서론
2025년 11월 18일, 구글이 Gemini 3를 공개했습니다. 2023년 12월 Gemini 1 출시 이후 약 2년 만에 선보이는 이번 모델은 "가장 지능적인(most intelligent) 모델"이라는 수식어와 함께 등장했습니다.
Gemini 시리즈의 세대별 진화를 살펴보면:
- Gemini 1 (2023): 네이티브 멀티모달(native multimodality)과 긴 컨텍스트 윈도우(long context window) 도입
- Gemini 2 (2024): 에이전틱 기능(agentic capabilities)과 추론(reasoning) 능력 강화
- Gemini 3 (2025): 모든 기능의 통합과 최첨단 추론 능력 제공
특히 주목할 점은 즉각적인 실용화입니다. Gemini 3 Pro는 출시 당일부터 AI Mode in Search에 적용되어 복잡한 추론과 동적 경험을 제공합니다. 이는 구글이 처음으로 출시 첫날 검색에 Gemini를 배포한 사례입니다.
💡 AI Mode in Search란?
복잡한 질문에 대해 AI가 종합적인 답변, 후속 질문, 유용한 웹 링크를 제공하는 새로운 검색 환경입니다. 사용자가 원하는 내용을 정확하게 표현하고, 여러 주제를 동시에 탐색할 수 있도록 돕습니다.
https://blog.google/intl/ko-kr/products/explore-get-answers/ai-mode-in-korean/
이번 포스팅에서는 Gemini 3의 핵심 기술, 성능 지표, 실전 활용 방법을 살펴보겠습니다.
https://blog.google/intl/ko-kr/company-news/technology/gemini-3-developers/
배경: Gemini의 진화와 AGI를 향한 여정
Gemini 프로젝트의 비전
Gemini는 구글의 Artificial General Intelligence (AGI) 달성을 향한 핵심 프로젝트입니다. Google DeepMind CEO Demis Hassabis는 Gemini 3를 "AGI를 향한 또 다른 큰 발걸음"이라고 표현했습니다.
"Today we're taking another big step on the path toward AGI and releasing Gemini 3."
현재 Gemini의 영향력:
- AI Overviews: 월 20억 사용자
- Gemini 앱: 월 6억 5천만 사용자 (전년 대비 70% 이상 증가)
- Cloud 고객: 70% 이상이 구글 AI 활용
- 개발자: 1,300만 명이 생성 모델 사용
세대별 핵심 혁신
Gemini 1 (2023): 멀티모달 기반 확립
텍스트, 이미지, 오디오, 비디오를 네이티브하게 처리하는 멀티모달 아키텍처를 도입했습니다. 긴 컨텍스트 윈도우로 대량의 정보를 처리할 수 있는 기반을 마련했습니다.

Gemini 2 (2024): 에이전트와 추론의 진화
자율적으로 복잡한 작업을 수행하는 에이전틱 워크플로우를 지원하고, 고급 추론 능력을 선보였습니다. Gemini 2.5 Pro는 LMArena에서 6개월 이상 1위를 유지하며 추론 능력의 우수성을 입증했습니다.

Gemini 3 (2025): 완전한 통합과 상황 이해
모든 기능이 통합되고, 상황과 의도 파악 능력이 "방을 읽는(reading the room)" 수준으로 향상되었습니다. 단순한 명령 수행을 넘어 맥락을 이해하고 적절히 대응합니다.

Full-Stack AI 전략의 차별점
구글의 차별화 포인트는 전 영역 통합 AI 혁신(full stack approach)입니다:
- Infrastructure: 최첨단 하드웨어 (TPU 등)
- Research & Models: 세계적 수준의 연구팀과 모델
- Tooling: AI Studio, Vertex AI 등 개발 도구
- Products: 수십억 사용자에게 도달하는 제품군
이러한 통합 접근 덕분에 고급 기능을 빠르게 전 세계에 배포할 수 있습니다.
Gemini 3 Pro의 핵심 기술
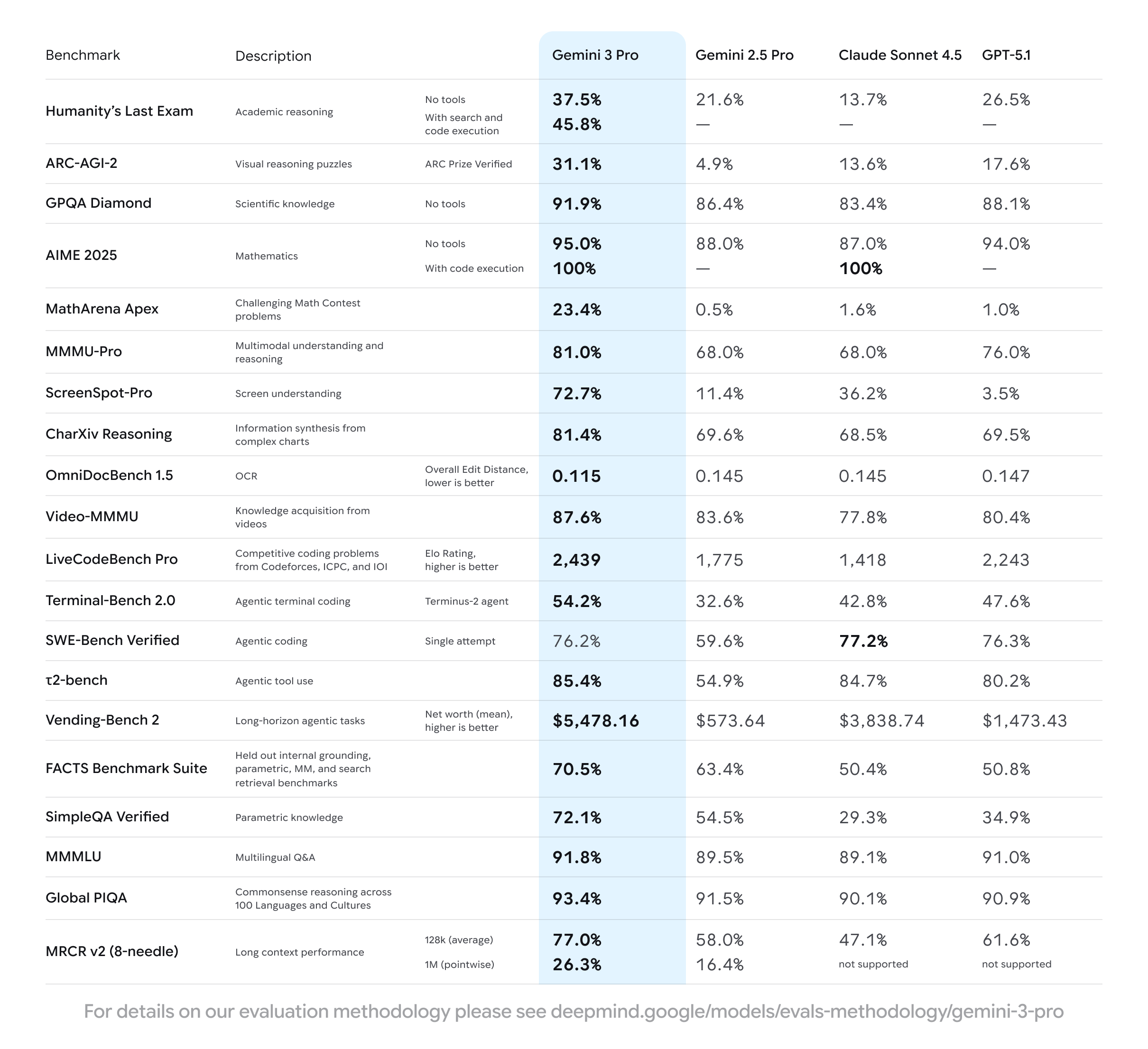
1. 최첨단 추론 능력 (State-of-the-Art Reasoning)
Gemini 3 Pro는 깊이와 뉘앙스(depth and nuance)를 파악하는 추론 능력에서 새로운 기준을 제시합니다.
