영상 : https://www.youtube.com/watch?v=_KI4WYw9wmA&t=21s
GAN(Generative Adversarial Network, 적대적 생성 네트워크)
: 서로 싸우면서 발전하는 형식. 흔히 드는 예로 경찰과 도둑의 위조지폐.
도둑이 위조지폐를 계속 만들어내면서 경찰이 구분 못할 정도로 정교하게 만들어 내면,
경찰은 이 위조지폐를 더 정밀하게 구분해내기 위해 노력함.
이렇게 만들고 판별해내는 한 쌍이 이루어진게 GAN.
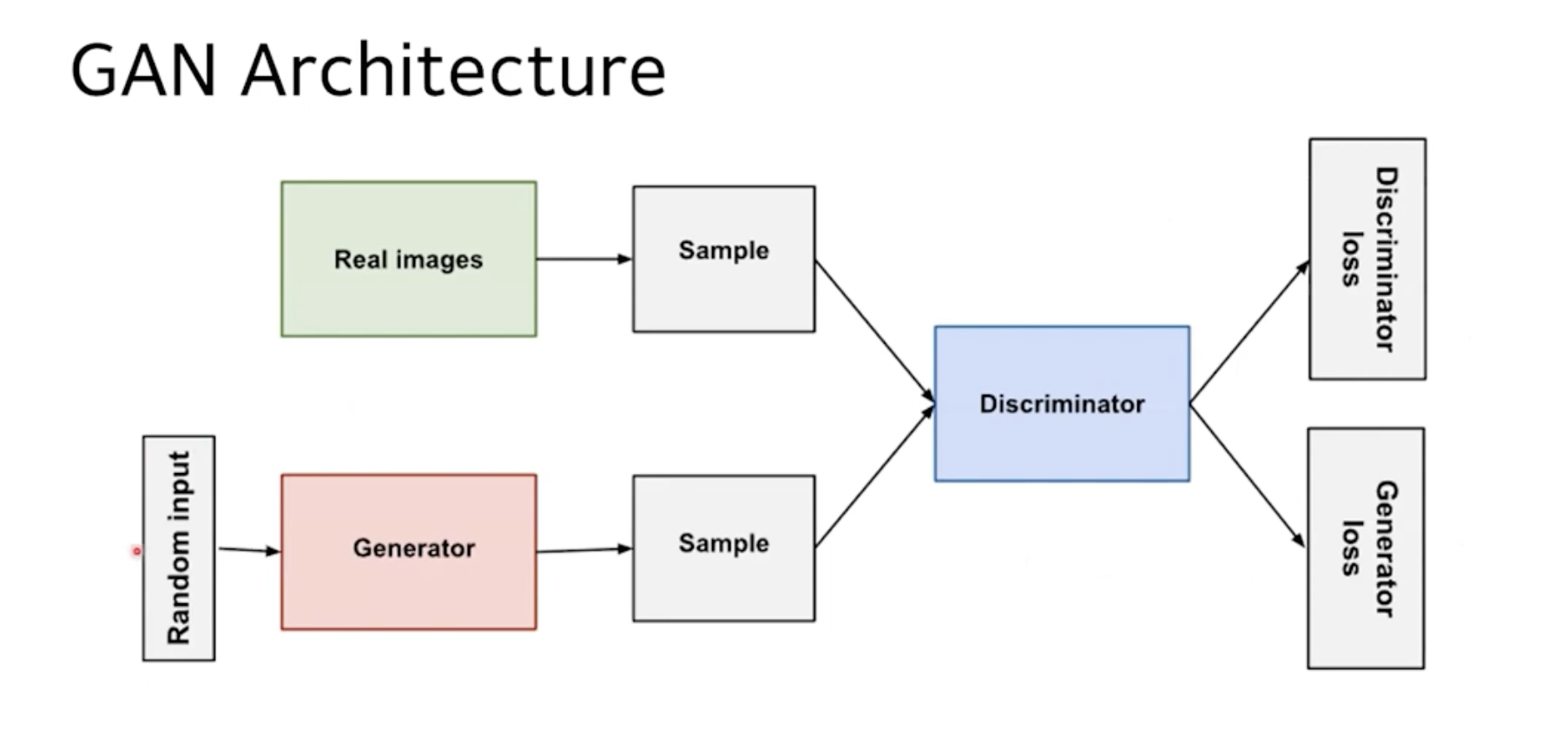
Random input(z) : latent space vector라고 부르는, 잠재적 공간 벡터. 무엇이든 될 수 있다는 의미로 이렇게 부름. 보통 z 벡터로 많이 부름.
