6.1 Introduction
A special type of counting process
💡
Counting process
A counting process ( N t ) t ≥ 0 (N_{t})_{t \geq 0} ( N t ) t ≥ 0 0 ≤ s ≤ t 0 \leq s \leq t 0 ≤ s ≤ t N s ≤ N t N_{s} \leq N_{t} N s ≤ N t
N t N_t N t [ 0 , t ] [0, t] [ 0 , t ]
ex) t t t
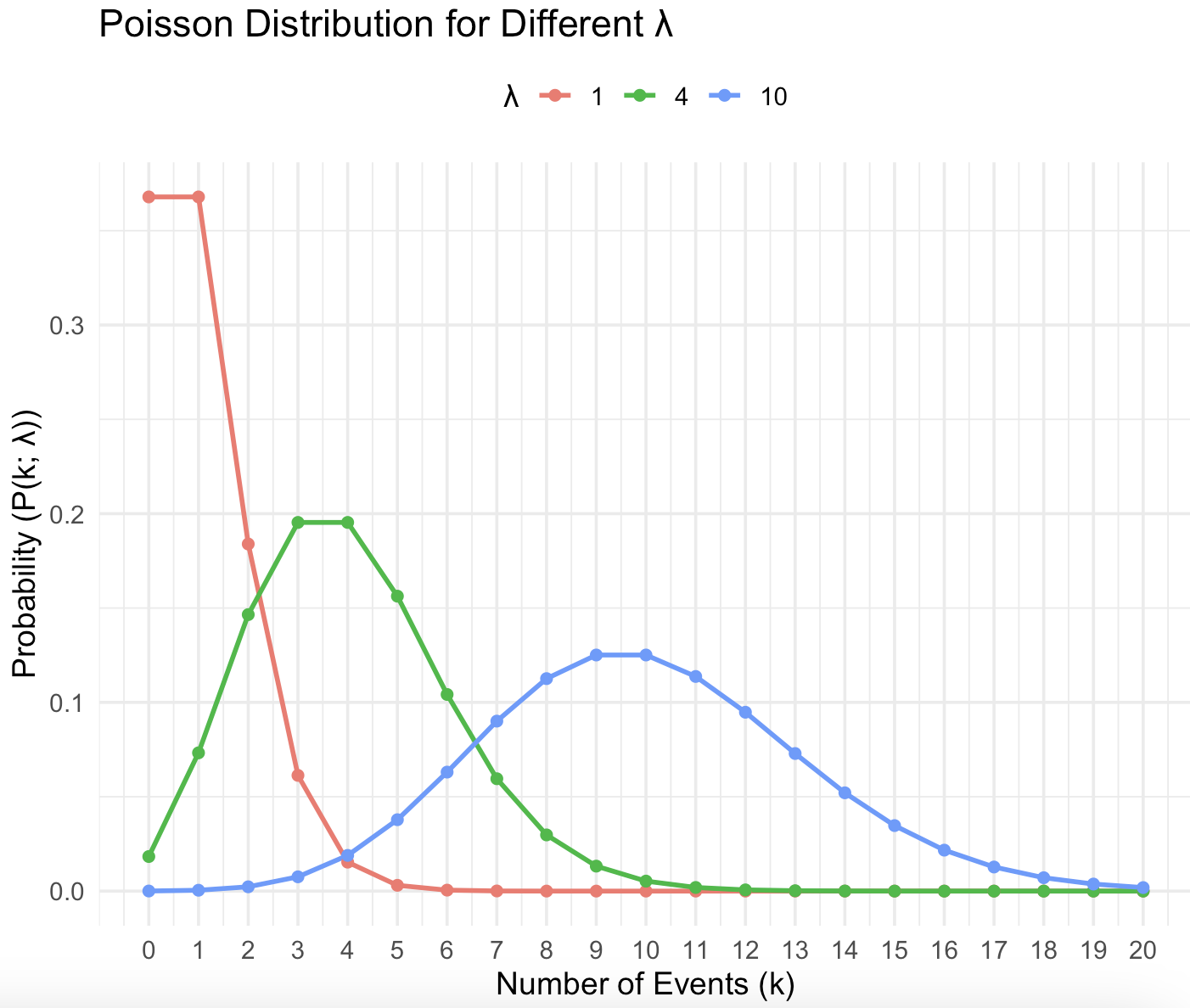
Poisson Distribution
X ∼ P o i s ( λ ) X \sim Pois(\lambda) X ∼ P o i s ( λ )
pmf f X ( x ) = P ( X = x ) = e − λ λ x x ! , where x = 0 , 1 , 2 , … f_X(x) = P(X = x) = e^{-\lambda} \frac{\lambda^x}{x!}, \quad \text{where } x = 0, 1, 2, \dots f X ( x ) = P ( X = x ) = e − λ x ! λ x , where x = 0 , 1 , 2 , …
E [ X ] = λ E[X] = \lambda E [ X ] = λ E [ X ] = ∑ x = 0 ∞ x e − λ λ x x ! = λ e − λ ∑ x = 1 ∞ λ x − 1 ( x − 1 ) ! = λ \mathbb{E}[X] = \sum_{x=0}^\infty x e^{-\lambda} \frac{\lambda^x}{x!} \\= \lambda e^{-\lambda} \sum_{x=1}^\infty \frac{\lambda^{x-1}}{(x-1)!} \\= \lambda E [ X ] = ∑ x = 0 ∞ x e − λ x ! λ x = λ e − λ ∑ x = 1 ∞ ( x − 1 ) ! λ x − 1 = λ V a r ( X ) = λ Var(X) = \lambda V a r ( X ) = λ E [ X 2 ] = ∑ x = 0 ∞ x 2 e − λ λ x x ! = ∑ x = 1 ∞ x 2 e − λ λ x x ! = λ e − λ ∑ x = 1 ∞ x λ x − 1 ( x − 1 ) ! = λ e − λ [ ∑ x = 1 ∞ ( x − 1 ) λ x − 1 ( x − 1 ) ! + ∑ x = 1 ∞ λ x − 1 ( x − 1 ) ! ] = λ e − λ [ λ ∑ x = 2 ∞ λ x − 2 ( x − 2 ) ! + ∑ x = 1 ∞ λ x − 1 ( x − 1 ) ! ] = λ e − λ [ λ ∑ z = 0 ∞ λ z z ! + ∑ y = 0 ∞ λ y y ! ] = λ e − λ [ λ e λ + e λ ] = λ 2 + λ V a r ( X ) = E [ X 2 ] − ( E [ X ] ) 2 = λ 2 + λ − λ 2 = λ \mathbb{E}[X^2] = \sum_{x=0}^\infty x^2 e^{-\lambda} \frac{\lambda^x}{x!} \\ = \sum_{x=1}^\infty x^2 e^{-\lambda} \frac{\lambda^x}{x!} \\ = \lambda e^{-\lambda} \sum_{x=1}^\infty x \frac{\lambda^{x-1}}{(x-1)!} \\ = \lambda e^{-\lambda} \left[ \sum_{x=1}^\infty (x-1) \frac{\lambda^{x-1}}{(x-1)!} + \sum_{x=1}^\infty \frac{\lambda^{x-1}}{(x-1)!} \right] \\ = \lambda e^{-\lambda} \left[ \lambda \sum_{x=2}^\infty \frac{\lambda^{x-2}}{(x-2)!} + \sum_{x=1}^\infty \frac{\lambda^{x-1}}{(x-1)!} \right] \\ = \lambda e^{-\lambda} \left[ \lambda \sum_{z=0}^\infty \frac{\lambda^z}{z!} + \sum_{y=0}^\infty \frac{\lambda^y}{y!} \right] \\ = \lambda e^{-\lambda} [\lambda e^\lambda + e^\lambda] \\ = \lambda^2 + \lambda \\ \mathrm{Var}(X) = \mathbb{E}[X^2] - (\mathbb{E}[X])^2 \\ = \lambda^2 + \lambda - \lambda^2 \\ = \lambda E [ X 2 ] = ∑ x = 0 ∞ x 2 e − λ x ! λ x = ∑ x = 1 ∞ x 2 e − λ x ! λ x = λ e − λ ∑ x = 1 ∞ x ( x − 1 ) ! λ x − 1 = λ e − λ [ ∑ x = 1 ∞ ( x − 1 ) ( x − 1 ) ! λ x − 1 + ∑ x = 1 ∞ ( x − 1 ) ! λ x − 1 ] = λ e − λ [ λ ∑ x = 2 ∞ ( x − 2 ) ! λ x − 2 + ∑ x = 1 ∞ ( x − 1 ) ! λ x − 1 ] = λ e − λ [ λ ∑ z = 0 ∞ z ! λ z + ∑ y = 0 ∞ y ! λ y ] = λ e − λ [ λ e λ + e λ ] = λ 2 + λ V a r ( X ) = E [ X 2 ] − ( E [ X ] ) 2 = λ 2 + λ − λ 2 = λ mgf M X ( t ) = ∑ x = 0 ∞ e t x e − λ λ x x ! M_X(t) = \sum_{x=0}^\infty e^{tx} e^{-\lambda} \frac{\lambda^x}{x!