[Compression] The Devil Is in the Details: Window-based Attention for Image Compression (WACNN, STF)리뷰
Image Compression
논문 제목
The Devil Is in the Details: Window-based Attention for Image Compression (CVPR 2022)
URL: https://arxiv.org/abs/2203.08450
인용수 : 168회 (24.10.24 기준)
요약
- CNN 기반 모델은 nonrepetitive textures와 같은 local redundancy를 캡처하기에는 적합하지 않아서 reconstruction quality에 큰 영향을 미친다. -> "이미지 압축에서 global structure & local texture를 어떻게 잘 활용하는가"가 core problem으로 떠올랐다.
- ViT와 Swin Transformer에서 영감을 받아, global-related feature learning과 local-aware attention mechanism을 결합하면 이미지 압축 성능이 향상됨을 발견.
- 본 논문에서는 local features learning을 위해 보다 간단하면서도 효과적인 window-based local attention block을 제안.
- 제안된 window-based local attention block은 CNN 및 Transformer 모델의 성능을 향상시키는 plug-and-play 요소로 사용가능하다.
- 최종적으로 WAM을 적용한 Symmetrical TransFormer (STF) framework와 CNN 기반의 framewokr(WACNN) 두 프레임워크를 제안했다.
Method
Window-based Attention
- 이전의 연구에서 Attention 매커니즘을 사용하여 global receptive field에 기반한 attention masks를 생성한다.
- 하지만 Classification, Segmentation, Object Detection과 달리, image compression에서의 global semantic information은 다른 비전 태스크보다 실용적이진 않음.
Attention in Non-overlapped Windows
- 저자는 공간적으로 인전합 요소에 기반하여 attention mask를 생성하면 더 적은 계산비용으로 RD performance를 향상시킨다고 한다.
- 효율적인 모델링을 위해 window-based attention을 제안.
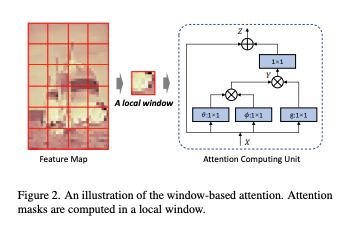
위 그림처럼 Feature map은 MxM 크기의 중첩되지 않은 윈도우로 나뉜다.
각 윈도우에서 attention map을 개별적으로 계산한다.
와 는 K번째 윈도우 내에서 각각 i번째와 j번째 elements를 나타낸다.
여기서 , 이다
와 는 채널 간 변환 (cross-channel transforms)이다.
: embeded Gaussian function
: 정규화 계수
i와 k가 주어질 때,
: k번째 윈도우의 j 차원에 따른 소프트맥스 계산
위 어텐션 매커니즘에는 Residual connection이 필요하다고 하며, 출력은 아래 수식과 같다.
여기서 는 의 위치별 임베딩을 계산하는 가중치 행렬이다.
Window Attention Module

이전 연구에서는 NLAM(Non-Local Attention Module)을 제안했고, 이는 Non-local Block과 Conv Layer로 구성된다.
저자는 NLAM를 WAM으로 대체하여 높은 Contrast를 가지는 영역에 초점을 맞췄다고 한다.
위 그림을 살펴보면 WAM이 복잡한 영역(high contrast)을 포함하는 부분에 더 많은 비트를 할당하고 단순한 영역(low contrast)dpsms 더 적은 비트를 할 당하는 것을 확인할 수 있다.
반면 NLAM은 global receptive field를 사용하여 서로 다른 영역에 균등한 비트를 할당하는 경향이 있다.
