[Compression] Learned Image Compression with Discretized Gaussian Mixture Likelihoods and Attention Modules 리뷰
논문 제목
Learned Image Compression with Discretized Gaussian Mixture Likelihoods and
Attention Modules (CVPR 2020)
URL: https://arxiv.org/abs/2001.01568
인용수 : 866회 (24.09.23 기준)
2018년 이후 학습 기반의 이미지 압축 모델은 Autoencoder + Hyperprior + Context Model 총 3가지로 구성되어 있다.
해당 논문은 Context Model에서 Discretized Gaussian Mixture Likelihood을 적용하여 엔트로피 모델링을 개선하였고, 인코더 & 디코더에 Attention 모듈을 도입한 논문이다.
이미지 압축 모델은 정확한 모델이름을 정의하지 않은 논문이 많다. 이 논문 또한 마찬가지이며, 최신 논문에서는 Cheng’20 (CVPR'20) 다음과 같이 명명된다.
요약
- Discretized Gaussian Mixture Likelihood을 사용하여 latent codes의 분포를 매개변수화하여 정확하고 유연한 엔트로피 모델을 달성.
- Attention 모듈을 압축 모델에 통합하여 성능을 향상시킴.
Related Work
-
엔트로피 추정 기법들은 Learned Image Compression 성능을 크게 향상 시켰고, 가장 대표적인 방법은 Hyperprior Model과 Joint Model(Context+Hyperprior)이다. 그러나 latent representation의 실제 주변 분포와 추정된 분포 간에는 여전히 차이가 존재함.
-
Parameterized Model 섹션에서 생성 연구에서 매개변수화된 분포모델을 조사했다. 그 예시로 PixcelCNN에 discretized logistic mixture likelihood를 제안한 PixcelCNN++를 통해 더 빠른 학습이 가능하다고함. L3C는 PixelCNN++와 logistic mixture model을 사용하여 lossless image compression을 수행함. 그러나 learned image compression에서는 parameterized distribution model의 효과를 연구한 사례가 거의 없음.
Proposed Method
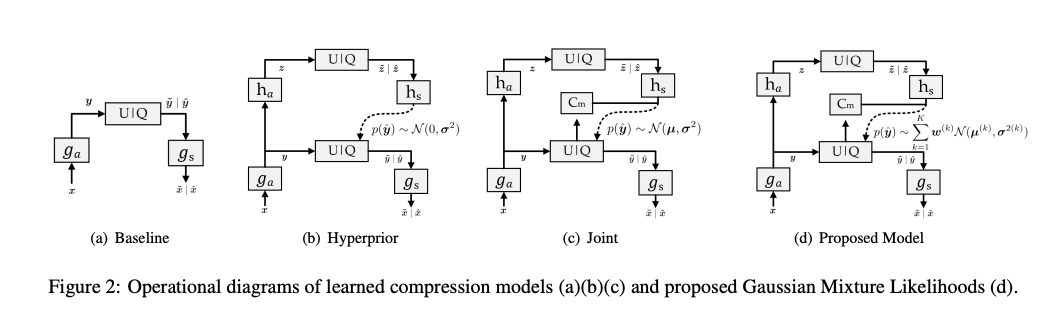
Discretized Gaussian Mixture Likelihoods
(b) Hyperprior에 대해 다음과 같은 단변량 가우시안 분포 모델을 가정한다.
(c) 개선된 연구에서는 Scale Hyperprior를 mean and scale Gaussian distribution로 확장하였으며, 이는 다음과 같다.
이 분포를 Autoregressive model과 결합하여 Joint 모델로 불린다.
(d) Joint 엔트로피 모델도 spatial redundancy가 관찰됨. 이웃한 요소를 컨텍스트 모델의 입력으로 사용되더라도, parameterized distributions가 이웃 요소들로부터의 정보와 추가 비트 를 완전히 활용하지 못할 수 있다. 이는 single Gaussian distribution의 고정된 형태에 의해 제한된다. 이를 극복하기 위해 더 유연한 parameterized model을 고려해서 arbitrary likelihoods를 달성하기 위해 Gaussian mixture model를 제안.
일반적으로 위 식은 countinuous하지만 양자화 후 는 discrete.
Logistic mixture likelihoods를 사용하지 않은 이유는 Gaussian이 더 성능이 좋았다고 한다.
엔트로피 모델은 아래 수식으로 나타낸다.
: feature map에서 위치
: mixture model의 index
: 가중치
: 평균
: 분산
: 누적 분포 함수
논문에서는 을 사용했다고 함.
모델 구조
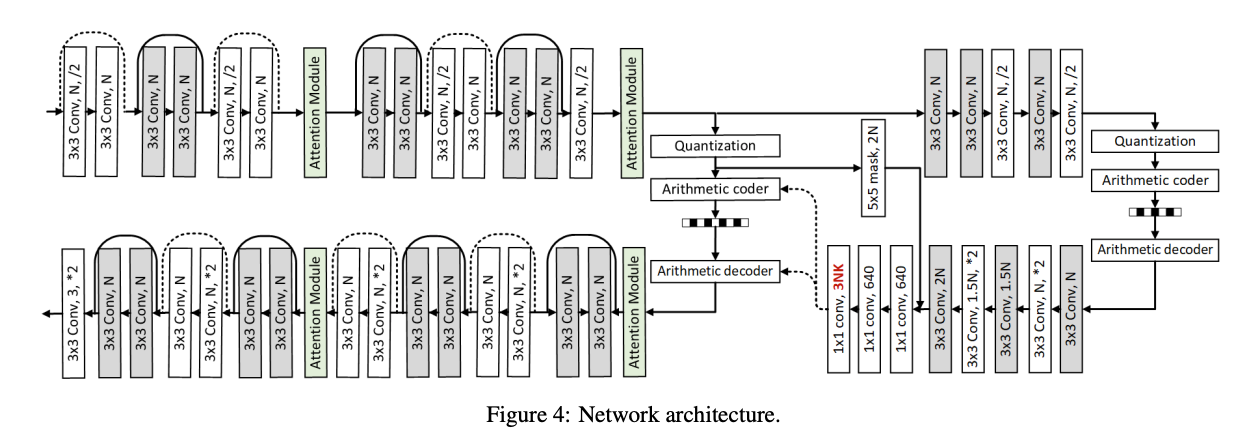
모델 구조는 Deep ResidualLearning for Image Compression 논문과 유사한 구조를 가진다.