} M X ( t ) = ∑ x = 0 ∞ e t x e − λ x ! λ x M X ( t ) = ∑ x = 0 ∞ e t x e − λ λ x x ! = e − λ ∑ x = 0 ∞ ( λ e t ) x x ! = e − λ e λ e t = e λ ( e t − 1 ) M_X(t) = \sum_{x=0}^\infty e^{tx} e^{-\lambda} \frac{\lambda^x}{x!} \\ = e^{-\lambda} \sum_{x=0}^\infty \frac{(\lambda e^t)^x}{x!} \\ = e^{-\lambda} e^{\lambda e^t} \\ = e^{\lambda (e^t - 1)} M X ( t ) = ∑ x = 0 ∞ e t x e − λ x ! λ x = e − λ ∑ x = 0 ∞ x ! ( λ e t ) x = e − λ e λ e t = e λ ( e t − 1 )
there are several ways to characterize the Poisson process
the number of events that occur in fixed intervals
when events occur
def1) Poisson process
💡
def1) Poisson process
A Poisson process with parameter λ \lambda λ ( N t ) t ≥ 0 (N_{t})_{t \geq 0} ( N t ) t ≥ 0
N 0 = 0 N_0 = 0 N 0 = 0 For all t > 0 t>0 t > 0 N t N_t N t λ t \lambda_t λ t
(Stationary increments) For all s , t > 0 \ s, t > 0 s , t > 0 N t + s − N s \ N_{t+s} - N_s N t + s − N s N t \ N_t N t
P ( N t + s − N s = k ) = P ( N t = k ) = e − λ t ( λ t ) k k ! , for k = 0 , 1 , … P(N_{t+s} - N_s = k) = P(N_t = k) = \frac{e^{-\lambda t} (\lambda t)^k}{k!}, \quad \text{for } k = 0, 1, \dots P ( N t + s − N s = k ) = P ( N t = k ) = k ! e − λ t ( λ t ) k , for k = 0 , 1 , …
(Independent increments) For 0 ≤ q < r ≤ s < t , N t − N s 0 \leq q < r \leq s < t, \ N_t - N_s 0 ≤ q < r ≤ s < t , N t − N s N r − N q N_r-N_q N r − N q
Stationary increments property: the distribution of the number of arrivals in an interval only depends on the length of the interval
Independent increments property: the number of arrivals on disjoint intervals are independent random variables
N t N_t N t
E [ N t ] = λ t E[N_t] = \lambda t E [ N t ] = λ t
Example 6.2
6.2 Arrival, Interarrival times
def2) Poisson process
💡
def2) Poisson process
Let X_1, …, X_n be a sequence of iid exponential random variables with parameter λ \lambda λ t > 0 t>0 t > 0
N t = max { n : X 1 + ⋯ + X n ≤ t } N_t = \max \{ n : X_1 + \cdots + X_n \leq t \} N t = max { n : X 1 + ⋯ + X n ≤ t }
with N0 = 0. Then $(N {t})_{t \geq 0}$ defines a Poisson process with parameter λ \lambda λ
Let S n = X 1 + ⋯ + X n , for n = 1 , 2 , … S_n = X_1 + \cdots + X_n, \quad \text{for } n = 1, 2, \dots S n = X 1 + ⋯ + X n , for n = 1 , 2 , …
We call S 1 , S 2 , … S_1, S_2, … S 1 , S 2 , … arrival times of the process, where S k S_k S k k k k
Furthermore, X k = S k − S k − 1 , for k = 1 , 2 , … X_k = S_k - S_{k-1}, \quad \text{for } k = 1, 2, \dots X k = S k − S k − 1 , for k = 1 , 2 , …
is the interarrival time between the ( k − 1 ) (k-1) ( k − 1 ) k k k S 0 = 0 S_0 = 0 S 0 = 0
