0강. 딥러닝/머신러닝 개요
구글 번역
TtS engine (Text to Speech) -> 딥러닝 적용해서 실제 사람처럼 말하게 함.
자기가 혼자 코드를 짜는 AI(MS AI) -> 손 디자인 올리면 이걸 알아서 HTML로 만들어줌.
Adobe
- 사진이 보정됐는지 안 됐는지 판단해주는 AI
다 딥러닝으로 제작한 AI.
머신러닝은 어느정도의 가이드라인을 줘야함.
가이드라인도 컴퓨터가 알아서 찾는 방식이 딥러닝.
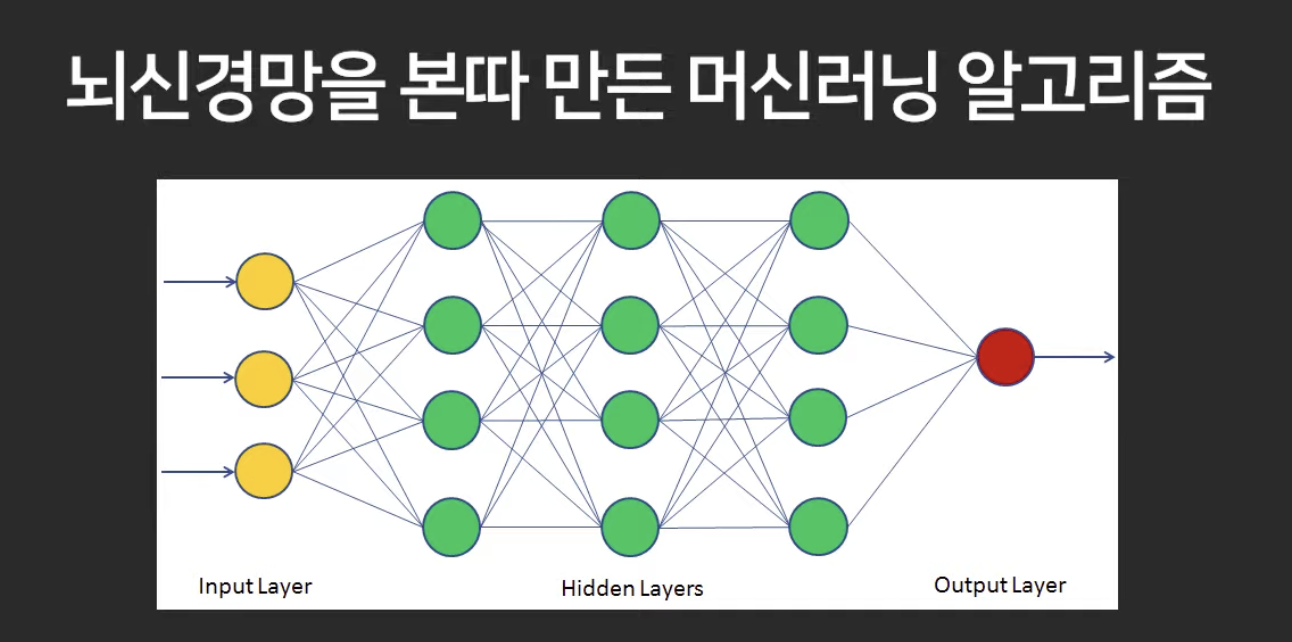
뉴럴 네트워크(신경망)를 이용해 머신러닝을 진행하는것이 딥러닝.

1강. 머신러닝 기초 개념
머신러닝 : 기계에게 학습시키기.
ex.) 사진을 보고 사람인지 아닌지 판단하는 알고리즘
그 알고리즘 사람이 가이드 줄 수도 있지만, 이 알고리즘을 기계가 스스로 학습하도록 만들면 그게 머신러닝.
수많은 사람 사진을 보여주면서 알아서 판단하라고.
기계가 스팸메일 몇만개 검토하며 어떤 제목이 스팸메일일 확률이 높은지 알아서 검토함.
이 등의 문제들을 머신러닝으로 풀기 가능.
머신러닝의 종류
- 지도학습 (Supervised Learning)
: 데이터에 정답이 있고 , 정답 예측 모델을 만들 때
또한 정답이 있는 것으로 훈련을 했으니 새로운 사진이 와도 더 잘 예측할 수 있을 것. - 비지도 학습 (Unsupervised Learning)
: 데이터에 정답이 없고, 그냥 사진 엄청 많은데 거기서 알아서 분류를 해봐라, 유사도를 찾아봐라 라는 것.
군집화 등으로 비슷한거끼리 묶어줌.
ex.) 옷추천, 영화추천 등 - 강화학습 (Reinforcement Learning)
: 게임 가르칠 때의 예, 하나 깨면 +1, 잃으면 -10 이렇게 보상을 주면서 최종 점수는 높아지도록 방향키 움직여라 라는 것.
머신러닝, 기계의 학습 과정.
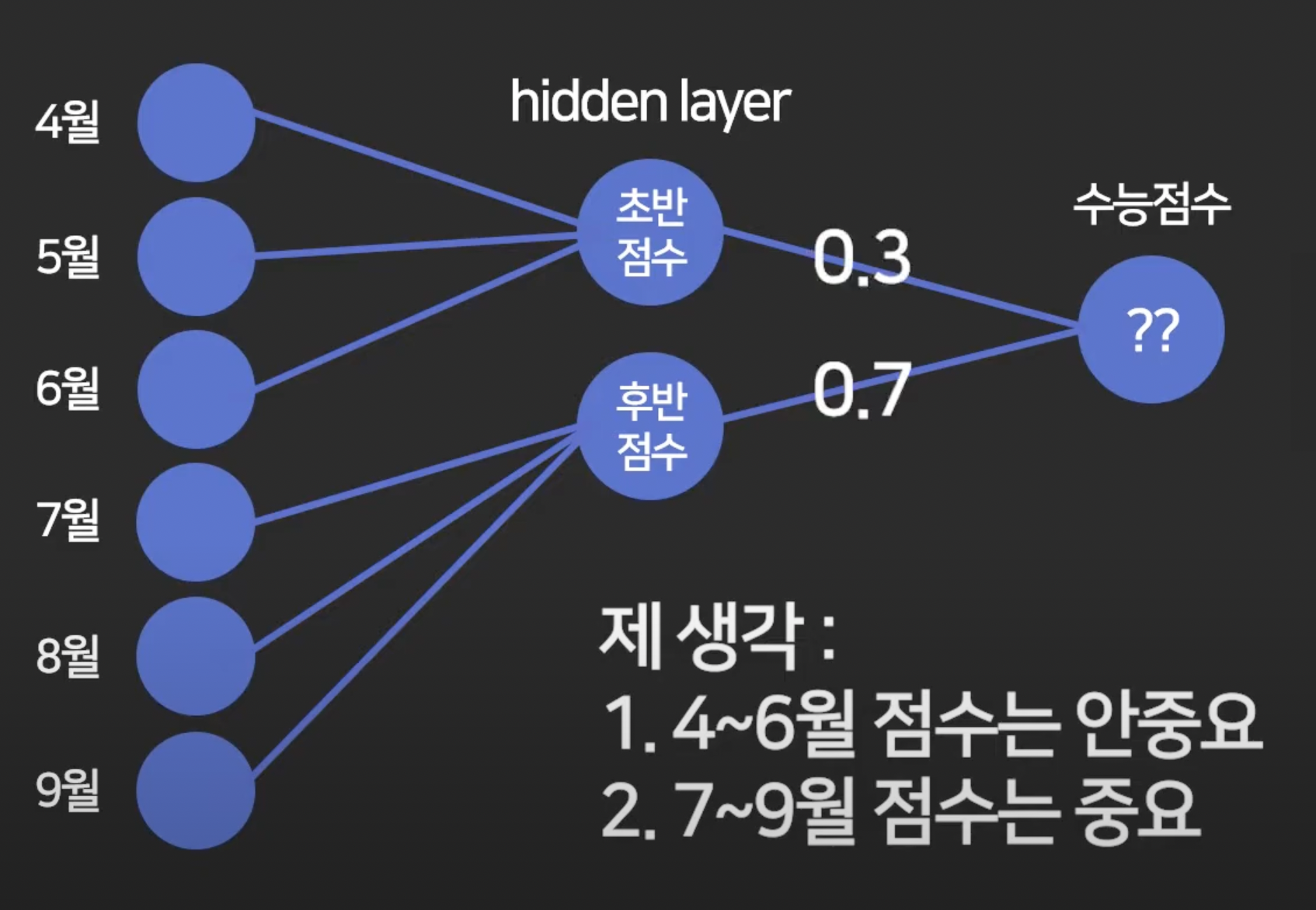
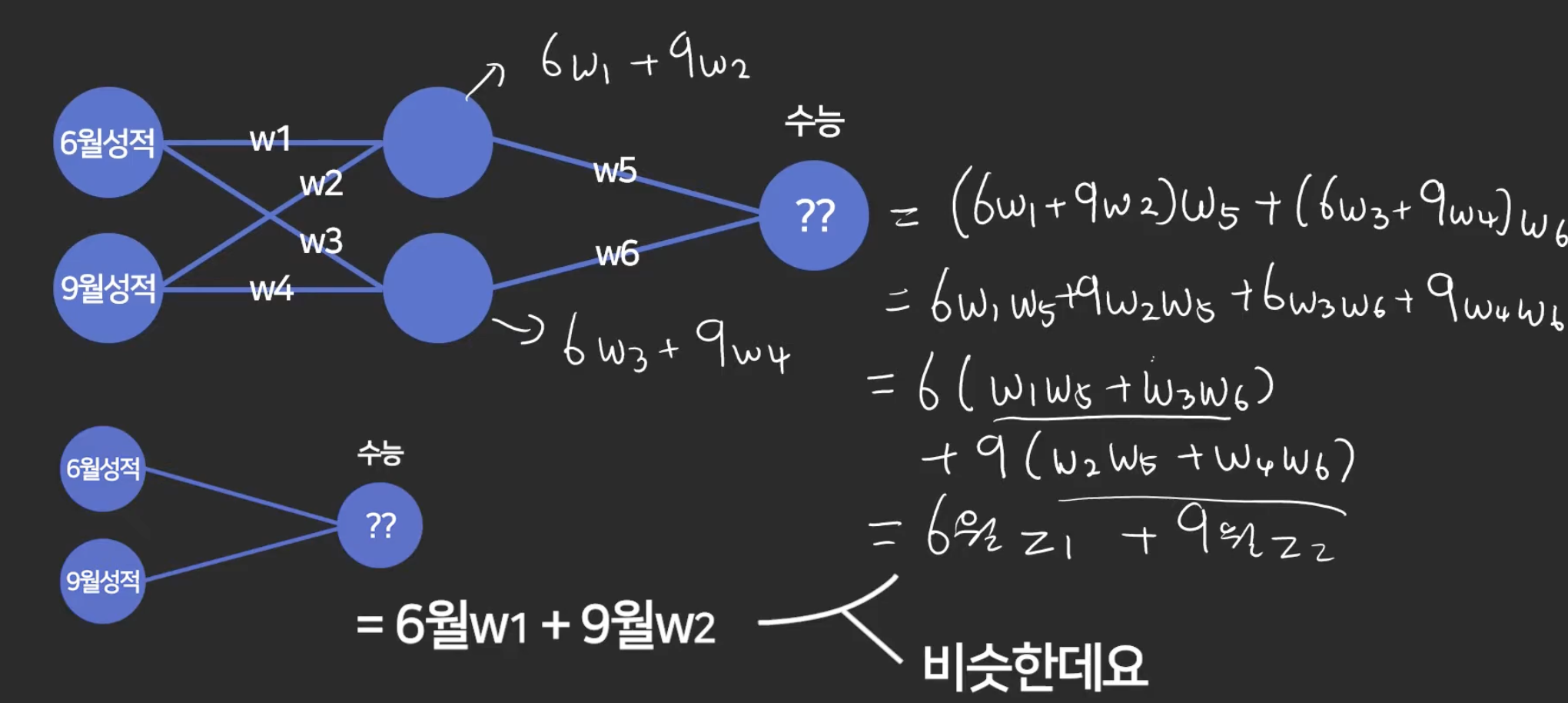
ex. ) 수능 성적 예측
- 6, 9 월 성적 반반씩 영향이 있을 것이라 판단.
