
1. 개요
금일 ChatGPT와 API에서 o3-mini 및 o3-mini-high를 공개하였습니다.
아래 "블로그 포스트"와
📢 We’re releasing OpenAI o3-mini, the newest, most cost-efficient model in our reasoning series, available in both ChatGPT and the API today. Previewed in December 2024, this powerful and fast model advances the boundaries of what small models can achieve, delivering exceptional STEM capabilities—with particular strength in science, math, and coding—all while maintaining the low cost and reduced latency of OpenAI o1-mini. - OpenAI blog
아래 "X 게시물"과 함께 소개되었는데요.
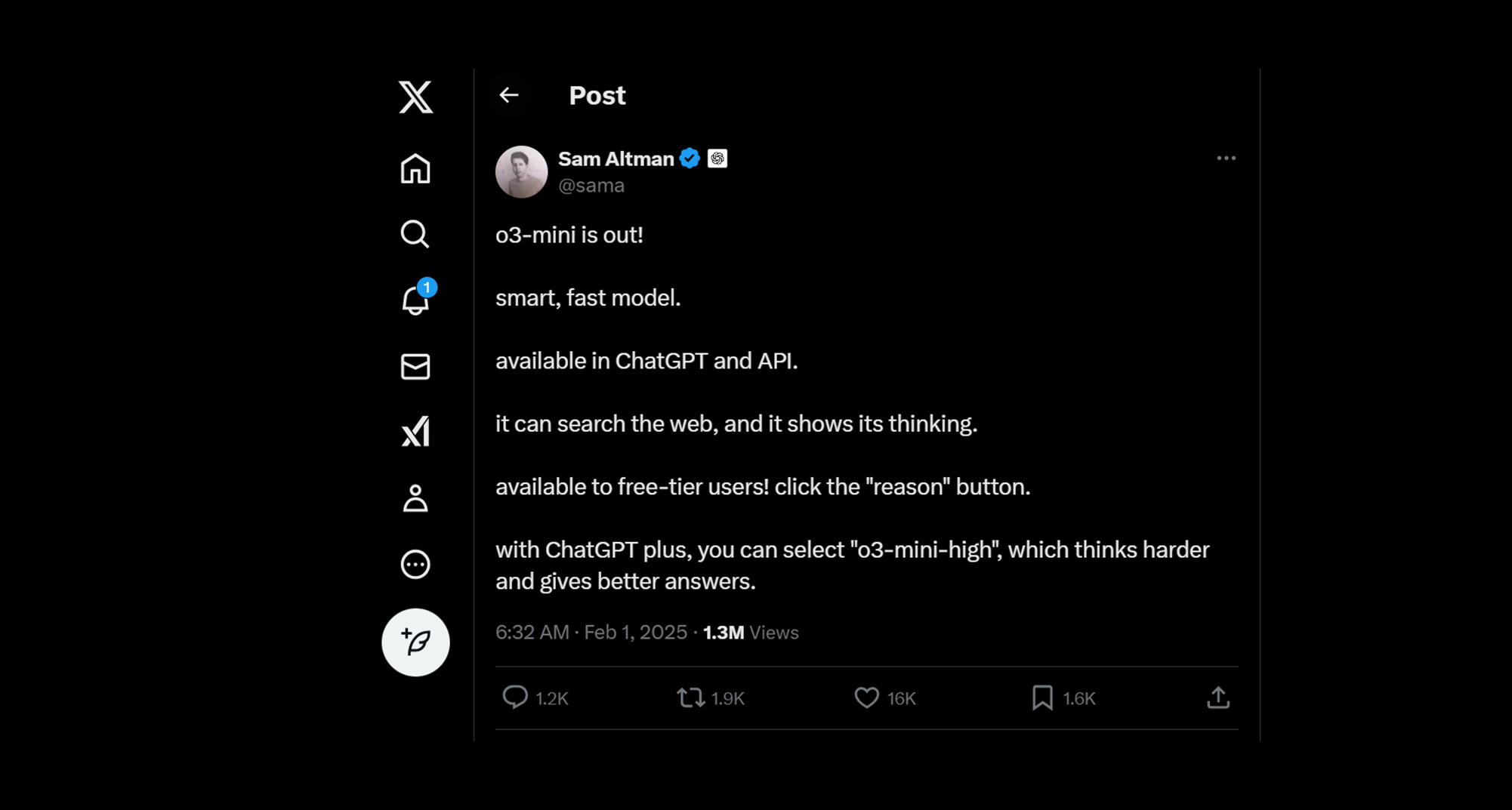
Image Source: Sam Altman's X post
(번역) Sam Altman's X post
o3-mini 출시! 스마트하고 빠른 모델.
ChatGPT 및 API로 제공됩니다.
웹을 검색하면 생각을 알 수 있습니다.
무료 계층 사용자에게 제공됩니다! "이유" 버튼을 클릭하세요.
ChatGPT 플러스를 사용하면 더 열심히 생각하고 더 나은 답변을 제공하는 "o3-mini-high"를 선택할 수 있습니다.
"무료 계층 사용자에게 제공됩니다! "이유" 버튼을 클릭하세요."에서 말하는 기능은 아래 그림에서 설명하는 Reason💡 버튼입니다.
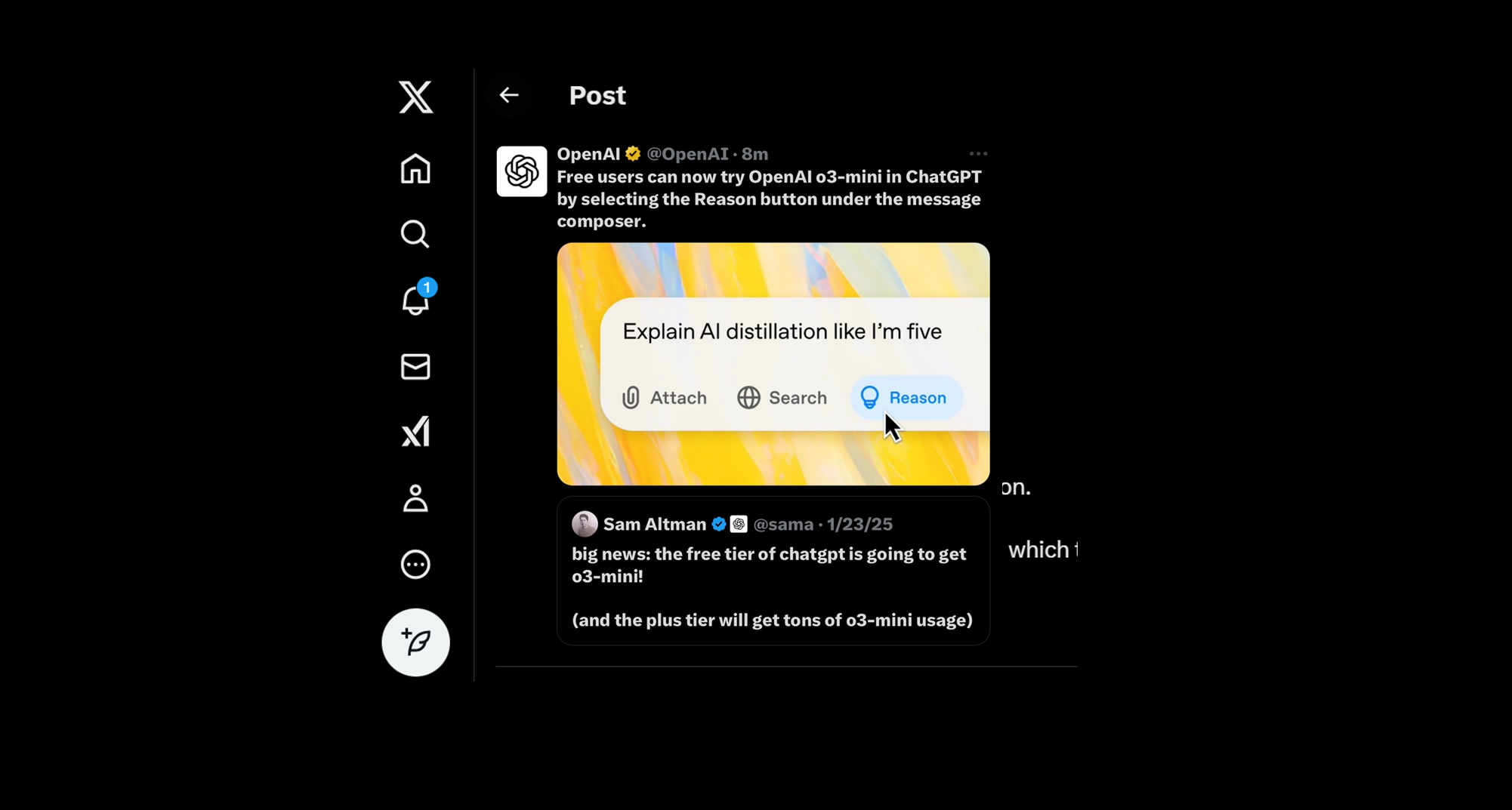
Image Source: OpenAI's X post
❓ STEM capabilities란?