Generator(G) : 이 z가 G로 들어가면, Sample로 Fake image가 나옴.
이 fake 이미지와 위의 real image가 이 Discriminator(D)라고 불리는 판별자로 들어가서 판별을 받고, 이 결과로 나온 판별 값을 바탕으로 D의 loss, G의 loss를 계산하여 이 loss 값을 바탕으로 G와 D가 업데이트 됨.
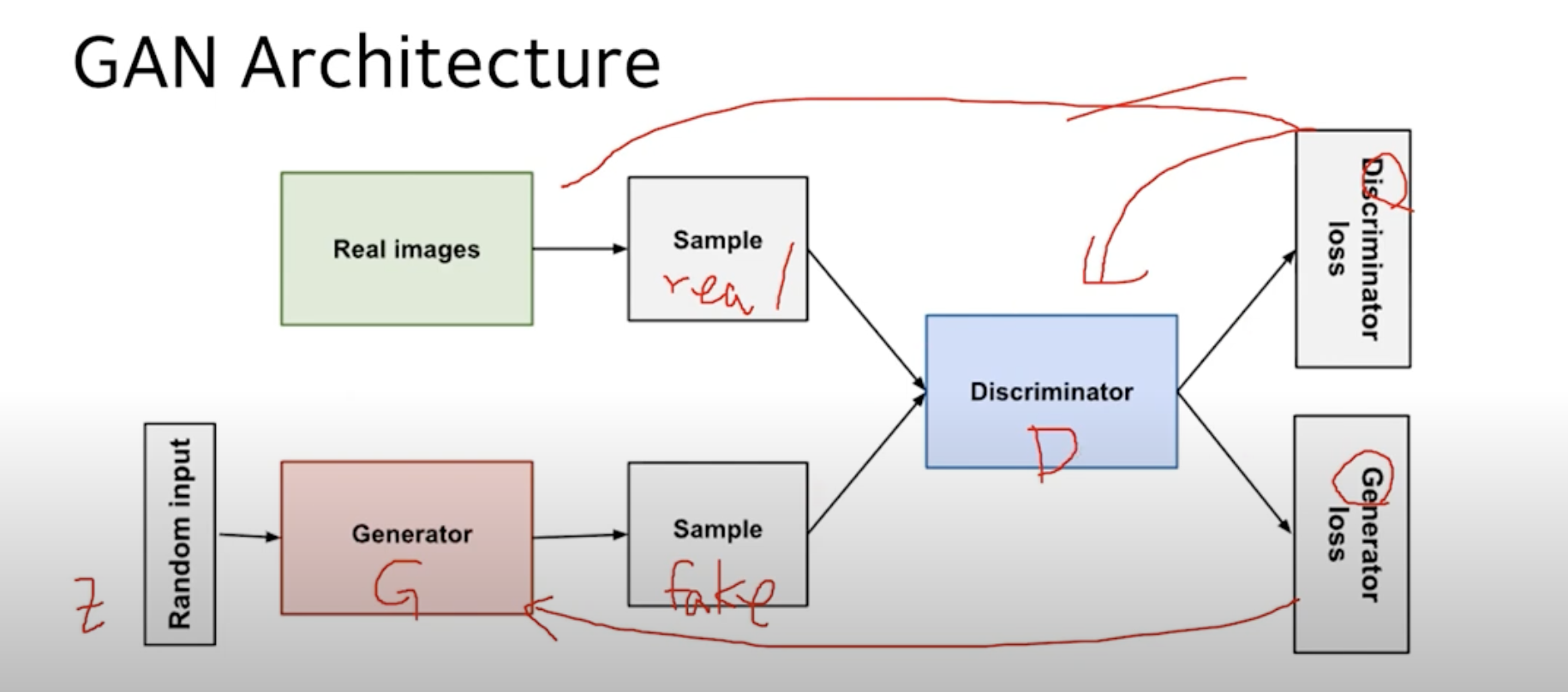
+) G : 비지도학습, D : 지도학습을 함. ( z가 G를 통해 fake image가 나오는 과정은 정답이 없기 때문에 비지도 학습인 것, real과 fake에서는 real이 정답이니까 1, fake니까 0이라는 정답을 가지고 있기 때문에 지도 학습이 되는것.)
