[Compression] MLIC++: Linear Complexity Multi-Reference Entropy Modeling for Learned Image Compression 리뷰
Image Compression
논문 제목
MLIC++: Linear Complexity Multi-Reference Entropy Modeling for Learned Image Compression (ICML NCW 2023)
URL: https://arxiv.org/abs/2307.15421
인용수 : 36회 (24.10.05 기준)
MLIC++는 Paper with Code에서 Kodak 데이터셋에 대한 이미지 압축 벤치마킹 모델에서 현재 1위를 계속 지키고 있는 모델이다.
기존 모델의 한계점을 극복한 논문이고, 제안한 방법이 워낙 많이 때문에 단순히 메모로 만은 부족해서 번역해서 정리해보려 합니다. 학습 기반 이미지 압축에 대한 블로그는 많이 없어서 한국어로 정리 해놓으면 지금은 힘들지만 나중에 편할 것 같습니다..!ㅎ
요약
- 잠재표현은 channel-wise, local spatial, 그리고 global spatial 상관관계를 포함하고 있다.
- 기존의 global context module은 전역 상관관계를 포착하기 위해 계산 비용이 많이 드는 이차 복잡도(quadratic complexity)를 기반으로 하고 있으며, 이는 고해상도 이미지 코딩에 어려움이 있음. -> (GPU OOM 이슈 등)
- 본 논문에서는 Linear Complexity Multi-Reference Entropy Model, MEM++을 제안.MEM++는 잠재 표현에 내재된 다양한 상관관계를 효과적으로 포착할 수 있다.
- 잠재 표현은 여러 슬라이스로 나뉘며, 특정 슬라이스를 압축할 때, 이전에 압축된 슬라이스가 해당 슬라이스의 channel-wise context로 사용함.
- local context를 캡처하기 위해, 선형 복잡도의 checkerboard attention module을 새롭게 도입 -> checkerboard modulde은 속도는 빠르나 성능이 조금 떨어지는 문제가 있었음.
- global context를 캡처하기 위해 decomposition of softmax operation를 활용하여 linear complexity attention-based global correlations capturing을 제안.
Method
Motivation
정보 이론(information theory)에 따르면, 조건부 엔트로피(conditional entropy)는 다음과 같은 관계를 따름.
여기서 𝐻는 샤논 엔트로피(Shannon entropy)를 나타내며, ctx는 의 컨텍스트(context)를 의미한다. 의 상관관계를 활용하면 비트 절약이 가능하다.

그림 2와 그림 3에서는 Cheng'20(Cheng et al., 2020)에 의해 추출된 Kodim19의 잠재 표현에서 채널 별 상관관계(channel-wise correlations)와 공간 상관관계(spatial correlations)를 시각화 한 것이다.
그림 2는 여러 채널의 특징을 시각화하며, 이들의 유사성이 상당히 큼을 보여준다.
하지만 보통 Context Model에서 사용하는 masked convolution 기반의 spatial context module은 상관관계가 완전히 포착되지 않을 수 있다.
그림 3에서는 각 심볼(symbol)과 오른쪽 아래 코너에 위치한 심볼 간의 코사인 유사도(cosine similarity)가 시각화되어 있습니다. 동일한 색상의 심볼들은 높은 상관관계를 가진다.
이웃하는 심볼들은 매우 높은 유사도를 가지고 있으며, 이는 로컬 컨텍스트 모듈(local context module)의 필요성을 시사한다.
그리고 그림 3의 이미지에 잔디 특징이 유사한 아래쪽 왼쪽과 오른쪽 코너에 있는 심볼들 간의 상관관계를 포착하기 위해 전역 컨텍스트 모듈(global context module)도 필요.
잠재 표현은 중복성(redundancy)을 포함하고 있으며, 이를 모델링함으로써 비트 절약을 이끌어낼 수 있다.
하지만, 기존의 엔트로피 모델들은 로컬 공간, 전역 공간, 그리고 채널 도메인에서 상관관계를 완전히 포착하지 못한다고 한다. 공간 컨텍스트 모듈은 채널 간의 상호작용이 제한되어 있고, 채널 별 컨텍스트 모듈은 현재 슬라이스 내에서 상호작용이 부족하다 언급하였음.