STEM 역량은 Science, Technology, Engineering, and Mathematics (STEM)을 연구하여 얻은 기술과 지식을 의미합니다.
- 예를 들어:
- 문제 해결: 문제를 식별하고 해결하는 능력
- 창의성: 상상력을 활용하여 솔루션을 개발하는 능력
- 비판적 사고: 정보를 분석하고 결론에 도달하는 능력
- 팀워크: 목표를 달성하기 위해 다른 사람들과 협력하는 능력
- 커뮤니케이션: 정보를 명확하게 전달하는 능력
- 연구: 새로운 정보를 발견하는 능력
- 데이터 분석: 정보를 검토하고 결론에 도달하는 능력
- 수학: 고급 수학 기술을 사용하여 복잡한 방정식을 푸는 능력
- 디자인 사고: 문제에 대한 잠재적 해결책을 식별하는 능력
- 호기심: 질문을 통해 더 많은 정보를 배울 수 있는 능력
- 고객 서비스: 고객에게 제품을 제공하는 기능
- 리더십: 다른 사람들에게 영향을 미치고, 협상하며, 갈등에 대처할 수 있는 능력
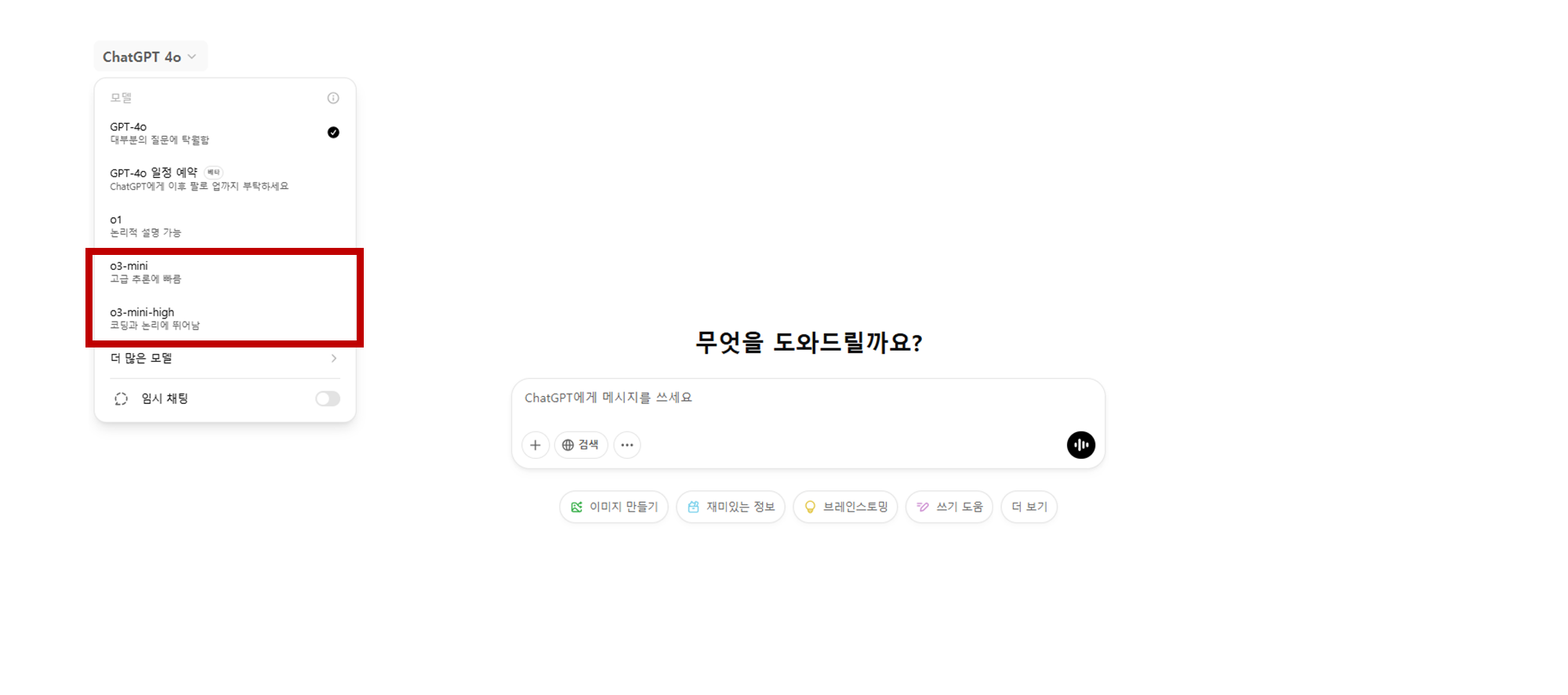
o3-mini chatGPT 제공 옵션
ChatGPT에서 o3-mini는 기본적으로 중간(Medium) reasoning effort을 사용하여 속도와 정확성 간의 균형을 제공합니다.
- 이를 통해 일반적인 질의응답, 코딩, 수학, 과학 등 다양한 분야에서 빠르면서도 높은 정확도의 응답을 기대할 수 있습니다.
또한, o3-mini-high 옵션도 제공되며, 이는 더 높은 지능을 갖춘 모델로, 보다 깊이 있는 추론과 복잡한 문제 해결에 적합합니다.
- 다만, 응답 생성 시간이 다소 증가할 수 있기 때문에, 보다 정교한 분석이나 복잡한 수학 및 코딩 문제를 다룰 때 유용합니다.
Reasoning Effort API 옵션
OpenAI o3-mini는 API 호출 시 세 가지 reasoning effort 수준(Low, Medium, High)을 조절할 수 있도록 설계되었습니다.
이를 통해 사용자는 작업의 특성에 맞춰 모델의 연산량과 응답 품질을 최적화할 수 있습니다.
-
Low Reasoning Effort:
- 빠른 응답이 필요한 경우 적합 (예: 단순 요약, 기본적인 코드 생성).
-
Medium Reasoning Effort (기본값):
- 속도와 정확성의 균형을 유지하며, 일반적인 AI 활용에 적합 (예: 중간 난이도의 수학 문제 해결, 논리적인 질문 응답).
-
High Reasoning Effort:
- 복잡한 문제 해결을 위해 더 깊이 있는 추론 수행 (예: 고급 알고리즘 문제 해결, 과학적 분석, 논리적 사고 요구).
유료 사용자들은 기본적으로 o3-mini(Medium reasoning effort)을 사용하게 되며, 필요에 따라 o3-mini-high을 선택하여 더욱 정밀한 AI 추론 결과를 얻을 수 있습니다.
- 특히 Pro 사용자들은 o3-mini와 o3-mini-high을 제한 없이 자유롭게 활용할 수 있어, 다양한 상황에 맞춰 최적의 모델을 선택하여 사용할 수 있습니다.
API를 통해 reasoning effort 옵션을 조절하면 복잡한 작업에서는 더 강력한 추론 성능을 발휘하고, 빠른 작업에서는 응답 속도를 최적화할 수 있습니다.
o3-mini 특징 정리
OpenAI의 최신 AI 모델 o3-mini의 특징을 정리하면 아래와 같습니다:
- 비용 효율적인 최신 reasoning 모델로, 고급 수학 및 코딩 문제에서 뛰어난 성능을 발휘함.
- 함수 호출(Function Calling), 구조화된 출력(Structured Outputs), 개발자 메시지 지원 등 다양한 기능을 지원하여 유연성을 높임.
- 세 가지 reasoning effort 제공: Low, Medium, High, 이를 통해 사용자는 응답 속도와 정확성 간의 균형을 조절 가능.