-> 아래와 같이 예측함.
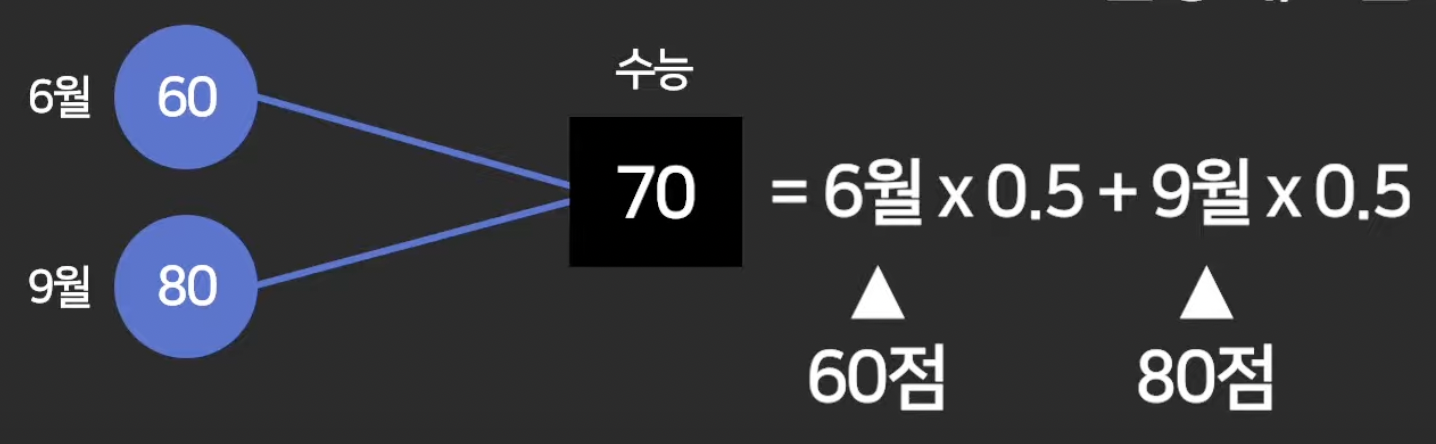
그래서 이렇게

이 weight(가중치)값들을 컴퓨터보고 찾도록 하는 것이 머신러닝.
b (bias, 상수, 편향) 도 예측하도록 할 수 있음.
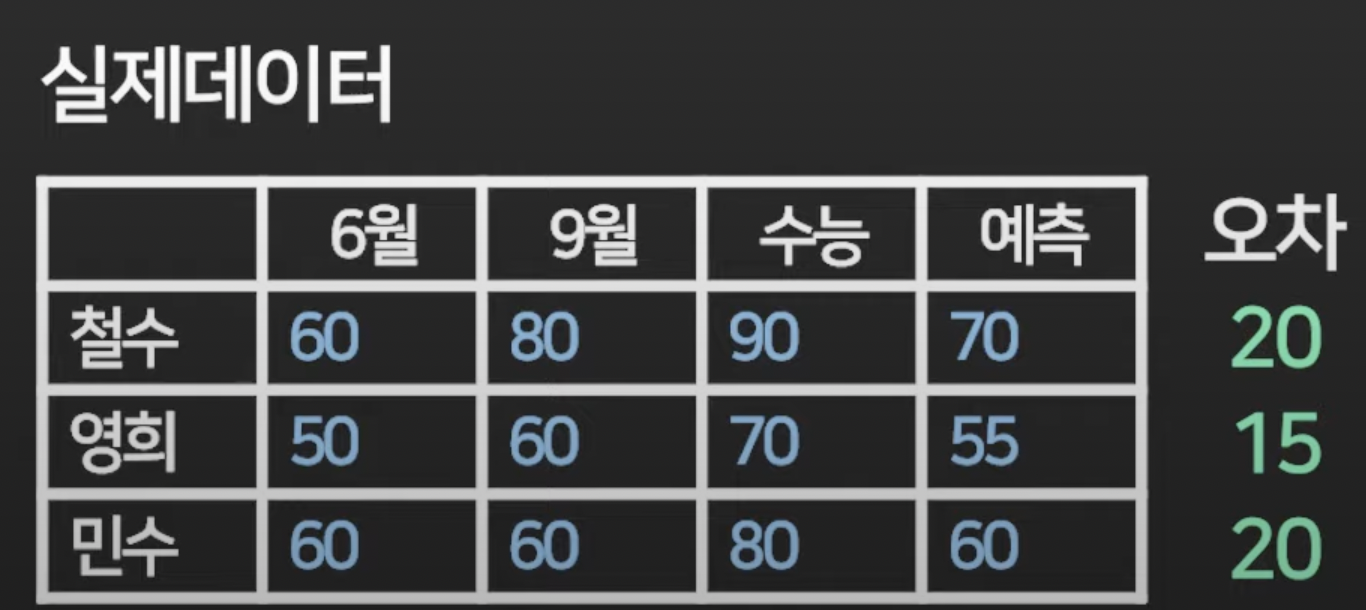
이렇게 오차값을 최소화 하는 방향으로 weight값을 예측해달라고 하는것.
그렇다면 딥러닝은?
중간에 layer를 하나 만들어서 레이어를 거쳐서 예측 결과를 내도록 만들면 그게 딥러닝.
아래처럼 디자인 한 것.

2강. Neural Network
이게 여러개 있으면 deep neural network.
레이어를 여러개 만들면 더 정교하게 예측할 수 있음.
수능 점수 예측 예시
이런 식으로 중간에 생각할 수 있는 레이어를 기계한테 적용하는 것.
실제 레이어를 거쳐가며 이건 차 로고 같다, 차 백미러 같다 이렇게 직접 분류를 할 수 있게 됨.
-> 이것을 특징 추출 (feature extraction)이라고 함.

3강. loss function
각 노드는 그냥 숫자임. (동그란 거 위 그림들에서)
얘랑 연결된 노드들을 각 가중치들을 곱해서 더한 값을 이 노드에 넣어주는 것.
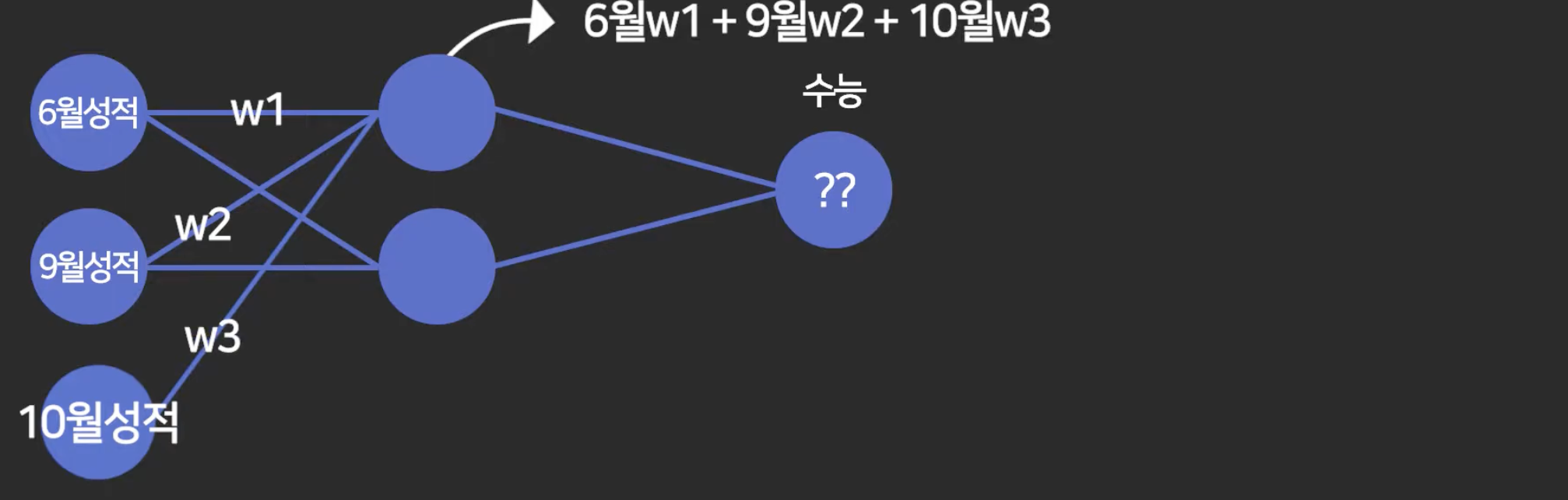
이 w 값들은 컴퓨터가 알아서 찾도록 할거고.
이 노드를 보통 h1, h2 이렇게 많이 말함. hidden layer 1 이런 의미.