Memorylessness
💡
A random variable X X X s , t > 0 s,t>0 s , t > 0
P ( X > s + t ∣ X > s ) = P ( X > t ) P(X>s+t|X>s) = P(X>t) P ( X > s + t ∣ X > s ) = P ( X > t )
Minimum of Independent Exponential Random Variables
💡
Minimum of Independent Exponential Random Variables
Let X 1 , … , X n X_1, …, X_n X 1 , … , X n λ 1 , … , λ n \lambda_1, …, \lambda_n λ 1 , … , λ n
Let M = m i n ( X 1 , … , X n ) M = min(X_1,…, X_n) M = m i n ( X 1 , … , X n )
For t > 0 t>0 t > 0 P ( M > t ) = e − t ( λ 1 + … , + λ n ) P(M>t) = e^{-t(\lambda_1+ …, +\lambda_n)} P ( M > t ) = e − t ( λ 1 + … , + λ n ) λ 1 + … + λ n \lambda_1+ …+\lambda_n λ 1 + … + λ n
For k = 1 , 2 , … , n k=1, 2, …, n k = 1 , 2 , … , n
P ( M = X k ) = λ k λ 1 + ⋯ + λ n P(M = X_k) = \frac{\lambda_k}{\lambda_1 + \dots + \lambda_n} P ( M = X k ) = λ 1 + ⋯ + λ n λ k
Exponential dist X ∼ E x p ( λ ) X \sim Exp(\lambda) X ∼ E x p ( λ ) x ∈ [ 0 , inf ) x \in [0, \inf ) x ∈ [ 0 , inf ) λ e − λ x \lambda e^{-\lambda x} λ e − λ x
Example 6.4
Arrival times and Gamma Distribution
💡
Arrival times and Gamma Distribution
For n = 1 , 2 , … , n=1, 2, …, n = 1 , 2 , … , S n S_n S n n n n λ \lambda λ S n S_n S n S n S_n S n
f S n ( t ) = λ n t n − 1 e − λ t ( n − 1 ) ! , for t > 0 f_{S_n}(t) = \frac{\lambda^n t^{n-1} e^{-\lambda t}}{(n-1)!}, \quad \text{for } t > 0 f S n ( t ) = ( n − 1 ) ! λ n t n − 1 e − λ t , for t > 0
Mean and variance are
E ( S n ) = n λ and V a r ( S n ) = n λ 2 E(S_n) = \frac{n}{\lambda} \quad \text{and} \quad Var(S_n) = \frac{n}{\lambda^2} E ( S n ) = λ n and V a r ( S n ) = λ 2 n
Gamma dist. X ∼ G a m m a ( α , β ) X \sim Gamma(\alpha, \beta) X ∼ G a m m a ( α , β ) x ∈ [ 0 , inf ) x \in [0, \inf) x ∈ [ 0 , inf ) f ( x ) = 1 Γ ( α ) β α x α − 1 e − x / β f(x) = \frac{1}{\Gamma(\alpha) \beta^\alpha} x^{\alpha - 1} e^{-x / \beta} f ( x ) = Γ ( α ) β α 1 x α − 1 e − x / β α β \alpha \beta α β α β 2 \alpha \beta^2 α β 2
Example 6.5
6.4 Thinning, Superpostition
Thinning
💡
Thinned Poisson Process
Let ( N t ) t ≥ 0 (N_{t})_{t \geq 0} ( N t ) t ≥ 0 λ \lambda λ type k event with probability p k p_k p k k = 1 , … , n k=1, …, n k = 1 , … , n p 1 + … + p n = 1 p_1 + … + p_n = 1 p 1 + … + p n = 1 N t ( k ) N_t^{(k)} N t ( k ) [ 0 , t ] [0, t] [ 0 , t ] ( N t ( k ) ) t ≥ 0 (N_t^{(k)})_{t \geq 0} ( N t ( k ) ) t ≥ 0 λ p k \lambda p_k λ p k
( N t ( 1 ) ) t ≥ 0 , … , ( N t ( n ) ) t ≥ 0 (N_t^{(1)})_{t \geq 0}, …, (N_t^{(n)})_{t \geq 0} ( N t ( 1 ) ) t ≥ 0 , … , ( N t ( n ) ) t ≥ 0
are independent. Each process is called a thinned Poisson process.
Superposition
💡
Superposition process