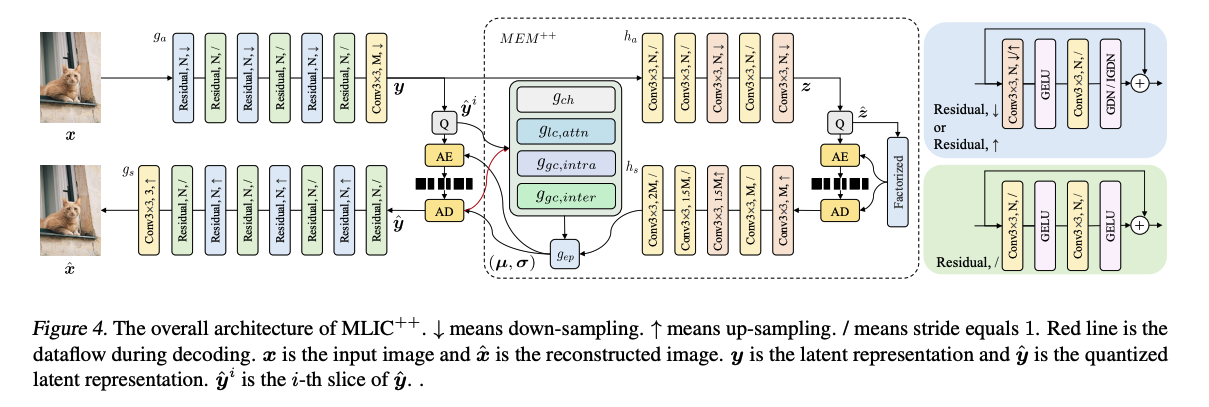
Overall Architecture
표기법 설명

모델 파라미터 정의

MLIC++
- MLIC++는 MLIC+ 및 MLIC++(ACMMM, 2023)과 다른 모델이다.
- 복잡성 줄이기 위해 인코더 디코더에 Attention Module을 전부 제거함.
- 양자화는 혼합 양자화(mixed quantization)를 사용.
- 엔트로피 추정을 위한 uniform noise 추가와 양자화 과정에서 미분 가능성을 보장하기 위한 STE로 구성됨. Gaussian mean-scale distribution가 엔트로피 추정에 사용
여기서 는 y의 추정된 평균이며, , 은 의 추정된 bit-rate이다.
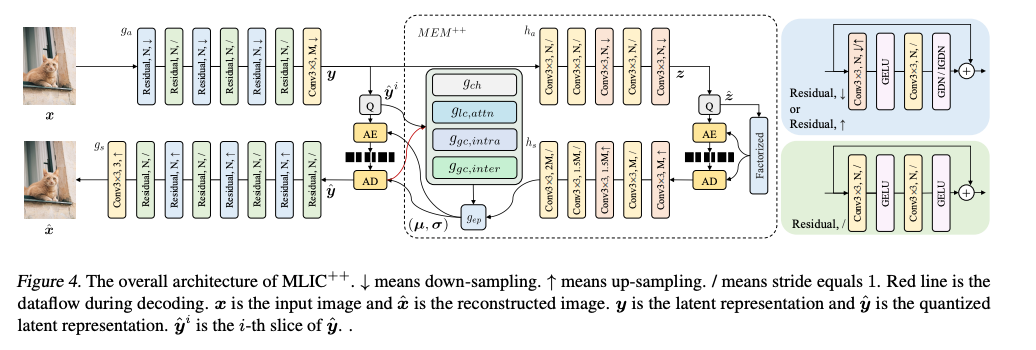
MEM++
제안한 Linear Complexity Multi-Reference Entropy Model은 channel-wise, local spatial, and global spatial correlations을 선형 복잡도로 효과적으로 포착할 수 있다.
총 4개의 컴포넌트로 구성됨.
각각의 파트는 각 모듈 별 상세 설명에서 잘 설명해준다.
추정된 bit-rate는 다음 수식으로 나타낸다.
여기서 은 side information의 bit-rate이고, 는 i번째 슬라이스의 앵커부분의 bit-rate, 는 i번째 슬라이스의 비앵커(non-anchor)부분의 bit-rate이다.
는 hyperprior 인코더-디코더를 통해 나온 hyperpriors를 의미함.
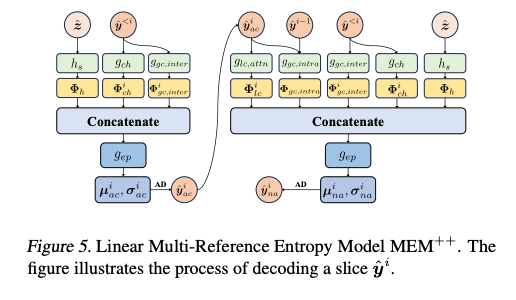
Channel-wise Context Module
- 채널 별 상관관계는 이미지의 잠재 표현에서 중요한 역할을 한다.