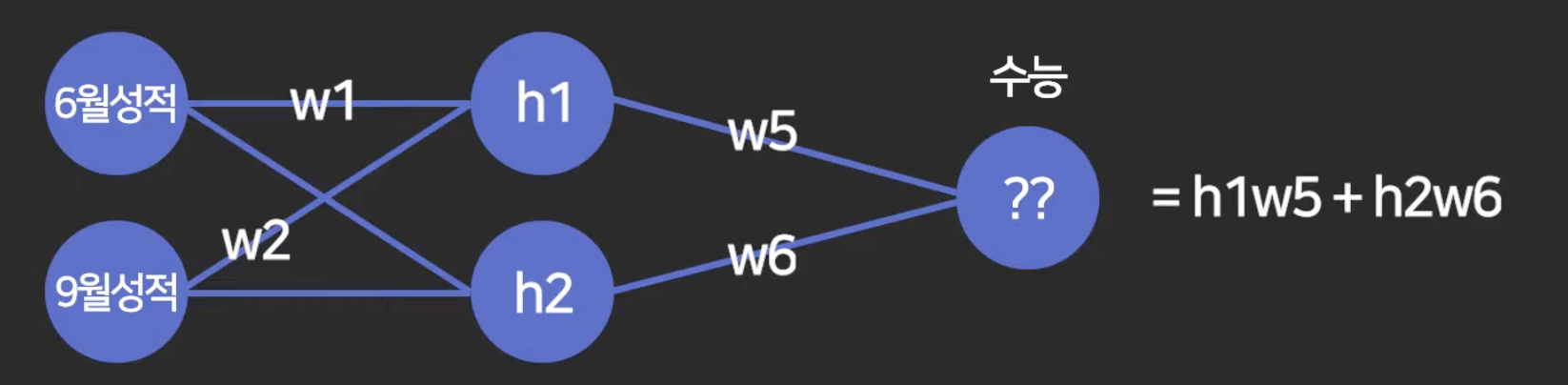
컴퓨터에게는 오차를 최소화하는 방향으로 w 값을 찾도록 하는 건데,
실제 데이터를 가져다가 비교하면서 이렇게 하면 된다고 했죠.

이런 식으로 평균제곱오차를 오차 구하는 방법으로 쓰고, 이렇게 구한 값을 최소화하는 방향으로 w를 구하라고 하는것.
loss function (cost function)
: 이 모델의 정확도, 오차가 얼마나 나왔는지 평가할 때 쓰는 함수.

y는 실제 값.
그래서 이 식이 평균제곱오차 구하는 식.
특히 정수를 예측할 때 이런 것을 쓰고,
뭐 평균을 예측하고 싶은 분류 문제, 확률 문제 등을 쓰고 싶을 때는

4강. 활성 함수 (activation function)
