
■Learning

-
Learning(학습)의 개념
-어떤 작업(task)에서 에이전트가 경험을 통해서 작업 성능을 개선할 수 있는 것을 학습이라고 함(에이전트에서 지식습득에 대한 검증의 어려움 때문) -
Learning(학습)의 필요성
-설계자는 에이전트가 맞딱뜨리는 모든 상황에 대한 예측을 할 수 없기 때문에 에이전트 스스로 학습 능력이 있어야 함
-미리 예측할 수 있는 상황이 있더라도 무엇이 최선인지 사람이 모를 때는 에이전트 스스로 더 나은 행동을 위한 학습을 할 필요가 있음
-학습을 통해서 에이전트 스스로가 행동을 결정할 수 있는 지식을 갖도록 함 -
학습은 성능을 개선시키는 쪽으로 에이전트에 대한 행동 결정 메커니즘 수정의 과정이다(행동 결정 방법을 고치는)
-
학습 대상 요소들
-condition-action rules
-World model and/or action model
-utility, value, goals -
Data & Knowledge Representation(데이터 및 지식 표현법)
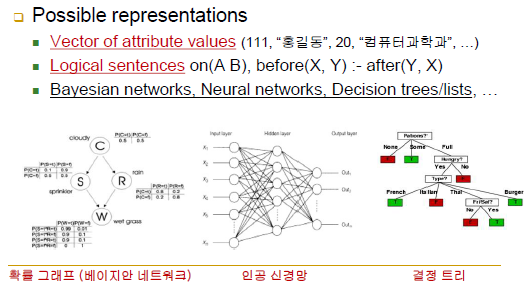
-vector of attribute values(111, "홍길동", 20, "컴퓨터과학과"..)
-logical sentences on(A,B), before(X,Y): - after(Y,X)
-data representation(입력 데이터), knowledge(출력 데이터)
-확률 그래프, 인공 신경망, 결정 트리 등등
-학습에 쓰일 수 있도록 제공되는 입력 데이터의 모양은 어떻고, 그걸로부터 만들어내야 할 지식의 형태는 어떤지를 먼저 정의해야 학습에 가장 필수적인 요건이자 학습 알고리즘을 기술할 수 있음
■Prior Knowledge(사전 지식)

-학습하기 전에 가지고 있는 지식
- Learning types
-indective learning(귀납적 학습): 많은 사례로부터 보다 일반화된 규칙들을 알아내는 것(다수의 구체적 사례들 -> 일반화된 지식), 대다수 학습의 경우임
-deductive or analytical learning(연역적, 분석적 학습): 직접 증명법/ 일반화된 지식/규칙 -> 구체적인 사례/지식/규칙(일반화된 많은 지식에 소량의 데이터로 또 다른 데이터를 이끌어내는 방법)
-연역적 학습법은 귀납적 학습법에 비해서 사전 지식을 많이 필요로 함, 귀납적 학습법은 사전의 데이터들을 많이 필요로 함
■Feedbacks to Learn From(피드백)
-Learning types(depending on feedbacks)에 따른 세 가지 경우
- Supervised learning(교사학습, 감독학습)

