이번에는 원래의 constraint 자체가 second-order cone 형태로 주어진 robust SOCP에 대해 알아보자. SOCP의 목적함수는 LP와 동일하며, constraint는 일반적으로 다음과 같이 주어진다. A의 각 행벡터를 ai∈Rn이라 하자.
∣∣Ax+b∣∣2≤cTx+d, whereA∈Rm×n,b∈Rm,c∈Rn,d∈R
SOCPs with interval uncertainty
가장 간단하게 생각할 수 있는 uncertainty set은 행렬 A에 원소 크기가 δ로 제한된 Δ가 더해진 형태이다. 이를 수식으로 나타내면 아래와 같다. 이전에 LP에 conic uncertainty를 더하면 SOCP로 변환됨을 확인했기 때문에, 우변에 다음과 같이 자유롭게 더할 수 있다.
∣∣(A+Δ)x+b∣∣2≤(c+u)Tx+d for allΔs.t.∣∣Δ∣∣∞≤δ, u∈U={u:Fu+g⪰K0}
이때 좌변과 우변을 t≥0에 대해 ∣∣(A+Δ)x+b∣∣2≤t와 t≤(c+u)Tx+d로 분리해 생각하자. 그러면 우변은 이전과 동일하게 t≤cTx+d−λTg,FTλ+x=0,λ⪰K∗0의 세 부등식으로 나타난다. 좌변은 계산을 통해 확인해 보자. sup∣∣(A+Δ)x+b∣∣2=sup(∑i=1m[(ai+Δi)Tx+bi]2)1/2=sup{∣∣z∣∣2∣zi=aiTx+ΔiTx+bi,∣∣Δi∣∣∞≤δ}=inf{∣∣z∣∣2∣zi≥∣aiTx+bi∣+δ∣∣x∣∣1}
따라서 처음의 무한 가지 경우의 수가 있는 부등식은, 아래의 m+3개의 부등식으로 축약된다.
이번엔 Δ의 l2-induced norm으로 주어진 형태의 uncertainty set에 대해 살펴보자. l2-induced norm은 ∣∣Δ∣∣=sup∣∣u∣∣2=∣∣v∣∣2=1uTΔv로 정의되며, A의 maximum singular value와 같다. 이런 경우에는 좀 더 복잡한 증명이 필요하다. P∈Rm×n, Δ∈Rn×n에 대해 matrix uncertainty를 반영한 inequality는 아래와 같다.
∣∣(A+PΔ)x+b∣∣2≤t,∣∣Δ∣∣≤δ
이제 다음 두 사실을 이용해 이 부등식을 풀 수 있는 형태로 만들어 보자. 증명은 생략하겠다.
Schur complement를 이용해 이 부등식을 [t(A+PΔ)x+b((A+PΔ)x+b)TtIm]⪰0,∣∣Δ∣∣≤1
로 바꿀 수 있다. 이는 임의의 스칼라 s∈R과 벡터 v∈Rm에 대해 ts2+2s((A+PΔ)x+b)Tv+t∣∣v∣∣22≥0임과 동치이다.
이 식에서 ∣∣Δ∣∣≤1에 대해 infimum을 취하면 결국 ts2+2s(Ax+b)Tv+t∣∣v∣∣22−2∣∣sx∣∣2∣∣PTv∣∣2≥0과 같다.
이때 sup{uTx∣∣∣u∣∣22≤∣∣PTv∣∣22}=∣∣PTv∣∣2∣∣x∣∣2임을 이용해, 이 부등식을 ts2+2s(Ax+b)Tv+t∣∣v∣∣22+2suTx≥0 for all∣∣u∣∣22≤∣∣PTv∣∣22
로 나타낸 뒤, 행렬 형태로 나타내면
⎣⎢⎡svu⎦⎥⎤T⎣⎢⎡0000PPT000−In⎦⎥⎤⎣⎢⎡svu⎦⎥⎤⪰0→⎣⎢⎡svu⎦⎥⎤T⎣⎢⎡tAx+bx(Ax+b)Tt0xT00⎦⎥⎤⎣⎢⎡svu⎦⎥⎤⪰0
그리고 S-lemma를 이용하면, 최종적으로 matrix uncertainty inequality는 다음을 만족하는 x∈Rn,λ를 찾는 문제와 같다.