- 각 채널의 잠재 표현은 서로 매우 유사한 정보를 공유하고 있기 때문에 채널 별 상관관계를 활용하는 것이 중요하다.
제안된 channel-wise context module에서 ŷ은 채널 차원으로 여러 슬라이스로 나뉜다.
특정 슬라이스 를 압축할 때, 이전에 압축된 슬라이스 가 해당 슬라이스의 channel-wise context로 사용된다.
여기서 가 channel-wise context를 추출하는 함수이다.
이 channel-wise context는 hyperprior와 결합하여 더 정교한 엔트로피 모델링을 가능하게함.
Checkerboard Attention-based Local Context Module
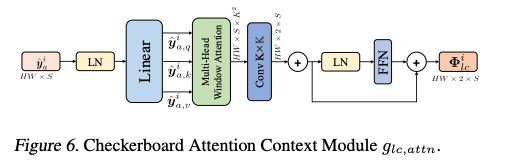
- CNN 기반의 local context module의 한계점은 fixed weights로 인해 content-adaptive contexts 캡처가 제한적이다.
- Transformer는 입력에 따라 동적으로 생성되는 attention weight가 사용됨. -> content-adaptive local context module를 구성하는데 영감을 받았다고 한다.
local receptive field를 하나의 window로 간주하며, local spatial context는 feature map을 winodw로 나눠 캡처한다. 각 심볼(=잠재 표현의 특정 값)은 주변 심볼과 관련이 있기 때문에, 저자는 나눠진 window들이 overlapped되도록 설정하는 것을 제안함. 이를 novel checkerboard attention context module이라고 한다.
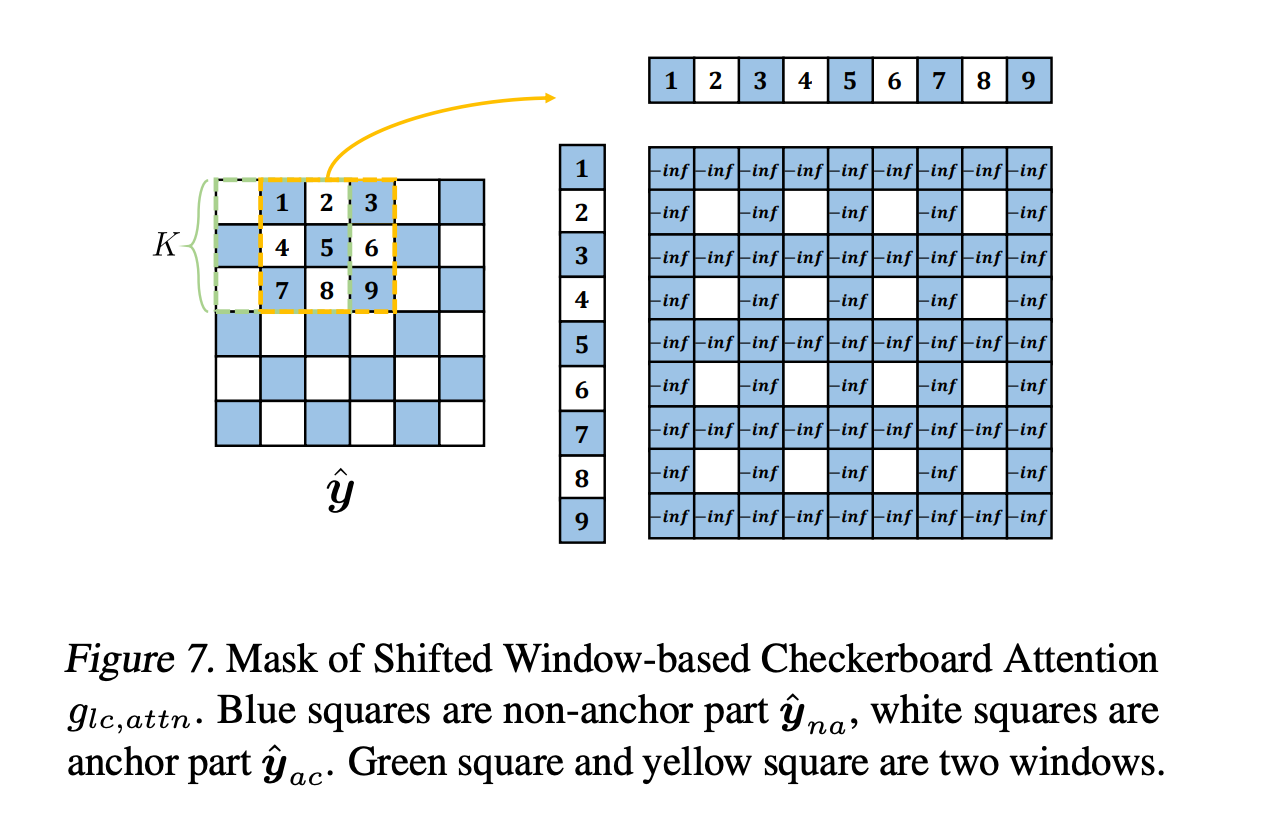
논문에서는 i번째 슬라이스내에서 작동하는 과정을 예로 들었다.