- 스트리밍 지원 (단, 비전(이미지) 기능 없음), 따라서 시각적 이해가 필요한 작업에서는 OpenAI o1 모델 사용 권장.
- ChatGPT 및 API(Chat Completions, Assistants, Batch API)에서 사용 가능하여 다양한 개발 환경에서 활용 가능.
- Plus 및 Team 사용자의 메시지 제한이 기존 o1-mini의 50개에서 150개로 증가, 이를 통해 더 많은 쿼리를 실행할 수 있음.
- 검색 기능 추가(웹 링크 제공)로 최신 정보를 더욱 정확하게 제공할 수 있음.
- 무료 사용자도 'Reason' 모드 선택을 통해 사용 가능, 이는 OpenAI reasoning 모델 중 처음으로 무료 사용자에게 제공됨.
o1, o1-mini, o3, o3-mini 비교
OpenAI는 다양한 AI 모델을 개발해왔으며, 각 모델은 성능과 효율성 측면에서 차별점을 가집니다.
- 아래는
o1,o1-mini,o3,o3-mini의 주요 비교 사항입니다.
| 모델 | 주요 특징 | 성능 | 비용 | 활용도 |
|---|---|---|---|---|
| o1 | 일반적인 AI 추론 모델 | 중간 수준 | 중간 | 범용적 사용 가능 |
| o1-mini | 속도와 비용 최적화 모델 | 중간에서 낮은 수준 | 낮음 | 빠른 응답과 저비용 요구 환경 |
| o3 | 고급 AI 추론 모델 | 최고 수준 | 높음 | 연구 및 복잡한 문제 해결 |
| o3-mini | o3의 비용 효율적 버전 | 높은 수준 | 낮음 | STEM, 코딩, 비용 절감 필요 환경 |
✅ 표 정리:
- o1은 범용적인 AI 모델로 활용되며, 균형 잡힌 성능을 제공합니다.
- o1-mini는 저비용과 빠른 응답을 원하는 사용자에게 적합합니다.
- o3는 최고 수준의 성능을 제공하지만, 높은 비용이 수반됩니다.
- o3-mini는 o3의 장점을 유지하면서도 더 낮은 비용과 효율적인 성능을 제공합니다.
비용 분석
아래는 openAI pricing 사이트에서 가격표를 가져온 것입니다. (asof 25.02.01)
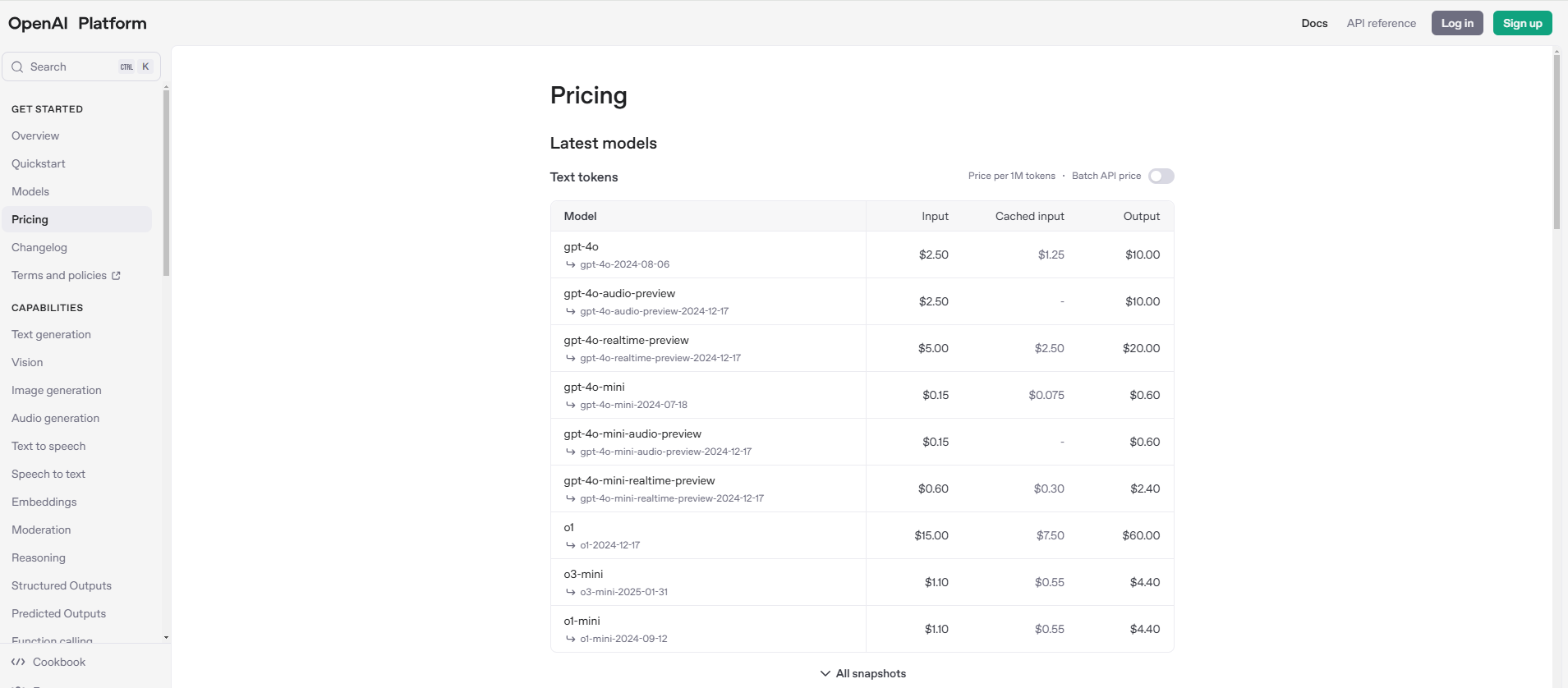
Image Source : https://openai.com/api/pricing/
o1과 o3-mini의 가격만 비교하면 아래와 같습니다:
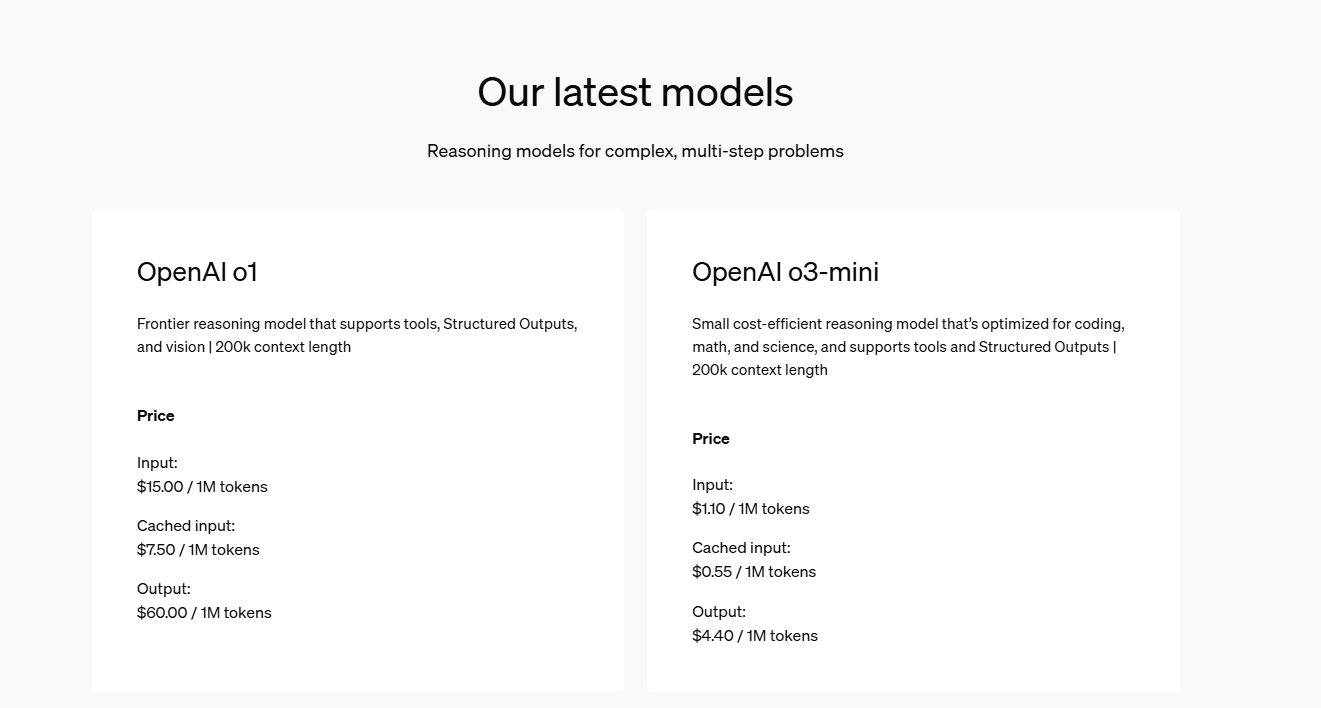
Image Source : https://openai.com/api/pricing/
Input/Ouput Token 비교
다음은 현존하는 openAI reasoning model들에 대한 정보입니다.
