[Compression] End-to-End Optimized Versatile Image Compression With Wavelet-Like Transform - iWave++ 리뷰
Image Compression

논문 제목
End-to-End Optimized Versatile Image Compression With Wavelet-Like Transform
URL: https://ieeexplore.ieee.org/document/9204799
인용수 : 163회 (24.11.11 기준)
이 논문을 이해하기 위해서는
iWave: CNN-Based Wavelet-Like Transform for Image Compression과 Wavelet Transform & Lifting Scheme에 대한 전반적인 내용을 알고계셔야 합니다...!
URL: https://ieeexplore.ieee.org/document/8931632
인용수 : 76회 (24.11.11 기준)
요약
- trained wavelet-like transform 기반 모델인 iWave를 활용하여 iWave++를 제안.
- 기존 방식과 달리 iWave++는 단일 모델로 무손실(lossless) 및 손실(lossy) 압축을 모두 지원
- 실험결과 Lossy iWave++는 Kodak 데이터셋에서 BPG에 비해 17.34%의 bits saving 효과를 보여줌.
- Lossless iWave++ 또한 FLIF와 비교해 유사하거나 더 나은 성능을 보여줌.
Introduction

- 이전 연구에서 revertible transform인 iWave를 제안. 전통적인 웨이블릿 변환은 Lifting Scheme으로 구현할 수 있으며, lifting scheme 자체는 information lossless이다.
- iWave의 아이디어는 Lifting Scheme의 필터를 trained convolutional
neural networks (CNNs)로 대체하여 wavelet-like transform-iWave를 만드는 것. - iWave는 전통적인 웨이블릿을 사용한 JPEG-2000 보다 더 나은 압축 성능을 달성.
- 하지만 BPG나 다른 end-to-end 방법 보다는 성능이 떨어지는 문제가 있었고, lossless에 대해서는 연구를 하지 않았음.
Related Work
End-to-End Image Compression
Lossy Image Compression
- 제안된 iWave++는 정보 손실이 없는 iWave 변환을 사용함
- iWave는 wavelet-like transform으로 multi-scale pyramid decomposition과 scalable bitstream을 지원한다.
Lossless Image Compression
- Lossless coding은 entropy coding으로 잘알려져있으며, information source의 정확한 확률 추정에 의존한다.
- likelihood-based generative models은 산술 인코더/디코더를 사용하면 무손실 이미지 압축에도 사용가능하다고함.
- 보통의 압축 방법은 하나의 압축 방법만 지원하지만, iWave++는 무손실도 가능하면서 손실압축도 가능하기에 차별성을 가진다고함.
Lifting Scheme of Wavelet Transform
- lifting scheme은 2세대 wavelet transform이라고 알려져 있으며, custom-design을 통해 웨이블릿을 구성하는 방식이다.
- lifting scheme은 구현이 용이할 뿐만 아니라 새로운 웨이블릿을 설계할 때 높은 자유도를 제공한다.
Lifting scheme 등장 이전에는 적절한 특성을 만족하는 웨이블릿을 handcrafting으로 설계해야했기에 쉽지 않은 작업이었다.
Lifting scheme은 간단한 필터 연결을 통해 sophisticated wavelets을 구현하는 방법을 제안했다.
Lifting schemed은 세 단계로 구성된다
1. Split
2. Prediction
3. Update
예를 들어, 1차원 신호 의 경우 신호는 짝수부분 와 홀수 부분 로 나뉜다.
와 사이에는 강한 상관관계가 존재, 를 사용하여 를 예측할 수 있다. (또는 그 반대도 가능)
여기서 는 예측에 사용되는 특정 필터를 나타내고 는 prediction residual을 나타낸다.
일반적으로 는 의 고주파 정보를 포함한다.
다음으로 Update 단계가 수행된다.
여기서 는 업데이터에 사용되는 특성 필터를 나타내며, 은 의 저주파 정보를 포함한다.
Prediction과 Update는 basic lifting step을 구성하며, Lifting Scheme에서 multiple lifting steps을 사용한다.
