Multi-task Learning
Multi-task learning에 대한 학습을 정리
Introduction
- 머신러닝 및 딥러닝은 많은 labeled data가 필요하다.
- 데이터를 확보하기 어려운 경우 관련있는 여러 task를 동시에 학습시키는 Multi-task learning이 좋은 해결 방법이 될 수 있다.
- 연관있는 task들을 연결시켜 동시에 학습시킬 때 성능이 향상되는 것을 발견할 수 있다.
- Multi-task learning은 인간이 새로운 것을 학습할 때 이전에 학습했던 유사경험에 접목시켜 더 빨리 학습하는 것에서 영감을 얻었다.
- 이 점에서 전이학습(Transfer learning)과 유사해 보이지만, 모든 task들에서 성능향상을 지향하는 Multi-task learning과 다르게 전이학습은 target task와 source task가 확실하게 구분되어 target task의 학습에만 초점을 맞춘다.
장점
- Knowledge Transfer: 각각의 task를 학습하면서 얻은 정보가 서로 다른 task들에 좋은 영향을 준다.
- Overfitting 감소: 여러 task를 동시에 수행하기 때문에 보다 일반화된 특징표현(generalized representation)을 학습한다.
- Computational Efficiency: 하나의 신경망으로 여러 task를 동시에 수행.
단점
- Negative Transfer: 다른 task에 악영향을 미치는 task가 존재할 수 있다.
- Task Balancing의 어려움: task마다 학습 난이도가 크게 차이나면 수렴하지 않거나 강건하지 않을 수 있다.
Task Balancing의 어려움
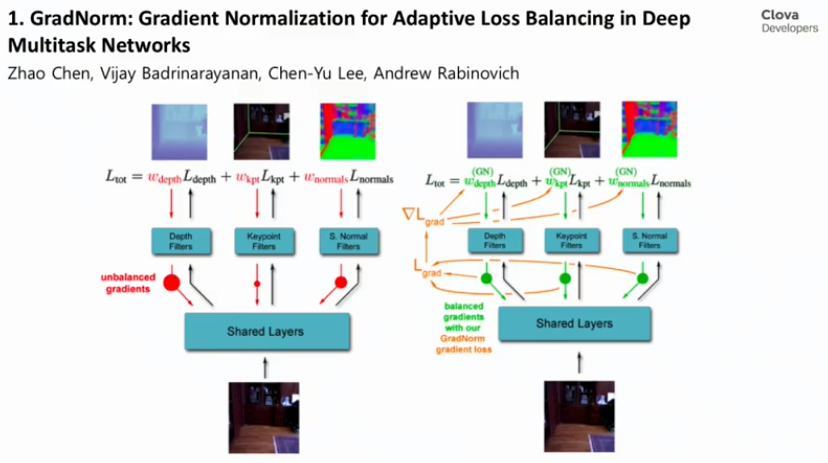
왼쪽의 그림처럼 각기 다른 task를 수행함에 있어 난이도 차이가 존재할 때 서로 다른 gradient를 전달하여 학습속도가 차이날 수 있다.
- Depth filters는 비교적 간단한 task라서 빠르게 수렴.
- Keypoint filters는 그보다 어려운 task이기 때문에 느리게 수렴.
- 이러한 수렴 속도 차이가 전체적인 모델 성능을 저해할 수 있다.
When multi-task learning makes sense
일반적으로 세 가지의 경우에 multi-task learning이 효과적일 수 있다.
1. 낮은 수준의 특징들(lower-level features)을 공유하는 경우
- 자율주행차의 경우에 신호등, 자동차, 보행자를 인식하는 것이 stop sign을 인식하는데 도움이되는 비슷한 특성을 가지고 있다.
- 모두 도로에 관련한 특성을 가지고 있기 때문
2. 일반적으로, 각 task가 가지는 데이터의 양이 비슷해야 한다.
- 전이학습(Transfer learning)과 비교될 수 있는 부분
- 전이학습은
A task에서 데이터의 양이 많고B task에서 데이터의 양이 적을 때 효과적, 전이학습의 목표는A task의 향상보다는,B task의 집중하기 때문이다.
- 전이학습은
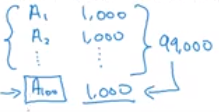
- 위의 그림처럼 의 관점에서 보면 다른 task 의 task의 정보들이 의 예측에 큰 도움을 줄 수 있다.
- 이 규칙이 꼭 지켜야만 하는 것은 아니지만 한 task의 관점에서 볼 때, 다른 task에 대한 데이터가 많을수록 효과적일 수 있다.
- 중요한 것은 의 데이터가 이미 충분히 있고 다른 task에 대한 데이터가 훨씬 더 많은 데이터를 가지는 것
3. 모든 task에 대해 충분히 큰 모델을 사용할 수 있어야 한다.
- multi-task learning처럼 하나의 모델이 여러 task를 수행할 수 있지만, 각각의 task에 서로다른 모델이 사용될 수 있다.
- multi-task learning이 이처럼 분리된 모델을 학습하는 것보다 성능이 낮은 경우는 모델이 충분이 크지 않은 경우임을 발견한 연구가 있었다.
2 Multi-task leaning methods for deep learning
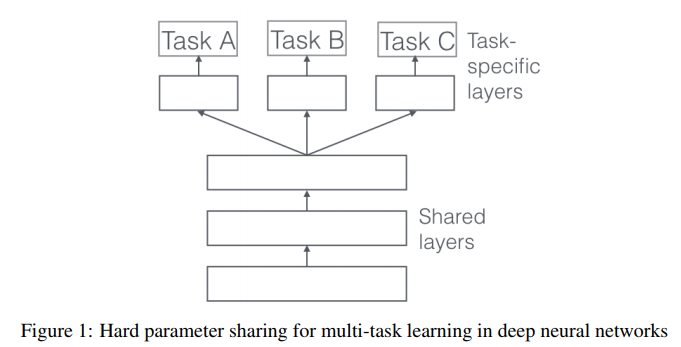
1. Hard Sharing
multi-task learning에 주로 사용되는 방법, task-specific layer를 제외한 모든 task간의 hidden layer를 공유하는 것이다.
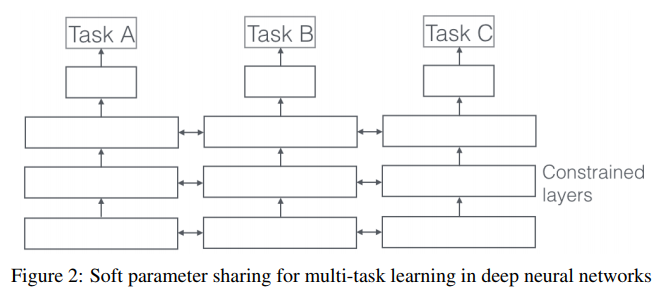
2. Soft Sharing
각각의 task가 각자 자신의 parameter를 가지며, 모델의 parameter를 서로서로 제약(regularize)하여 영향을 주고 받는다.
References

딥 러닝을 공부하는