| Model | Context Window (tokens) | Max Output Tokens |
|---|---|---|
| o1 | 200,000 | 100,000 |
| o1-mini | 128,000 | 65,536 |
| o3-mini | 200,000 | 100,000 |
Table Source: https://platform.openai.com/docs/models#o1
2. 주요 성능 분석
위에서 특징을 살펴봤다면 이제 benchmark 데이터를 기준으로 한번 살펴보도록 하겠습니다.
다음 주요 성능 분석은 아래 페이지에 근거하여 작성되었습니다.
2.1 수학(Mathematics) 성능
AIME 2024 평가 결과
- 낮은 reasoning effort: o1-mini와 유사한 성능.
- 중간 reasoning effort: o1과 비슷한 성능.
- 높은 reasoning effort: o1 및 o1-mini보다 우수한 성능.
(참고) N/A는 별다른 model specification이 없는 경우 N/A로 기록함
| 모델 | low | mid | high | N/A |
|---|---|---|---|---|
| o1-mini | - | - | - | 63.6 |
| o1 | - | - | - | 83.3 |
| o3-mini | 60.0 | 79.6 | 87.3 | - |
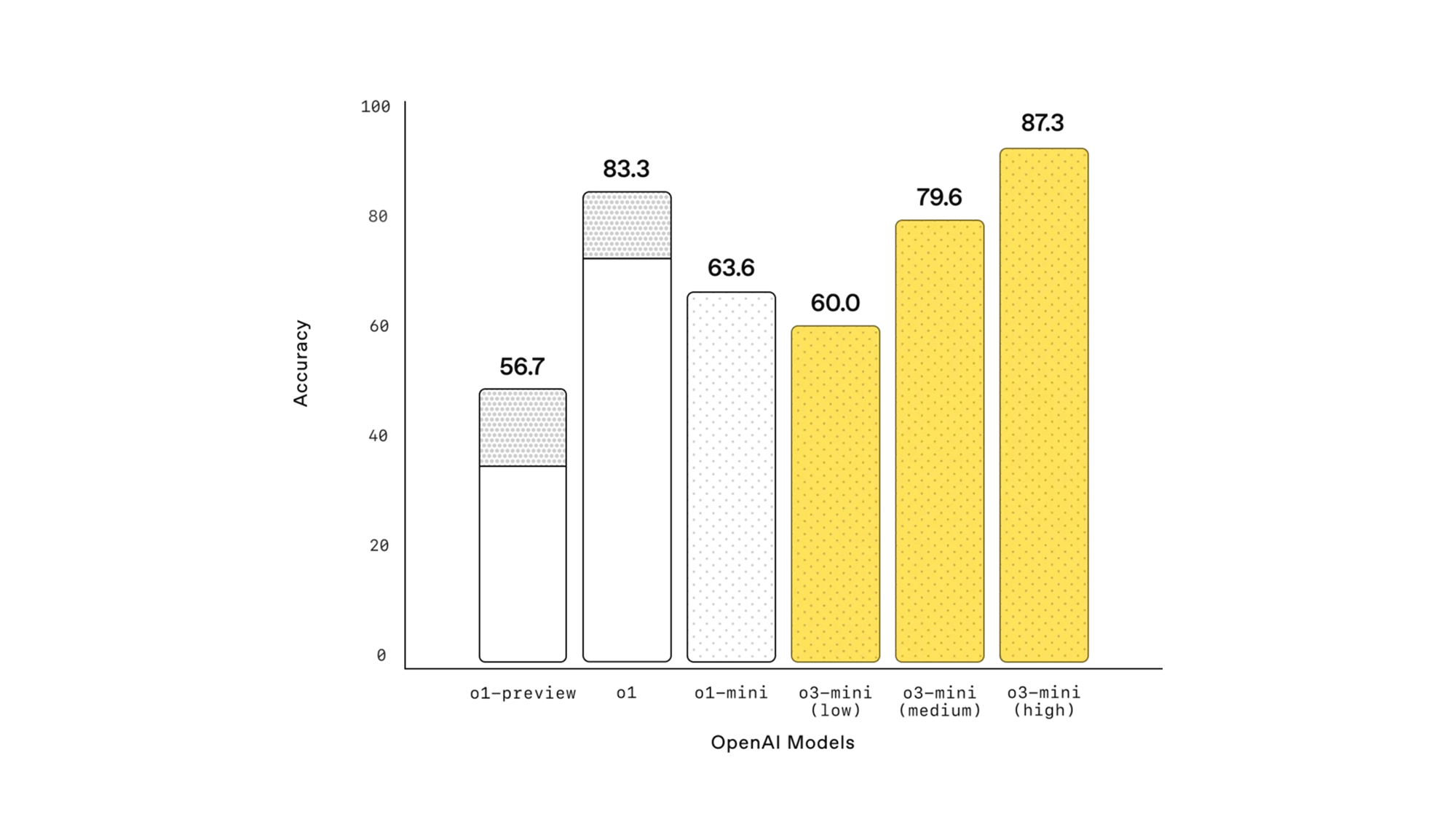
✅ 표 해석:
-
AIME(American Invitational Mathematics Examination) 2024에서 높은 reasoning effort에서 가장 높은 성능을 기록하였으며, 중간 effort에서도 o1 수준에 근사하는 성능을 유지함.
-
이는 복잡한 수학적 문제 해결에서 o3-mini가 상당한 경쟁력을 갖추었음을 의미함.
2.2 과학(Science) 성능
PhD 수준 과학 문제(GPQA Diamond)
- 낮은 reasoning effort: o1-mini보다 우수.
- 높은 reasoning effort: o1과 유사한 성능.