GAN loss
loss function로는 BCE (Binary Cross Entropy)를 사용함.
왜냐면 앞에서 D는 진짜인지 가짜인지 라벨을 뱉어내기 때문.
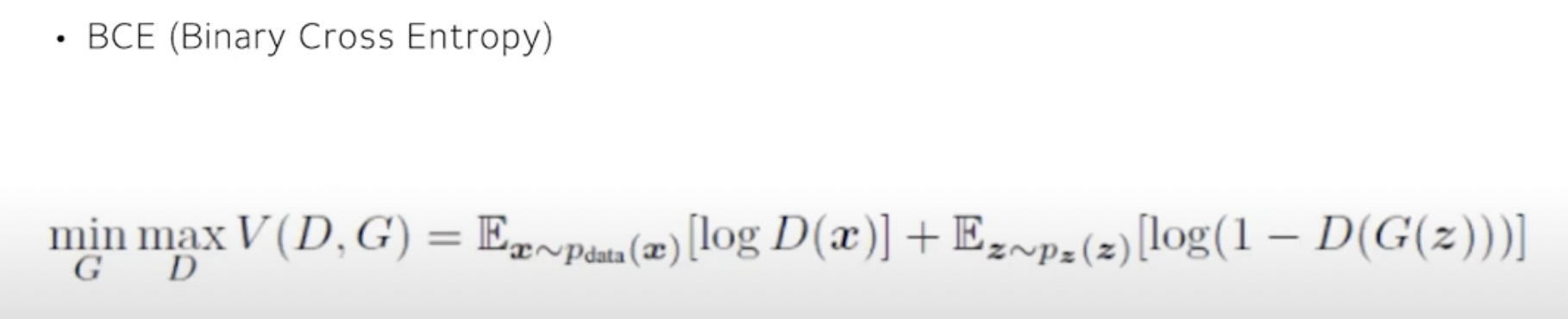
D의 입장에서는 구별을 할 수 있어도 능력을 높이는 것이 중요하고 G의 입장에서는 차이가 안나도록 하는 것이 최대의 성능을 내는 것이기 때문에 Min과 Max 이렇게 G, D를 표현함.

G와 D를 동시에 업데이트하는 것이 아니라, 실제로는 하나를 묶어두고 한 쪽 업데이트를 진행함.
위는, real이 들어오면 1, fake는 0으로 판별해야 하는데,
그래서 + 기준 앞뒤의 log 값이 0, 즉 log1이 되는 것이 Max값인 loss임.

G의 입장에서는, z의 입장에서만 영향을 받기 때문에 왼쪽 식은 고려를 하지 않고,
D가 fake image가 1로 나와야 하기 때문에 (D가 fake image를 1, 즉 real image로 판별해야함)
D가 1이 되면서 log0이 되면서 -무한대 가 최소값이 되게 됨.
GAN Image
G는 어떻게 이미지를 만들어내느냐.
-> 이미지, 차원 분포에 대한 이해 필요.
이미지를 구성하는 작은 단위는 픽셀. 픽셀은 3가지 색을 담당. 즉, 3차원.
