논문 : https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
이미지 인식 대회의 2012년도 우승 결과.
에러 17%인데, 2등과 10% 가량 차이가 에러율이 차이가 나면서 화제가 됨.
이 대회 이후, AlexNet의 정답률 85%를 찍으면서 이때부터 딥러닝의 시대가 열림.
1. Overall Architecture
- GPU 2대를 병렬처리하여 사용.
- 총 8개의 레이어 (5개의 convolutionary layer, 3개의 fully-connected layer)
- softmax를 이용해서 마지막에 1000가지의 class가 나옴.
- Activation funtion : ReLU를 사용.
- Normalization(정규화)로 Local Response 사용
- Overlapping Pooling을 도입
- Data Augmentation, DropOut 사용
2. Dataset
- 1000개의 이미지 카테고리
- 2010년도의 test set이 다 라벨링 되어있어서 그거 사용.
- 120만개의 train set, 50000개의 validation set, 150,000개의 test set 사용
- 전처리 :
이미지의 모든 사이즈를 256x256으로 맞춤
즉, resize and crop 말고는 따로 전처리를 한 것은 없음.
3. Architecture
(기여를 많이 한 순으로 소개)
1. ReLU 활성 함수(activation function) 사용
2. GPU 2대를 사용한 것.
3. Local Response Normlization
4. Overlapping Pooling
3-1. ReLU Nonlinearity
이전까지는, activation function으로 tanh나 sigmoid같은 활성함수가 주로 사용되었음.
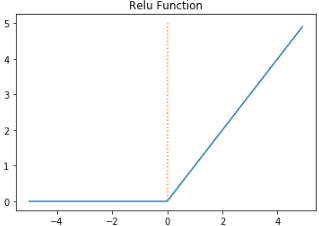
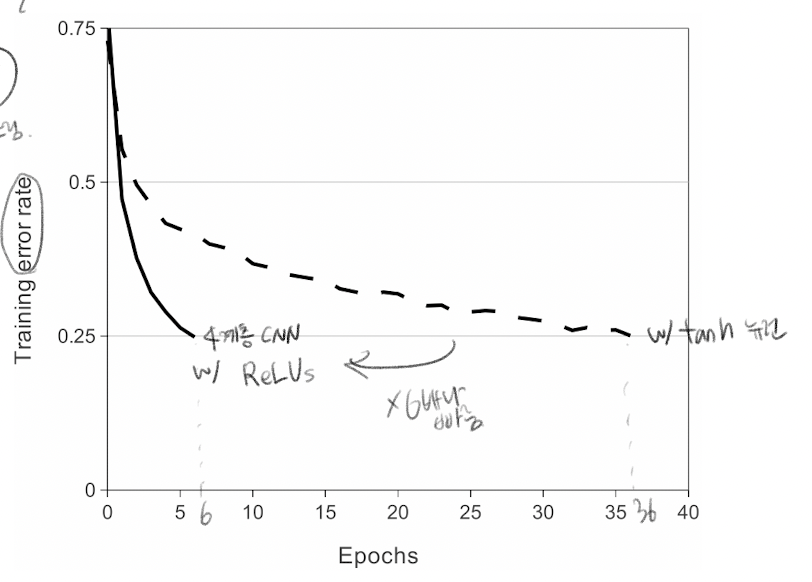
ReLU를 사용해서, Tanh와 비교해서 accuracy가 75%가 되기 위해 6 epoch만에 도달했고, Tanh는 36번만에 도달함. 따라서 약 6배 빠르게 수렴한 것.
3-2. Training on Multiple GPUs
GPU 2대 사용.
12,000장의 더 많은 데이터를 돌릴 수 없어서, 메모리가 부족해서 GPU 2대를 병렬해서 사용함.
특정 레이어에서만 GPU에 상관없이 모든 커널을 가져다 쓸 수 있게 additional trick을 사용.
따라서 1,2,4,5 번째 convolutional layer에서는 같은 GPU 내의 kernel만 사용할 수 있고,
3번째 convolutional layer와 3개의 fully-connected layer에서는 모든 kernel을 사용할 수 있음.
-> 이를 통해 top1 error는 1.7%, top5 error는 1.2% 정도 감소시킴.
3-3. Local Response Normalization
실제 뇌세포의 증상으로, 강한 뉴런의 활성화가 근처 다른 뉴런의 활동을 억제시키는 현상이 존재함.
여기에 영감을 받아서 이 Local Response Normalization(LRN)을 사용함.
예로, 주변이 다 1인데 가운데만 10인 상황. 이런 경우에 전체적으로 값이 좀 높게 뛰는 등 이렇게 특정 값에 의해 과대 적합이 되는 것을 방지하기 위해 LRN을 사용함.