{kind=link}
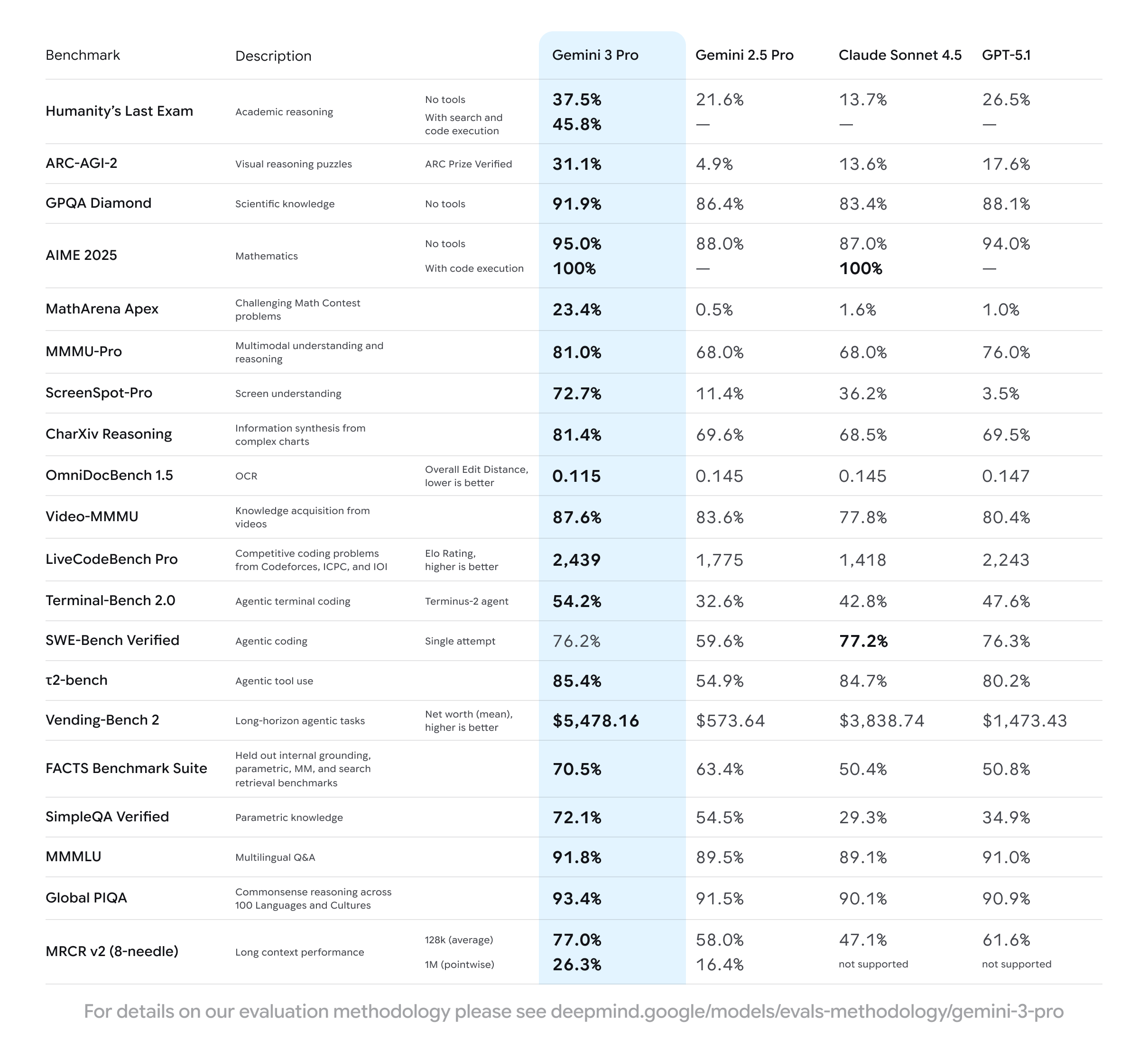
학술적 추론 (Academic Reasoning)
Humanity's Last Exam: 대학원 수준의 복잡한 학술 문제
- No tools: 37.5% (Claude 13.7%, GPT-5.1 26.5%)
- With tools: 45.8%
- 경쟁 모델 대비 2배 이상 성능 우위
GPQA Diamond: PhD 수준 과학 문제
- 91.9% (Claude 83.4%, GPT-5.1 88.1%)
- 전문 과학 지식과 추론 능력 모두 요구되는 벤치마크에서 최고 성능
수학적 추론 (Mathematical Reasoning)
AIME 2025: 미국 수학 경시대회 문제
- No tools: 95.0% (Claude 87.0%, GPT-5.1 94.0%)
- With code execution: 100%
- 고난도 수학 문제를 코드 실행 도구 활용 시 완벽하게 해결
MathArena Apex: 경쟁 수학 문제
- 23.4% (Claude 1.6%, GPT-5.1 1.0%)
- 극도로 어려운 수학 문제에서 경쟁 모델 대비 10배 이상 성능
코딩 능력 (Coding Performance)
LiveCodeBench Pro: 경쟁 프로그래밍 평가
- Elo Rating: 2,439 (Claude 1,418, GPT-5.1 2,243)
- Codeforces, ICPC, IOI 경쟁 문제 기반
SWE-Bench Verified: 실제 소프트웨어 엔지니어링
- 76.2% (Claude 77.2%, GPT-5.1 76.3%)
- GitHub 이슈 해결 작업에서 Claude와 경쟁적 성능
Terminal-Bench 2.0: 에이전틱 터미널 코딩
- 54.2% (Claude 42.8%, GPT-5.1 47.6%)
- 복잡한 터미널 작업 자율 수행 능력
지식 기반 추론 (Knowledge-Based Reasoning)
SimpleQA Verified: 파라메트릭 지식 평가
- 72.1% (Claude 29.3%, GPT-5.1 34.9%)
- 모델 내부 지식만으로 정확한 답변 생성 능력에서 2배 이상 성능
MMMLU: 다국어 종합 지식 평가
- 91.8% (Claude 89.1%, GPT-5.1 91.0%)
- 다국어 환경에서의 포괄적 지식 이해
Global PIQA: 100개 언어 상식 추론
- 93.4% (Claude 90.1%, GPT-5.1 90.9%)
- 다양한 문화권의 상식적 추론 능력
장기 맥락 처리 (Long Context Performance)
Vending-Bench 2: 장기 에이전틱 작업
- Net worth (mean): $5,478.16 (Claude $3,838.74, GPT-5.1 $1,473.43)
- 복잡한 의사결정이 필요한 장기 작업에서 최고 성능
MRCR v2: 긴 맥락 정보 검색
- 128k (average): 77.0% (Claude 47.1%, GPT-5.1 61.6%)
- 1M (pointwise): 26.3% (Claude/GPT-5.1 미지원)
- Needle-in-a-haystack 정보 검색 능력
2. 멀티모달 이해의 새로운 지평
시각적 추론 (Visual Reasoning)
ARC-AGI-2: 시각적 추론 퍼즐
- 31.1% (Claude 13.6%, GPT-5.1 17.6%)
- ARC Prize 검증 방식 기반 일반 지능 측정에서 압도적 우위
ScreenSpot-Pro: 화면 이해 능력
- 72.7% (Claude 36.2%, GPT-5.1 3.5%)
- UI 요소 인식 및 화면 구조 이해에서 Claude 대비 2배, GPT-5.1 대비 20배 성능
MMMU-Pro: 복잡한 이미지 추론
- 81.0% (Claude 68.0%, GPT-5.1 76.0%)
- 이미지와 텍스트를 통합한 전문가 수준 문제 해결
실용 사례:
- 손으로 쓴 다국어 레시피 해독 및 번역으로 가족 요리책 생성
- 학술 논문 분석 후 인터랙티브 플래시카드 자동 생성
공간 추론 (Spatial Reasoning)
Gemini 3는 공간 이해(spatial understanding) 능력이 크게 향상되었습니다.
핵심 작업:
- 포인팅(Pointing): 3D 공간에서 객체의 정확한 위치 및 방향 식별
- 궤적 예측(Trajectory Prediction): 움직이는 객체의 미래 경로 분석
- 작업 진행 파악: 로봇 작업의 완료도 평가 및 다음 단계 제안
활용 분야:
- 자율주행: 실시간 장애물 감지 및 경로 예측
- XR 기기: 공간 매핑 및 제스처 인식
- 로보틱스: 최적 경로 계획 및 정밀 제어
컴퓨터 사용 에이전트 개선:
데스크톱, 모바일, OS 화면을 지능적으로 이해하여 컴퓨터 사용 에이전트의 성능을 크게 향상시켰습니다.
- 화면 요소의 정확한 인식
- 마우스 움직임과 제스처를 통한 사용자 의도 파악
- 컨텍스트 기반 능동적 작업 수행
비디오 추론 (Video Reasoning)
Video-MMMU: 비디오 이해 벤치마크
- 87.6% (Claude 77.8%, GPT-5.1 80.4%)
- 시간적 맥락 이해 및 지식 습득 능력
고프레임 속도 이해:
- 빠른 동작 포착 능력 향상
- 스포츠 경기, 빠르게 움직이는 장면에서 중요 순간 감지
긴 컨텍스트 회상:
- 수 시간 분량의 연속 영상 분석
- 서사 종합 및 특정 세부 사항 정확 검색
실제 예시:
사용자가 "내 피클볼 경기 영상을 분석해서 개선점을 찾아줘"라고 요청하면:
1. 백핸드 스윙 시 팔꿈치 각도 분석
2. 네트 플레이 반응 속도 평가
3. 발놀림 패턴 확인
4. 맞춤형 훈련 플랜 생성
문서 이해 (Document Understanding)
OmniDocBench 1.5: OCR 정확도
- Overall Edit Distance: 0.115 (Claude 0.145, GPT-5.1 0.147)
- 복잡한 문서의 텍스트 추출 및 이해 성능에서 최고 정확도
CharXiv Reasoning: 복잡한 차트 분석
- 81.4% (Claude 68.5%, GPT-5.1 69.5%)
- 학술 논문 수준의 차트에서 정보 합성 및 추론
1백만 토큰 컨텍스트 윈도우
Gemini 3는 100만 토큰의 컨텍스트를 지원합니다:
- 긴 학술 논문 여러 편 동시 분석
- 긴 비디오 강의나 튜토리얼 전체 처리
- 대규모 코드베이스 전체 이해
3. 깊이 있는 상호작용 (Depth and Nuance)
Gemini 3 Pro의 응답 방식이 진화했습니다.
이전 모델들의 특징:
- 상투적 표현과 과도한 칭찬
- "듣고 싶은 말" 중심
Gemini 3 Pro의 특징:
- 직설적이고 간결한 응답
- "필요한 말"을 전달하는 진정한 사고 파트너(thought partner)
- 진정성 있는 통찰 제공
실제 활용 예시:
토카막 플라즈마 시각화 요청 시:
# 사용자: "토카막에서 플라즈마 흐름을 시각화해줘"
# Gemini 3 Pro의 응답:
"""
토카막(tokamak) 플라즈마의 나선형 흐름을 시각화하는 코드를 생성하겠습니다.