결함 : 여기까지만 하면 hidden layer가 있나 없나 결과가 비슷함.
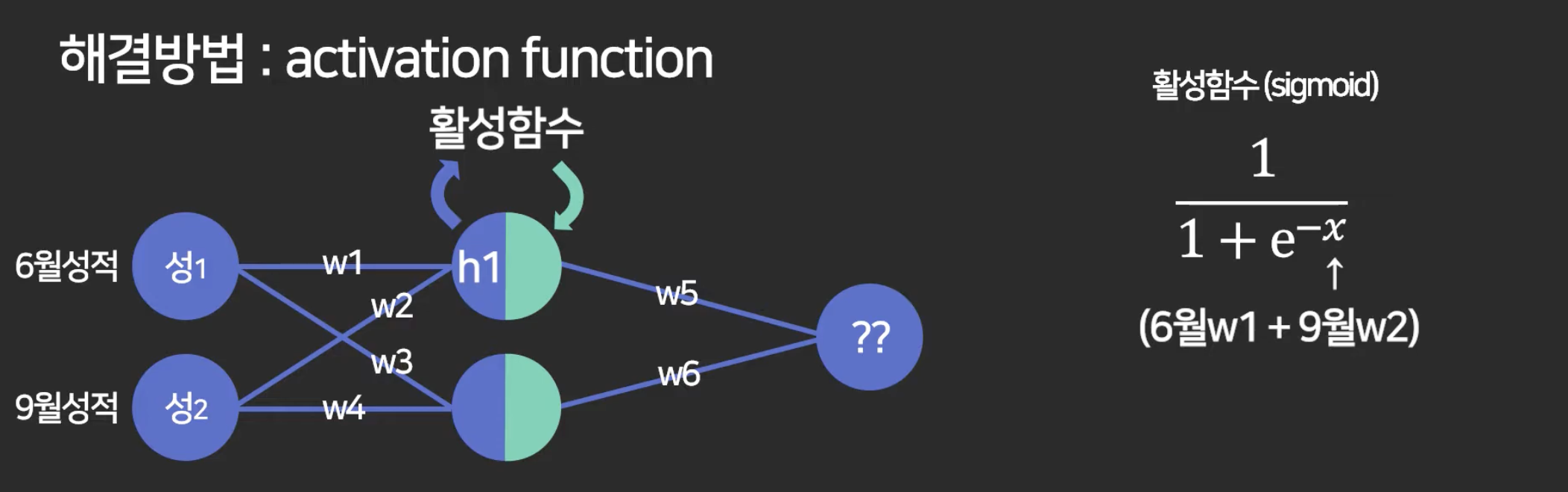
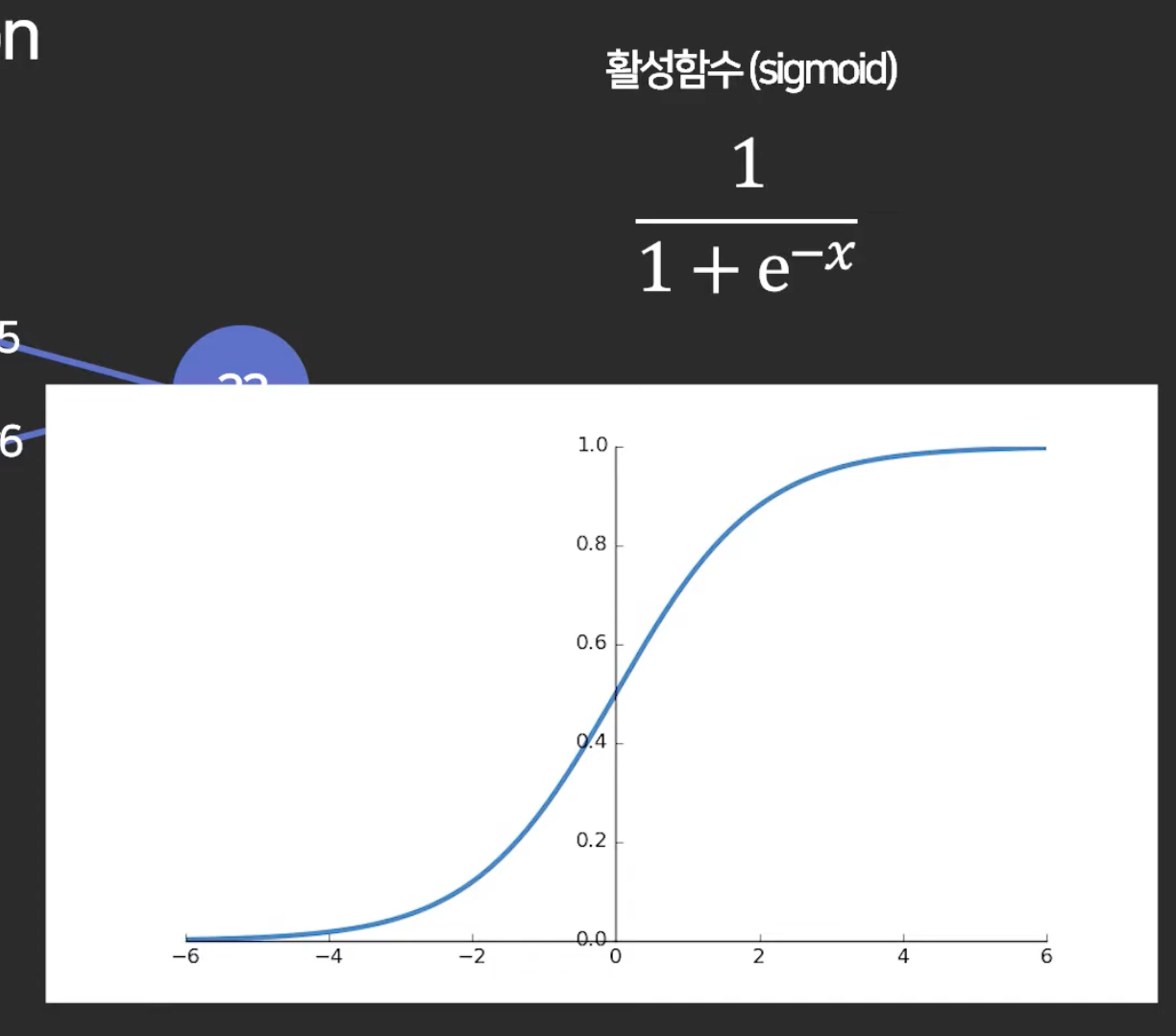
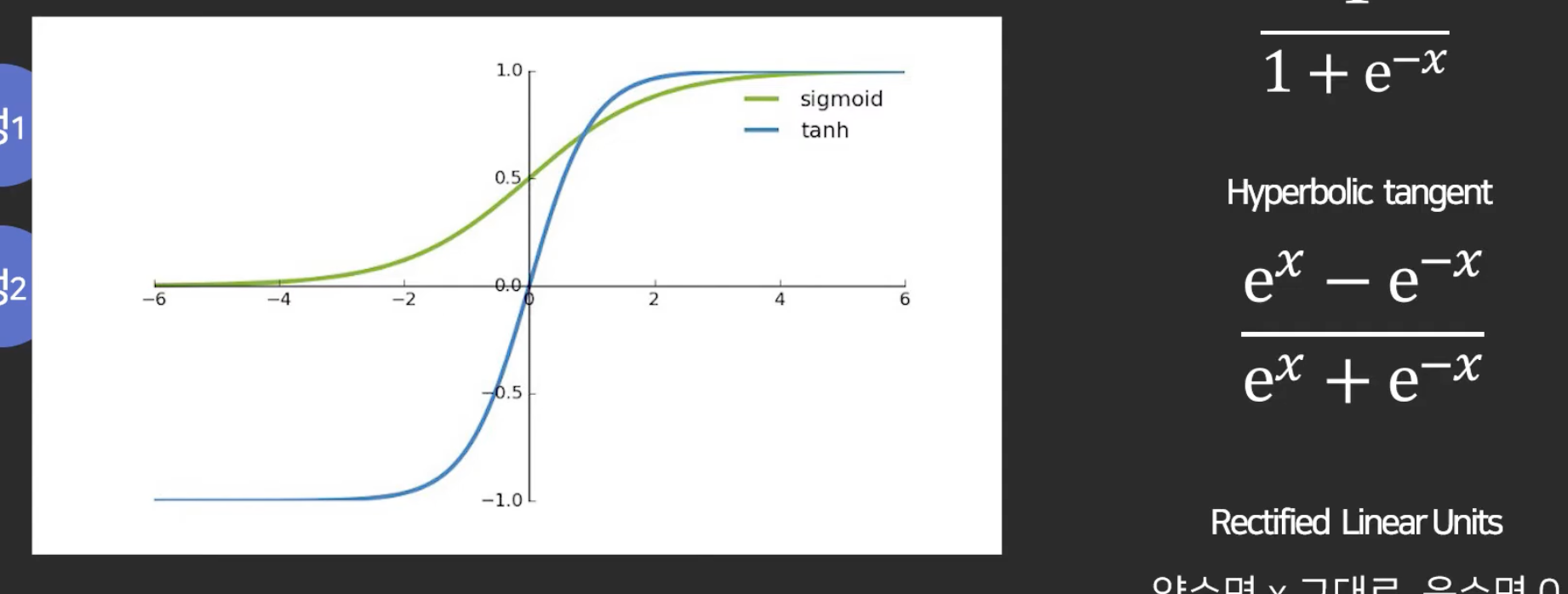
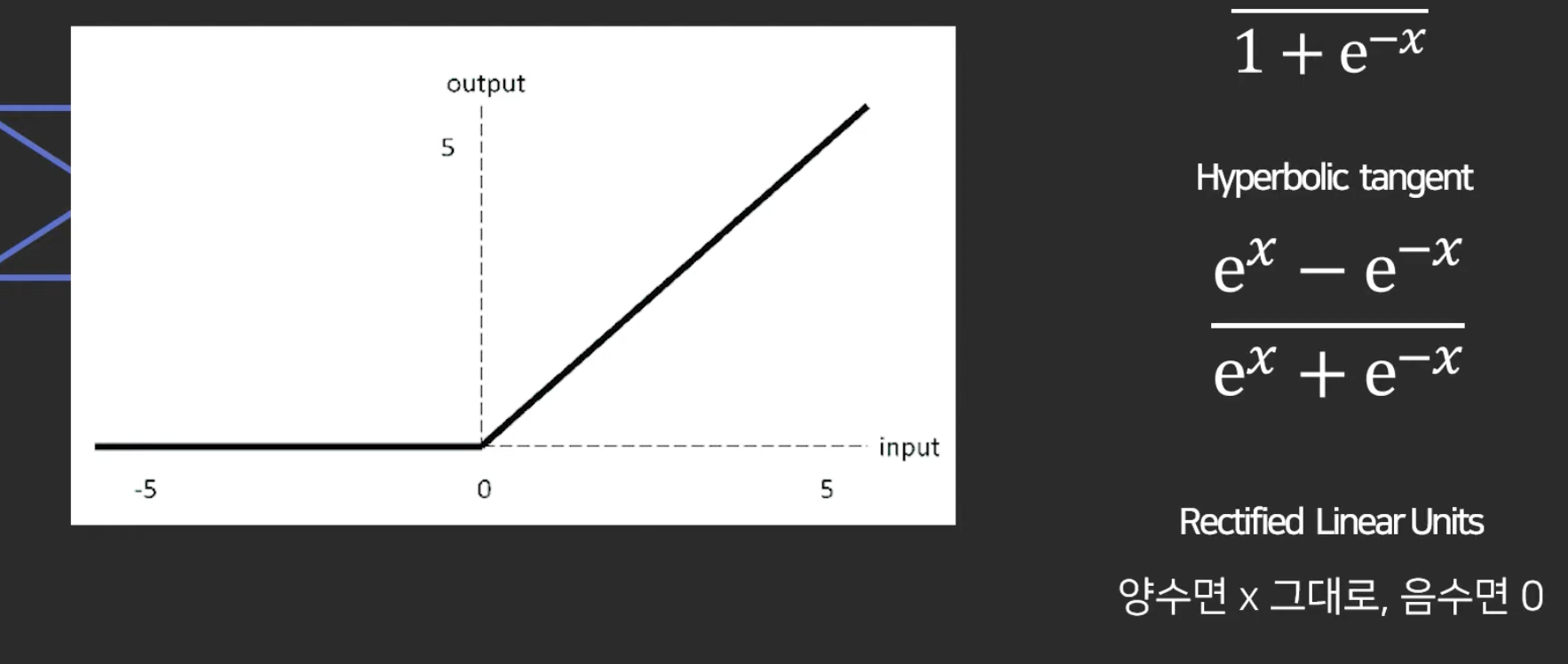
이런 거를 적용해주면 layer가 제 역할을 하게 됨. layer를 거칠수록 정교한 예측을 가능하게 함.
-> activation function이 필요한 이유: 비선형적인 예측을 하고 싶을 때

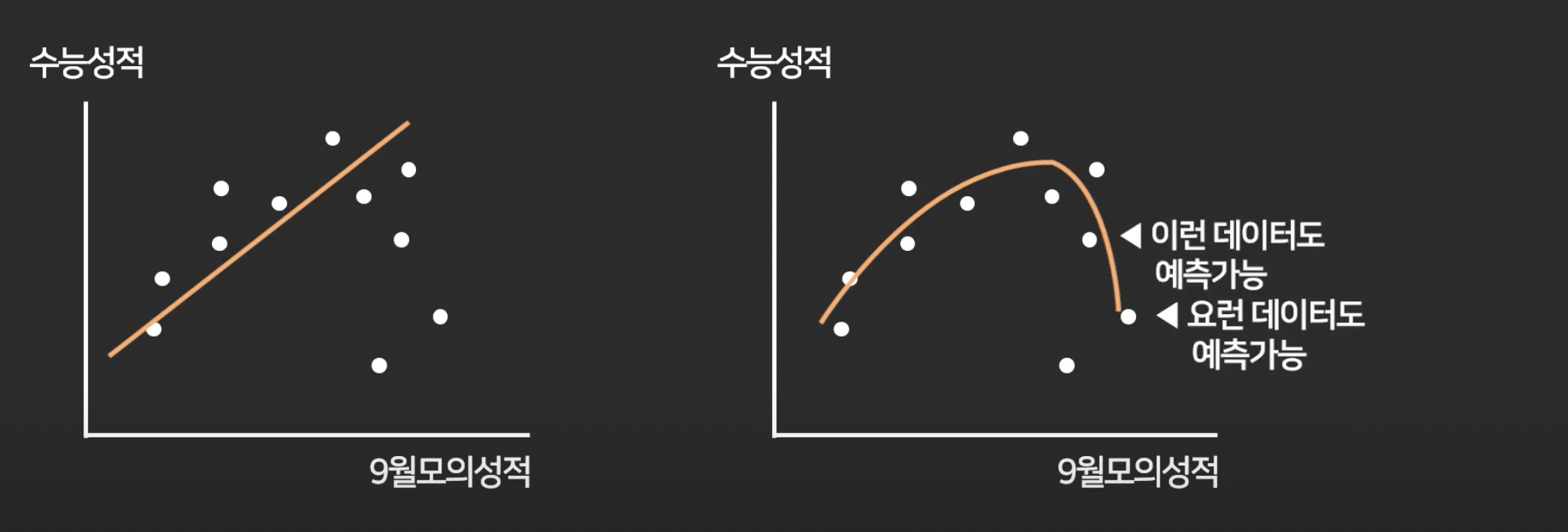
따라서 activation function이 없으면 딥 러닝이 아니라고 보면 도미.