위 과정들은 를 과 로 변환하고, 적절하게 선택된 prediction과 update 필터를 통해 이 변환은 특정 유형의 웨이블릿(specific kind of wavelets)이 된다.
Lifting Scheme은 이론적으로 무손실이다.
그 이유는 과 가 있다면 다음과 같이 를 재구성할 수 있기 때문임.
여기서 은 split의 역연산인 Merge연산을 나타낸다.
위 과정은 prediction과 update가 적절히 선택되면 inverse wavelet transform이 된다고한다.
iWave++는 iWave의 아이디어를 바탕으로 엔트로피 코딩과 de-quantization 모듈을 추가하여 end-to-end로 최적화하였음.
(기존 iWave는 end-to-end 프레임워크가 아니였다)
Proposed Method
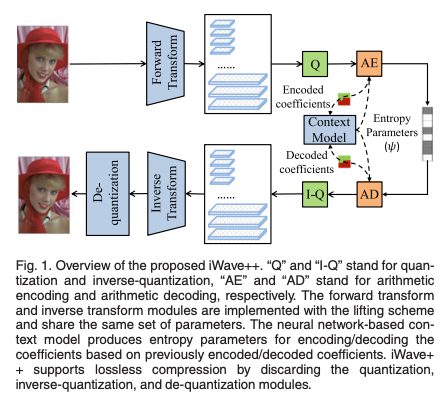
Overview of iWave++
제안된 iWave++ 프레임워크는 상단 이미지 (Fig. 1.)에 있다.
프레임워크는 네 가지 신경망 기반 모듈이 있다.
- forward transform (Encoder)
- inverse transform (Decoder)
- de-quantization
- context model for entropy coding
기존의 end-to-end 방식과 다르게, forward transform에서는 정보손실이 발생하지 않는다. iWave++가 lossless 및 variable rate compression을 지원하기 때문.
손실 압축의 경우, 계수 𝑦는 스칼라 양자화를 통해 이산 인덱스 𝑞를 얻는다.
여기서 은 rate와 distortion을 제어하는 유일한 parameter인 quantization step라고 한다.
무손실 압축의 경우에는 가 된다.
양자화된 계수 는 신경망 기반의 Context Model의 도움을 받아 arithmetic encoder에서 압축되어 비트로 변환된다.
디코더에서는 arithmetic decoder를 사용하여 비트스트림을 압축 해제한 후, inverse quantization을 통해 재구성된 계수 를 얻는다.
or
-> lossless
은 역변환인 를 통해 재구성된 이미지 로 변한된다.
여기서 는 의 역변환으로 동일한 매개변수 집합을 공유한다.
따라서 순방향 변환 이후 양자화에 의한 정보 손실은 역변환에서 보상받을 수 없음.
이를 보완하기 위해 역변환 이후 de-quantization module을 통해 양자화에 의한 손실을 보상한다고함.
iWave: Wavelet-Like Transform
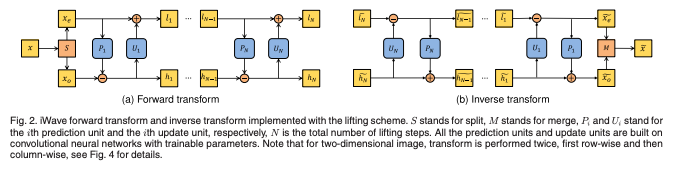
1차원 신호를 예시로 lifting scheme을 설명하면 다음과 같다.
위 이미지와 같이 한 단계의 lifting(prediction & update) 후에 과 을 얻는다.
iWave에는 와 로 표기된 N개의 리프팅 단계가 있다.
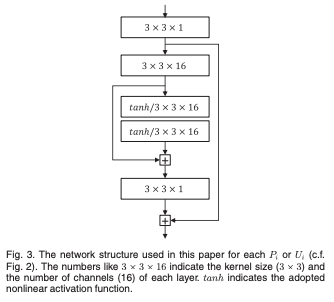
와 는 모두 CNN으로 구현되며, 파라미터는 end-to-end 학습을 통해 최적화된다.