이 시각화는 자기장이 플라즈마를 어떻게 가두는지 보여줍니다.
나선형 경로는 하전입자가 자기력선을 따라 움직이는 것을 나타냅니다.
"""⚛️ 토카막 (Tokamak)이란?
핵융합 발전을 위한 도넛 모양의 자기 가두기 장치입니다.
- 목적: 태양에서 일어나는 핵융합 반응을 지구에서 재현
- 원리: 초고온 플라즈마(1억도 이상)를 자기장으로 가둬 핵융합 반응 유도
- 형태: 도넛(토러스, torus) 모양의 진공 용기

Gemini 3는 복잡한 과학 개념을 고충실도(high-fidelity) 시각화로 변환하고, 물리학을 담은 시를 작성하는 등 창의적 브레인스토밍 파트너 역할을 합니다.
4. Gemini 3 Deep Think: 추론의 극대화
Deep Think는 Gemini 3의 추론 능력을 한 단계 더 끌어올린 특별 모드입니다.
Deep Think의 작동 원리
확장된 추론 시간 (Extended Reasoning Time):
- 일반 모드: 즉각적 응답 생성
- Deep Think: 문제를 더 오래 "생각"하여 정교한 답변 도출
- 원리: Chain-of-Thought와 유사하지만 더 깊고 반복적인 추론 과정
멀티모달 이해 강화:
- 텍스트, 이미지, 코드를 통합적으로 분석
- 복잡한 시각적 패턴 인식 능력 대폭 향상
- 추상적 개념과 구체적 데이터의 연결 강화
Deep Think의 성능
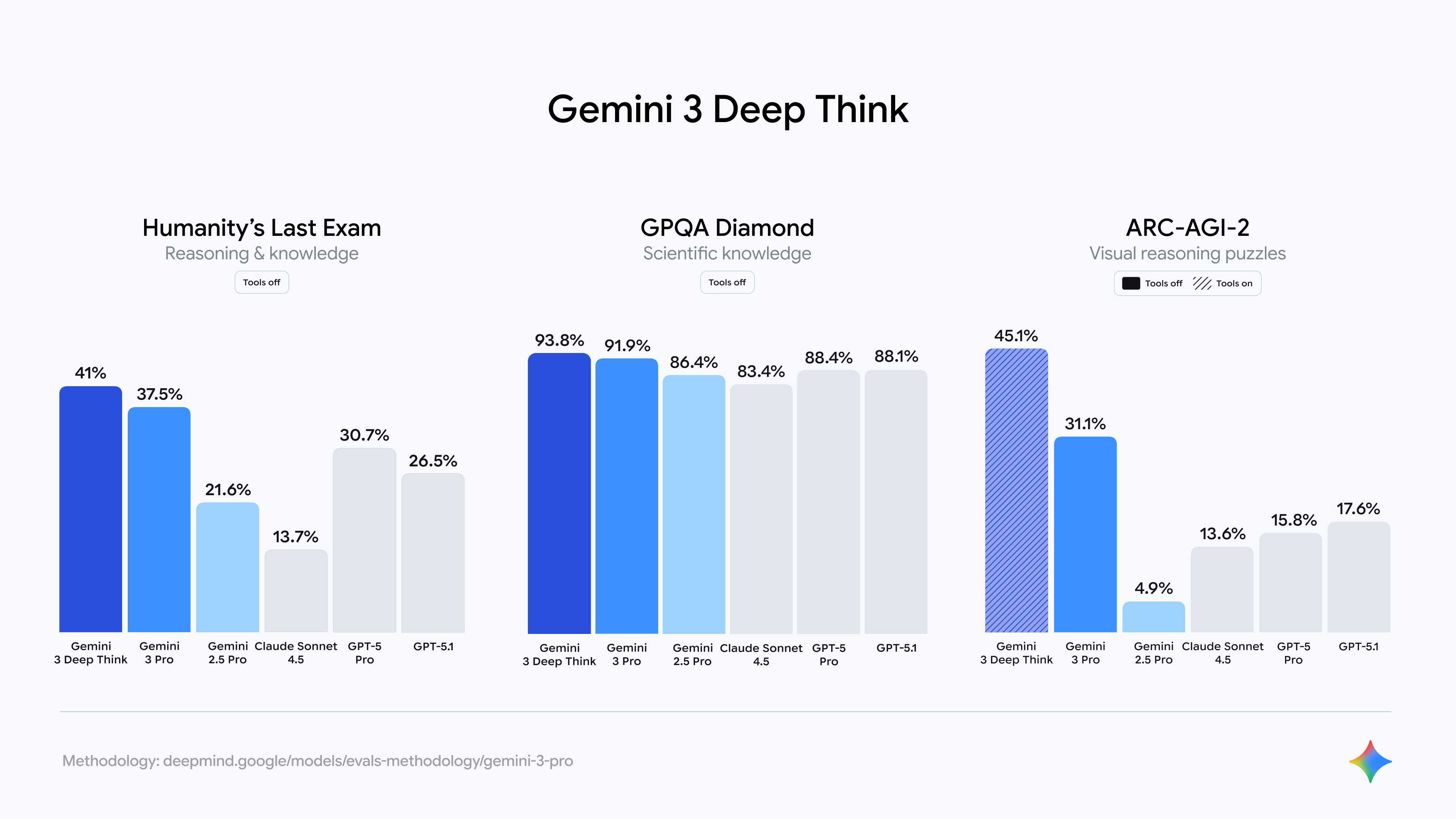
https://blog.google/products/gemini/gemini-3/#gemini-3-deep-think
| 벤치마크 | 일반 모드 | Deep Think | 향상률 | 특징 |
|---|---|---|---|---|
| Humanity's Last Exam | 37.5% | 41.0% | +9.3% | 복합 추론 |
| GPQA Diamond | 91.9% | 93.8% | +2.1% | 전문 지식 |
| ARC-AGI-2 | 31.1% | 45.1% | +45.0% | 새로운 문제 해결 |
핵심 인사이트:
- 지식 기반 문제 (GPQA): 상대적으로 작은 향상 (이미 높은 수준)
- 추론 기반 문제 (ARC-AGI): 가장 극적인 향상 (깊은 사고의 효과)
Deep Think 모드는 현재 안전성 테스터들에게 제공되며, 곧 Google AI Ultra 구독자에게 공개될 예정입니다.
5. 광범위한 언어 지원
Gemini 3는 다국어 성능에서도 선도적입니다:
- 주요 언어에서 최고 수준의 이해와 생성 능력
- 문화적 뉘앙스와 맥락 정확한 파악
개발자를 위한 실전 활용
1. 에이전틱 코딩의 새로운 가능성
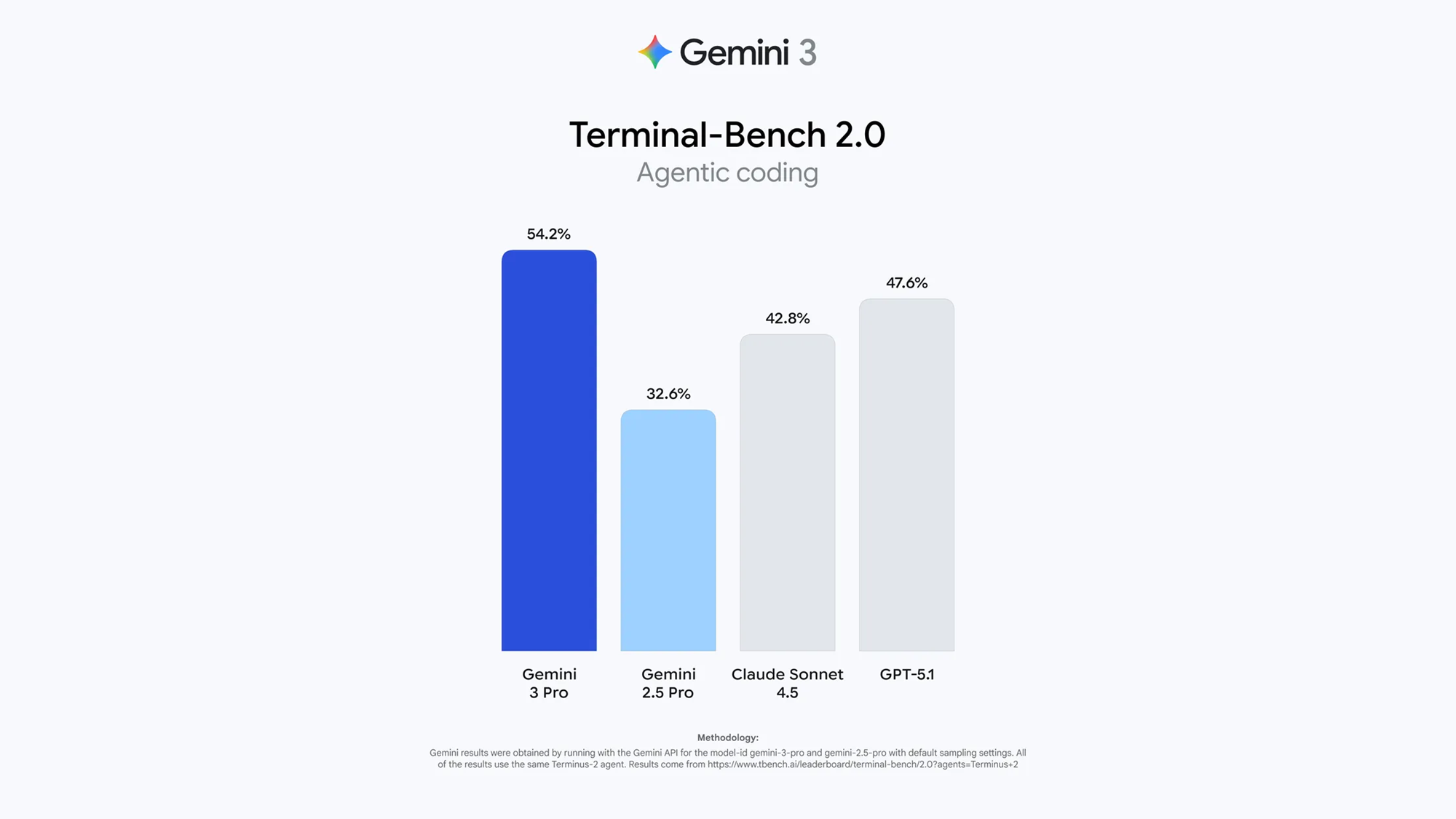
Terminal-Bench 2.0 성능:
- 54.2% 달성 (Claude 42.8%, GPT-5.1 47.6%)
- 터미널을 통한 컴퓨터 제어 능력 측정
- 자율적으로 복잡한 소프트웨어 작업 수행
SWE-bench Verified:
- 76.2% 달성
- 실제 소프트웨어 엔지니어링 벤치마크
- Gemini 2.5 Pro 대비 대폭 향상
적용 제품:
- Google Antigravity: 구글의 새로운 에이전트 개발 플랫폼
- Gemini CLI: 명령줄 인터페이스
- Android Studio: 안드로이드 앱 개발
- 서드 파티: Cursor, GitHub, JetBrains, Manus, Cline 등
Cline 개발자의 평가:
"Gemini 3 Pro는 전체 코드베이스에서 복잡하고 장기적인 작업을 처리하며, 다중 파일 리팩토링, 디버깅 세션, 기능 구현 전반에 걸쳐 컨텍스트를 유지합니다. Gemini 2.5 Pro보다 긴 컨텍스트를 훨씬 더 효과적으로 활용합니다."