-
잠재표현 의 크기가 HxW라고 한다면, 를 overlap하는 window로 나뉙 위해 stride를 1로 설정, window의 크기는 KxK로 설정한다. (여기서 K=5)
-
로컬한 상관관계 추출을 위해 각 window의 어텐션 맵 게산. Convolution 기반의 Context Module처럼 와 간의 상호작용 및 내에서의 상호작용은 허용하지 않음.
-
그림에서 KxK 컨볼루션을 상요하여 local context를 합치고 이를 FFN에 전달한다.
전체 과정은 Transformer와 유사하게 동작함.
- ,,는 로 정의
- mask는 어텐션 마스크
- S는 각 슬라이스의 채널 수(320 / 10 = 32)
Intra-slice global spatial context module
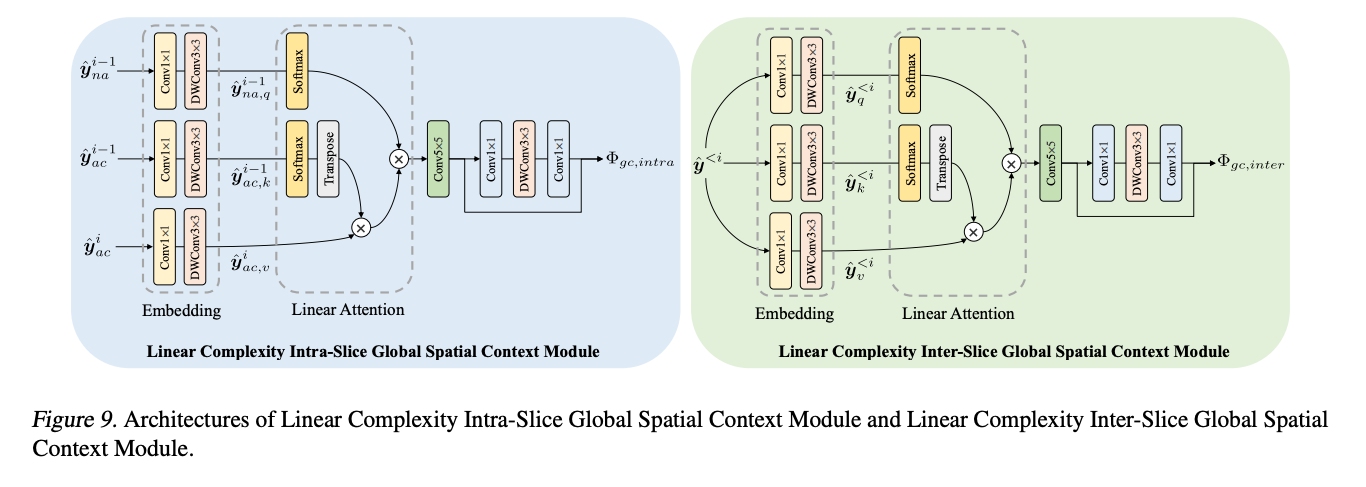
-
디코딩 과정에서 심볼 간의 global correlations를 결정하는 것은 매우 어려운 Task이다. -> 디코딩 중에는 심볼이 알려지지 않기 때문.
-
잠재 표현에서 각 채널은 고유한 정보를 담고 있다. 채널들이 유사한 global similarities를 가지는 것은 Figure3을 통해 확인할 수 있다.