Assume that ( N t ( 1 ) ) t ≥ 0 , … , ( N t ( n ) ) t ≥ 0 (N_t^{(1)})_{t \geq 0}, …, (N_t^{(n)})_{t \geq 0} ( N t ( 1 ) ) t ≥ 0 , … , ( N t ( n ) ) t ≥ 0 n n n λ 1 , … , λ n \lambda_1, …, \lambda_n λ 1 , … , λ n N t = N t ( 1 ) + … , + N t ( n ) N_t = N_t^{(1)}+ …, +N_t^{(n)} N t = N t ( 1 ) + … , + N t ( n ) t ≥ 0 t \geq0 t ≥ 0 ( N t ( n ) ) t ≥ 0 (N_t^{(n)})_{t \geq 0} ( N t ( n ) ) t ≥ 0 λ = λ 1 + … + λ n \lambda = \lambda_1+…+\lambda_n λ = λ 1 + … + λ n
Review
continuous time, discrete event 상황에서의 확률 과정
특별한 유형의 counting process →
N t N_t N t t t t
s . t i f 0 ≤ s ≤ t , t h e n N s ≤ N t s.t\ if\ 0≤s≤t,\ then\ N_s≤N_t s . t i f 0 ≤ s ≤ t , t h e n N s ≤ N t
N 0 = 0 N_0=0 N 0 = 0 For all t > 0 N t h a s a p o i s s o n d i s t r i b u t i o n w i t h p a r a m e t e r λ t \text {For all }t>0\ N_t\ \text has\ a \ poisson\ distribution\ with\ parameter\ \lambda t For all t > 0 N t h a s a p o i s s o n d i s t r i b u t i o n w i t h p a r a m e t e r λ t
P ( N t + s − N s = k ) = P ( N t = k ) = e − λ ( t ) k ! ( λ ( t ) ) k , for k = 0 , 1 , … P(N_{t+s} - N_s = k) = P(N_t = k) = \frac{e^{-\lambda (t)}}{k!} \left(\lambda (t)\right)^k, \quad \text{for } k = 0, 1, \ldots P ( N t + s − N s = k ) = P ( N t = k ) = k ! e − λ ( t ) ( λ ( t ) ) k , for k = 0 , 1 , …
P ( X = k ) = λ k e − λ k ! P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!} P ( X = k ) = k ! λ k e − λ X ∼ P o i s s o n ( λ ) P ( X = k ) = λ k e − λ k ! , k = 0 , 1 , 2 , … X \sim \mathrm{Poisson}(\lambda) P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!}, \quad k = 0, 1, 2, \dots \\ X ∼ P o i s s o n ( λ ) P ( X = k ) = k ! λ k e − λ , k = 0 , 1 , 2 , … …
Symbol Meanings: X – the random variable representing the number of events in a given interval λ – the average rate (or expected number) of occurrences per interval k – a non-negative integer ( 0 , 1 , 2 , … ) representing the number of occurrences \textbf{Symbol Meanings:} \\ \begin{array}{ll}X & \text{-- the random variable representing the number of events in a given interval} \\[6pt]\lambda & \text{-- the average rate (or expected number) of occurrences per interval} \\[6pt]k & \text{-- a non-negative integer (} 0,\,1,\,2,\,\dots \text{) representing the number of occurrences}\end{array} Symbol Meanings: X λ k – the random variable representing the number of events in a given interval – the average rate (or expected number) of occurrences per interval – a non-negative integer ( 0 , 1 , 2 , … ) representing the number of occurrences X - 주어진 시간 구간 사이에서의 사건 발생 횟수를 나타내는 확률변수
λ \lambda λ
k k k
→ 해석 λ \lambda λ
stationary increments
정상성 → 시간에 따라 분포는 바뀌지 않고 유지된다
independent increments
독립성 → 어떤 시간 구간에서든지의 발생횟수는 다른 구간에 대해 독립임
되게 직관적으로 이해가 잘 안된다
내가 오기 직전에 버스가 왔다는 사실이 크게 상관이 없다는거지?