- 닉 패시(Nik Pash), 클라인(Cline) AI 총괄
2. Google Antigravity: 새로운 에이전트 개발 플랫폼

핵심 개념:
- 작업 중심(Task-Oriented) 개발: 높은 수준의 과제 정의
- 자율 에이전트: 에디터, 터미널, 브라우저를 넘나들며 작업 수행
- 익숙한 IDE: 핵심 AI IDE 경험은 그대로 유지
작동 방식:
- 개발자가 설계자(architect) 역할 수행
- 지능형 에이전트가 복잡한 작업을 계획 및 실행
- 상세한 산출물로 작업 내용 소통
- 에이전트가 자체 코드 검증
지원 기능:
- 기능 구축 및 UI 반복 작업
- 버그 수정 및 디버깅
- 조사 및 보고서 생성
- 브라우저 기반 컴퓨터 사용을 통한 검증
가용성:
- MacOS, Windows, Linux용 퍼블릭 프리뷰
- 무료 다운로드 가능
3. Gemini API의 새로운 기능
클라이언트 사이드 배시 툴 (Client-Side Bash Tool)
모델이 명령줄을 통해 직접 쉘 명령어를 제안할 수 있습니다.
활용 사례:
- 로컬 파일 시스템 탐색
- 개발 프로세스 구동
- 시스템 작업 자동화
서버 사이드 배시 툴 (Server-Side Bash Tool)
호스팅된 샌드박스에서 명령 실행:
- 로컬 설정 불필요
- 다국어 프로토타이핑
- 안전한 데이터 실험 환경
현재 상태:
- 얼리 액세스 파트너 대상 제공
- 곧 일반 공개 예정
구조화된 출력 (Structured Output)과 통합
Google Search Grounding과 URL 컨텍스트를 구조화된 출력과 결합할 수 있습니다.
워크플로우 예시:
# 의사 코드 (pseudocode)
1. 데이터 가져오기 (Google Search / URL)
2. 정보 추출 및 분석
3. 특정 형식으로 출력 (JSON, CSV 등)
4. 후속 에이전트 작업에 활용데이터 수집 → 처리 → 활용의 전체 파이프라인을 자동화하는 강력한 기능입니다.
4. 바이브 코딩 (Vibe Coding)의 실현

https://blog.google/intl/ko-kr/company-news/technology/gemini-3-developers/
바이브 코딩이란?
자연어가 유일한 문법이 되는 프로그래밍 방식
WebDev Arena 성능:
- 1487 Elo (1위)
- 웹 개발 능력 측정 벤치마크
핵심 개선 사항:
1. 복잡한 지시사항 수행: 다단계 계획 자동 처리
2. 심층 툴 사용: 필요한 도구 자동 선택 및 활용
3. 단일 프롬프트 생성: 하나의 요청으로 완전한 앱 생성
실제 예시:
사용자: "우주선이 날아다니는 레트로 3D 게임을 만들어줘"
Gemini 3가 생성:
- 3D 렌더링 엔진
- 물리 엔진 (충돌, 중력)
- 사용자 입력 처리 (키보드, 마우스)
- 점수 시스템 및 게임 로직
- 완전히 작동하는 게임
Emergent 공동창업자의 평가:
"Gemini 3의 뛰어난 프롬프트 준수(prompt adherence) 능력은 풀스택 앱 개발, 특히 UI/프론트엔드 워크플로우를 크게 향상시킵니다."
- 마다브 자(Madhav Jha), 이머전트(Emergent) 공동 창업자 겸 CTO
5. Google AI Studio
핵심 특징:
빌드 모드(Build Mode):
- 적절한 모델과 API 자동 연결
빠른 반복:
- 주석(annotations) 등으로 직관적 수정

제로샷 앱 생성:
- 단일 프롬프트로 완성된 앱
"I'm feeling lucky" 기능:
- 버튼 클릭 하나로 창의적 영감과 코드 구현 동시 제공
- Gemini 3가 알아서 판단하여 앱 생성
6. 멀티모달 기능 세부 설정
비전 토큰 구성 (Vision Token Configuration)
시각적 충실도 제어: 필요한 시각적 충실도(visual fidelity) 수준에 따라 비전 토큰 사용량을 조절할 수 있습니다.
제어 가능한 요소:
- 지연 시간: 빠른 응답과 정밀 분석 간 균형
- 비용: 토큰 수에 따른 비용 최적화
- 해상도: 작업별 적절한 이미지 품질 선택
활용 시나리오:
| 작업 유형 | 권장 설정 | 특징 |
|---|---|---|
| 빠른 분류/태깅 | 낮은 충실도 | 속도 우선, 기본 패턴 인식 |
| 문서 OCR | 중간 충실도 | 텍스트 가독성 확보 |
| 세밀한 시각 분석 | 높은 충실도 | 디테일 중요 작업 |
| 의료 영상 분석 | 최고 충실도 | 진단 정확도 필수 |
참고: https://ai.google.dev/gemini-api/docs/gemini-3?thinking=high&hl=ko#media_resolution
문서 이해의 진화
OmniDocBench 1.5 성능:
- Overall Edit Distance: 0.115 (Claude 0.145, GPT-5.1 0.147 대비 최고)
핵심 능력:
- 복잡한 레이아웃 분석 (다단 구성, 표, 그래프)
- 맥락적 정보 추출 (단순 텍스트 인식 초월)
- 논리적 구조 파악 (문서 흐름, 섹션 관계)
- 다국어 문서 처리
이미지에서 앱으로
단 한 장의 이미지로 Gemini 3 Pro는 시각적 이해, 추론, 코딩 능력을 결합해 즉시 작동하는 인터랙티브 앱을 생성할 수 있습니다.