-
현재 슬라이스를 디코딩 할 때, 디코딩 된 이전 슬라이스가 현재 슬라이스의 global correlation을 추정하는데 도움을 줌.
global correlation을 추정하는 대표적인 방법은 코사인 유사도지만 fixed된 방식이며, 특징을 정확하게 포착하지 못할 수 있다.
이를 극복하기 위해 Attention Map을 사용하여 global correlation을 추정한다. -> 어텐션에서 k,q,v는 모두 학습 가능한 파라미터기 때문.
다음은 이차복잡도인 방법과 선형 복잡도인 방법에 대한 설명이다.
i-1번째 슬라이스와 i번째 슬라이스 과정을 예로 들었다.
Vanilla Approach
-
를 compress or decompress할 때 과 의 상관관계를 계산된다.
-
checkerboard local context module은 non-anchor를 디코딩할 때 앵커 부분을 visible하게 만들기 때문에, 의 앵커부분과 및 사이의 어텐션 맵을 곱해서 과 간의 global correlation을 구함.
-
local correlation로 인해 인접한 심볼들은 유사한 global correlation을 가진다.
-
인접한 심볼들의 global correlation을 집계하고, 어텐션 맵을 조정하기 위해 KxK 컨볼루션을 사용
여기서 3 x 3 depth-wise convolutional layer를 임베딩에 사용하는데 기본 컨볼루션에 비해 다음과 같은 장점을 가진다고 한다.
- 가벼움. 전체 복잡도에 미치는 영향이 줄어든다.
- translation equivariance 덕분에 모든 resolution에 유연하게 사용가능.
- zero-padding과 boundary effect로 위치 정보를 임베딩할 수 있다.
- DepthRB(depth-wise residual bottleneck)으로 비선형성 강화.
하지만 quadratic complexity가 단점이다. - 복잡하고 시간이 오래걸림... 여기서 L= HxW
Linear Complexity Approach
- Vanila에서 의 계산 복잡도는 라고 한다.
- 하지만 를 먼저 계산하면 계산 복잡도는 라고 저자는 주장함.
효율적인 어텐션 연산은 non-negativity와 linear complexity를 위해 도입되었다. (Shen, 2021)
방법은 행에서 에 소프트맥스 연산을, 열에서 에 소프트맥스 연산을 취함.
위 식에서 는 learnable한 유사성 척도로 사용됨.
이 연산의 복잡도는 로, 해상도에 대해 선형 복잡도를 가진다. 이 선형 복잡도는 고해상도 이미지 코딩을 위한 global spatial context module을 사용하는 것을 더 쉽게 만들어준다고 한다.
Inter-slice global spatial context module
- 슬라이스 간의 global correlations을 고려하여, intraslice global context module을 inter-slice global context로 확장함.
- 현재 슬라이스의 심볼에서, 이전 슬라이스의 동일한 위치에 있는 심볼이 현재 슬라이스 심볼의 근사치로 사용.
- 슬라이스 간 상관관계가 있기 때문. -> Fig2
- 근사치(approximation) 사용으로 anchor와 non-anchor에 더 많은 컨텍스트를 통해 이점을 가질 수 있다.
선형 복잡도에 관한 수식은 다음과 같다.
여기서 i는 i번째 슬라이스를 의미한다.
Intra-slice global spatial context module과 마찬가지로, 어텐션을 사용하여 유사성을 측정한다.
슬라이스 간 global context를 효율적으로 하기 위해, vanila attention의 소프트맥스 연산을 두 개의 독립된 소프트맥스 연산으로 나눴다.
이를 통해 의 전체 복잡도를 가진다고 한다.
Result

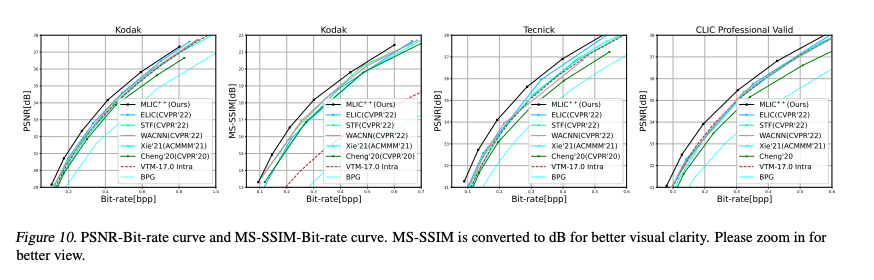
정성 & 정량평가에서 두 손실함수로 최적화한 MLIC++가 더 좋은 성능을 보였다.