출력층에는 활성함수가 없을 수 있음.
출력값을 0~1 사이의 값으로 넣고 싶으면 써도 되고.
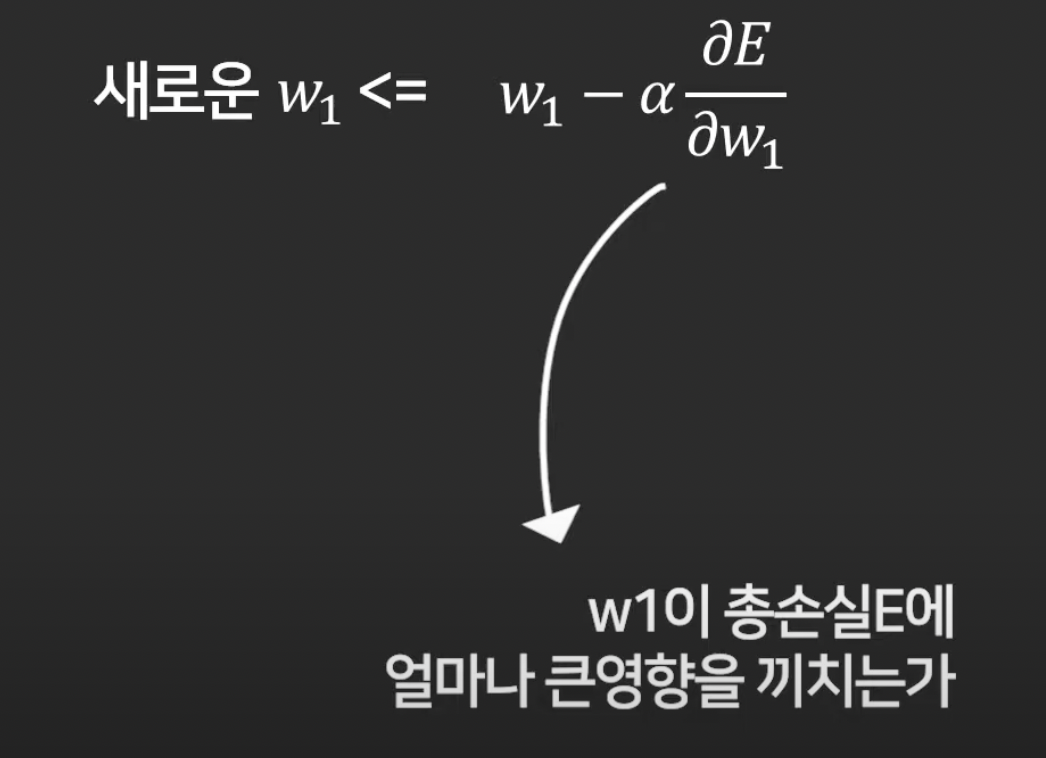
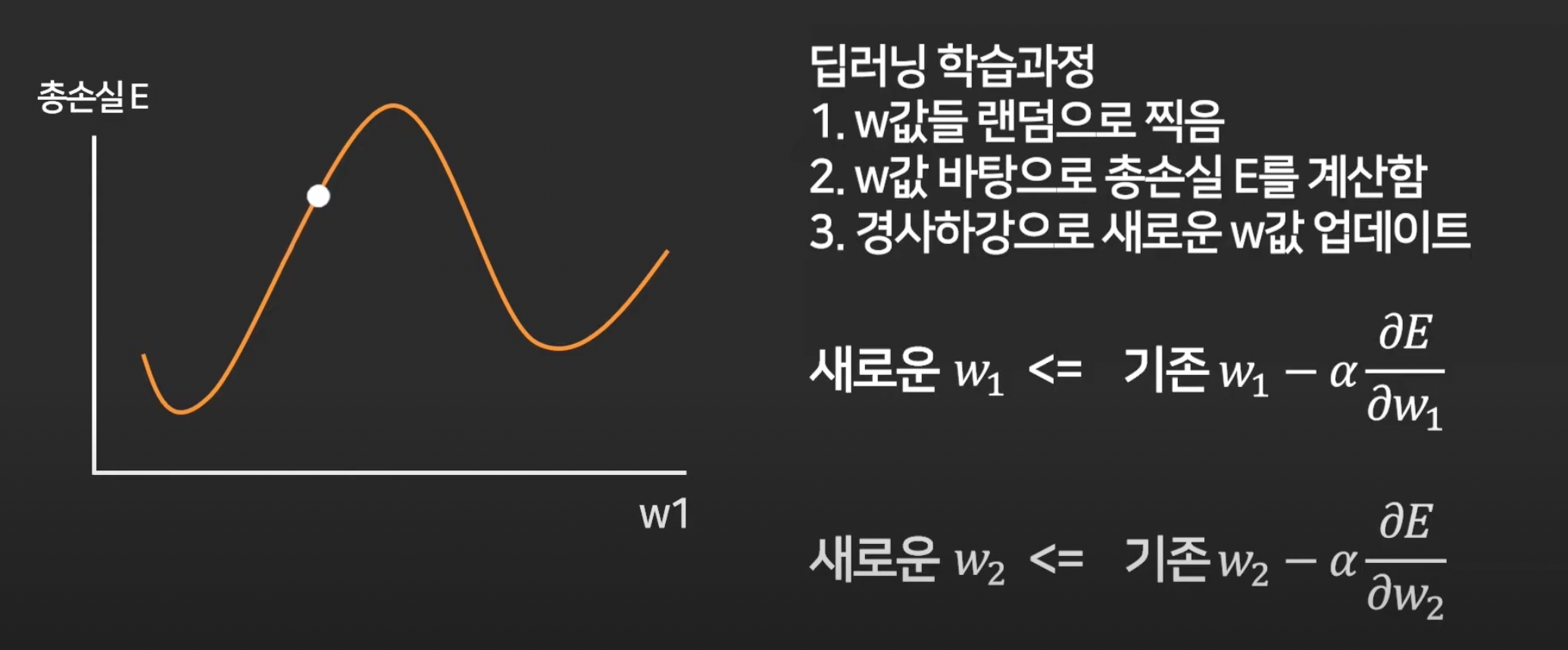
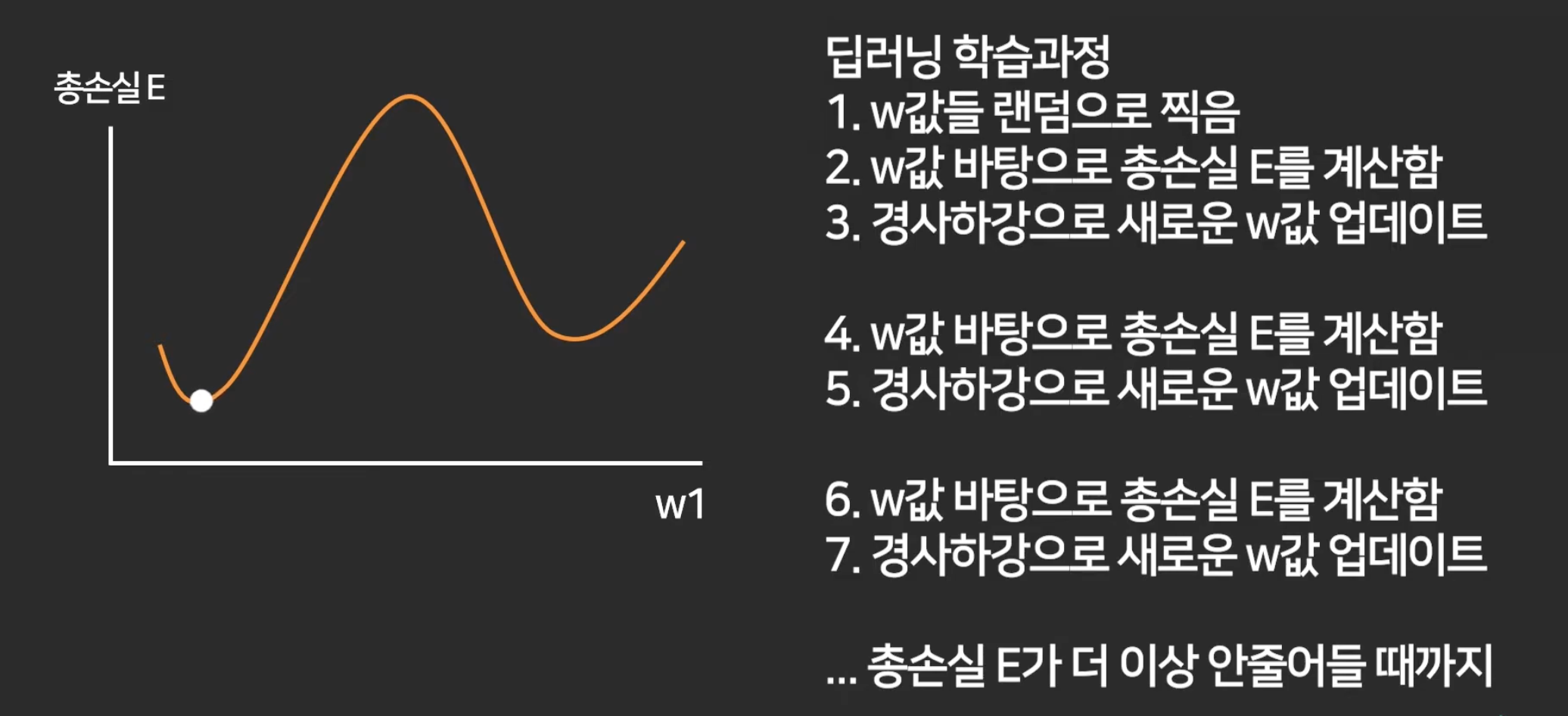
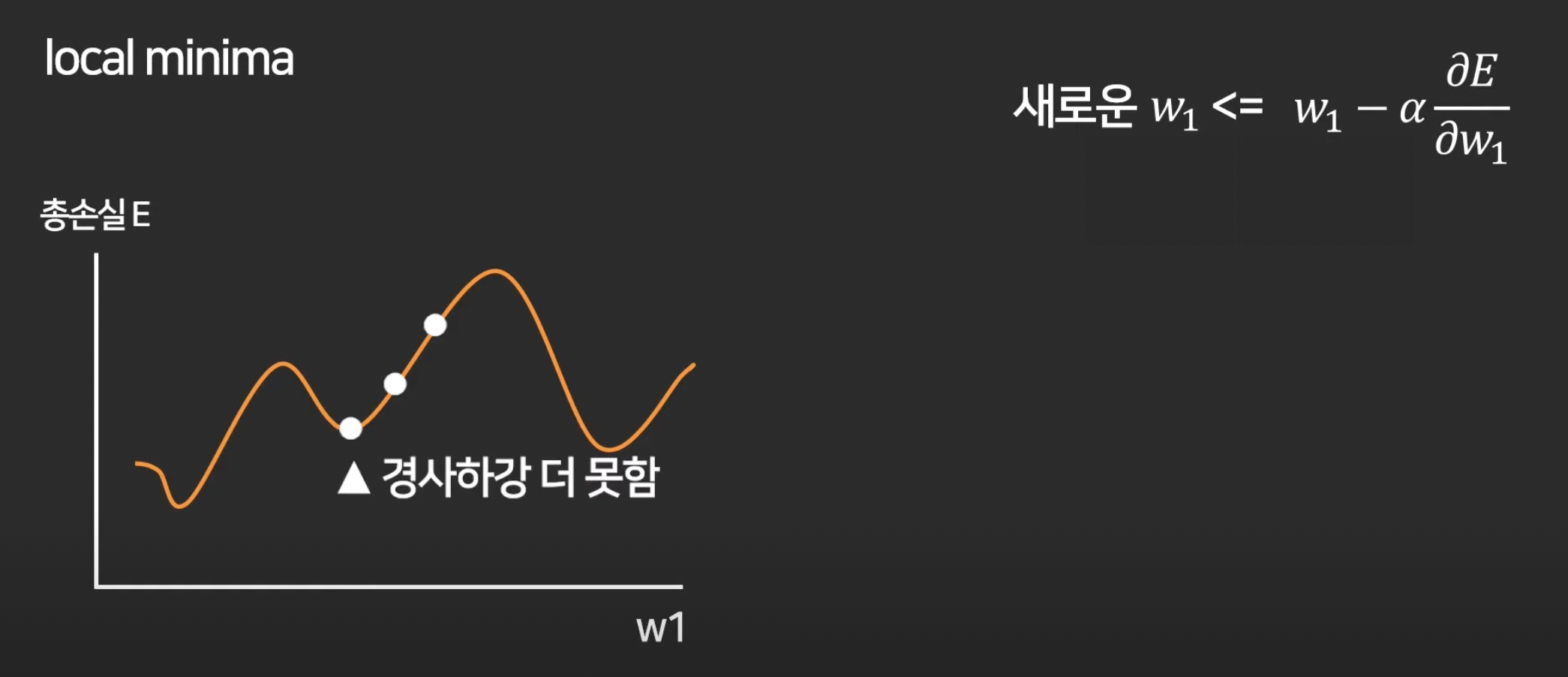
5강. 경사하강법 (Gradient Descent)
이제 loss를 최소화 하는 w를 찾는 방법에 대해 배울 것.

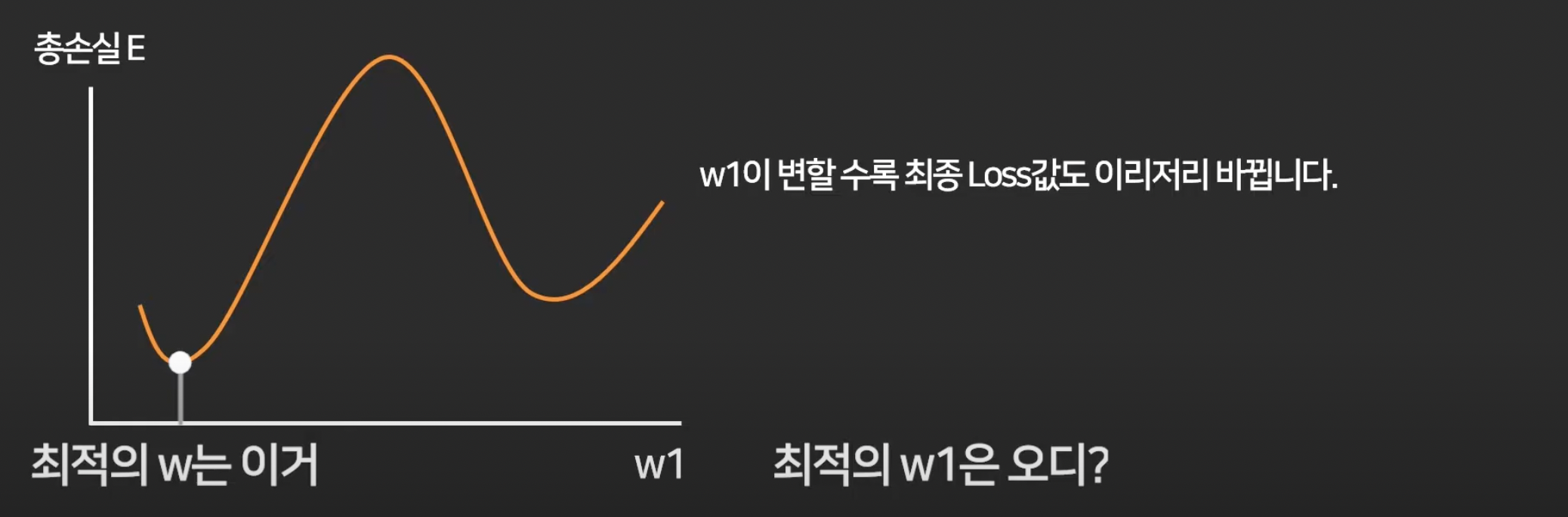
첫 w1은 랜덤으로 아무데나 찍고,
경사하강법이라는 알고리즘 이용.