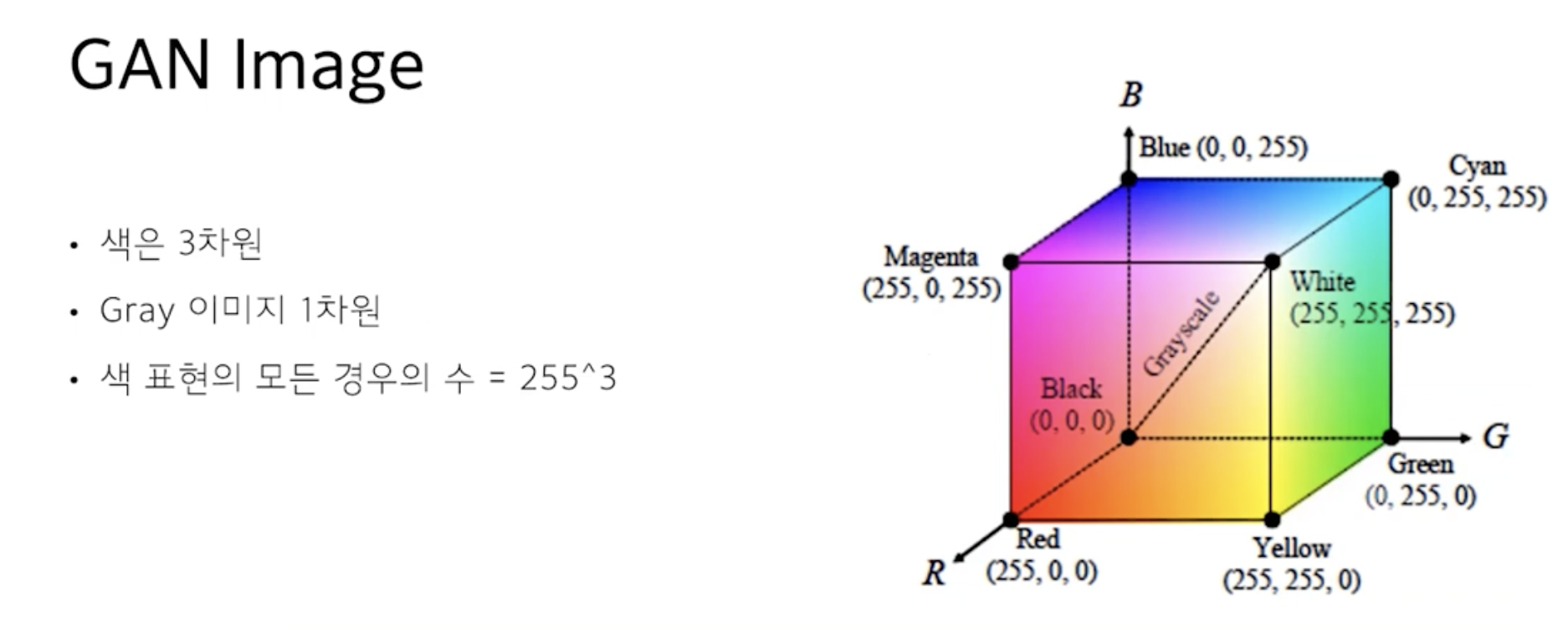
그렇다면, 이미지는 하나의 픽셀은 하나의 차원으로 두기 위해 gray 이미지를 사용한다고 가정하면,

이러함. 근데 이렇게 많은 경우의 수들이 전부 다 의미 있는 이미지일까?
하는 의문. 왼쪽의 노이즈 이미지 같은 것도 정말 많이 나올 것.
그래서 의미 있는 이미지는 차원에서 특정 영역에 몰려잇거나 .. ?
-> 이 부분은 경험적으로 실험을 계속 해 볼 수 밖에 없었음.