(참고) N/A는 별다른 model specification이 없는 경우 N/A로 기록함
| 모델 | low | mid | high | N/A |
|---|---|---|---|---|
| o1-mini | - | - | - | 60.0 |
| o1 | - | - | - | 78.0 |
| o3-mini | 70.6 | 76.8 | 79.7 | - |
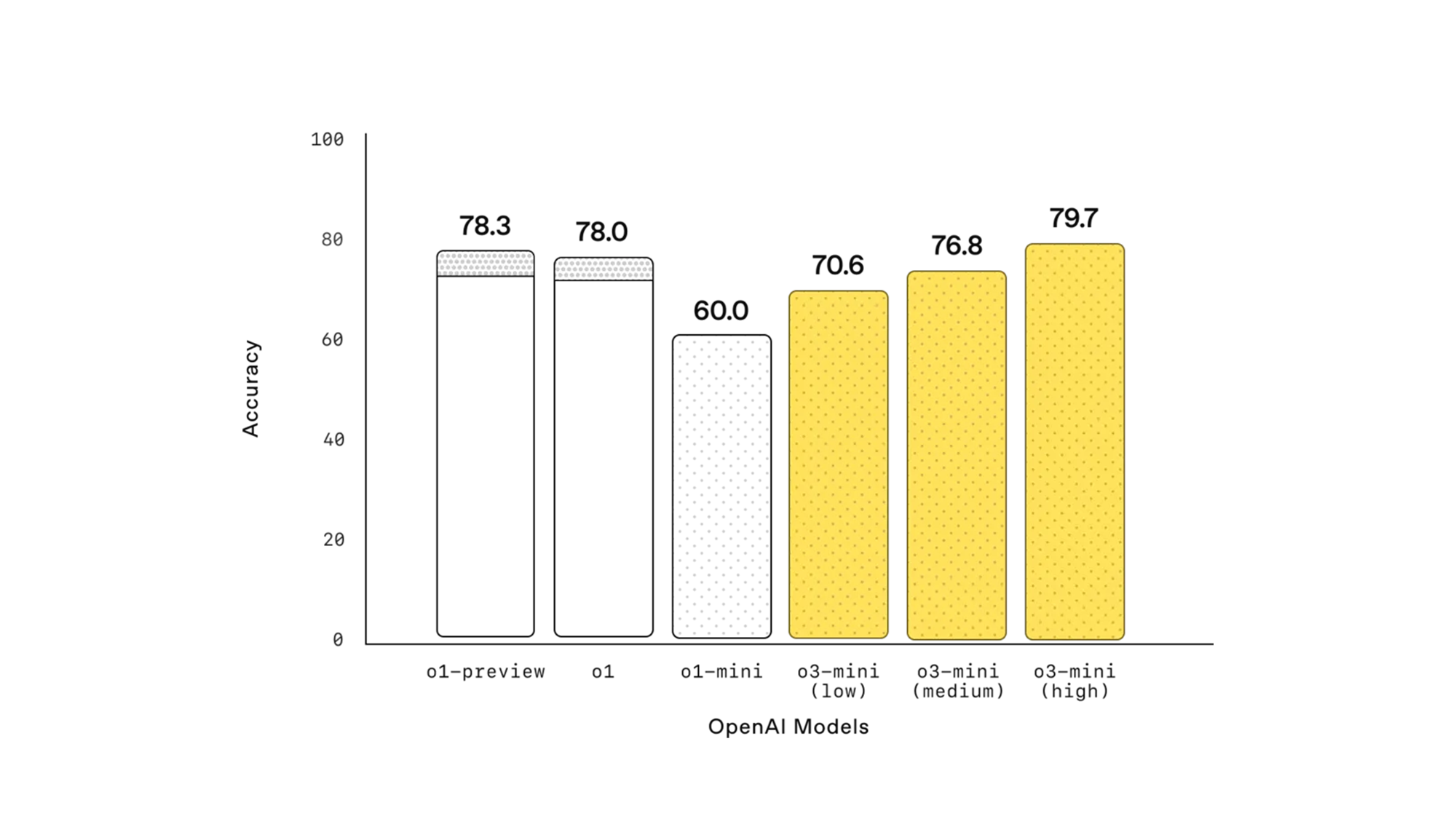
✅ 표 해석:
-
GPQA(Google PhD-level Question Answering) 평가에서 o3-mini는 낮은 reasoning effort에서도 높은 성능을 유지하며, 높은 reasoning effort에서는 o1 수준과 동등한 결과를 보임.
-
이는 생물학, 화학, 물리학 등의 과학 분야에서 강력한 분석 및 논리적 추론 능력을 갖추고 있음을 의미함.
2.3 알고리즘 및 컴페티션 코딩 성능 (Codeforces)
(참고) Elo 점수는 체스, e스포츠, 프로그래밍 대회(Codeforces 등)와 같은 경쟁 환경에서 참가자의 상대적인 실력을 평가하는 방식입니다. 이 점수는 경기 결과에 따라 동적으로 변하며, 더 강한 상대를 이기면 점수가 더 크게 오르고, 약한 상대에게 지면 점수가 크게 감소하는 특징이 있습니다.
| 모델 | Elo 점수 |
|---|---|
| o1-preview | 1258 |
| o1 | 1891 |
| o1-mini | 1650 |
| o3-mini (low) | 1831 |
| o3-mini (medium) | 2036 |
| o3-mini (high) | 2130 |
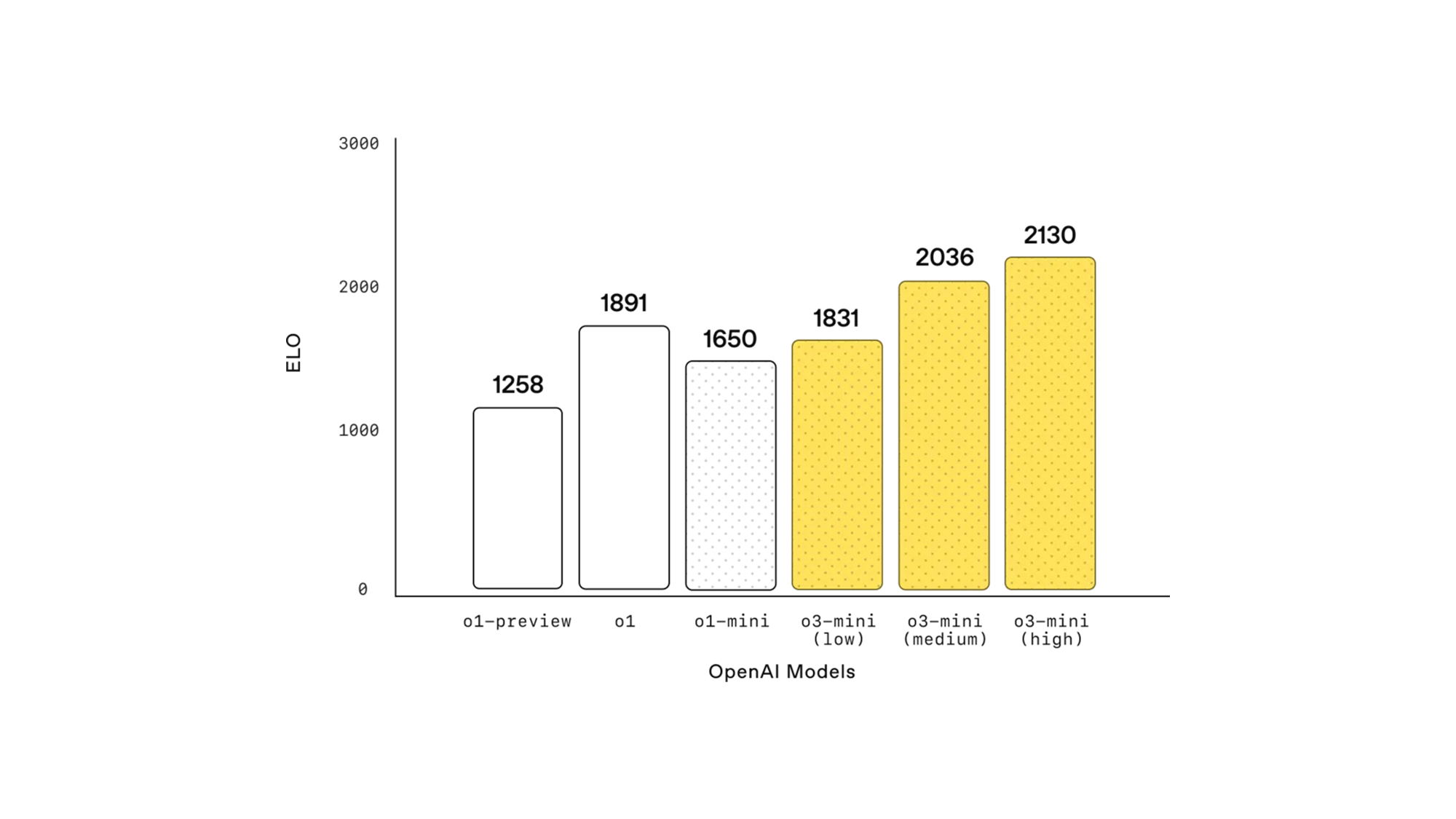
✅ 표 해석:
- o3-mini (high) 모델은 2130 Elo를 기록하여 기존 모델보다 높은 성능을 보였으며, o1-mini보다 500 Elo 이상 높은 성능을 보여줌.
2.4 고급 수학 문제 해결 능력 (FrontierMath)
(참고) FrontierMath는 고급 수학 문제 해결 능력을 평가하는 벤치마크이며, 여기서
Pass@k는 AI 모델이 수학 문제를 얼마나 잘 해결할 수 있는지 측정하는 핵심 지표입니다.