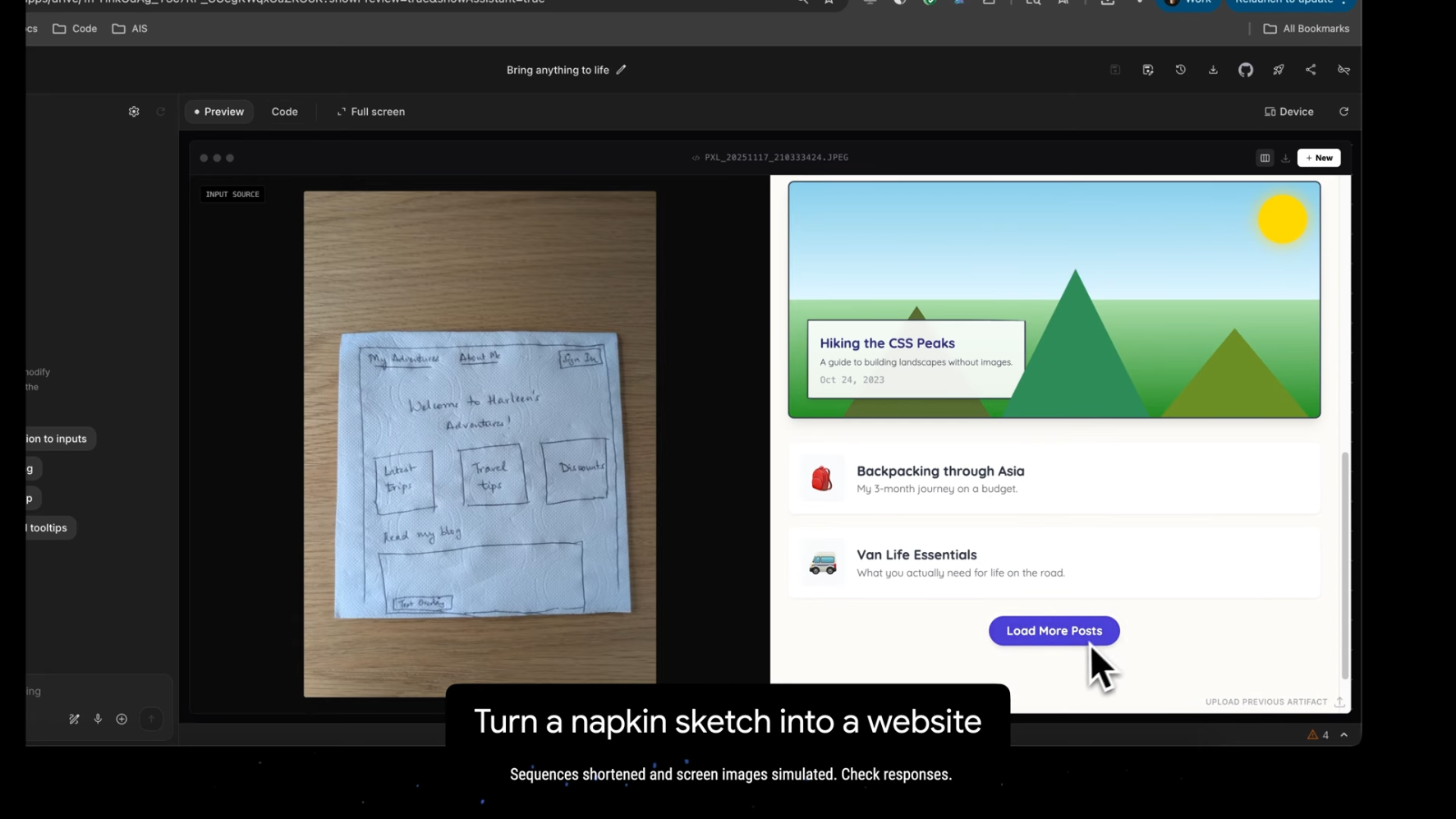
손으로 그린 UI 스케치에서 실제 작동하는 웹 애플리케이션까지 구현 가능합니다.
공간 추론의 활용
핵심 작업:
- 포인팅: 3D 공간에서 객체의 정확한 위치 및 방향 식별
- 궤적 예측: 움직이는 객체의 미래 경로와 상호작용 분석
- 작업 진행: 로봇 작업의 완료도 평가 및 다음 단계 제안
활용 분야:
- 자율주행 차량: 실시간 장애물 감지 및 궤적 예측, 위험도 평가
- XR 기기: 실시간 공간 매핑 및 환경 이해, 제스처 인식
- 로보틱스: 작업 공간 이해 및 최적 경로 계획
Visual Computer 데모: 사용자가 손으로 그린 명령을 파악하는 것을 넘어, 화면 구성요소에 대한 깊은 이해를 기반으로 명령을 능동적이고 지능적으로 처리합니다.
비디오 분석의 진화
고프레임 처리: 높은 프레임 속도의 이해력을 바탕으로 재빠른 동작을 포착해, 빠르게 움직이는 장면에서 중요한 순간을 놓치지 않습니다.
긴 컨텍스트 분석:
- 몇 시간 분량의 연속 영상에서 서사 종합
- 특정 장면 및 세부 사항 정확한 검색
- 전체 맥락 유지하며 긴 컨텍스트 회상
OpusClip의 실제 성과:
OpusClip CTO Jay Wu의 평가에 따르면 에이전트 기반 비디오 워크플로우에서:
1. 속도: 기존 구현 대비 32% 이상 증가
2. 정밀성: 복잡한 지침 준수 및 구조화된 디코딩
3. 신뢰성: 환각 없이 긴 컨텍스트 추론 관리
"제미나이 3는 속도(32% 증가), 정밀성(복잡한 지침 및 구조화된 디코딩), 신뢰성(긴 컨텍스트 추론 및 세분화된 툴 호출) 세 가지 측면에서 뛰어납니다."
— Jay Wu, OpusClip 공동 창업자 겸 CTO
7. 가격 및 가용성
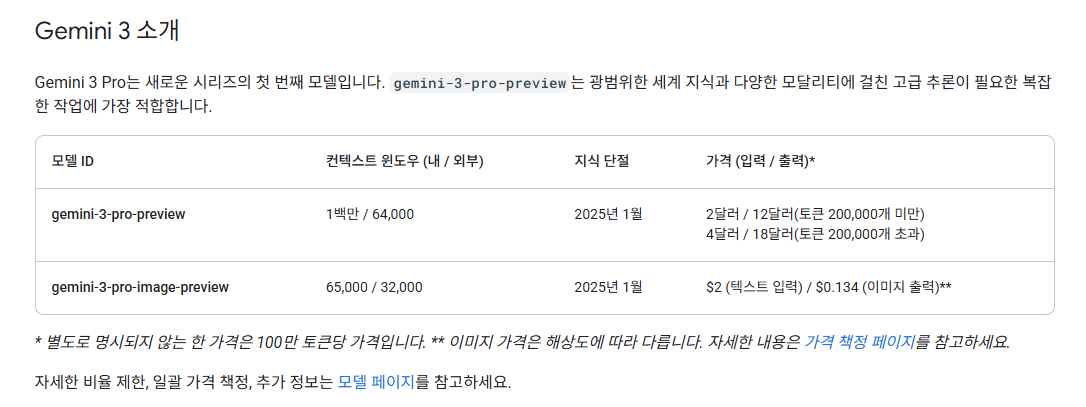
https://ai.google.dev/gemini-api/docs/gemini-3?hl=ko&thinking=high
8. API 세부 제어 파라미터
Gemini 3에는 개발자가 지연 시간, 비용, 멀티모달 충실도를 효과적으로 제어할 수 있도록 설계된 새로운 파라미터가 도입되었습니다.
사고 수준 (Thinking Level)
thinking_level 파라미터는 모델이 대답을 생성하기 전의 내부 추론 프로세스의 최대 깊이를 제어합니다.
핵심 개념:
- Gemini 3는 이러한 수준을 엄격한 토큰 보장이 아닌 사고를 위한 상대적 허용치로 취급합니다
- 지정되지 않은 경우 Gemini 3 Pro는 기본적으로
high로 설정됩니다
설정 옵션:
| 수준 | 특징 | 권장 사용 사례 |
|---|---|---|
low | 지연 시간과 비용 최소화 | 간단한 안내 따르기, 채팅, 고처리량 애플리케이션 |
medium | (출시 예정) | 출시 시 지원되지 않음 |
high (기본값) | 추론 깊이 최대화 | 복잡한 문제 해결, 고급 추론 필요 작업 |
실용적 의미:
high설정에서는 모델이 첫 번째 토큰에 도달하는 데 시간이 훨씬 더 오래 걸릴 수 있지만 출력은 더 신중하게 추론됩니다- 복잡한 추론이 필요하지 않은 경우 더 빠르고 지연 시간이 짧은 응답을 위해 모델의 사고 수준을
low로 제한할 수 있습니다
코드 예시:
from google import genai
from google.genai import types
client = genai.Client()
# 복잡한 추론 작업 - high (기본값)
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents="Find the race condition in this multi-threaded C++ snippet: [code here]",
# thinking_level은 기본값 'high'
)
# 간단한 작업 - low로 설정하여 속도 향상
response_fast = client.models.generate_content(
model="gemini-3-pro-preview",
contents="What is the capital of France?",
config=types.GenerateContentConfig(
thinking_level="low"
)
)
https://ai.google.dev/gemini-api/docs/gemini-3?hl=ko&thinking=high
미디어 해상도 (Media Resolution)
media_resolution 매개변수를 통해 멀티모달 시각 처리의 세부적인 제어를 도입합니다.