N 7 − N 2 = N 5 N_7 - N_2=N_5 N 7 − N 2 = N 5
N 7 − N 2 , N 5 N_7 - N_2, N_5 N 7 − N 2 , N 5
분포수렴과 확률 수렴의 차이와 같게 볼 수 있다.
Translated 포아송 과정
N t = N t + s − N s , t ≥ 0 N_t = N_{t+s} - N_s, \quad t ≥ 0 N t = N t + s − N s , t ≥ 0
6.2 Arrival & Arrival time interval
도착시간은 지수분포를 따름. 지수분포와 포아송분포 간의 관계
Poisson def2
시간 관점으로 접근 →
N t N_t N t
X 1 , X 2 … X_1, \ X_2\ \dots X 1 , X 2 …
카운팅 프로세스를 새롭게 정의함.
N t = max { n : X 1 + ⋯ + X n ≤ t } , N_t = \max \{ n : X_1 + \cdots + X_n \leq t \}, N t = max { n : X 1 + ⋯ + X n ≤ t } , S n = X 1 + ⋯ + X n , for n = 1 , 2 , … S_n = X_1 + \cdots + X_n, \quad \text{for } n = 1, 2, \ldots S n = X 1 + ⋯ + X n , for n = 1 , 2 , … 무기억성- Memorylessness
P ( Z > t ) = P ( A > t + 10 ∣ A > 10 ) = P ( A > t + 10 ) P ( A > 10 ) = e − ( t + 10 ) / 30 e − 10 / 30 = e − t / 30 = P ( A > t ) P(Z > t) = P(A > t + 10 | A > 10) = \frac{P(A > t + 10)}{P(A > 10)} = \frac{e^{-(t + 10)/30}}{e^{-10/30}} = e^{-t/30} = P(A > t) P ( Z > t ) = P ( A > t + 1 0 ∣ A > 1 0 ) = P ( A > 1 0 ) P ( A > t + 1 0 ) = e − 1 0 / 3 0 e − ( t + 1 0 ) / 3 0 = e − t / 3 0 = P ( A > t ) Minimum of Independent Exponential Random Variable
지수분포 RV의 최솟값 M 최소 시간간격
M의 분포를 구할 수 있음
Arrival Times and Gamma Distributions
도착 시간과 감마분포
도착시간 S n S_n S n
일반적으로 포아송 과정을 완전히 무작위적인 사건 또는 점의 분포로 생각하는 것이 일반적입니다.
[0, ∞) 또는 어떤 무한 구간에서 균일한 분포를 가질 수는 없지만, 포아송 과정과 균일 분포 사이에는 강한 관련이 있습니다.
포아송 과정이 구간 [0, t]에 정확히 n 개의 사건을 포함하고 있다면, 그 사건의 비순서적 위치 또는 시간은 해당 구간에서 균일하게 분포
증명
P ( S 1 ≤ s ∣ N t = 1 ) = P ( S 1 ≤ s , N t = 1 ) P ( N t = 1 ) = P ( N s = 1 , N t = 1 ) P ( N t = 1 ) = P ( N s = 1 , N t − N s = 0 ) P ( N t = 1 ) = P ( N s = 1 ) P ( N t − s = 0 ) P ( N t = 1 ) = e − λ s λ s e − λ ( t − s ) e − μ t μ t = s t , P(S_1 \leq s | N_t = 1) = \frac{P(S_1 \leq s, N_t = 1)}{P(N_t = 1)} = \frac{P(N_s = 1, N_t = 1)}{P(N_t = 1)} = \frac{P(N_s = 1, N_t - N_s = 0)}{P(N_t = 1)} = \frac{P(N_s = 1)P(N_t - s = 0)}{P(N_t = 1)} = \frac{e^{-\lambda_s} \lambda_s e^{-\lambda(t-s)}}{e^{-\mu t} \mu t} = \frac{s}{t}, P ( S 1 ≤ s ∣ N t = 1 ) = P ( N t = 1 ) P ( S 1 ≤ s , N t = 1 ) = P ( N t = 1 ) P ( N s = 1 , N t = 1 ) = P ( N t = 1 ) P ( N s = 1 , N t − N s = 0 ) = P ( N t = 1 ) P ( N s = 1 ) P ( N t − s = 0 ) = e − μ t μ t e − λ s λ s e − λ ( t − s ) = t s , 이는 [0, t] 구간의 균등 분포의 누적 분포 함수입니다.
which is the cumulative distribution function of the uniform distribution on [0, t].