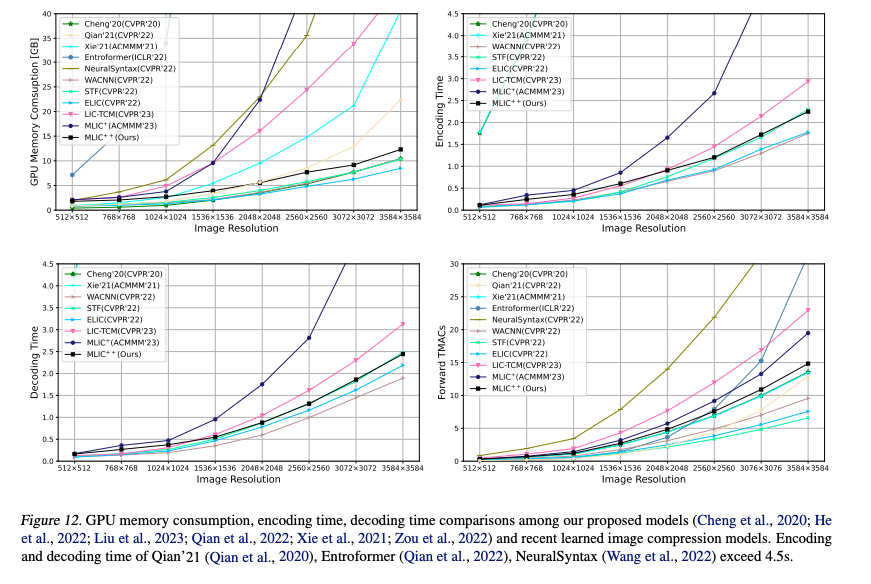
GPU 메모리 소모나 인코딩 & 디코딩 속도 측면에서도 저자가 이전에 제안한 MLIC+보다 소모량과 속도 차이가 확연하게 나는 것을 확인할 수 있다.
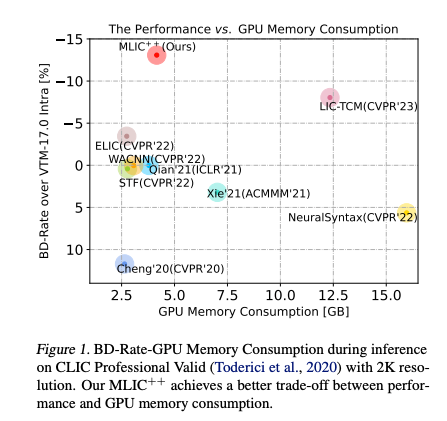
Ablation Study
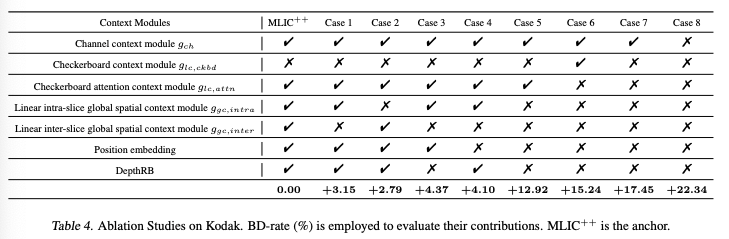
저자가 제안한 Checkerboard attention context module ,Linear intra-slice global spatial context module, Linear inter-slice global spatial context module 등 모듈에 대해 ablation study를 진행한 결과이다. 하나의 모듈이라도 빠질 경우 BD-rate가 나빠지는 것을 확인할 수 있다.
Conclusion
- checkerboard attention를 사용한 local spatial context module과 선형복잡도의 intra-slice & inter-slice global context module을 제안.
- 세 모듈을 바탕으로 MEM++라는 엔트로피 모델을 제안함.
- MLIC++는 선형적인 GPU메모리 소비를 보였고, 이는 고해상도 이미지 코딩에 적합했다.
- 향후에는 MLIC++를 보다 실용적으로 만들 것이다.
-> 인코더 & 디코더의 비대칭 설계 + 더 가벼운 MEM++ 연구.
이상으로 현재 학습 기반 이미지 압축에서 SOTA를 유지하고 있는 MLIC++에 대해 정리하였습니다.
최근 연구에서 비교모델로 벤치마킹되는 모델인만큼 한 번쯤은 읽어봐야할 논문 같습니다.