핵심 개념:
- 해상도가 높을수록 미세한 텍스트를 읽거나 작은 세부정보를 식별하는 모델의 능력이 향상되지만, 토큰 사용량과 지연 시간이 증가합니다
media_resolution파라미터는 입력 이미지 또는 동영상 프레임당 할당되는 최대 토큰 수를 결정합니다
설정 옵션 및 권장 사용법:
| 미디어 유형 | 권장 설정 | 최대 토큰 수 | 사용 안내 |
|---|---|---|---|
| 이미지 (일반) | media_resolution_high | 1120 | 최고의 품질을 보장하기 위해 대부분의 이미지 분석 작업에 권장 |
| 문서 OCR | media_resolution_medium | 560 | 문서 이해에 최적화. high로 늘려도 표준 문서의 OCR 결과가 개선되는 경우는 거의 없음 |
| 동영상 (일반) | media_resolution_low | 70 (프레임당) | 대부분의 동작 인식 및 설명 작업에 충분. low와 medium 설정이 동일하게 처리됨 |
| 동영상 (텍스트 중심) | media_resolution_high | 280 (프레임당) | 밀도 높은 텍스트(OCR) 또는 작은 세부정보를 읽는 작업이 포함된 경우에만 필요 |
유연한 설정:
- 개별 미디어 파트별로 설정 가능
- 전역적으로 (
generation_config를 통해) 설정 가능 - 지정하지 않으면 모델에서 미디어 유형에 따라 최적의 기본값 사용
코드 예시:
from google import genai
from google.genai import types
import base64
# v1alpha API 버전 사용 필요
client = genai.Client(http_options={'api_version': 'v1alpha'})
# 고해상도 이미지 분석
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents=[
types.Content(
parts=[
types.Part(text="What is in this image?"),
types.Part(
inline_data=types.Blob(
mime_type="image/jpeg",
data=base64.b64decode("..."),
),
media_resolution={"level": "media_resolution_high"} # 고해상도
)
]
)
]
)
print(response.text)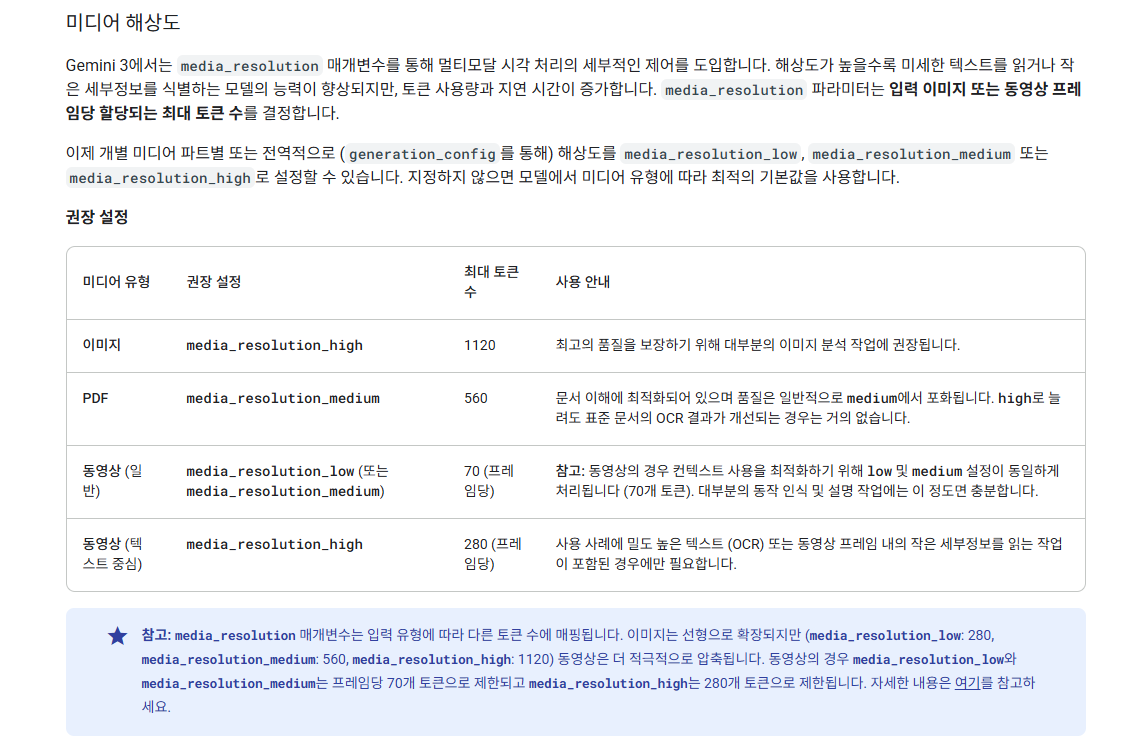
https://ai.google.dev/gemini-api/docs/gemini-3?hl=ko&thinking=high
생각 서명 (Thought Signatures)
Gemini 3는 사고 서명을 사용하여 API 호출 전반에서 추론 컨텍스트를 유지합니다.
핵심 개념:
- 이러한 서명은 모델의 내부 사고 과정을 암호화한 표현입니다
- 모델이 추론 기능을 유지하도록 하려면 요청에서 이러한 서명을 수신된 그대로 모델에 다시 반환해야 합니다
검증 수준:
| 작업 유형 | 검증 엄격도 | 영향 |
|---|---|---|
| 함수 호출 | 엄격 | API는 '현재 턴'에 엄격한 검증을 적용합니다. 서명이 누락되면 400 오류가 발생합니다 |
| 텍스트/채팅 | 유연 | 검증이 엄격하게 적용되지는 않지만 서명을 누락하면 모델의 추론 및 대답 품질이 저하됩니다 |
함수 호출 시나리오:
Gemini가 functionCall을 생성할 때 다음 턴에서 도구의 출력을 올바르게 처리하기 위해 thoughtSignature를 사용합니다. '현재 턴'에는 마지막 표준 사용자 text 메시지 이후에 발생한 모든 모델(functionCall) 및 사용자(functionResponse) 단계가 포함됩니다.
- 단일 함수 호출:
functionCall부분에 서명이 포함되어 있으며, 반드시 반환해야 함 - 병렬 함수 호출: 목록의 첫 번째
functionCall부분에만 서명이 포함됨. 받은 순서대로 정확하게 반환해야 함 - 다단계(순차적): 모델이 여러 도구를 순차적으로 호출하는 경우, 각 함수 호출에 서명이 있으며 모든 서명을 누적하여 반환해야 함
코드 예시 - 다단계 함수 호출:
// 1단계: 모델이 항공편 도구를 호출
{
"role": "model",
"parts": [{
"functionCall": {
"name": "check_flight",
"args": {...}
},
"thoughtSignature": "<Sig_A>" // 저장 필요
}]
}
// 2단계: 사용자가 항공편 결과를 전송 (Sig_A 포함해야 함)
[
{
"role": "user",
"parts": [{ "text": "Check flight AA100..." }]
},
{
"role": "model",
"parts": [{
"functionCall": {
"name": "check_flight",
"args": {...}
},
"thoughtSignature": "<Sig_A>" // 필수
}]
},
{
"role": "user",
"parts": [{
"functionResponse": {
"name": "check_flight",
"response": {...}
}
}]
}
]
// 3단계: 모델이 택시 도구를 호출 (새 서명 생성)
{
"role": "model",
"parts": [{
"functionCall": {
"name": "book_taxi",
"args": {...}
},
"thoughtSignature": "<Sig_B>" // 저장 필요
}]
}
// 4단계: 사용자가 택시 결과를 전송 (전체 체인 필요)
[
// ... 이전 history ...
{
"role": "model",
"parts": [{
"functionCall": { "name": "check_flight", ... },
"thoughtSignature": "<Sig_A>" // 첫 번째 서명
}]
},
{ "role": "user", "parts": [{ "functionResponse": {...} }] },
{
"role": "model",
"parts": [{
"functionCall": { "name": "book_taxi", ... },
"thoughtSignature": "<Sig_B>" // 두 번째 서명
}]
},
{ "role": "user", "parts": [{ "functionResponse": {...} }] }
]특수 케이스 - 다른 모델에서 이전:
다른 모델(예: Gemini 2.5)을 사용하거나 Gemini 3에서 생성되지 않은 맞춤 함수 호출을 삽입하면 유효한 서명이 없습니다. 이러한 특정 시나리오에서 엄격한 유효성 검사를 우회하려면 필드를 다음 특정 더미 문자열로 채우세요: "thoughtSignature": "context_engineering_is_the_way_to_go"

https://ai.google.dev/gemini-api/docs/gemini-3?hl=ko&thinking=high
온도 설정 주의사항
Gemini 3의 경우 temperature 매개변수를 기본값인 1.0로 유지하는 것이 좋습니다.