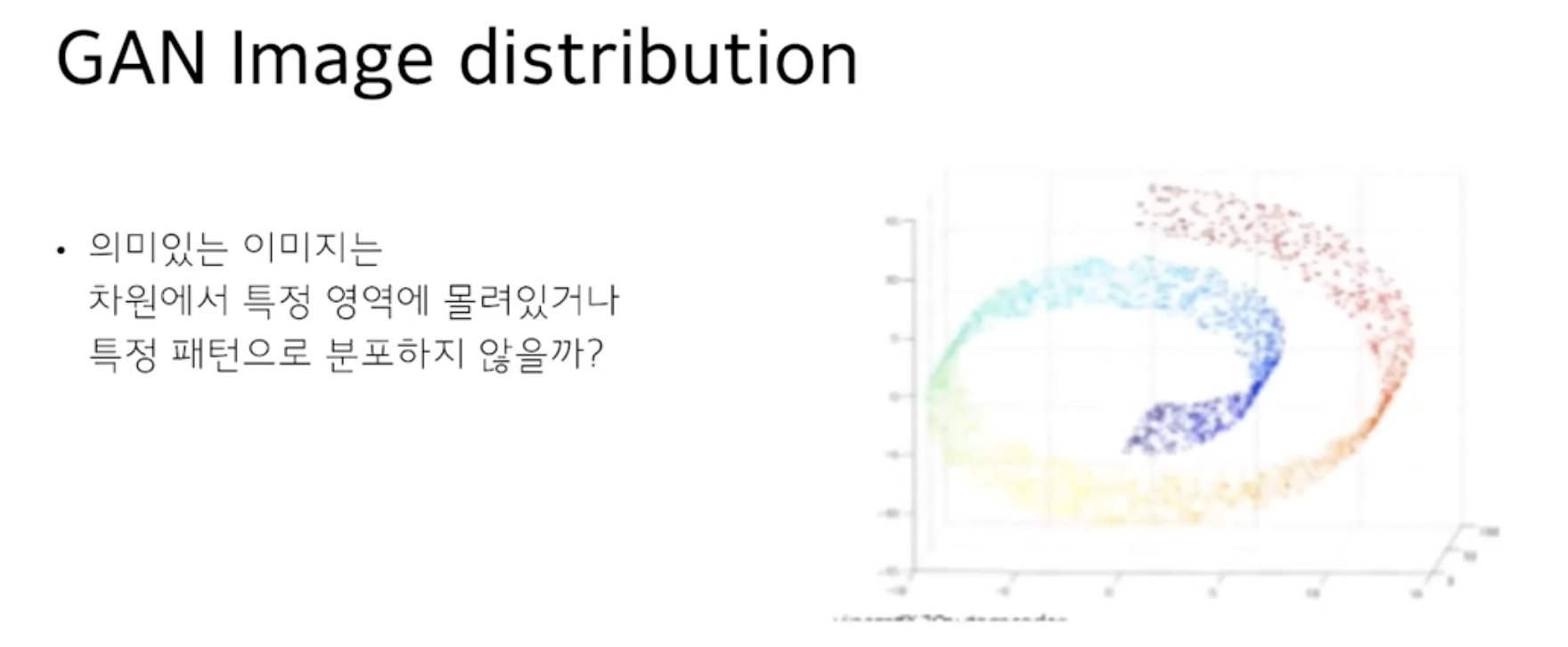
그래서 이 부분은 200x200 이미지에서 실제로 20만번 실험을 한 결과 실제로 의미 있는 이미지들은 40000차원에서 특정 패턴 또는 특정 위치에 있다고 경험적으로 결론 내릴 수 있었음.
왼쪽의 이미지가 그 결과임.
그래서 아무 의미 없어보이던 z 벡터를 의미있는 분포로 바꿔주는 게 G의 역할.