⎣⎢⎡tAx+bx(Ax+b)Tt−λPPT0xT0λIn⎦⎥⎤⪰0
Example: robust regression
예시를 통해 위에서 살펴본 이론을 적용해 보자. Regression problem은 우리가 잘 알고 있듯, 주어진 데이터를 잘 설명하는 직선의 계수를 찾는 문제로 데이터 행렬 A∈Rm×n,b∈Rm가 주어져 있을 때 ∣∣Ax−b∣∣2를 최소화하는 x∈Rn을 찾는 것이 목표이다. 이때 데이터 자체에 오염이 발생했다고 하고, 그 오염은 Δ∈Rm×n이 A에 더해진 형태로 나타난다. 이때 Δ의 범위를 위의 세 경우와 같이 분류해 보자. 즉 ∣Δij∣ 또는∣∣Δi∣∣2 또는 ∣∣Δ∣∣가 높은 확률로 제한된 경우이다. Δ를 어떤 확률 분포를 따르는 random noise라고 하면 이 가정은 현실적임을 알 수 있다. 가령 gaussian noise의 경우 noise의 범위가 평균(0)에서 그리 멀지 않은 부분에 집중될 것이기 때문이다.
다음 theorem을 이용해 Δ에 관한 probability bound를 도출해 보자.
Theorem. t≥0에 대해
1. P(∣Δij∣≥t)≤2exp(−2t2)
2. P(∣∣Δi∣∣2≥n+t)≤exp(−2t2)
3. P(∣∣Δi∣∣≥m+n+t)≤exp(−2t2)
이를 이용해 각각 t∞2(δ)=2log(2mn/δ),t22(δ)=2log(m/δ),top2(δ)=2logδ1로 설정하면 위의 upper bound가 δ가 되도록 조정할 수 있다. 따라서 uncertainty set의 bound를 각각 위의 세 값으로 설정하면 각각 다른 robust least squares solution을 얻을 수 있다.
mport cvxpy as cp
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(1)
# Generate data
m = 50
n = 20
A = 10 * np.random.randn(m, n)
u = np.random.randn(n)
u = u / np.linalg.norm(u)
b = A @ u + np.random.randn(m)
# Probabilities of exceeding the bounds on robustness
num_deltas = 23
deltas = np.logspace(-11, -1, num_deltas)
x_inf_sols = np.zeros((n, num_deltas))
x_2_sols = np.zeros((n, num_deltas))
x_op_sols = np.zeros((n, num_deltas))
nom_vals_inf = np.zeros(num_deltas)
nom_vals_2 = np.zeros(num_deltas)
nom_vals_op = np.zeros(num_deltas)
for ind, delta in enumerate(deltas):
t_op = np.sqrt(n) + np.sqrt(m) + np.sqrt(2 * np.log(1 / delta))
t_2 = np.sqrt(n) + np.sqrt(2 * np.log(m / delta))
t_inf = np.sqrt(2 * np.log(2 * m * n / delta))
print(f"Solving iteration {ind+1} of {num_deltas} with delta = {delta}")
# First with infinity norm-bounded perturbations
x_inf = cp.Variable(n)
z_inf = cp.Variable(m)
objective_inf = cp.Minimize(cp.norm(z_inf, 2))
constraints_inf = [z_inf[i] >= cp.abs(A[i, :] @ x_inf - b[i]) + t_inf * cp.norm(x_inf, 1) for i in range(m)]
problem_inf = cp.Problem(objective_inf, constraints_inf)
problem_inf.solve(solver=cp.ECOS, max_iters=1000, verbose=False)
x_inf_sols[:, ind] = x_inf.value
# Now with ellipsoid (l2) perturbations
x_2 = cp.Variable(n)
z_2 = cp.Variable(m)
objective_2 = cp.Minimize(cp.norm(z_2, 2))
constraints_2 = [z_2[i] >= cp.abs(A[i, :] @ x_2 - b[i]) + t_2 * cp.norm(x_2, 2) for i in range(m)]
problem_2 = cp.Problem(objective_2, constraints_2)
problem_2.solve(solver=cp.ECOS, max_iters=1000, verbose=False)
x_2_sols[:, ind] = x_2.value
# Now with the operator norm perturbation
x_op = cp.Variable(n)
objective_op = cp.Minimize(cp.norm(A @ x_op - b, 2) + t_op * cp.norm(x_op, 2))
problem_op = cp.Problem(objective_op)
problem_op.solve(solver=cp.ECOS, max_iters=1000, verbose=False)
x_op_sols[:, ind] = x_op.value
for ind, delta in enumerate(deltas):
nom_vals_inf[ind] = np.linalg.norm(A @ x_inf_sols[:, ind] - b, 2)
nom_vals_2[ind] = np.linalg.norm(A @ x_2_sols[:, ind] - b, 2)
nom_vals_op[ind] = np.linalg.norm(A @ x_op_sols[:, ind] - b, 2)
x_nominal = np.linalg.lstsq(A, b, rcond=None)[0]
nominal_value = np.linalg.norm(A @ x_nominal - b)