-입력 데이터만 주는 게 아니라 출력 라벨을 같이 줌
-어떤 입력 데이터가 들어왔을 때 어떤 것을 출력으로 내야하는 지를 쌍으로 주는 것임
-즉, 입 출력을 쌍으로 같이 주는 것이 supervised learning을 할 수 있는 준비가 된 것
-classification(분류): 출력 파트가 이산화된 값이면 분류
-regression(회귀): 출력 파트가 연속된 값이면 회귀(주가, 날씨 등등)
-ex) arch 개념학습: 막대기 그림은 input data(입력), + 또는 -는 라벨 데이터(출력) / arch의 그림만 있으면 감독학습을 진행할 수 없음, 그림(입력)에 따른 라벨 데이터(출력)가 있기에 감독학습을 진행할 수 있는 피드백 형태가 되는 것임
-Classification(분류): explosion/earthquake
-Regression(회귀): house price
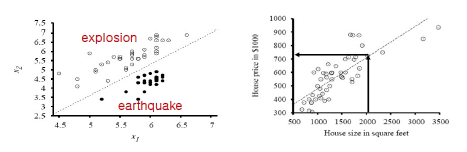
-입력 데이터는 모든 좌표에 해당하는데 label까지 붙어 있는 쌍으로 되어 있는 것은 매우 적음(Classification)
-
Unsupervised learning(비-교사학습, 무-감독학습)
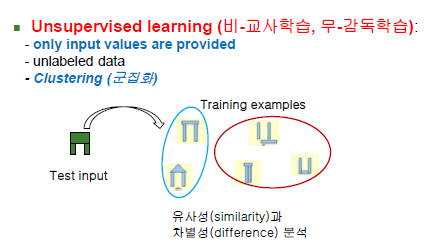
-입력 데이터만 주어지고 출력 라벨은 주어지지 않음
-Clustering(군집화)
-arch의 예시로 보았을 때 유사성과 차별성을 계속해서 분석해서 비슷한 것들 끼리 그룹화하게 됨
-supervised와 unsupervised learning은 같이 쓰이는 경우도 많이 존재
-즉, 사람이 처음부터 입력 데이터에 대한 출력 라벨을 주면 supervised learning이고, 출력 라벨 없이 에이전트 스스로가 입력 데이터들을 Clustering(군집화)하는 것을 unsupervised learning이라고 함 -
Reinforcement learning(강화학습)
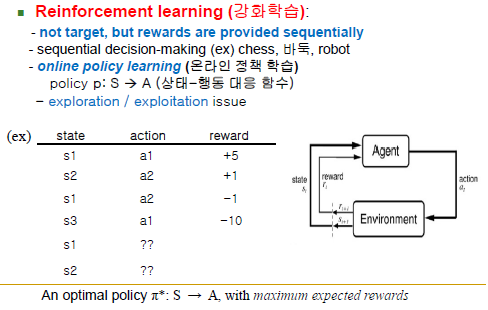
-강화학습의 reward와 supervised learning의 label과는 다름
-패널티 or 보상이라는 수치값이 주어짐(수치값은 양, 음, 크기 모두 중요)
-supervised learning은 입력 대 출력의 쌍이 존재하면 학습 가능, 학습 단계와 적용 단계가 분명하게 나뉨 / 학습하면서 적용하고, 적용하면 학습하는 경우가 일어나지 않음(선 학습 후 적용, offline learning)
-reinforcement learning은 학습과 행동이 어우러져서 돌아감, 행동 정책(policy)을 online 방식으로 학습함, 상태(입력)에 대해 정답(출력)을 주지 않음, 일단 먼저 행동하고 그 행동이 끝난 후에 행동이 얼마나 잘 됐는지에 따라 reward를 부여(선 행동 후 보상), 즉 가장 바람직한 행동 정책(policy)을 배우게 만드는 과정임(reward의 합이 커질 수 있는 방향으로 어떤 행동이 바람직한 것인지를 깨우치는 것)
■Supervised learning

-함수 f를 target function이라고 가정(목적함수), 함수 f를 알고있지는 못하는데(함수식을 모름) 대신 f가 어떤 특정 입력이 주어졌을 때 어떤 출력을 내는지에 대한 몇 가지 사례는 존재 -> An example(훈련 예)
-example(훈련 예)는 입력과 출력의 쌍으로 이루어짐( yi = f(xi) )
-위의 example이 N개 즉, 여러 개가 모이면 훈련 집합이 됨(training set)
-훈련 데이터로 미루어봤을 때 f에 근사하다고 생각되는 h함수(근사 함수)를 찾는 작업이 learning임(f 대신에 h를 사용할 수 있는데 h는 여러 사례들을 통해 굉장히 일반화된 것임)

-테스트 집합 != 훈련집합(구별되어야 함)
-일반화: new example에 대해서도 정답을 잘 맞추는 경우
-분류: on of a finite set of values(이산적)
-회귀: a number(연속적)
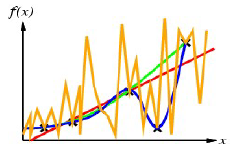
-일차, 이차 함수의 경우에는 f와 h가 충분히 가깝다고 보기 어려움
-삼차 함수의 경우에 f의 위치들을 근사 함수인 h도 100% 정확하게 다 지나가게 됨 -> h는 성공적으로 원했던 가설 함수를 찾을 수 있게 된 것임
-차수가 높아질수록 계수가 증가하기 때문에 학습 시간과 학습 데이터도 증가하게 됨
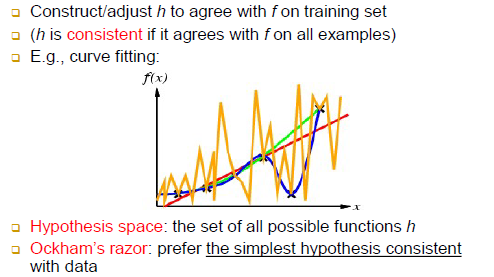
-Hypothesis space: 사실상 무한함
-Ockham;s razor: consistent한 한도 내에서는 가급적 간단한 가설 함수를 찾으려고 노력해야 함(razor: 잘라내라)
■Learning Decision Trees(DT)