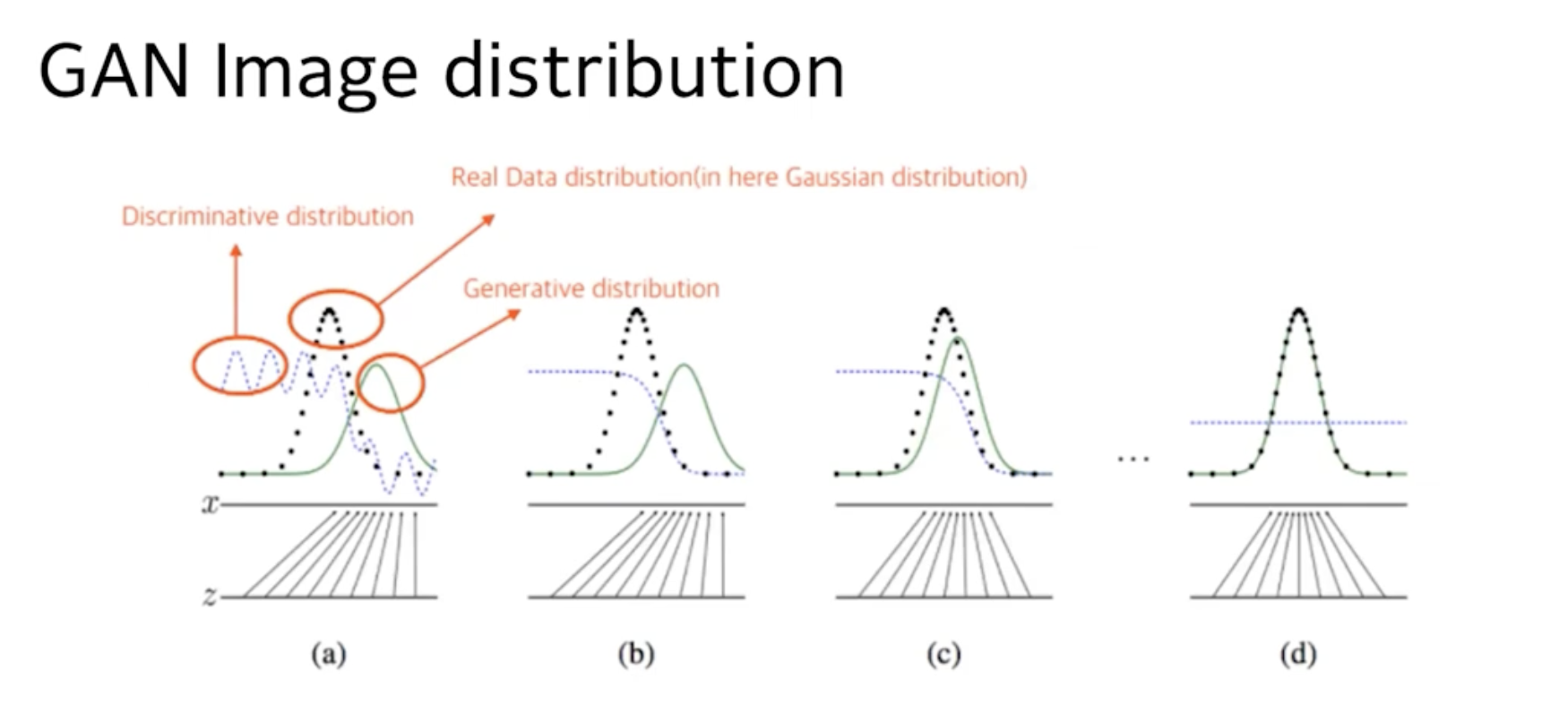
그래서 검은 점선 : real data의 분포, 초록 실선 : 생성된 데이터의 분포, 파란 점선 : 판별해내는 능력.
그래서 점점 더 생성된 데이터의 분포가 real에 가까워지고, 판별은 점점 애매모호해지는, 전부다 1이 되는 .. 수준이 되게 됨 이정도까지 되면 GAN의 훈련이 끝나는 것.
이건 좀 비주얼적으로 표현한 것.
아무것도 없던 노이즈가 점점 분포를 맞춰나가면서, 우리가 원하는 모습이 되는 것을 볼 수 있음.
CNN으로 생각을 해보면,
real image 같은 경우 여러 feature들을 인식할 수 있죠? 차근차근 내려가다보면,
반대로 이런 feature들을 생성해내면은 image를 만들어 낼 수 있어야 한다. 라는게 GAN의 개념.