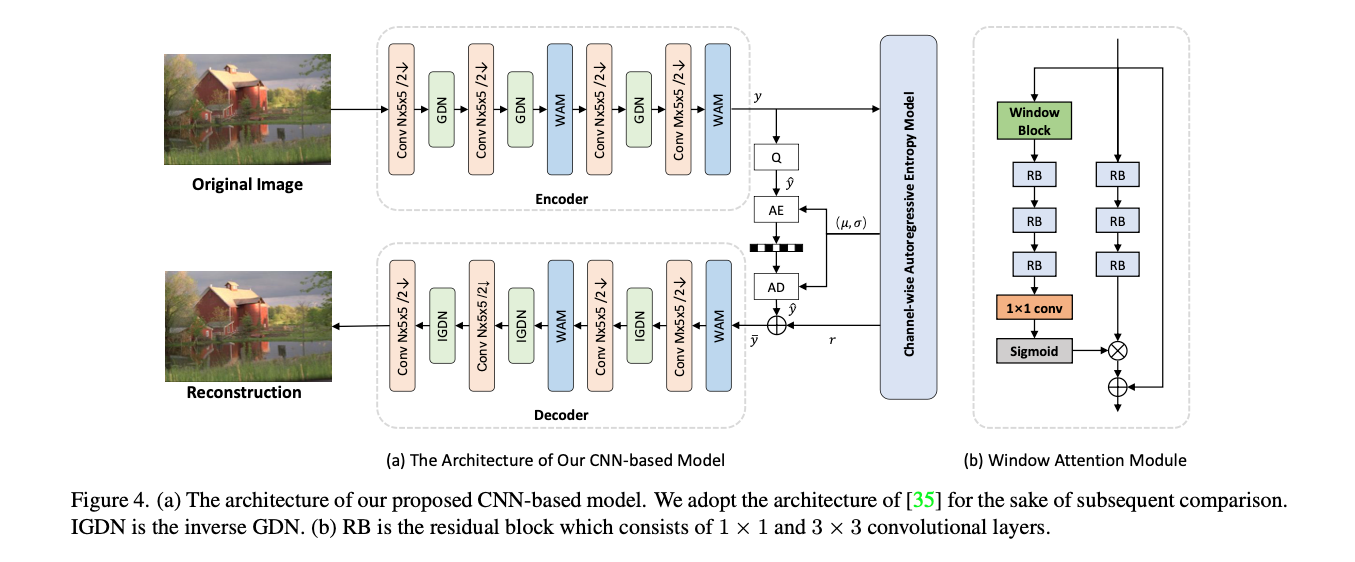
CNN-based Architecture
모델은 "Channel-wise autoregressive entropy models for learned image compression"를 기반으로 설계되었다.
인코더-디코더 각각에 제안된 WAM을 배치했다.
WAM은 서로 다른 영역에 비트를 보다 합리적이고 효율적으로 할당한다. 그리고 오버헤드는 발생하지 않는다고 한다.
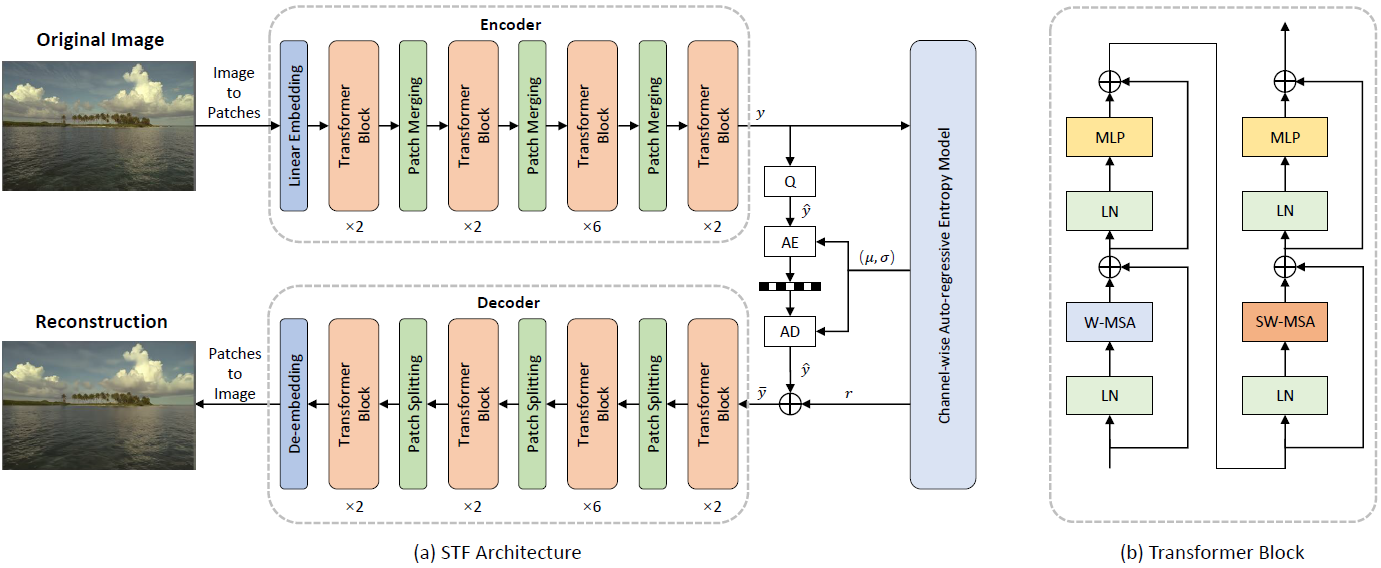
Transformer-based Architecture
Rethinking the Transformer
- 기존 연구들의 대부분은 공간적 중복을 제거하고 구조를 포착하기 위해 CNN을 기반 모델을 사용. 이미지를 패치로 직접 분할하는 것은 각 패치 내의 space redundancy를 유발할 수 있다.