본 논문에서는 와 에 대해 일관된 구조를 사용.
N단계의 리프팅이 끝난 후에 저주파 성분 과 을 웨이블릿 계수로 얻게된다.
2차원 이미지의 경우, 변환은 행 방향과 열 방향으로 두 번 진행된다.
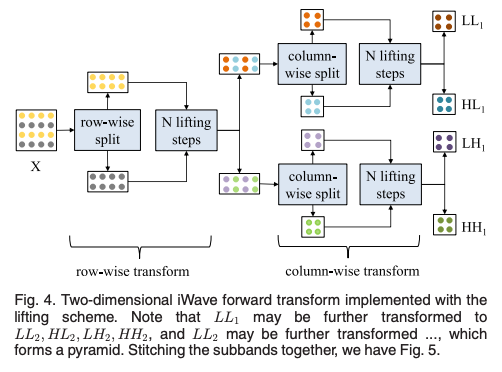
그림 4와 같이 은 모두 2차원으로 여기서 L은 저주파를, H는 고주파를 나타낸다.
natural images를 위해서 종종 multiscale pyramid decomposition을 수행한다고한다.
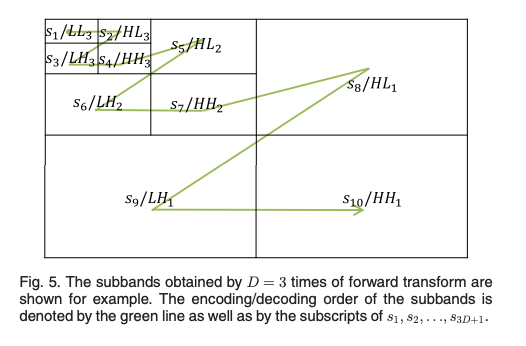
LL1의 서브밴드를 변환하여 LL2~HH2를 얻고 이후에 LL2 서브밴드를 다시 변환하는 방식으로 진행된다.
D번의 forward transform 후에는 3D+1개의 서브밴드를 얻을 수 있다.
Entropy Coding
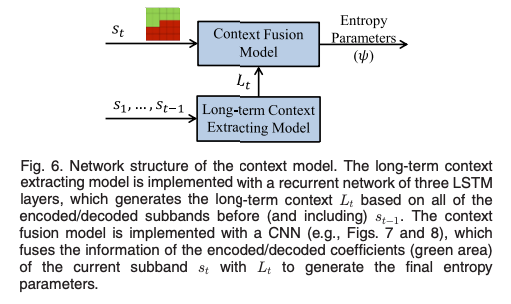
엔트로피 코딩은 context model, probability model, 그리고 arithmetic coding engine으로 구성된다.
Context Model
본 논문에서 Conext Model은 "Joint autoregressive and hierarchical priors for learned image compression"을 사용하였음.Context Model 논문 리뷰
이미 압축된 서브밴드를 처리하여 long-term context 의 정보와 현재 서브밴드의 이미 압축된 계수 정보를 결합하여 최종 엔트로피 파라미터를 생성한다.
Probability Model
컨텍스트 모델의 output은 arithmetic coding에서 사용할 확률분포를 결정하는 데 사용.
Probability Model은 누적 분포를 파라미터화하고 이를 미분하여 필요한 확률분포를 얻는다.
누적분포는 다음과 같이 정의된다.
여기서 K=5이고, 각 함수 는 다음과 같은 형태이다.
k=1
1< k< K
k=K 일 때,
파라미터 ,,는 엔트로피 파라미터 c를 구성한다.