Pass@1: AI가 한 번의 시도로 정답을 맞출 확률Pass@4: AI가 4번 시도하는 동안 정답을 맞출 확률Pass@8: AI가 8번 시도하는 동안 정답을 맞출 확률

| 모델 | Pass@1 | Pass@4 | Pass@8 |
|---|---|---|---|
| o3-mini (high) | 9.2% | 16.6% | 20.0% |
| o1-mini | 5.8% | 9.9% | 12.8% |
| o1 | 5.5% | 10% | 12.8% |
✅ 표 해석:
- o3-mini 모델은 Pass@1, Pass@4, Pass@8 성능이 모두 o1-mini와 o1을 크게 초과, 특히 수학적 reasoning을 필요로 하는 문제에서 유의미한 성능 향상을 보임.
2.5 일반 지식 및 수학 지식 (General Knowledge)
(참고) General Knowledge 평가에는 여러 서브테스크가 포함되며, 주요 평가 항목은 다음과 같습니다.
- General(MMLU): 다양한 분야의 일반 지식을 평가하는 벤치마크
- Math(Math) : 기초 및 고급 수학 문제 해결 능력
- Math(MGSM) : Multi-step math 문제 해결 능력
- Factuality(SimpleQA) : 간단한 사실 질문에 대한 정답률
| Category | Eval | o1-mini | o3-mini (low) | o3-mini (medium) | o3-mini (high) |
|---|---|---|---|---|---|
| General | MMLU (pass@1) | 85.2 | 84.9 | 85.9 | 86.9 |
| Math | Math (pass@1) | 90.0 | 95.8 | 97.3 | 97.9 |
| Math | MGSM (pass@1) | 89.9 | 55.1 | 90.8 | 92.0 |
| Factuality | SimpleQA | 7.6 | 13.0 | 13.4 | 13.8 |
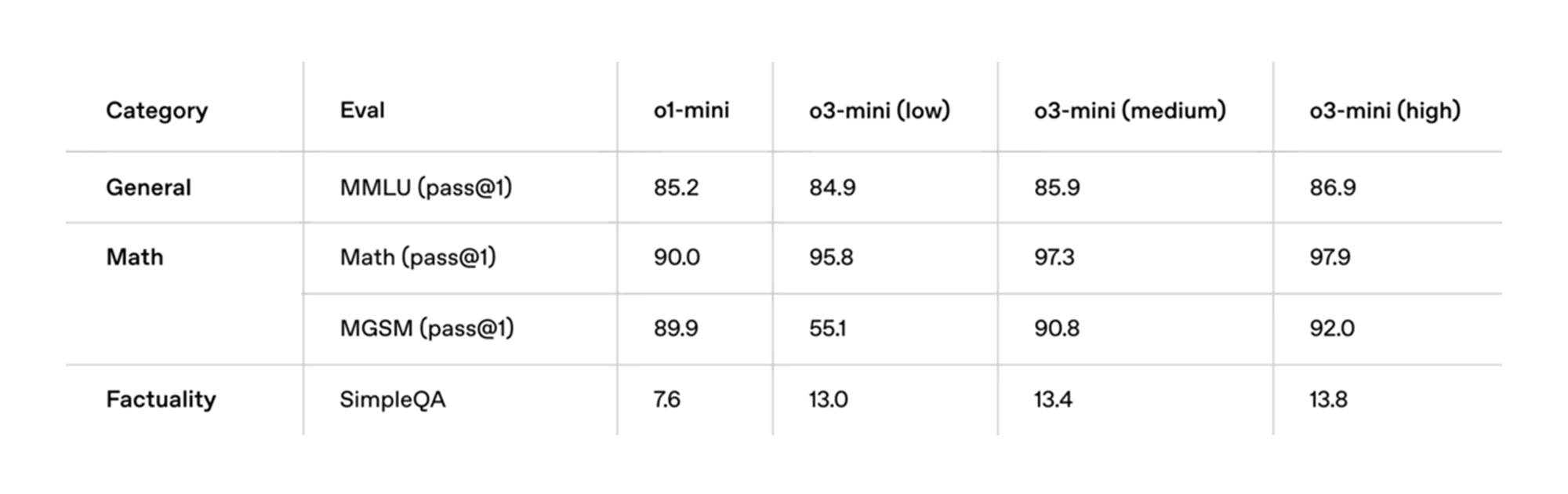
✅ 표 해석:
- MMLU(일반 지식)에서는 기존 모델과 유사한 성능을 보였으나, 수학(MGSM) 성능에서 o3-mini가 확연히 향상된 결과를 보임.
2.6 인간 평가 결과 (Human Preference Evaluation)
(참고) Human Preference Evaluation은 실제 (인간) 사용자들이 AI 모델이 생성한 응답을 비교하여 어느 모델이 더 나은 결과를 제공하는지 평가하는 벤치마크입니다.
- 이 테스크는 단순한 수치 기반 평가(MAE, BLEU, Pass@k 등)와 달리, 실제 사용자의 주관적인 선호도 및 이해도를 반영하여 AI 모델을 평가하는 것이 특징입니다.
| 평가 항목 | 평가 기준 | o1-mini | o3-mini (medium) |
|---|---|---|---|
| STEM 영역 | Win Rate (%) | 50% | 58~60% |
| 비-STEM 영역 | Win Rate (%) | 50% | 58~60% |
| 시간 제약 상황 | Win Rate (%) | 50% | 54~58% |
| Major Error Rate | 오류율 (%) | 약 27% | 약 17% (39% 감소) |
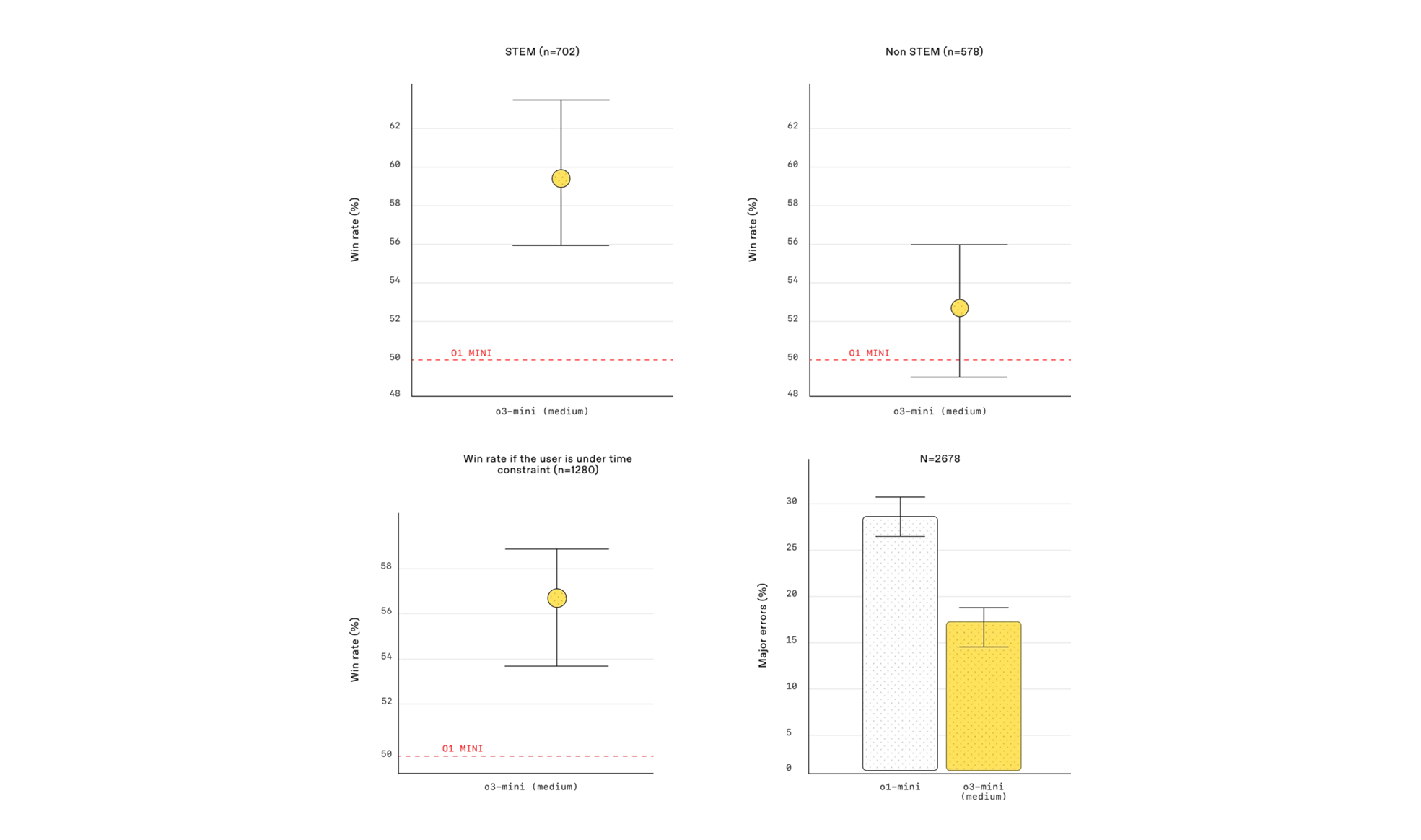
✅ 표 해석:
-
STEM 및 비-STEM 도메인에서 o3-mini (medium) 모델이 기존 o1-mini 모델보다 더 선호되는 응답을 생성.