공식 :
-> top1 error는 1.4%, top5 error는 1.2% 정도 감소시킴.
3-4. Overlapping Pooling
원래의 traditional pooling은, Pooling window랑 stride의 크기가 같아서 겹치지 않게 줄였는데,
Overlapping Pooling은 Pooling window > stride의 크기로 해서, 겹치게 구현함.
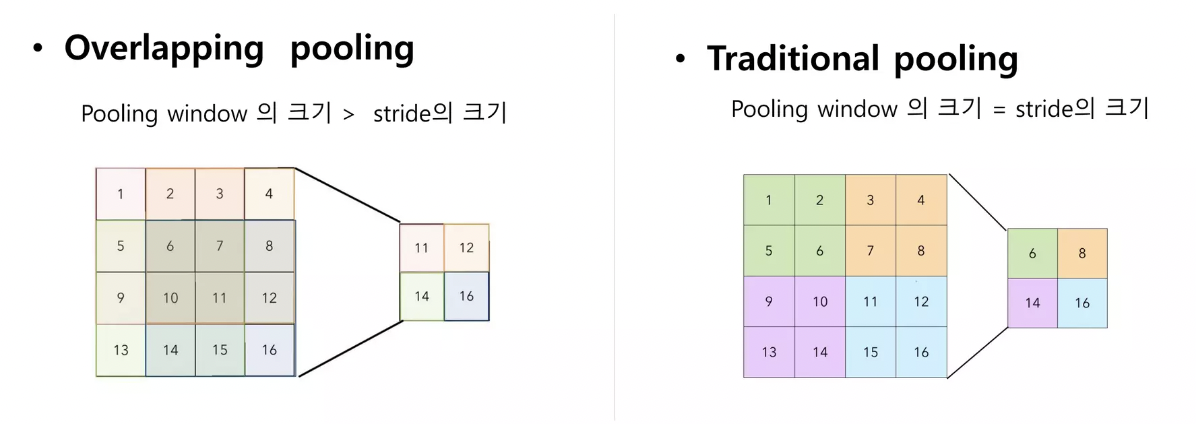
-> traditional pooling과 output size는 같으나, Overfitting(과대 적합)이 덜 되고
-> top1 error는 0.4%, top5 error는 0.3% 정도 감소시킴.
4. Reducing Overfitting
CNN 같은 Neural Network에서 가장 문제되는게, 파라미터가 너무 많아지는 것.
파라미터가 너무 많아지면 overfitting이 될 수 있는데,
그래서 Overfitting을 어떻게 줄였는지에 대한 설명.
1. Data Augmentation
2. DropOut
을 통해 Overfitting을 감소시킴.
4-1-1. Data Augmentation
Image Translation과 horizontal reflection(좌우 반전)을 사용
먼저는 이미지가 그냥 한 개인데, 좌우 반전을 하면 이미지가 2개로 늘어남 (좌우 반전을 한 애가 추가되는 거니까)
다음,
256x256 이미지를 랜덤으로 잘라서 224x224 패치로 만듦.
그래서 1024배가 증가함. 움직일 수 있는게 좌우, 상하로 각각 32개가 있으니까.
그리고 여기에 좌우반전까지 해주면
1024 * 2 해서 총 2048배가 증가함.
4-1-2. Jittering
색깔을 변화시키는 것. RGB 픽셀 값을 (3x3 공분산) 에서 아래 공식에 따라 모든 픽셀에 값을 더해 줌,
4-2. DropOut
0.5의 확률로 hidden neuron의 값을 0으로 바꿔줌으로써 dropout된 뉴런은 forward, backpropagation 시 영향을 미치지 않게 됨.
논문에서는 3개의 fully-connected layer 중 앞의 두 개에만 Dropout을 적용하고, 테스트 시에는 dropout 대신 그냥 결과물에 0.5를 곱해줌.
5. Details of Learning
- stochastic gradient descent 활용
- batch size = 128
- momentum = 0.9
- weight decay = 0.0005
- Learning rate = 0.01
- Epochs = 90
- 2개의 NVIDIA GTX 580 3GB GPU를 사용했을 때, 5-6일 정도 소요.
6. Results
6-1. Qualitative Evaluations
GPU1은 색감과 관련 없는 것, GPU2는 색감과 관련 있는 것으로 feature을 뽑아냄. (특징 추출을 함)
top 5 error가 나온 사진들(왼쪽):

-> 이런 에러가 나올 수 밖에 없었던 것을 설명함.
참고:
https://youtu.be/40Gdctb55BY
https://www.youtube.com/watch?v=5i2xG4WqR7c&t=14s
https://www.slideshare.net/ssuser67be14/alexnet-paper-review