-레스토랑 줄을 기다릴지 말지를 결정하는 속성들
-
Attribute-Based Representations
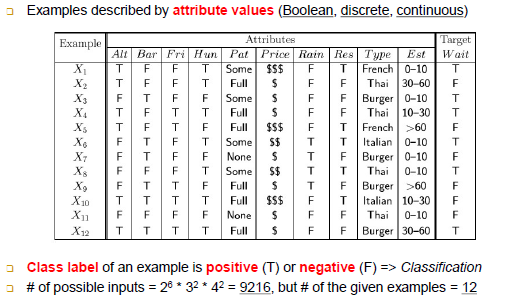
-Example은 사례(12개의 데이터(사례) 존재)
-Attributes는 속성, 테이블에 있는 값들은 속성값들
-Target Wait(라벨)는 결정 데이터
-원래 price와 WaitEstimate는 continuous한 값이지만 연속적인 값은 다루기 어렵기 때문에 discrete하게 변환함
-가능한 모든 입력 = 2^6 3^2 4^2 = 9216, 하지만 주어진 사례는 12개 -
Decision Trees
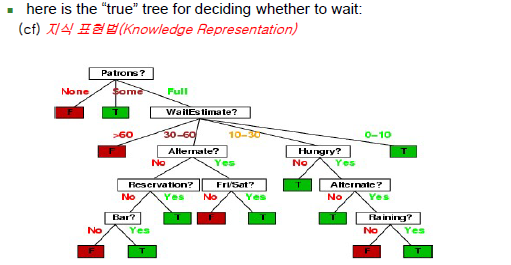
-지식 표현법 중 하나
-위의 예시는 사람이 만든 지식
-각 속성마다 최종 출력을 결정하는데 영향을 미치는 정도는 다름
-어떤 속성을 먼저 보고 기다릴지 말지를 판단할지가 중요
-전체 데이터 사례 중에서 T,F의 출력을 판별하는데 가장 도움되는 속성이 뭔지를 찾아서 루트노드로 설정, 이후 루트노드 제외하고 어떤 속성이 그 다음에 출력을 판별하는데 도움이 되는지(중요도)를 판별해서 서브트리의 루트노드로 설정하는 과정
-결정트리는 사이즈가 작으면 작을수록 좋다고 판단, 트리의 깊이와 한 노드에서 갈라지는 가짓수(branching factor)가 전체 트리의 크기를 좌우함 -
Decision Tree Learning

-결정하기까지 소요되는 시간이 줄어들게
-결국, 알고리즘에서 CHOOSE-ATTRIBUTE가 핵심
-이 함수는 새로운 서브트리의 노드를 만들어야 할 때마다 불림
-if examples is empty -> 사례가 없다 -> 말단 노드를 만들어 줌, 다수결로 결정
-if all examples have the same classification -> 모두 한쪽으로 치우쳐져 있는 상태 -> classification 바로 리턴
-attributes is empty -> 속성이 없는 상황, 속성이 별로 없던 상황에서 결정트리에 다 써먹은 상황, 그런데도 아직도 사례가 한쪽으로 정리되지 않은 상태 -> 현재의 examples를 통한 다수결 결정
-그 이후 else부분은 nomal한 부분
-best: IG가 가장 높은 값의 속성 선택
-tree: DT가 만들어지는 과정(루트 노드)
-examplesi: 부분집합을 쪼개는 것
-subtree: 재귀호출 부분 -
Choosing an Attribute
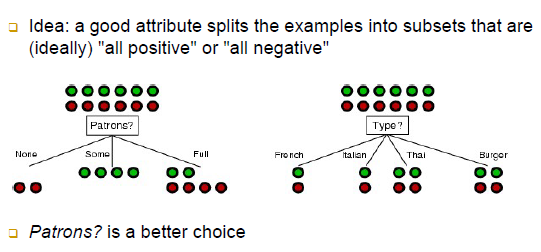
-초록색, 빨간색 공은 출력 라벨(T,F)들
-pattons필드의 부분집합에서 None과 Some은 클래스 라벨이 한 가지 종류로만 이루어져 있어 빠르게 출력 라벨 결정 가능
-Type필드는 클래스 라벨 상으로 봤을 때 모든 부분집합(4 개의 부분집합)이 혼재되어 있음. 즉, 한 번에 결정 노드(단말 노드)를 붙일수가 없음 -> 모든 부분집합들이 변별력이 좋지 않음(심지어 T,F의 개수도 똑같아 한쪽으로 치우치지 않아 더 결정하기 힘듦)
-한쪽으로 치우친 것이 좋은 속성임
-Patrons? is a better choice -
Using information Theory