-
시간 제약이 있는 경우에도 o3-mini 모델이 더 높은 정답률을 보임, 즉 빠르고 정확한 응답을 제공할 가능성이 높음.
-
Major Error Rate(중대한 오류 비율)가 기존 모델 대비 39% 감소, 즉 더 신뢰할 수 있는 정보를 제공.
2.7 코드 생성 및 컴플리션 성능 (LiveBench Coding)
(참고) LiveBench Coding 테스크는 AI 모델이 실제 코드를 생성(Generation)하고 완성(Completion)하는 능력을 평가하는 벤치마크입니다.
- 일반적인 코드 생성(Code Generation)뿐만 아니라, 논리적 추론(Reasoning)과 복잡한 코드 작성 능력을 테스트하는 것이 특징입니다.
- 아래 3가지 항목에 대해서 테스트를 수행합니다:
- Average Score : 전반적인 코드 생성 및 완성 성능
- LCB Generation : 논리적으로 일관된 코드 블록 생성 능력
- Code Completion : 코드 자동 완성(Completion) 능력
| 모델 | Reasoning Level | Average | LCB Generation | Code Completion |
|---|---|---|---|---|
| o3-mini | low | 0.618 | 0.756 | 0.48 |
| o3-mini | medium | 0.723 | 0.846 | 0.60 |
| o3-mini | high | 0.846 | 0.820 | 0.833 |
| o1 | high | 0.674 | 0.628 | 0.72 |
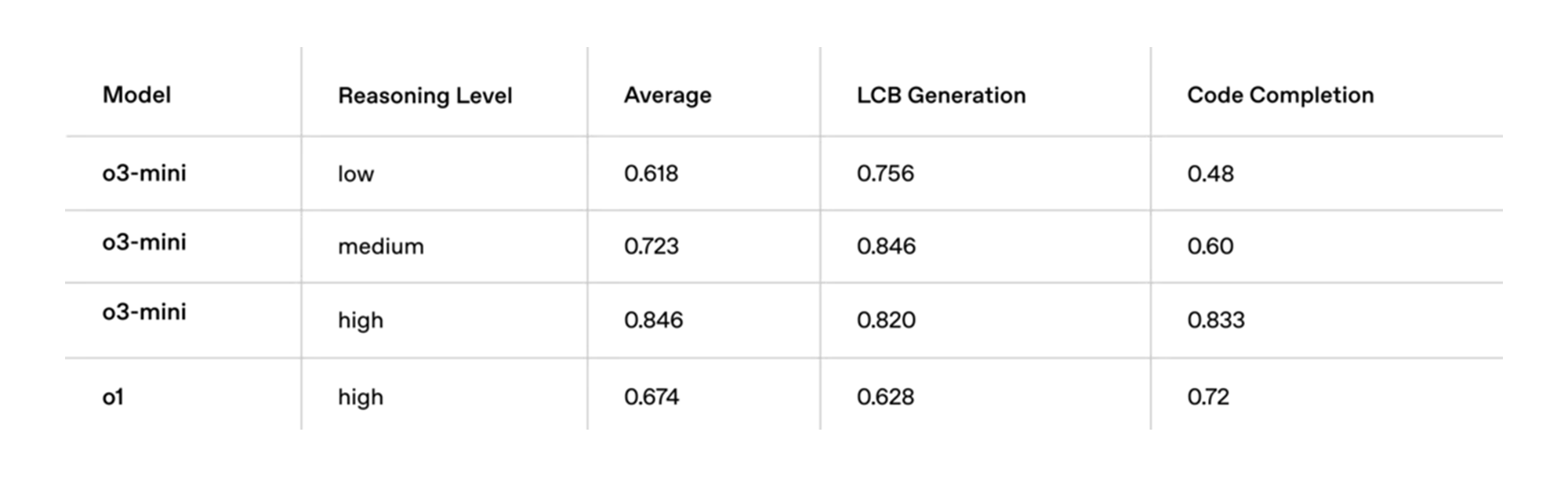
✅ 표 해석:
- o3-mini (high) 모델은 코드 자동 완성(Code Completion)에서 기존 o1 모델을 초과하는 성능을 보이며, 개발 생산성을 높일 수 있는 가능성을 확인.
2.8 소프트웨어 엔지니어링 성능 (SWE-bench Verified)
(참고) SWE-bench Verified는 AI 모델의 소프트웨어 엔지니어링(Software Engineering) 문제 해결 능력을 평가하는 벤치마크입니다.
- 이 테스크는 AI가 실제 코드 베이스에서 버그를 수정하고, 기능을 개선하며, 문제 해결을 수행하는 능력을 측정하는 것이 특징입니다.
| 모델 | 정확도 |
|---|---|
| o1-preview | 41.3% |
| o1 | 48.9% |
| o3-mini (low) | 40.8% |
| o3-mini (medium) | 42.9% |
| o3-mini (high) | 49.3% |
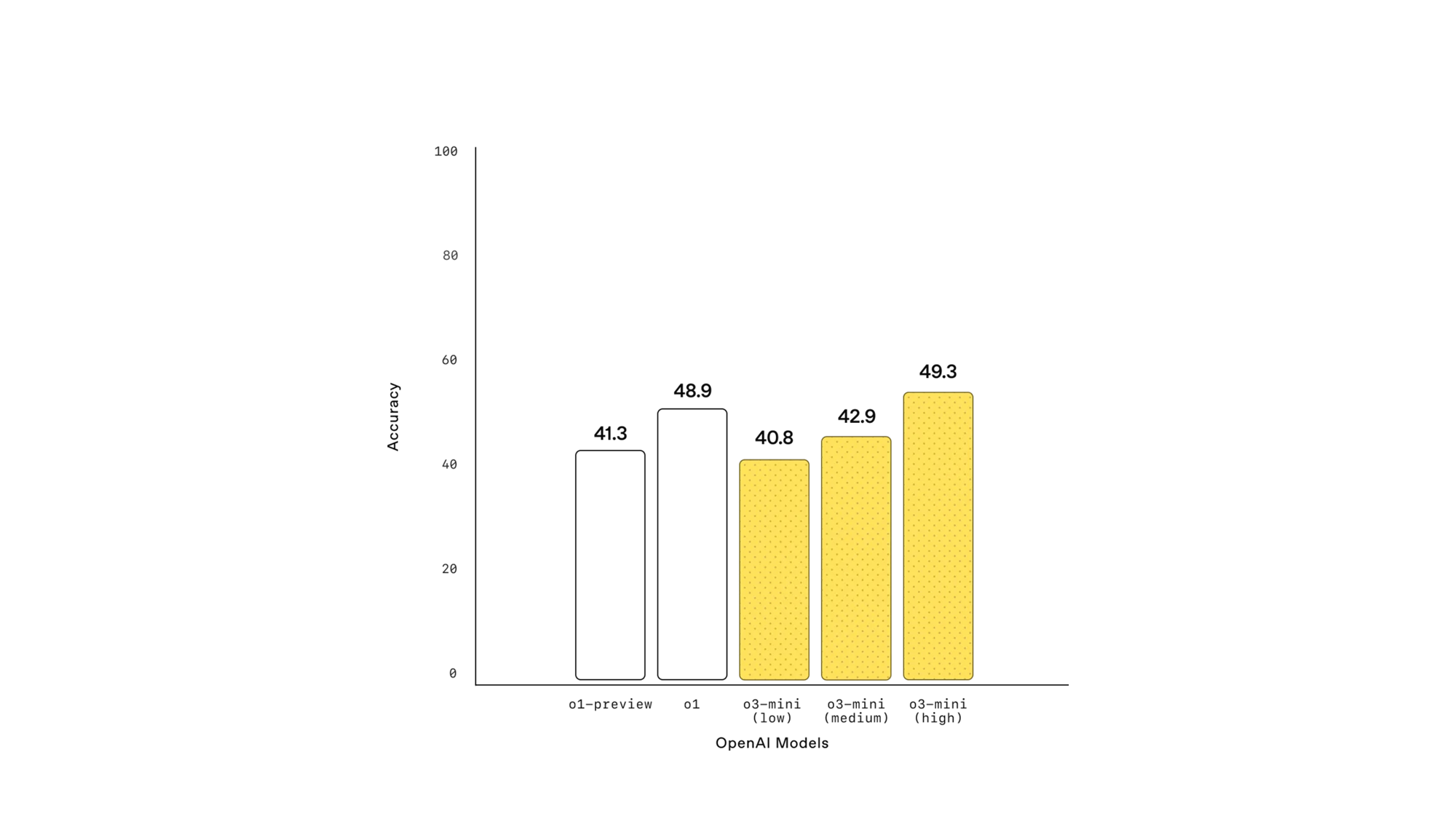
✅ 표 해석:
- 소프트웨어 엔지니어링 문제 해결에서 o3-mini (high) 모델이 o1 모델을 초과하는 성능을 보임.