중요 포인트:
- 이전 모델에서는 창의성과 결정론을 제어하기 위해 온도를 조정하는 것이 유용한 경우가 많았지만, Gemini 3의 추론 기능은 기본 설정에 최적화되어 있습니다
- 온도를 변경하면(1.0 미만으로 설정) 특히 복잡한 수학 또는 추론 작업에서 루핑이나 성능 저하와 같은 예기치 않은 동작이 발생할 수 있습니다
실전 활용 사례
1. 학습 도구: Learn Anything
가족 레시피 디지털화

할머니의 손글씨 레시피 사진을 업로드하면:
1. 손글씨 OCR 및 언어 감지
2. 다국어 번역 (필요시)
3. 레시피 형식 표준화
4. 요리 팁 추가
5. 공유 가능한 디지털 책 생성학술 자료 학습
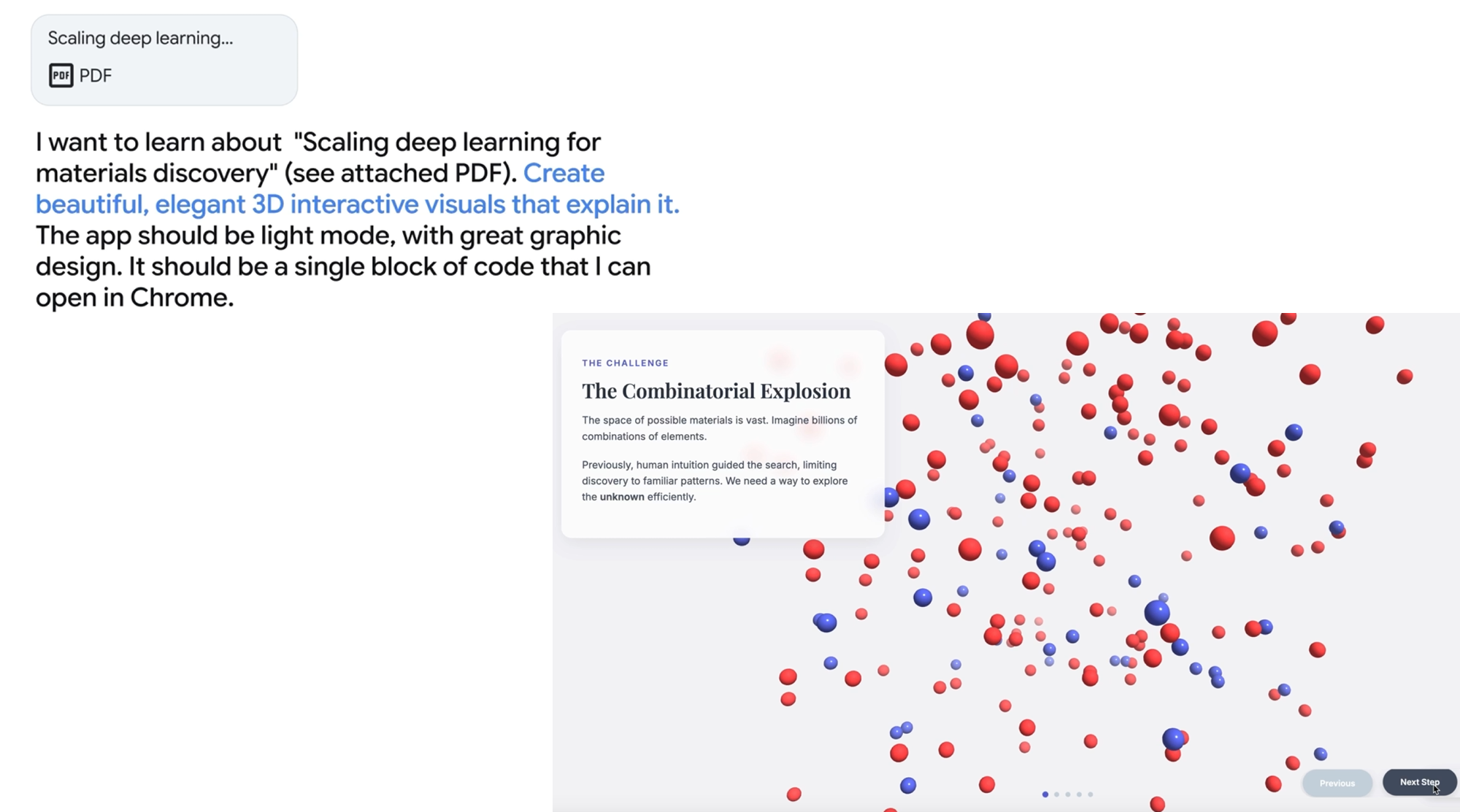
머신러닝 논문과 3시간짜리 강의 영상을 기반으로:
1. 핵심 개념 추출
2. 개념 간 연결고리 파악
3. 난이도별 질문 생성
4. 인터랙티브 시각화 포함
5. 복습 알고리즘 적용스포츠 분석
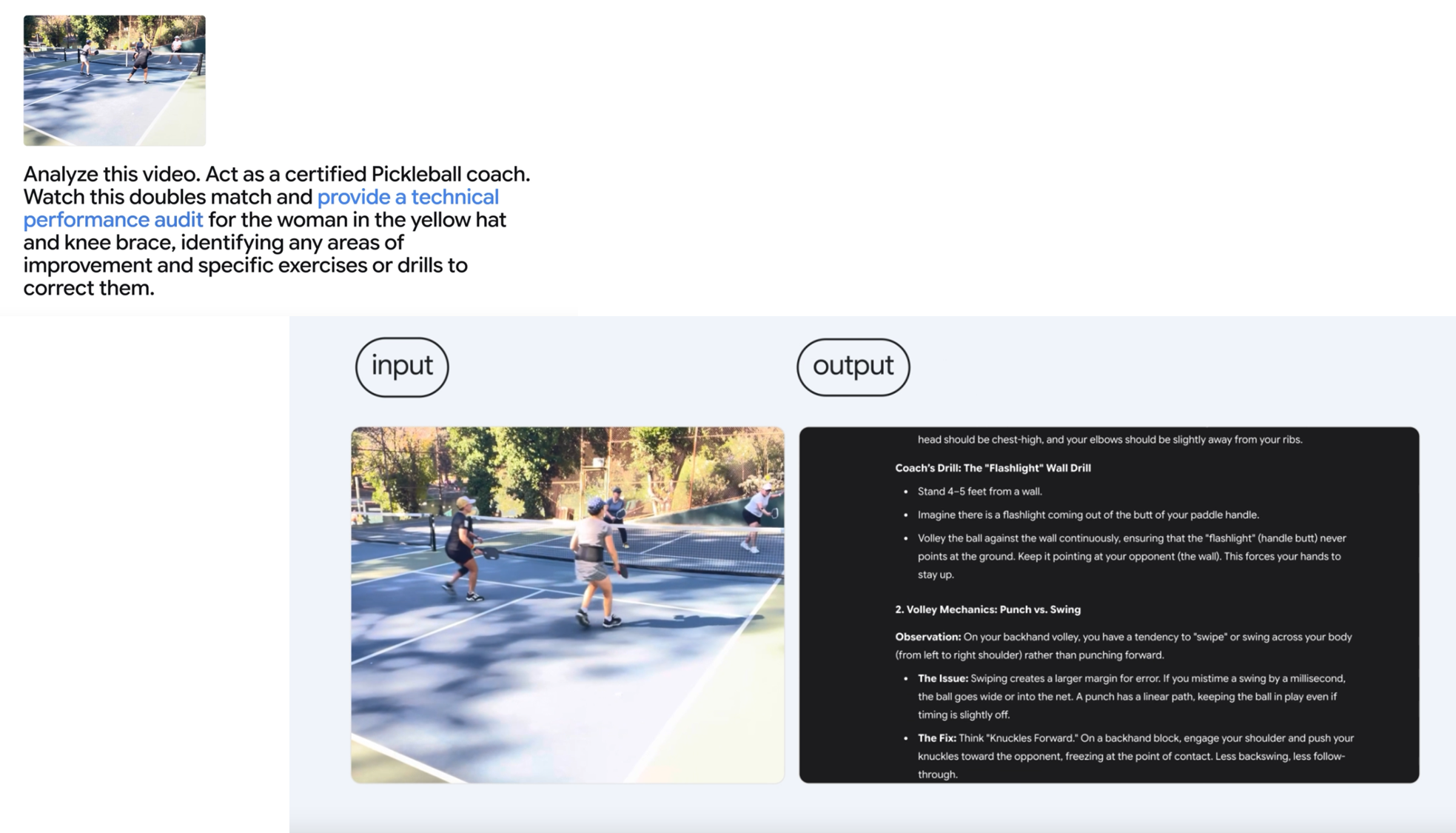
피클볼 경기 영상 분석:
- 폼 분석: 백핸드/포핸드 스윙, 서브 모션, 발놀림
- 전술적 결정: 샷 선택, 포지셔닝, 게임 페이스
- 개선 계획: 약점 집중 훈련, 점진적 목표 설정
2. 개발 도구: Build Anything
제로샷 게임 개발

Google AI Studio에서 "레트로 스타일의 우주선 게임을 만들어줘"라고 요청하면:
- 3D 렌더링
- 물리 기반 이동
- 적 AI
- 파워업 시스템
- 점수 저장모든 기능을 갖춘 완전한 게임을 즉시 생성합니다.