- GDN(Generalized Divisive Normalization)은 이미지 압축에서 주로 사용되는 정규화 및 비선형 활성화 함수이나,Transformer 기반 깊은 구조에서는 불안정하다.
또한, GDN과 Transformer의 주의 메커니즘은 호환되지 않는다. - large field에서 attention map을 계산하는 건 optimal하지 않다.
저자는 Swin Transformer에 영감을 받아 Local window 내에서 attention map을 계산하였다.
Transformer-based Encoder
Vision Transformer의 원리와 동일하게 원시 이미지를 N개의 패치로 분할한 후 Linear Embeding을 적용하여 C채널 개의 feature map을 생성한다.
이렇게 생성된 시퀀스는 Transformer와 patch merging layer에 입력된다.
Transformer -> 윈도우 내에서 attention mask 계산
patch merging layer -> 특징의 resolution을 다운샘플링하고 채널을 두 배로 확장
Transformer-based Decoder
디코더는 인코더와 대청적으로 설계함.
디코더에서는 업샘플링 과정과 시퀀스를 다시 이미지로 만들어주는 patch splitting layer와 de-embedding layer를 통해 복원된 이미지를 생성한다.
Entropy Model
잠재 표현의 확률 분포를 보다 효과적이고 효율적으로 예측하기 위해, SGM 기반 channel-wise auto-regressive entropy model을 사용.
Result

제안 모델이 전통적인 압축 방법보다 압축 효율 및 이미지 품질이 뛰어난 것을 확인할 수 있다.
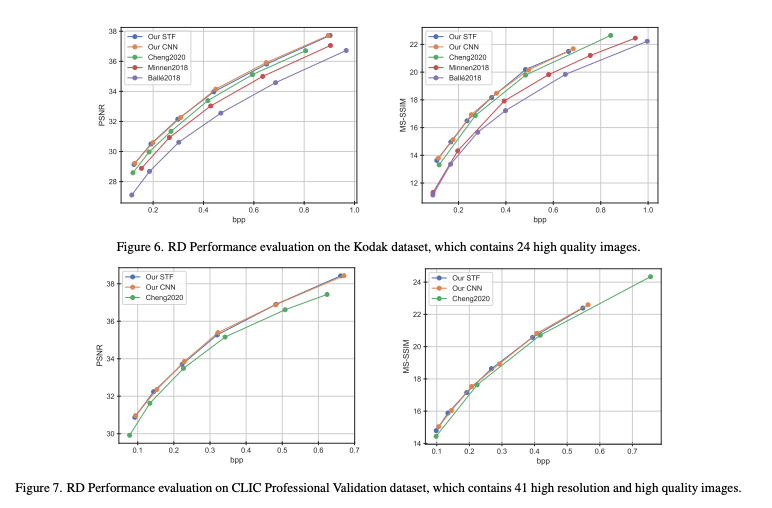
CLIC 검증데이터셋으로 나타낸 RD Curve에서도 기존 딥러닝 방법론보다 높은 성능을 보이는 것을 확인할 수 있었다.
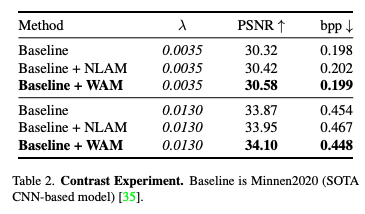
위 이미지는 Attention Module의 ablation study 결과이다.
이전에 제안된 NLAM보다 저자가 제안하는 WAM이 정량지표에서 앞서는 것을 확인할 수 있다.
Conclusion
- 본 논문에서는 localaware attention mechanism 연구하여 신경망이 학습한 global structure와 attention unit이 발견한 local texture를 결합하는 것이 중요함을 확인.
- CNN이나 Transformer 모델을 향상시키기 위한 plug-and-play component로 작동할 수 있는 flexible window-based attention module을 제시
