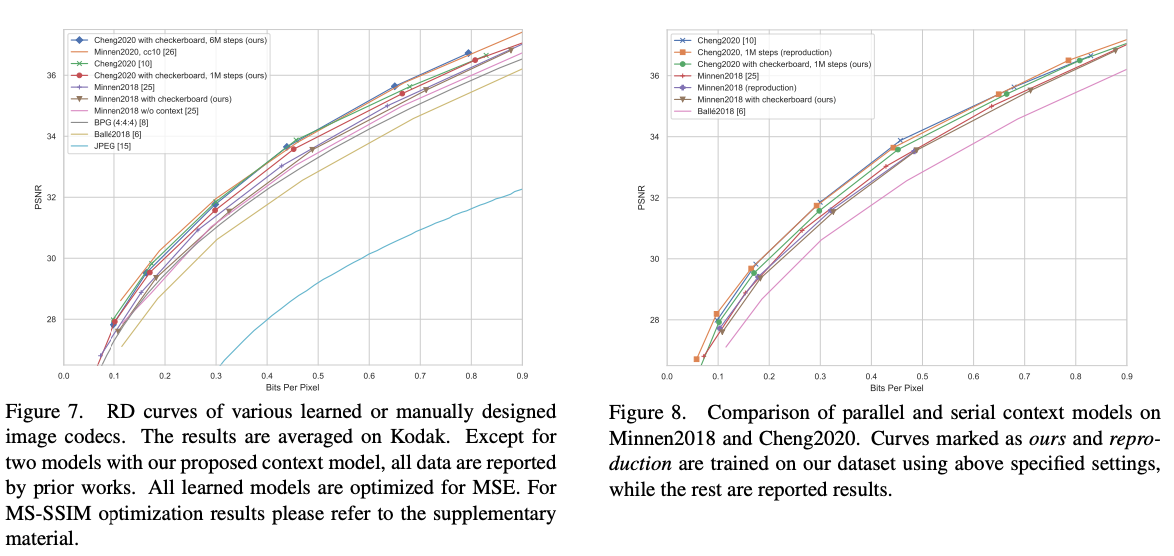
다른 논문들과 다르게 기존 모델들 보다 RD-Curve에서 지표가 좋지 않다. 해당 논문은 속도개선이 주된 novelty이기 때문에 특정 람다에서 성능이 높은 곳도 있고, 낮은 곳도 존재한다.
Decoding 시간 비교

디코딩 시간을 비교했을 때 Context Model이 없는 모델이 있는 모델보다 디코딩 속도가 월등히 빠르다.
하지만 Serial한 Context 모델은 40~50배정도 소요되는 것을 확인할 수 있다.
하지만 본 논문에서 제안한 Checkerboard Context Model을 통해 Context Model이 없는 모델과 거의 동일한 속도까지 내려온 것을 확인할 수 있다.
Discussion
- Serial한 Context Model은 계산 효율이 매우 좋지 않았다.
- 제안한 Checkerboard Context Model이 Two-Passes를 사용하여 병렬 디코딩 방식을 사용한다.
- 이를 통해 디코딩 속도를 크게 개선했고, 직렬(Serial) 컨텍스트 모델을 drop-in replacement할 정도의 방식으로 사용이 가능하다.
Checkerboard Context Model까지 정리해놨던 핵심 논문들을 모두 velog에 옮겨 정리했다.
이미지 압축 SOTA 논문들을 이해하기 위한 핵심 구조인 Hyperprior - Context Model - Checkerboard Context Model까지 이해한다면 2020년대 나온 논문 중 Transformer Layer나 INR 기반 모델이 아니라면 어느정도 모델의 구조와 기능들이 눈으로 보이지 싶습니다.
정리하다 보니 동일단어를 영어와 한국어를 번갈아가며 사용한 부분이 있는데 양해부탁드립니다..