De-Quantization
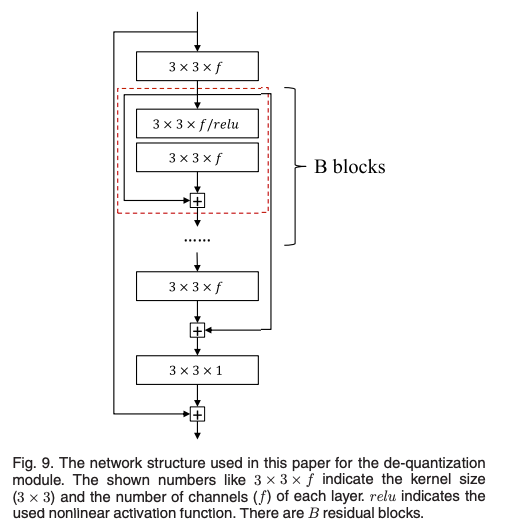
De-Quantization은 양자화로 이한 손실을 보상하고 복원된 이미지의 품질을 향상시킬 수 있다고 함.
image restoration 연구에서 영감을 받아서 단순한 CNN을 사용했음.
해당 네트워크는 global shortcut과 residual blocks을 포함하고, 이는 학습속도를 가속시킨다고함.
이미지에서 3x3은 커널의 크기이며, f는 채널 수를 나타낸다.
Experimental Results
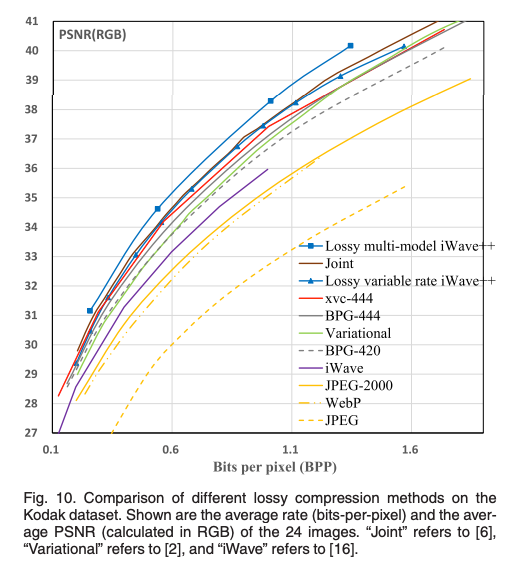
RD-Curve를 살펴보면 iWave++이 비교 모델들보다 성능이 유사하거나 좋은 것을 확인할 수 있다.

Kodak 단일 이미지로 봐도 전통적인 압축 방법은 BPG보다 이미지 품질은 높이면서 Rate는 낮춘 것을 확인할 수 있다.
Computational Complexity and Speed-Up
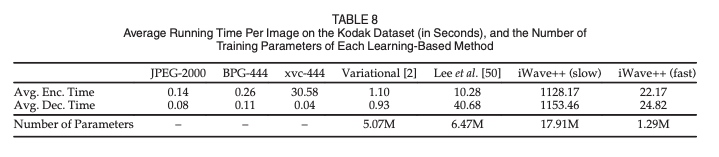
- (slow) iWave++는 매우 높은 계산 복잡도를 가지며, 특히 엔트로피 코딩이 가장 많은 시간을 소모한다.
- 이를 보완하기 위해 가벼운 버전의 컨텍스트 모델을 사용했고, 성능 손실이 거의 없음을 확인.
- GPU의 병렬 컴퓨팅을 활용하기 위해 블록 병렬 코딩을 설계함. ->각 서브밴드를 코딩할 때 계수를 16x16 블록으로 나누어 병렬로 처리.
- (fast) iWave++는 인코딩 시간을 약 98% 줄였음. 하지만 다른 모델들 보다 느리기에 개선의 여지가 많음.
이거는 AutoRegressive Context Model의 고질적인 문제이기 때문에 Wavelet-like Module의 인코딩 디코딩 속도를 시사하진 않았다..
Conclusion
- 본 논문에서는 wavelet-like transform을 활용한 end-to-end image compression 프레임워크인 iWave++를 제안.
- iWave++는 wavelet-like transform, 엔트로피 코딩, de-quantization 세 모듈로 구성되어있으며, 기존 end-to-end 방법들과 다르게 정보의 손실이 발생하지 않아 단일모델로 손실& 무손실 압축 모두 지원한다.
- iWave++는 벤치마크 데이터셋인 Kodak 데이터셋에서 비교 모델보다 높은 성능을 보여 SOTA를 달성했음.