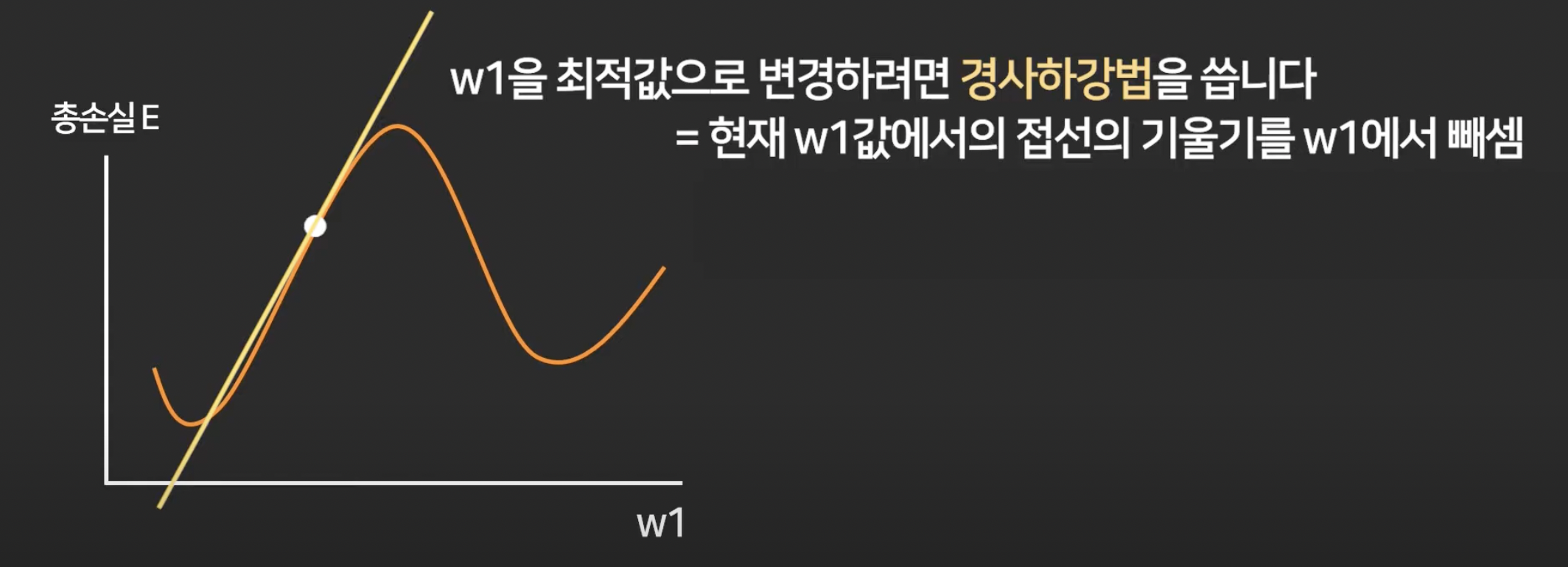
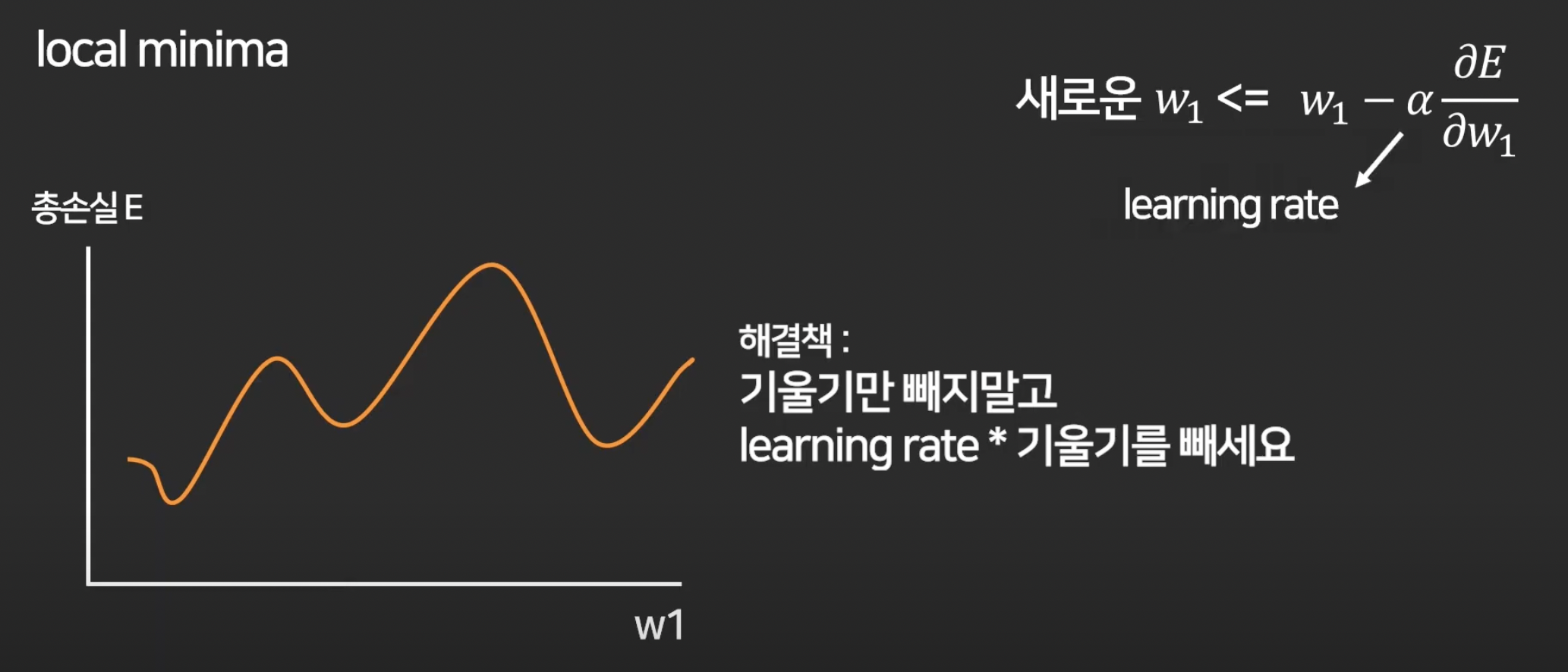
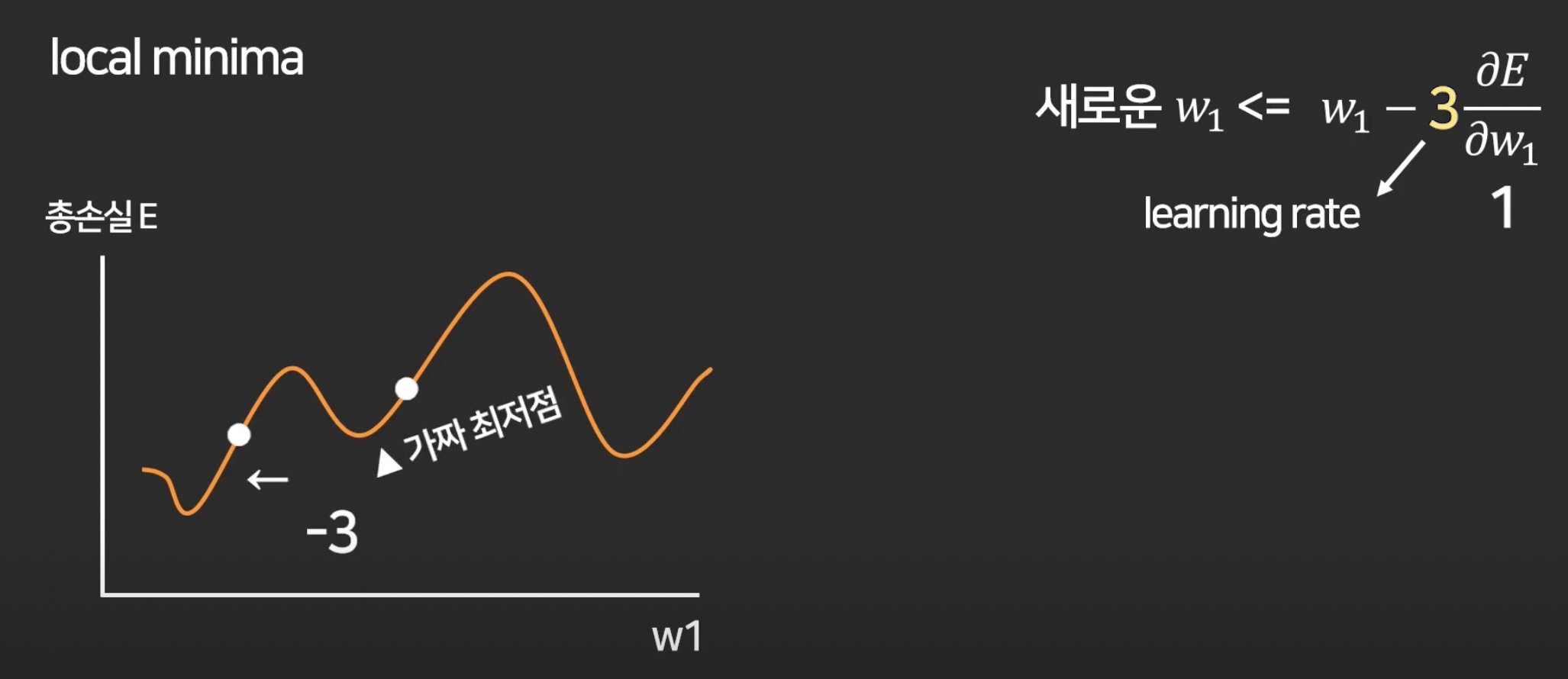
근데 이 learning rate는 정답이 없고 실험으로 이것저것 넣어보면서 가장 적합한 것을 찾으면 됨.

6강. Tensorflow2 기초

행렬을 이용하는 이유 : 숫자 여러개 계산을 편리하게 하기 위함.




+) tf.zeros(): 0만 담긴 텐서 만들어줌.
-
tensor의 shape : 행렬의 차원, dimension 을 의미.