2.9 응답 속도 비교 (Latency)
| 모델 | Time to First Token (ms) |
|---|---|
| o1-mini | 약 10,000ms |
| o3-mini (medium) | 약 7,500ms |
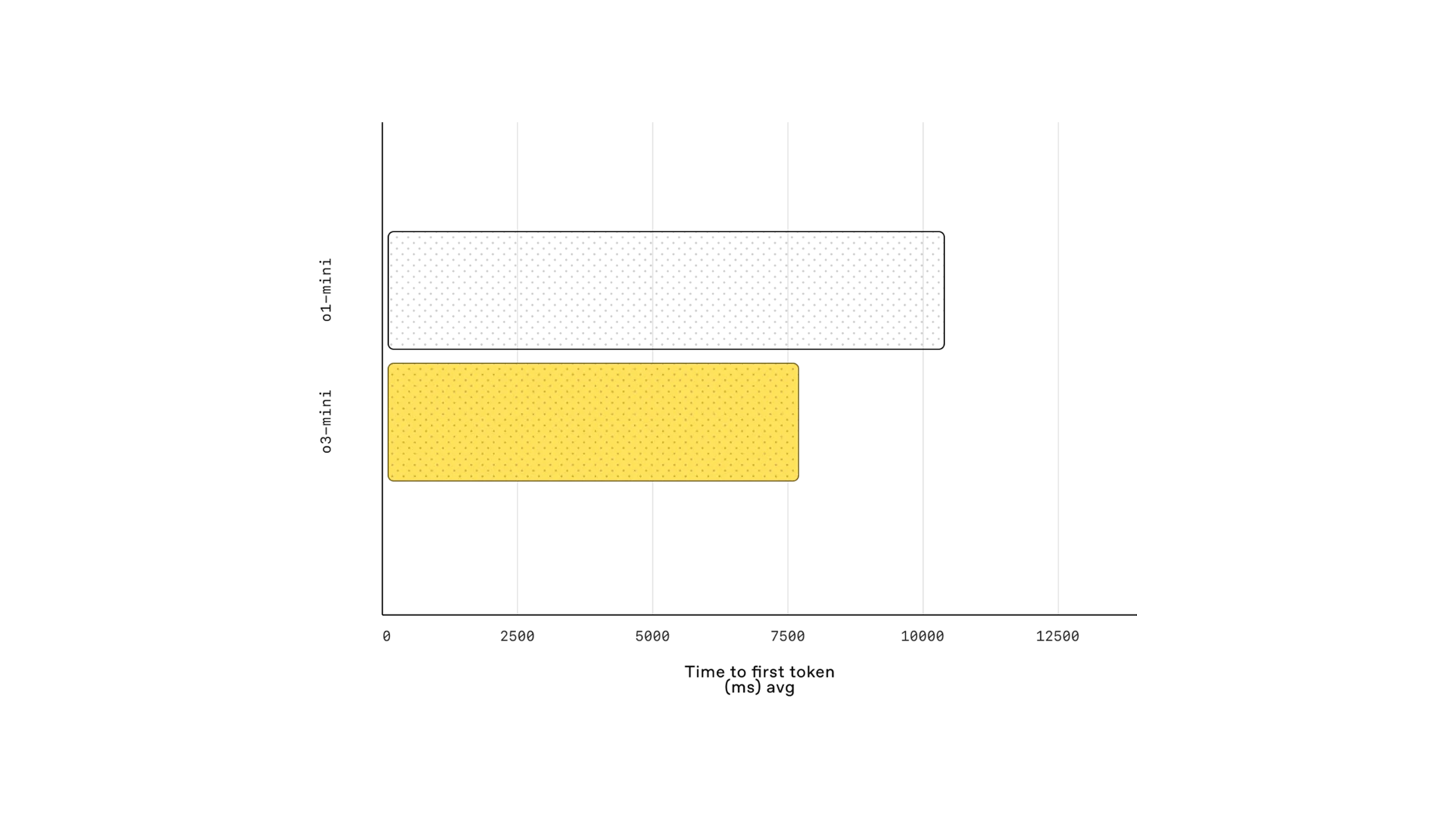
✅ 표 해석:
- o3-mini 모델은 빠른 응답 시간으로 실시간 상호작용 성능이 향상됨.
결론
OpenAI의 새로운 AI 모델인 o3-mini는 기존 모델(o1-mini, o1)과 비교했을 때, STEM(Science, Technology, Engineering, Mathematics) 및 프로그래밍 영역에서 더욱 강력한 성능을 발휘하는 것이 특징입니다.
- 특히, 복잡한 수학 문제 해결, 알고리즘 코딩, 과학적 분석에서 성능 향상이 두드러지며, AI 기반의 논리적 추론 능력을 필요로 하는 다양한 작업에 적합합니다.
주요 특징 요약
-
STEM & 프로그래밍 성능 강화: 수학(AIME, FrontierMath), 과학(GPQA), 코딩(Codeforces, LiveBench) 등의 벤치마크에서 기존 o1, o1-mini 대비 우수한 성능을 기록
-
세분화된 Reasoning Effort 설정 가능: API에서 Low, Medium, High 옵션을 지원하여 작업 특성에 따라 AI 연산량과 응답 품질을 최적화 가능
-
비용 효율적인 모델: 고성능을 유지하면서도 비용이 낮아 경제적 활용도가 높음
-
빠른 응답 속도: 기존 모델 대비 Time to First Token (TTFT) 성능 개선, 실시간 상호작용이 필요한 환경에서 유리함
-
무료 사용자도 Reasoning 기능 이용 가능: OpenAI의 reasoning 모델 중 최초로 무료 계층에서도 일부 기능이 제공됨
o3-mini vs. DeepSeek
최근 중국의 AI 스타트업 DeepSeek이 새로운 AI 모델 DeepSeek-R1을 공개하며 AI 업계의 경쟁이 더욱 심화되고 있습니다. DeepSeek-R1은 오픈소스로 제공되며, 비용 효율성과 고성능을 동시에 추구하는 모델로서 주목받고 있습니다.
이에 대응하여 OpenAI는 o3-mini를 출시하며, STEM 및 프로그래밍 성능을 극대화하면서도 낮은 비용과 빠른 응답 속도를 유지하는 전략을 선택했습니다.
- 특히, o3-mini는 무료 사용자도 Reasoning 모드를 활용할 수 있도록 지원하여 AI의 접근성을 높이는 데 주력하고 있습니다. 이는 DeepSeek이 오픈소스 전략을 취한 것과 유사한 방향성을 가지며, AI의 보급 및 활용도를 극대화하기 위한 움직임으로 볼 수 있습니다.
결과적으로, o3-mini는 AI 경쟁 구도 속에서 비용 대비 성능이 뛰어난 모델로 자리 잡으며, 다양한 사용자들에게 효과적인 AI 도구로 활용될 전망입니다.
읽어주셔서 감사합니다 😎