설명
도착 시간 (Arrival Times) : 포아송 과정에서의 도착 시간은 이벤트가 발생하는 시간을 의미합니다. 예를 들어, 문 앞에 도착하는 고객들의 도착 시간인 S_1, S_2, \ldots 를 생각할 수 있습니다. 이 도착 시간은 포아송 과정의 매개변수 \lambda 에 따라 결정됩니다.균일 분포 (Uniform Distribution) : 포아송 과정에서 특정 시간 간격 [0, t] 내에 n 개의 이벤트가 발생할 때, 이 이벤트의 도착 시간 (S_1, S_2, \ldots, S_n) 은 무작위로 균일하게 발생. 이것은 특정 구간 안에서 발생한 여러 사건들이 균등한 확률로 발생한다는 뜻.관계 :
N t = n N_t = n N t = n
도착 시간 S 1 , S 2 , … , S n S_1, S_2, \ldots, S_n S 1 , S 2 , … , S n
f ( s 1 , … , s n ) = n ! t n for 0 < s 1 < … < s n < t f(s_1, \ldots, s_n) = \frac{n!}{t^n} \quad \text{for } 0 < s_1 < \ldots < s_n < t f ( s 1 , … , s n ) = t n n ! for 0 < s 1 < … < s n < t
이는 각 도착 시간이 균일 분포를 따른다는 것을 나타내며, $$ S_1, S 2 , S_2 , S 2
P ( S 1 ≤ s ∣ N t = 1 ) P(S_1 \leq s | N_t = 1) P ( S 1 ≤ s ∣ N t = 1 ) = P ( S 1 ≤ s , N t = 1 ) P ( N t = 1 ) = P ( N s = 1 , N t = 1 ) P ( N t = 1 ) = \frac{P(S_1 \leq s, N_t = 1)}{P(N_t = 1)} = \frac{P(N_s = 1, N_t = 1)}{P(N_t = 1)} = P ( N t = 1 ) P ( S 1 ≤ s , N t = 1 ) = P ( N t = 1 ) P ( N s = 1 , N t = 1 ) = P ( N s = 1 , N t − N s = 0 ) P ( N t = 1 ) = P ( N s = 1 ) P ( N t − s = 0 ) P ( N t = 1 ) = \frac{P(N_s = 1, N_t - N_s = 0)}{P(N_t = 1)} = \frac{P(N_s = 1) P(N_{t-s} = 0)}{P(N_t = 1)} = P ( N t = 1 ) P ( N s = 1 , N t − N s = 0 ) = P ( N t = 1 ) P ( N s = 1 ) P ( N t − s = 0 ) = e − λ s λ s e − λ ( t − s ) e − λ t λ t = s t = \frac{e^{-\lambda s} \lambda s e^{-\lambda (t-s)}}{e^{-\lambda t} \lambda t} = \frac{s}{t} = e − λ t λ t e − λ s λ s e − λ ( t − s ) = t s 포아송에서 각 도착시간이 uniform을 따른다 증명
P ( s 1 ≤ S 1 ≤ s 1 + ϵ 1 , … , s n ≤ S n ≤ s n + ϵ n ∣ N t = n ) P(s_1 \leq S_1 \leq s_1 + \epsilon_1, \ldots, s_n \leq S_n \leq s_n + \epsilon_n | N_t = n) P ( s 1 ≤ S 1 ≤ s 1 + ϵ 1 , … , s n ≤ S n ≤ s n + ϵ n ∣ N t = n ) 6.6 Spatial Poisson Process
📌
2 이상의 고차원 space 에서 events 나 points 의 distribution을 모델링
특정 시간 내에 → event n번 발생할 확률
특정 영역 내에 → event n번 발생할 확률
📌
Notation
A ⊆ R d A \subseteq \mathbb{R}^d A ⊆ R d ( d ≥ 1 (d≥1 ( d ≥ 1
N A N_A N A
∣ A ∣ |A| ∣ A ∣
정의
모든 bounded setA ⊆ R d A ⊆ ℝ_d A ⊆ R d N A N_A N A λ ∣ A ∣ \lambda|A| λ ∣ A ∣
사건 발생 rate(면적당 발생 rate) * 면적
같은 시간 간격 - 같은 rate → 같은 면적 - 같은 rate : stationary increment
항상 A와 B 가 disjoint set 이면 N A N_A N A N B N_B N B
겹치지 않는 시간 → event 독립 → 겹치지 않는 공간 - event 독립 : indep increment
→→ 두 조건을 만족하면
( N A ) A ⊆ R d (N_A)_{A⊆ℝd} ( N A ) A ⊆ R d λ \lambda λ
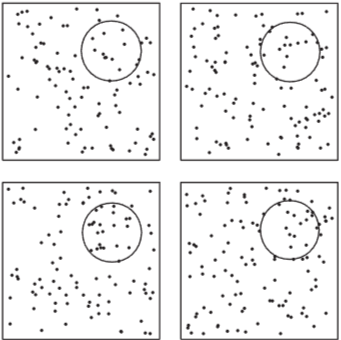
Example 6.11
A spatial Poisson process in the plane has parameter λ \lambda λ
→ param 이 1/2 인 공간 포아송 과정에서, 중심이 3,4이고 반지름이 2 인 원 안에 점이 5개 있을 확률을 구하시오
∣ C ∣ = 4 π |C| = 4\pi ∣ C ∣ = 4 π
P ( N C = 5 ) = e − ∣ C ∣ ∣ C ∣ 5 5 ! = e − 2 ( 2 ) 5 5 ! = 0.152. P(N_C = 5) = \frac{e^{-|C|} |C|^5}{5!} = \frac{e^{-2}(2)^5}{5!} = 0.152. P ( N C = 5 ) = 5 ! e − ∣ C ∣ ∣ C ∣ 5 = 5 ! e − 2 ( 2 ) 5 = 0 . 1 5 2 .