- 네트워크의 large receptive field와 Rate-Distortion 성능 개선을 위해 Residual Block을 사용.
- 디코더에서 더 많은 디테일을 유지하기 위해 transposed convolution 대신 subpixel convolution을 사용함.
Attention Module
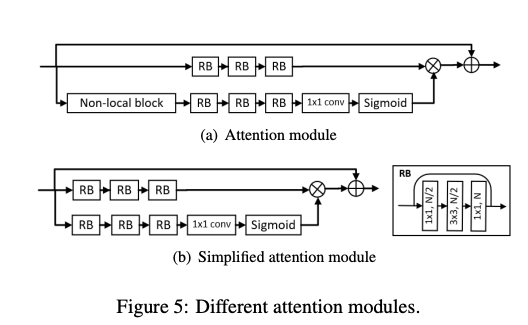
- 제안된 Attention Module은 (a)이지만, 훈련 시 시간이 많이 소요되는 단점이 있다.
- 이를 극복하기 위해 non-local block을 제거하여 모듈을 간소화. non-local block을 제거하더라도 residual block이 large receptive field를 캡쳐할 수 있기 때문.
본 논문에서는 (b)를 인코더-디코더에 넣었다고함.
Result
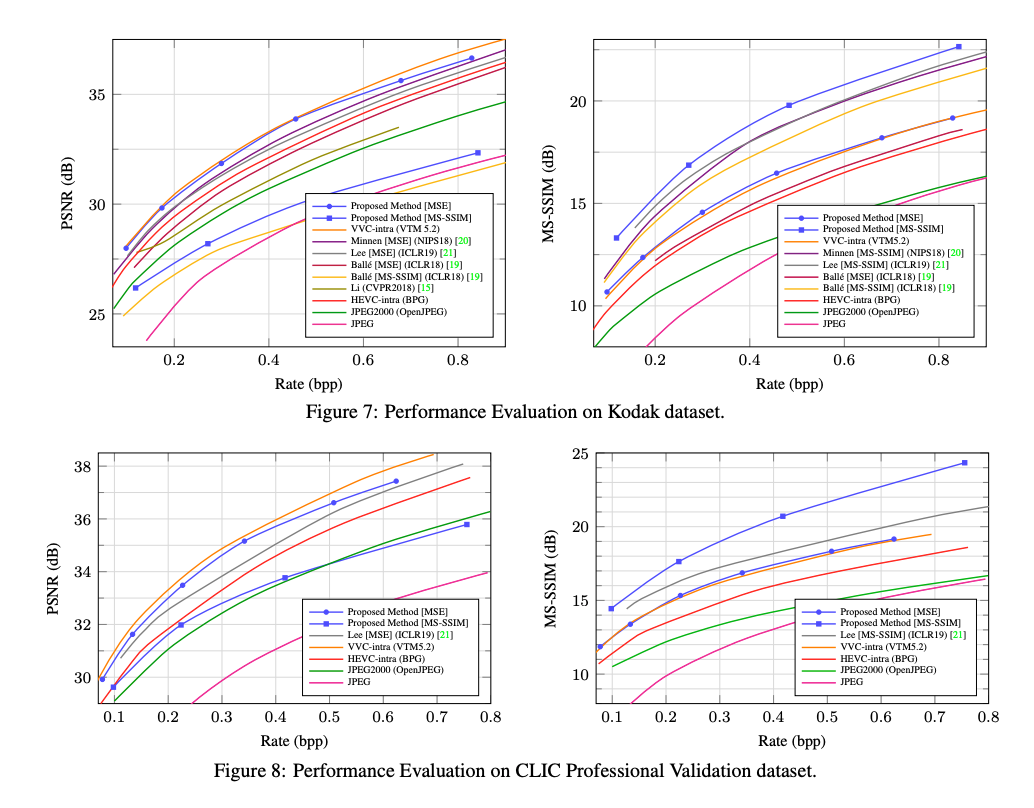
실험 결과, 제안된 방법은 기존의 학습된 압축 방법들과 HEVC, JPEG2000, JPEG와 같은 코딩 표준에 비해 높은 성능을 보였다.
PSNR 기준으로 차세대 압축 표준인 VVC와 유사한 성능을 달성했으며, MS-SSIM으로 훈련된 모델은 시각적으로 더 우수한 품질을 보였다.

Conclusion
- single parameterized model은 arbitrary likelihoods를 달성할 수 없어서 엔트로피 모델의 정확성을 제한.
- 더 유연하고 정확한 엔트로피 모델을 제안하기 위해 discretized Gaussian Mixture Likelihoods를 사용했다.
- 또한, simplified attention module을 활용하여 성능을 향상시켰다.
arbitrary likelihoods
특정한 형태의 분포에 국한되지 않고, 다양한 가능성을 가진 확률 분포를 유연하게 모델링할 수 있는 능력.
