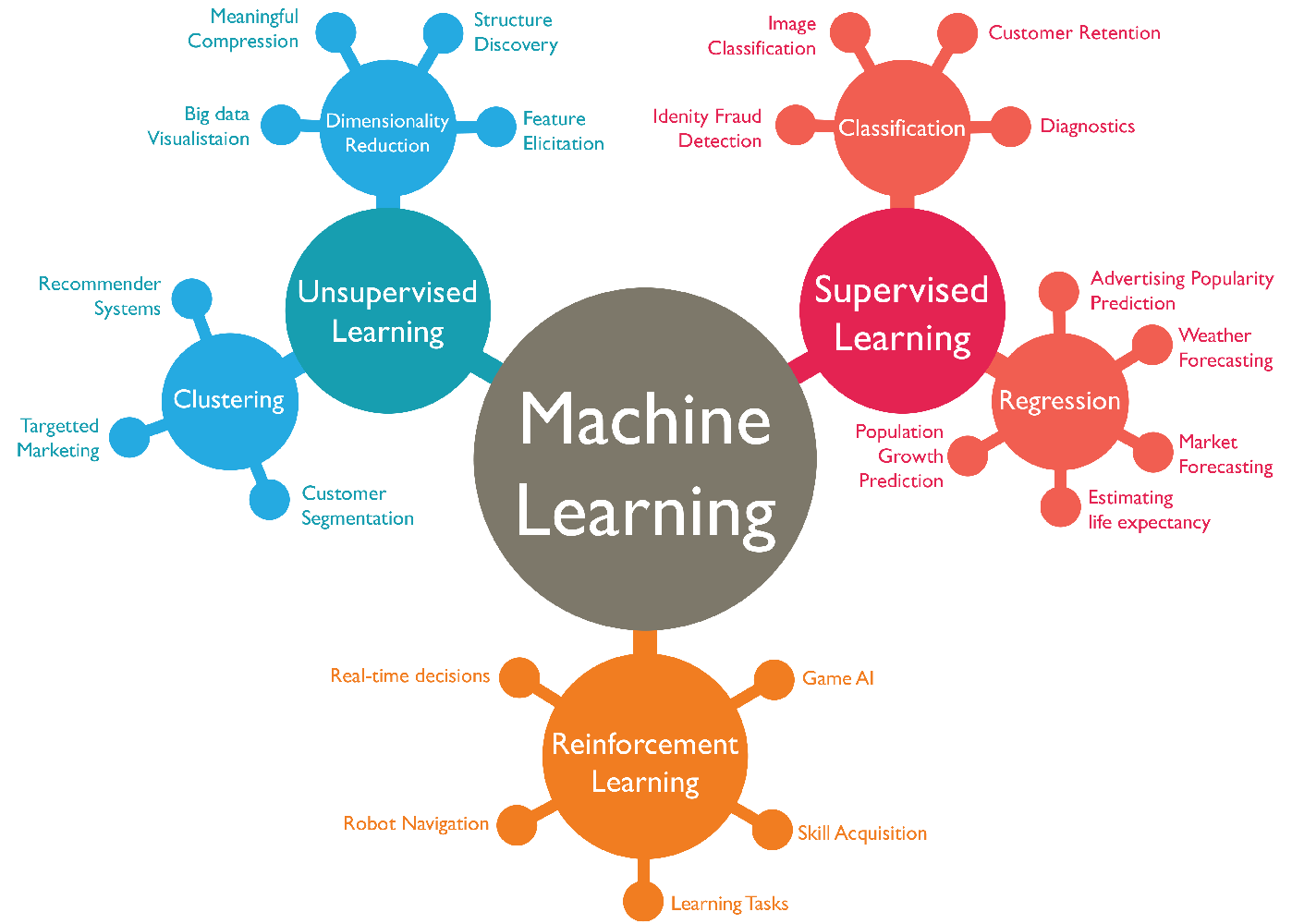
Machine Learning에서 우리가 결정해야 할 target value가 있는 상태로 학습시키는 것을 supervised learning이라고 한다. 반대로 target value가 없는 상황에서 학습을 시키는 것을 unsupervised learning이라고 한다. Unsupervised learning의 경우, target 데이터가 없기 때문에 데이터간의 연관성을 발견하여 그룹을 짓거나 연관관계를 파악하기 위하여 사용된다.
Supervised Learning에는 크게 Classification과 Regression의 두 가지가 존재한다. Unsupervised Learning은 Clustering, Dimensionality Reduction(차원 축소) 등으로 이루어진다.
그 밖에도 Reinforcement Learning(강화 학습)이 존재하는데, 이는 추후에 따로 다루기로 한다.