복잡한 UI 생성
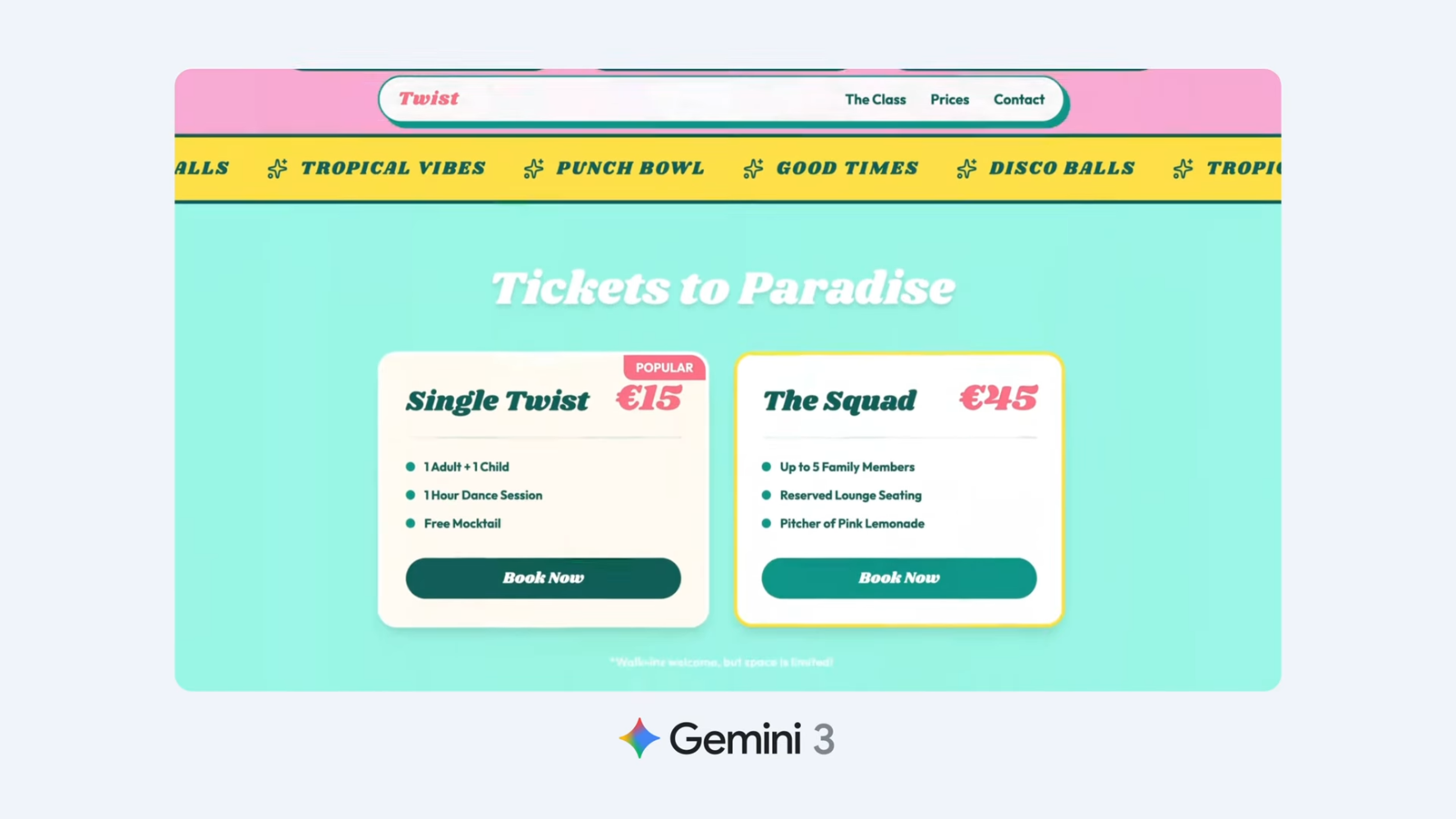
가족 참여형 댄스 이벤트 "Twist"를 위한 레트로 글래머 웹 랜딩 페이지 제작:
**주요 요구사항**:
- 1972년 마이애미 풀파티 분위기
- 트로피컬 파스텔 팔레트
- 플라밍고 벡터 애니메이션
- 완전한 반응형 디자인Gemini 3가 모든 요구사항을 충족하는 완성도 높은 페이지를 생성합니다.
에이전트 워크플로우
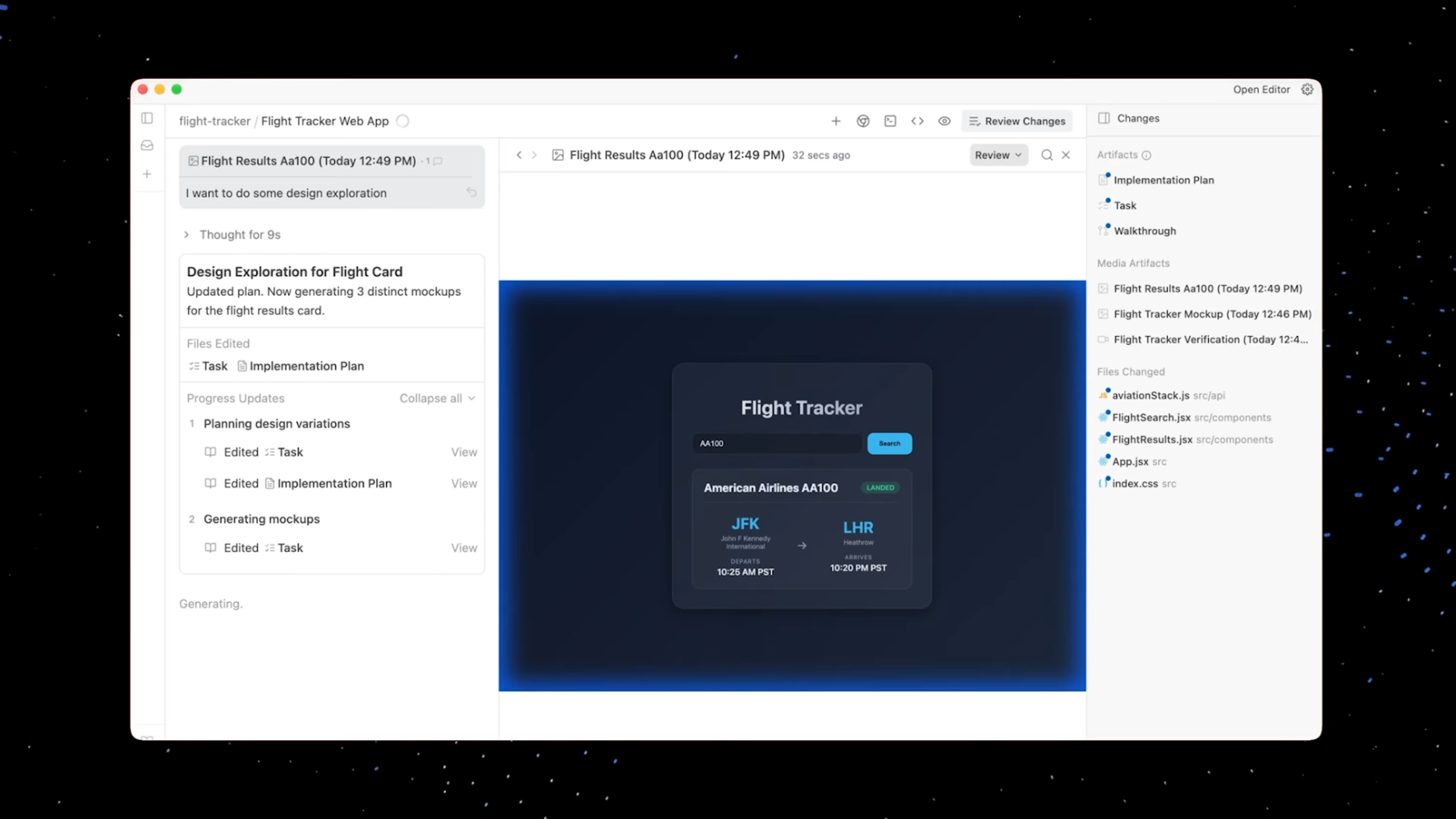
Google Antigravity를 사용한 항공편 조회 앱 개발:
**에이전트 수행 단계**:
1. 요구사항 분석 및 핵심 기능 정의
2. 항공 데이터 API 조사 및 선택
3. 프론트+백엔드 통합 아키텍처 설계
4. 기본 UI/UX 구조 기획
5. API 연동 백엔드 구현
6. 검색+결과 표시 UI 구현
7. 브라우저 자동 테스트로 기능 검증
8. 스크린샷 기반 UI 개선 피드백 반영
9. 디자인 모델로 다양한 UI 시안 생성
10. 선택한 UI 디자인으로 리팩터링
11. 단위 및 통합 테스트 작성/실행
12. 브라우저 재검증 및 자동 수정 반복
13. 최종 보고서(워크스루+데모 영상) 생성3. 계획 도구: Plan Anything
장기 계획 능력

Vending-Bench 2: Gemini 3 Pro가 1위
시뮬레이션된 자판기 사업을 1년 동안 관리하며:
- 재고 관리
- 가격 조정
- 마케팅 결정
- 유지보수 일정
을 일관되게 수행하는 능력을 평가합니다. Gemini 3는 다른 프론티어 모델보다 훨씬 높은 수익을 달성했습니다.
실생활 작업 자동화

Gemini Agent (Google AI Ultra 구독자 대상):
Gmail 정리 작업:
- 중요한 업무 메일: '업무' 폴더
- 영수증: '영수증' 폴더
- 뉴스레터: '읽을거리' 폴더
- 나머지: 적절히 분류
로컬 서비스 예약:
1. 근처 청소 서비스 검색
2. 리뷰 비교
3. 가격 확인
4. 가용 시간 확인
5. 예약 진행 (사용자 승인 후)
6. 캘린더에 일정 추가
결론
핵심 혁신 정리
Gemini 3 Pro의 차별화 포인트:
- 최첨단 추론: LMArena 1501 Elo, PhD 수준 문제 해결
- 뛰어난 멀티모달: 이미지, 비디오, 공간 이해에서 SOTA
- 강력한 코딩: WebDev Arena 1위, 바이브 코딩 실현
- 자율 에이전트: 복잡한 장기 작업 신뢰성 있게 수행
- 100만 토큰 컨텍스트: 방대한 정보 동시 처리
Deep Think 모드의 의미:
- 더욱 강력한 추론 (GPQA Diamond 93.8%)
- 신규 문제 해결 능력 (ARC-AGI-2 45.1%)
- 복잡한 문제에 대한 깊은 사고 실현
실용적 가치
개발자에게:
- 생산성 비약적 향상 (Google Antigravity)
- 더 빠른 프로토타이핑 (바이브 코딩)
- 복잡한 워크플로우 자동화 (에이전트)
일반 사용자에게:
- 학습 도구 혁신 (맞춤형 교육 자료 생성)
- 일상 작업 자동화 (Gmail 정리, 일정 관리)
- 창의적 프로젝트 지원 (게임, 앱, 콘텐츠 제작)
Gemini 3는 AI의 새로운 시대를 여는 모델입니다. 더 똑똑하고, 더 유용하며, 더 신뢰할 수 있는 AI를 통해 여러분의 아이디어가 현실이 되는 순간을 경험해 보시기 바랍니다.
읽어주셔서 감사합니다 😄