- (2,3) : 2행 3열의 차원의 텐서다. (행렬이다.)
: 3개의 데이터가 들어있는 거가 2개가 있다. 라는 것.
tensor의 datatype(dtype) : 실수가 들어있으면 실수, 정수가 들어있으면 정수...
tf.cast() 쓰면 자료형 바꾸기 가능. -
variable이라는 tensor
: weight를 저장하고 싶으면 Variable을 만들기.
예) w = tf.Variable(1.0) # 변수의 초기값을 1.0으로 설정하는 것.
weight는 variable로 만들어줘야함. 그래야 변경이 쉬움.
w.numpy() 라고 하면 그 변수에 저장된 값을 불러올 수 있음.
w.assign() 하면 variable에 저장된 값을 변경할 수 있음.
이런 걸 이용하면 Neural Network를 더 수월하게 만들 수 있다.
(근데 최근에는 Tensorflow에서 Pytouch를 더 이용하는 걸로 넘어가는 추세라고 함.)
7강. Tensorflow2로 해보는 간단한 선형회귀(Linear Regression) 예측
딥러닝으로 간단한 수학문제 풀어보기.
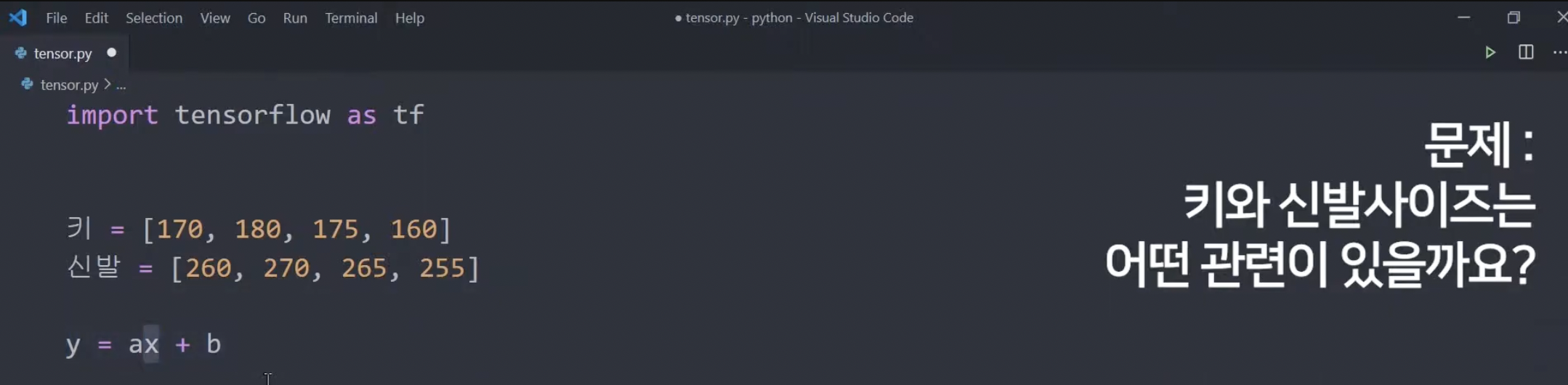
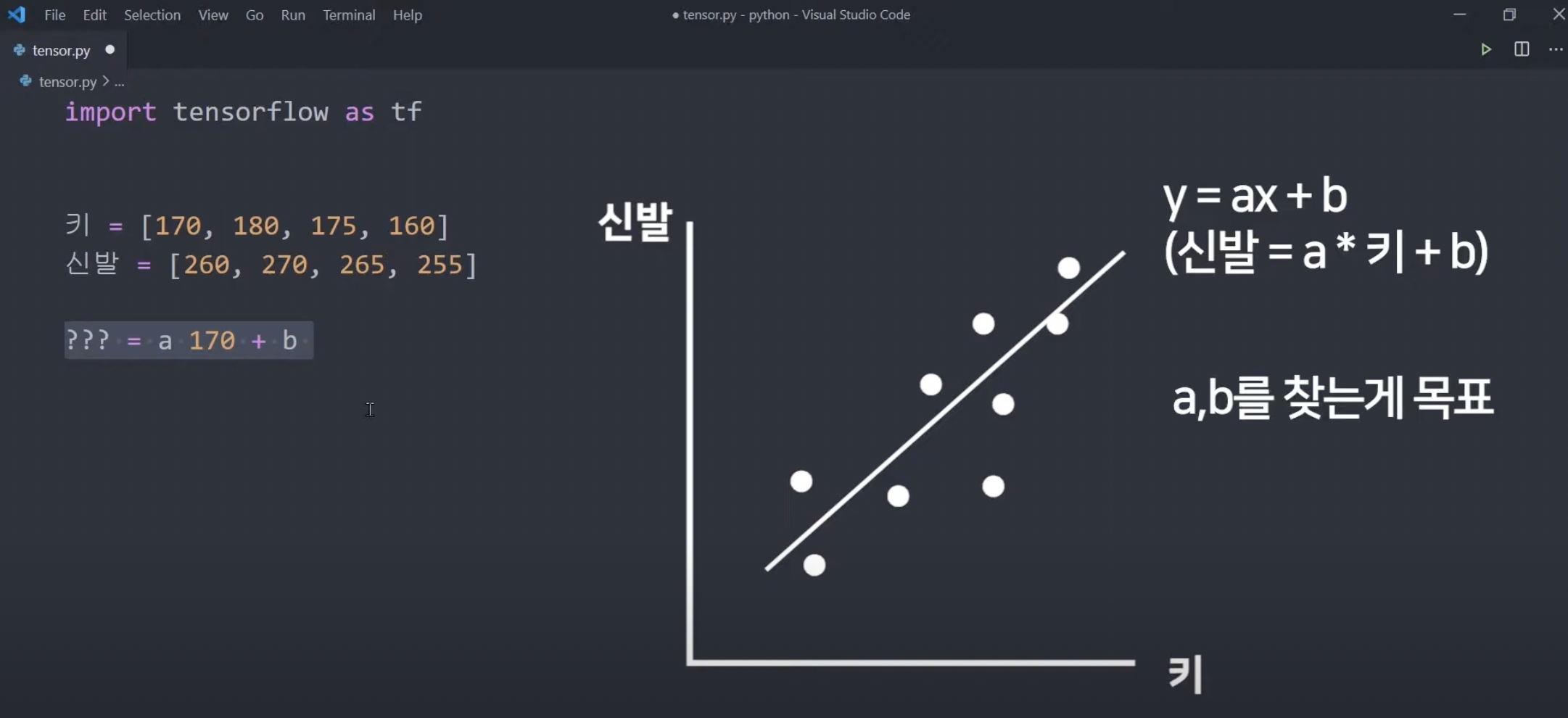
x : 키, y: 신발 -> 키를 대입해서 신발 사이즈를 예측하는 a와 b를 결정해보자.
(경사하강법을 이용할 것)
tf.keras.optimizers -> 경사하강법을 도와주는 고마운 친구 ..
tf.keras.optimizers.Adam(learning_rate = 0.1) -> 그 업데이트를 해줄 때 gradient를 알아서 스마트하게 도와주는 optimizer가 Adam, learning rate는 원래는 알아서 0.001인가로 설정되는데, 이 learning rate를 바꾸고 싶으면 이렇게 설정해주면 됨.
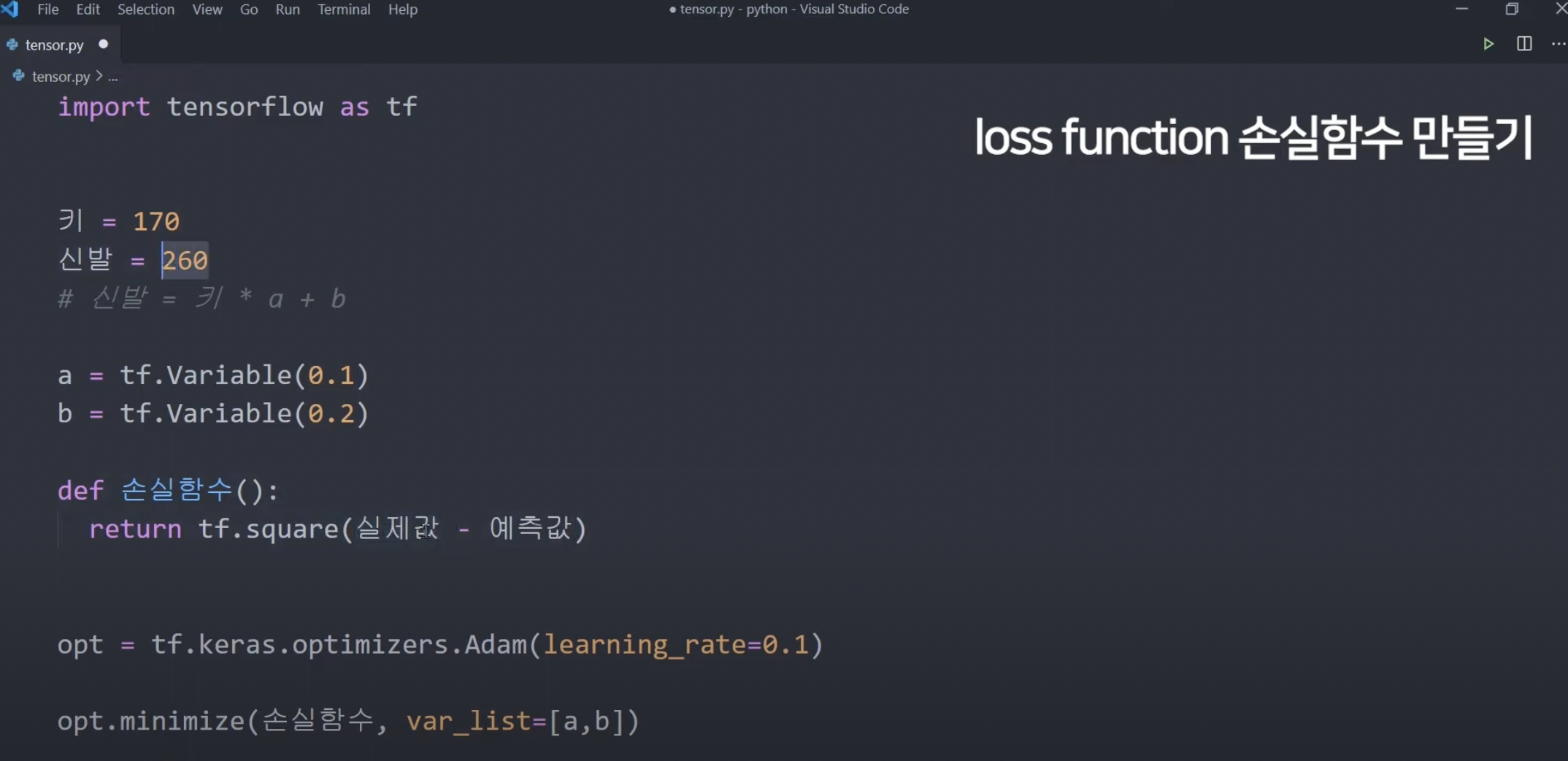

var_list : 경사하강법으로 업데이트할 모든 weight Variable들의 목록.
opt.minimize() : 경사하강법 한 번 해줌(a,b(weight) 값을 한 번 수정해줌) -> 경사하강법 계속할라면 이걸 반복문 안에 넣어서 일정 수 동안 반복하게 하면 됨.