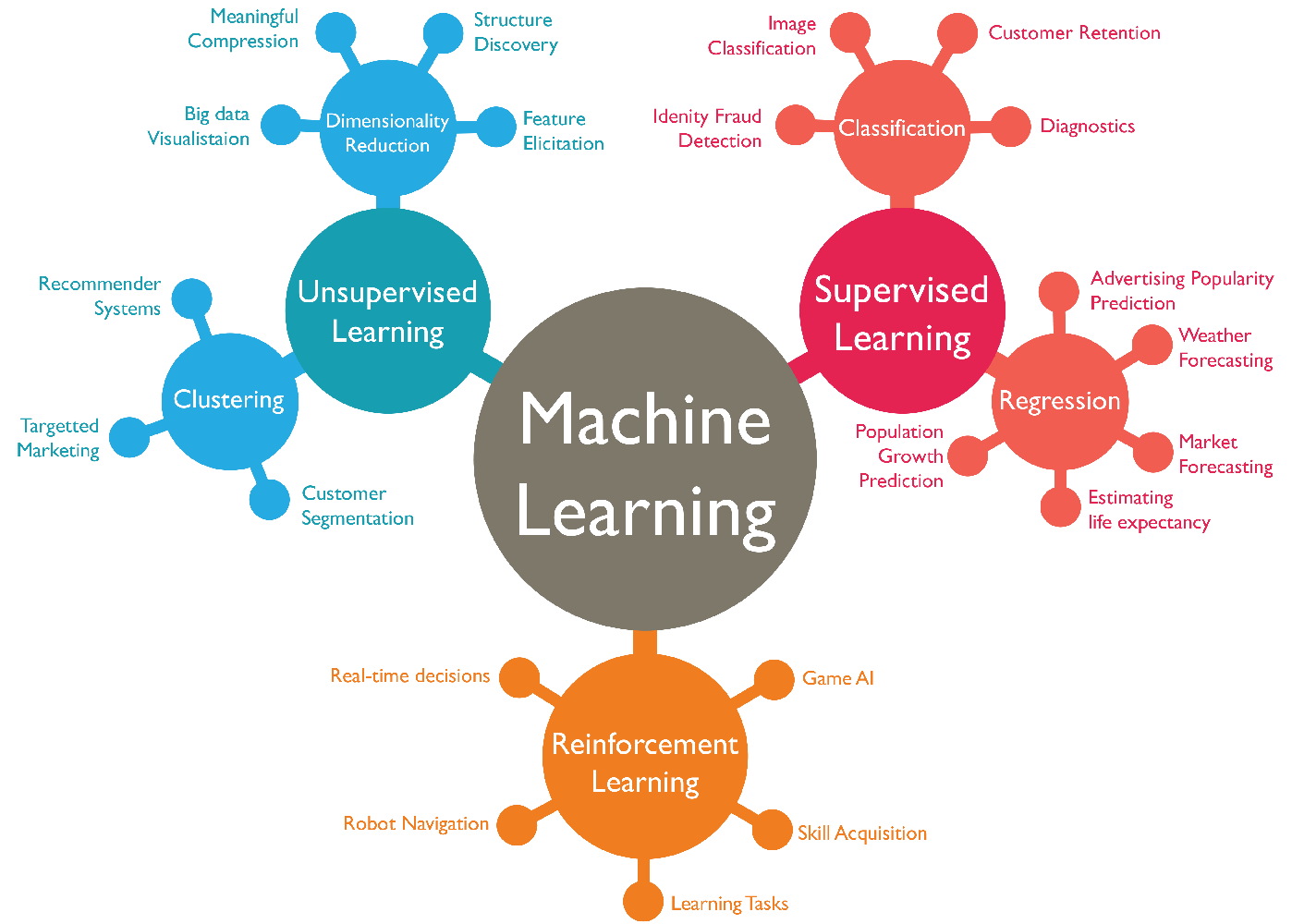
1. Supervised Learning
I. Classification
Classification이란 분류라는 한국어 해석이 직관적인 이해를 도와준다. 쉽게 말하면, 예측하는 결과값이 Categorized 할 수 있는 경우에는 Classification이다. 이 경우 예/아니오의 두 가지 결과값을 갖는 Binary Classification과(ex> Titanic Data에서 생존 여부 예측하기)
, 세 가지 이상의 결과값을 갖는 Multi-class Classification이 있다.
II. Regression
Regression은 연속적인 결과값을 가질 수 있는 경우 Regression을 사용하여 예측하게 된다. (ex> 주택 가격 예측)
2. Unsupervised Learning
I. Clustering
앞서 서술한 바와 같이, 데이터간의 연관성을 찾아 비슷한 특성을 지닌 데이터끼리 묶어주는 것을 Clustering이라고 한다. Clustering에는 K-Means, DBSCAN등의 다양한 알고리즘이 존재한다.
II. Dimensionality Reduction
차원 축소는 데이터의 양을 줄이는 방법에 관한 것이다. 차원 축소를 하는 이유는 시간 복잡도와 공간 복잡도를 줄이기 위해서나, 지나치게 많은 parameter는 overfitting의 원인이 될 수 있기 때문에 수행하곤 한다. 자세한 차원 축소의 방법에 관한 포스팅은 추후에 하도록 한다.