-Entropy(엔트로피: 혼합도, 불순도)
-위의 예시에서 patrons의 None과 Some 부분집합의 엔트로피는 0임 -> 순도가 100%, 불순도가 0%
-Type의 모든 부분집합은 엔트로피가 1임 -> 순도가 0%, 불순도가 100%
-엔트로피가 감소하는 것이 좋은 방향임(트리가 더 짧아짐)(원 집합의 엔트로피와 부분집합들의 엔트로피의 평균을 비교했을 때 더 작아져야 좋음)
-I: 엔트로피, P: positive, N: negative -
Information Gain(IG)

-정보 획득량 == 엔트로피 감소량
-IG(A): A(속성)의 IG값 -> A속성을 적용하기 이전의 전체집합의 엔트로피 - A속성 값에 따라서 부분집합을 나누었을 때 부분집합들의 엔트로피의 평균(remainder의 값만 바뀌기 때문에 remainder값이 중요)
-IG의 값이 큰 것을 고름

-IG(Patrons) = .0541
-IG(Type) = 0
-즉, IG의 값이 더 큰 Patrons를 서브트리의 루트 노드로 결정
-각각의 부분집합의 엔트로피에 weight값을 곱해서 더하면 결국 평균이 됨(즉, 부분집합이 전체집합에서 차지하는 weight를 차등적으로 부여해서 값을 계산하게 됨)
-
Example contd.
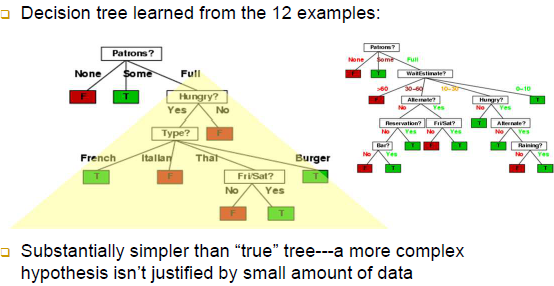
-Patrons가 루트노드일 때 후보노드로서의 Hungry에 대한 IG 값과 Patrons가 제외되고 Hungry가 서브트리의 루트노드일 때에 대한 IG값이 다름 즉, 귀찮더라도 매순간 새롭게 IG가 계산되어야 함
-자동생성과 사람이 생성한 결정트리가 조금 다른 것을 알 수 있음, 사례가 더 많으면 자동생성이 만든 결정트리가 사람이 생성한 결정트리에 다가갈 수 있음(품질이 더 높아짐) -
Performance Measurement
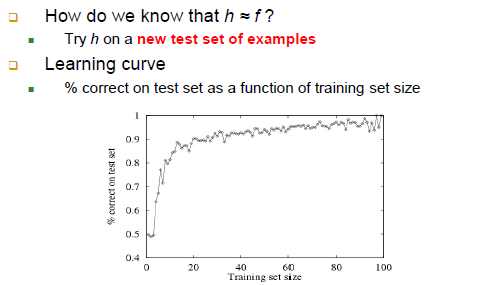
-위의 결정트리는 결국 건사함수 h
-학습 데이터가 늘어나면 늘어날수록 일반적으로 새로운 케이스에 대한 예측력이 증가하게 됨![]