Uniform distribution 의 2차원 적용, → 시간 축 내에서 event 발생이 uniform을 따르는 것 처럼,
n개의 point가 있다는 가정 하에 n 개의 점은 A내에서 균일하게 분포
→ Complete Spatial Randomness 모델이라 불림
lambda = 100, r = 0.2, 10만회 시뮬레이션 → 각 시뮬 별 원 내에 count 수 모음
→ 10만번중 52058번은 10~14개의 point가 원 내에 있음
import numpy as np
lambda_val = 100
square_area = 1
trials = 100000
sim_list = np. zeros( trials)
for i in range ( trials) :
N = np. random. poisson( lambda_val * square_area)
x_points = np. random. uniform( 0 , 1 , N)
y_points = np. random. uniform( 0 , 1 , N)
ct = np. sum ( ( np. square( x_points - 0.7 ) + np. square( y_points - 0.7 ) ) <= np. square( 0.2 ) )
sim_list[ i] = ct
print ( f"Mean: { np. mean( sim_list) } " )
print ( f"Variance: { np. var( sim_list) } " )
theoretical_mean = lambda_val * np. pi * np. square( 0.2 )
print ( f"Theoretical Mean: { theoretical_mean} " ) spatial poisson process가 이론적 값과 비슷한 시뮬레이션 결과를 유지 →
포아송 과정으로 모델링하면 공간 내에 점이 1,2,3.. 개 인 확률을 모두 구할 수 있음
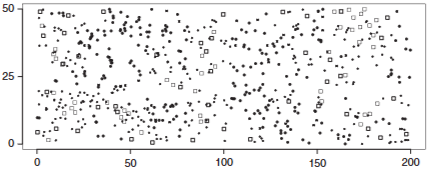
Point process
공간 포아송 과정은 Point process의 특별한 경우
📌
Complete spatial randomness 와 얼마나 다른지를 spatial poisson 으로 측정할 수 있음
→나와 가장 가까운 거리의 기댓값, 분산 구하기
measure : nearest neighbor distance : 한 점에서 가장 가까운 다른 점 까지의 거리
두 점 사이의 거리 D 가 특정 값 t 보다 크다는 사건 {D > t} 는 x 주위에 반지름 t 의 원내에 점이 존재하지 않는 경우
📌
Notation
x x x
D D D x x x
λ \lambda λ
t : 기준 거리
P ( D > t ) = P ( N C x = 0 ) = e − λ ∣ C x ∣ = e − λ π t 2 P(D > t) = P(N_{C_x} = 0) = e^{-\lambda |C_x|} = e^{-\lambda \pi t^2} P ( D > t ) = P ( N C x = 0 ) = e − λ ∣ C x ∣ = e − λ π t 2 D가 t보다 클 확률은, x 주위에 반지름 t인 원 내에 event가 0이라는 뜻
가장 가까운 거리 D에 대한 pdf
f D ( t ) = e − λ k t 2 2 π t , for t > 0 , f D ( 0 ) = e − λ k ( 0 ) 2 2 π ( 0 ) , for t > 0 , f_D(t) = e^{-\lambda kt^2} 2\pi t, \quad \text{for } t > 0,\quad f_D(0) = e^{-\lambda k(0)^2} 2\pi(0), \quad \text{for } t > 0, f D ( t ) = e − λ k t 2 2 π t , for t > 0 , f D ( 0 ) = e − λ k ( 0 ) 2 2 π ( 0 ) , for t > 0 , E ( D ) = 1 2 λ and V a r ( D ) = 4 − π 4 π λ . E(D) = \frac{1}{2\sqrt{\lambda}} \quad \text{and} \quad Var(D) = \frac{4 - \pi}{4\pi \lambda}. E ( D ) = 2 λ 1 and V a r ( D ) = 4 π λ 4 − π . Example 6.12
특정 거리 t 이상 떨어져 있는 이웃 점들이 얼마나 흔하지 않은지를 나타냄
E ( D ) = 1 2 630 10000 = 1.992 m , E(D) = \frac{1}{2 \sqrt{\frac{630}{10000}}} = 1.992 \, \text{m}, E ( D ) = 2 1 0 0 0 0 6 3 0 1 = 1 . 9 9 2 m , S D ( D ) n = 4 − 4 π 630 10000 630 = 0.041. \frac{SD(D)}{\sqrt{n}} = \sqrt{\frac{4 - \frac{4\pi630}{10000}}{\sqrt{630}}} = 0.041. n S D ( D ) = 6 3 0 4 − 1 0 0 0 0 4 π 6 3 0 = 0 . 0 4 1 . 6.7 NONHOMOGENEOUS POISSON PROCESS
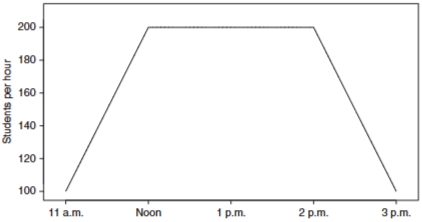
비균질 포아송 과정 - 항상 일정한 rate으로 도착한다는 가정은 비현실적
→ 맛나샘 → 1시에 rate이 피크를 찍고, 11시와 2시 rate은 더 낮음
E ( N t ) = ∫ 0 t λ ( x ) d x . E(N_t) = \int_0^t \lambda(x) \, dx. E ( N t ) = ∫ 0 t λ ( x ) d x . lambda가 일정하지 않고, 모든 t에 대해 poisson process의 mean이 위 식을 따름.