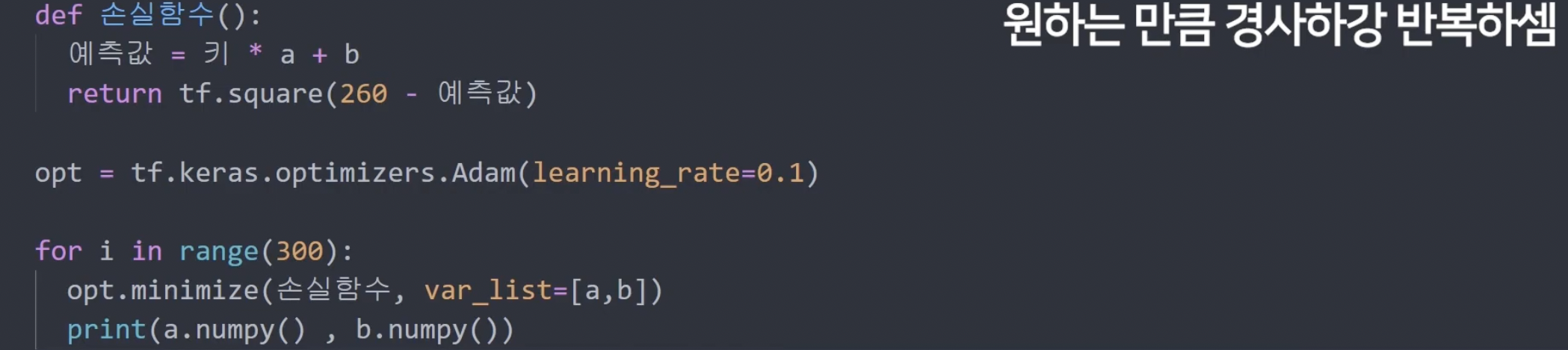
이렇게 하면 적당한 a,b 값이 나옴.
그냥 print(a, b) 하면 그 각 변수(variable)에 담긴 숫자 값만 나오는게 아니라 shape, dtype 등..도 같이 나옴. 그래서 numpy() 해서 좀 더 보기 좋게 만드는 것.

뭐 이렇게 ,, 나옴 numpy() 안 하면
이렇게 하면 키만 알면 예측한 신발 사이즈가 나오는 식이 나오는 것!
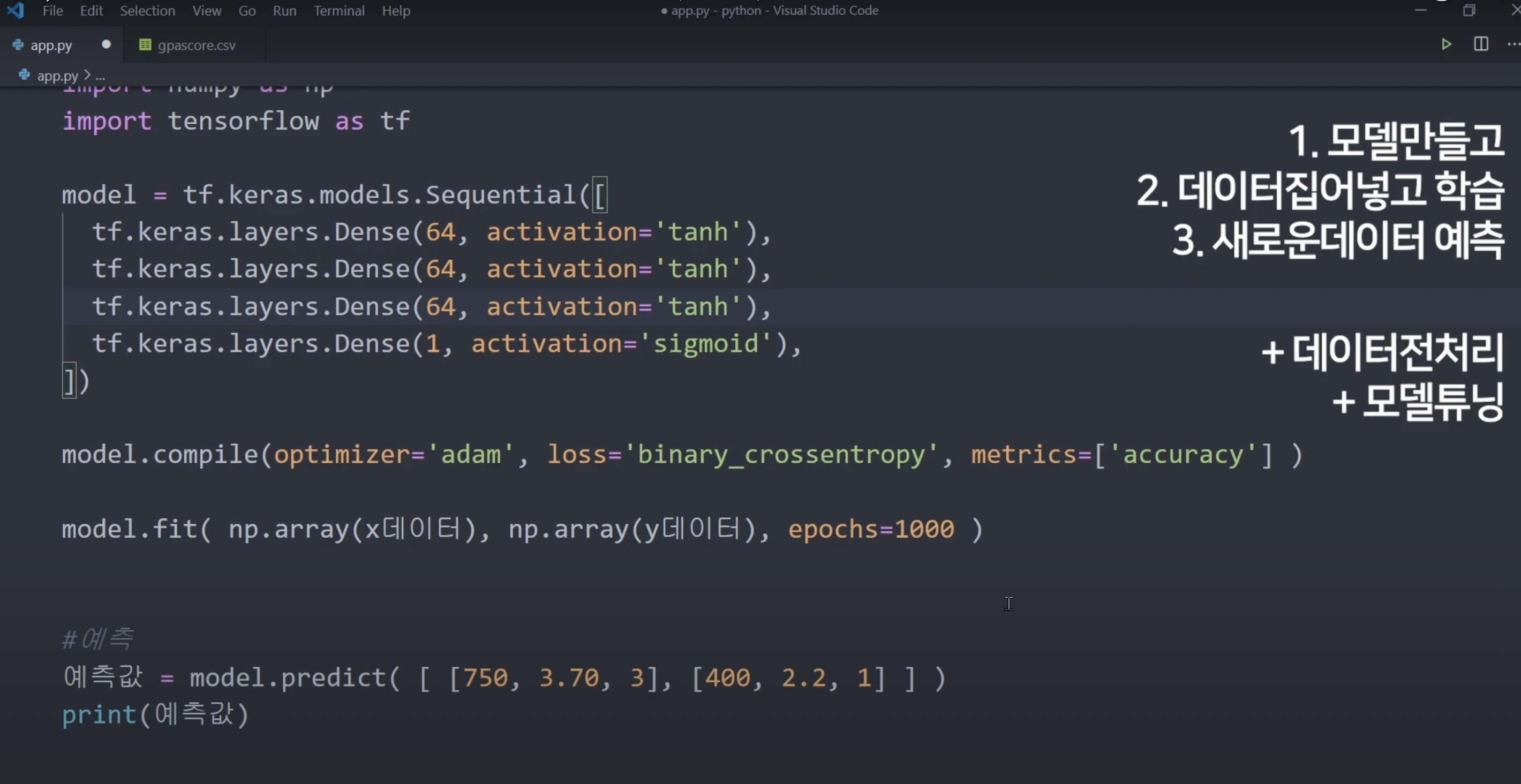
8강. 대학 합격 예측 AI 만들기
텐서플로우 안의 keras 라는 high-level API를 사용해서 학점, 지원한 학교 순위, 영어 점수를 받아서 대학원에 합격할 지 예측하는 대학 학점 AI를 만들어봅시다. 붙을 확률을 구하는 AI.
파이썬 파일과 같은 폴더에 csv라는 데이터 파일 만들기.
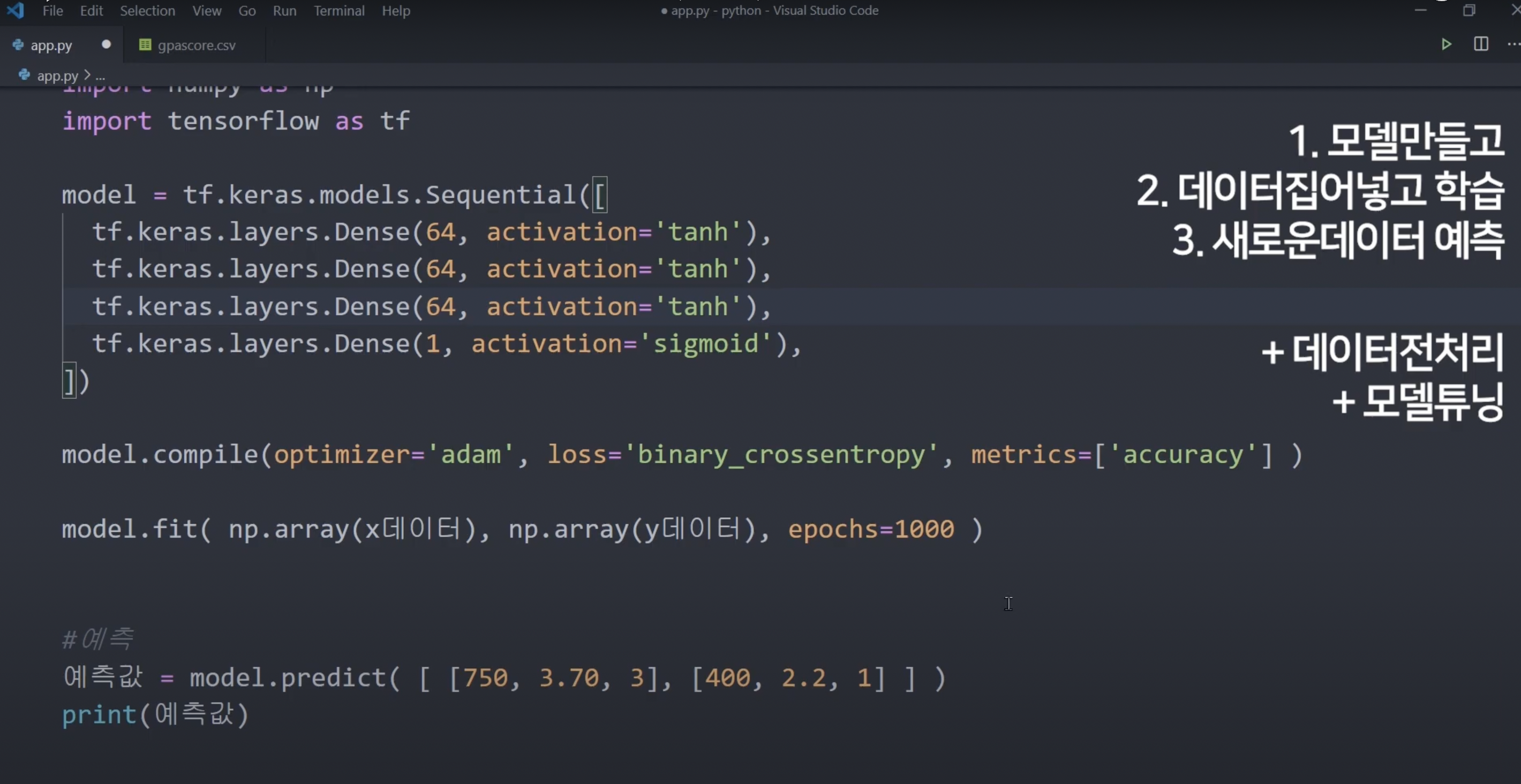
강의 보세요.
강의
https://www.youtube.com/playlist?list=PLfLgtT94nNq1DrREU_qG2w4yd2ZzJb-FG