# ... Additional code for Monte Carlo simulations and plotting ...
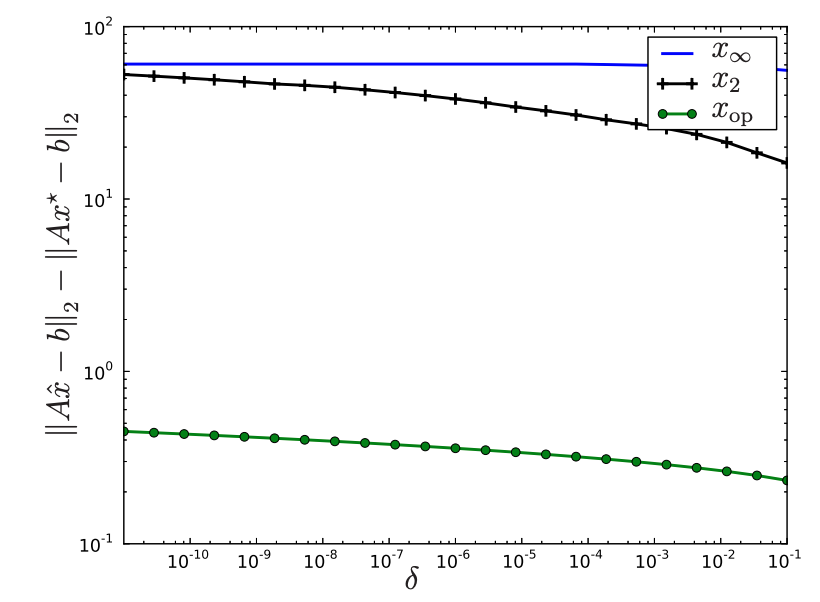
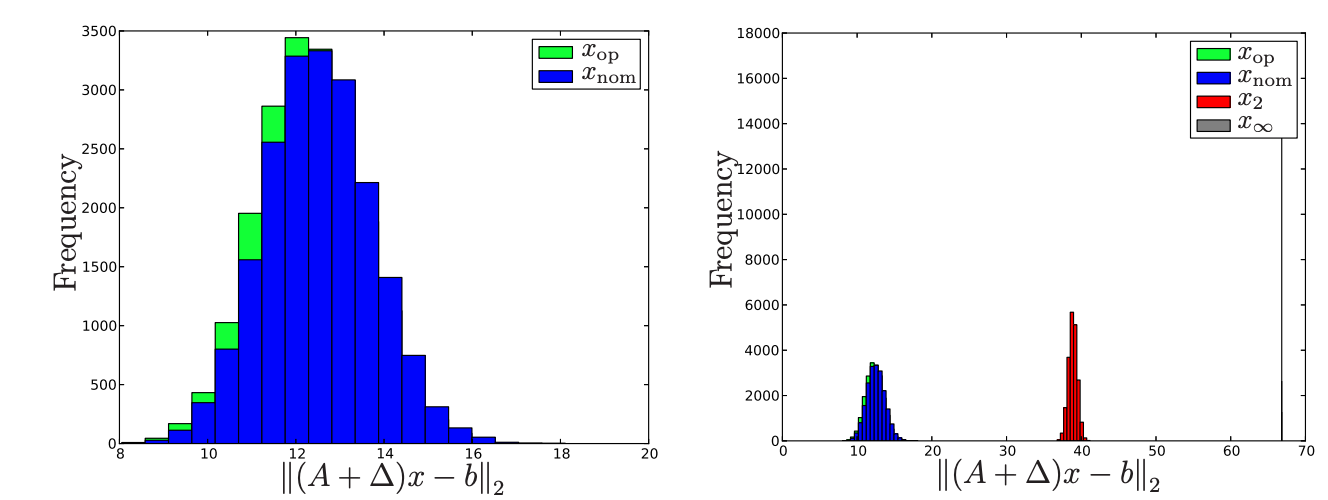
위의 코드를 통해 각각의 상황을 시뮬레이션할 수 있다. 결과는 아래와 같다.
x∗는 uncertainty를 반영하지 않은 least squares solution. operator norm을 사용한 xop 외의 다른 솔루션은 결과가 좋지 않다.
이전과 동일하게 x∞,x2는 작은 분산을 가진 대신 나쁜 결과를 보임을 monte carlo simulation을 통해 확인할 수 있다.