For 0 ≤ q < r ≤ s < t , N r − N q a n d N t − N s 0 ≤ q < r ≤ s < t, Nr − Nq and Nt − Ns 0 ≤ q < r ≤ s < t , N r − N q a n d N t − N s
λ ( t ) = { 100 + 100 t , 0 ≤ t ≤ 1 200 , 1 < t ≤ 3 500 − 100 t , 3 ≤ t < 4 \lambda(t) = \begin{cases} 100 + 100t, & 0 \leq t \leq 1 \\ 200, & 1 < t \leq 3 \\ 500 - 100t, & 3 \leq t < 4 \end{cases} λ ( t ) = ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ 1 0 0 + 1 0 0 t , 2 0 0 , 5 0 0 − 1 0 0 t , 0 ≤ t ≤ 1 1 < t ≤ 3 3 ≤ t < 4
6.8 Parting Paradox
버스는 포아송 프로세스에 따라 버스 정류장에 도착하고, 버스 간의 평균 시간은 10분
A가 시간 t 에 버스 정류장에 도착했을 때 버스를 기다릴 것으로 예상되는 시간은 얼마?
지수분포대로 10분 기다리냐 vs 아니면 연속된 버스 도착 사이에 도착하니 기댓값의 절반인 5분이 되어야 하냐
결론, 지수분포대로 10분 기다리고, A의 앞뒤 버스 도착 시간 차이가 20분이기 때문에 그 절반인 10분 기다림
📌
대기시간 역설
λ = 1 10 \lambda=\frac{1}{10} λ = 1 0 1
[ 0 , 200 ] [0,200] [ 0 , 2 0 0 ]
→ 평균 대기시간 10분
→ 리사가 도착했을 때 전후 버스시간 간격은 20분 (하지만 그래도 평균 시간간격은 10분)
→ 편향 샘플링 length-biased or size-biased sampling.
랜덤하게 도착 시간을 선택하면, 시간간격이 긴 시간 interval 사이에 놓일 확률이 높다.
애초에 긴 시간 간격 사이에 놓일 확률이 높은 상태로 뽑혔기 때문에, 전체 평균 대기시간이 10분일지라도, 어떤 한 점을 짚었을 때 대기시간은 길어진다.
리사가 도착했을 때, 리사 도착 앞뒤로 도착한 버스 사이의 간격은 20분이다.
대기시간 역설 증명
📌
S N t S_{N_t} S N t
S N t + 1 S_{N_t+1} S N t + 1 N t N_t N t
E ( S N t + 1 − S N t ) = E ( S N t + 1 ) − E ( S N t ) . E(S_{N_t+1} - S_{N_t}) = E(S_{N_t+1}) - E(S_{N_t}) . E ( S N t + 1 − S N t ) = E ( S N t + 1 ) − E ( S N t ) . E ( S N t ) = t − 1 λ + e − λ t λ . E(S_{N_t}) = t - \frac{1}{\lambda} + \frac{e^{-\lambda t}}{\lambda}. E ( S N t ) = t − λ 1 + λ e − λ t . E ( S N t + 1 − S N t ) = ( t + 1 λ ) − ( t − 1 λ + e − λ t ) = 2 − e − λ t λ ≈ 2 λ E(S_{N_{t+1}} - S_{N_t}) = \left( t + \frac{1}{\lambda} \right) - \left( t - \frac{1}{\lambda} + e^{-\lambda t} \right) = \frac{2 - e^{-\lambda t}}{\lambda} \approx \frac{2}{\lambda} E ( S N t + 1 − S N t ) = ( t + λ 1 ) − ( t − λ 1 + e − λ t ) = λ 2 − e − λ t ≈ λ 2 특정 시점 t 기준 앞뒤 도착시간은 평균 도착시간의 약 2배