공공데이터 포털에서 도로교통공단이 제공하는 2019년 및 2021년 사망 교통사고 데이터를 활용해 지역별, 요일별, 시간별 현황을 분석한 후 지도에 데이터를 시각화하는 작업을 수행했다.
수치로 보는 것보다 차트로 그렸을 때 직관적으로 현황을 파악할 수 있다는 것이 데이터 분석의 매력이라는 것을 느낄 수 있었다. 세련된 차트를 그릴 수는 없지만 스스로 구현해낼 수 있다는 사실에 지금은 만족하기로 한다.🙂
정부나 공공기관 및 이에 준하는 기업에서 제공하는 데이터 자료들은 대부분 EUC-KR로 인코딩되어 있다. 따라서 matplotlib을 사용해 시각화를 구현할 것이라면 한글이 깨지지 않도록 인코딩을 바꿔주는 등 원시 데이터를 전처리하는 과정이 필요하다. 반대로 써드파티 라이브러리인 plotly를 사용할 경우 원래 인코딩 값을 유지해도 무방하다.
또한 판다스 라이브러리는 csv파일을 작업할 때, 마지막 열이 공백의 값을 가지더라도 오류를 내지 않기 때문에 공백을 삭제하는 전처리 작업도 필요하지 않다.
오늘은 기술 블로그를 기존과는 다른 방식으로 작성한다. 코드를 다시 작성해보면서 코드의 의미와 기능을 복습하고자 한다.
0. 파이썬에서 사용할 라이브러리/모듈 불러오기
import pandas as pd
import plotly.express as px1. 데이터 준비하기
df = pd.read_csv('파일경로', encoding = 'EUC-KR')
df.head() #5행의 데이터 확인
df.info() #entries: 데이터 수, non-null count: 빈 값 여부, Dtype:데이터 형태인덱스의 수, 컬럼별 데이터 형식 등을 확인할 수 있다
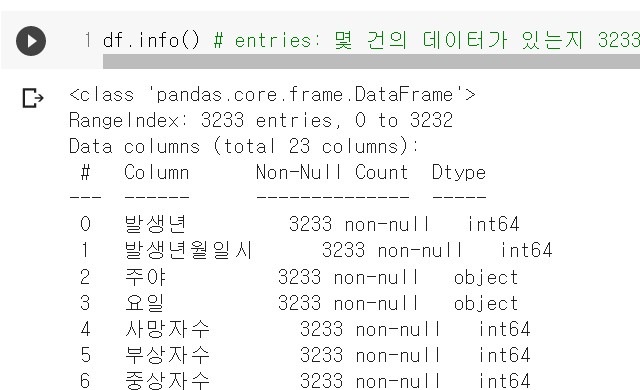
2. 교통사고 데이터 정제(전처리)
df = df.astype({'발생년월일시':'string'})
# '발생년월일'과 '시'를 분리해서 데이터를 분석에 활용하기 위해
# int(정수 숫자형)는 슬라이싱 할 수 없기에 문자형(string)으로 딕셔너리 문법을 이용해 형변환
df['발생시간'] = df['발생년월일시'].str[8:]
# 발생년월일시의 문자열 중 '시'를 슬라이싱하고 새로운 컬럼을 생성하여 데이터를 담는다. 원시자료에 이미 존재하는 컬럼명을 사용하면 해당 컬럼에 데이터를 덮어씌운다.
# 즉, 2019010100 --> 00 값을 '발생시간'컬럼에 담기
# 새로 생성한 컬럼은 기존 자료 맨 뒤에 붙는다.
# 이 때 .str 값을 넣지 않으면 발생년월일시의 7번째 행부터 끝까지의 값을 담게 된다.참고. slicing과 split 구분
1) slicing: 문자열이 연속되어 어떠한 자를 수 있는 기준이 없으나 컬럼 내 모든 데이터의 포맷이 동일하면 사용 *int형은 슬라이싱 불가 (만약 컬럼 내 데이터의 형태가 모두 다르면 padding기법을 통해 0으로 포맷을 맞춘 후 슬라이싱)
2) split: 공백이나 쉽표, 언더바 등과 같은 특수기호가 있어 자를 기준이 있을 경우 사용
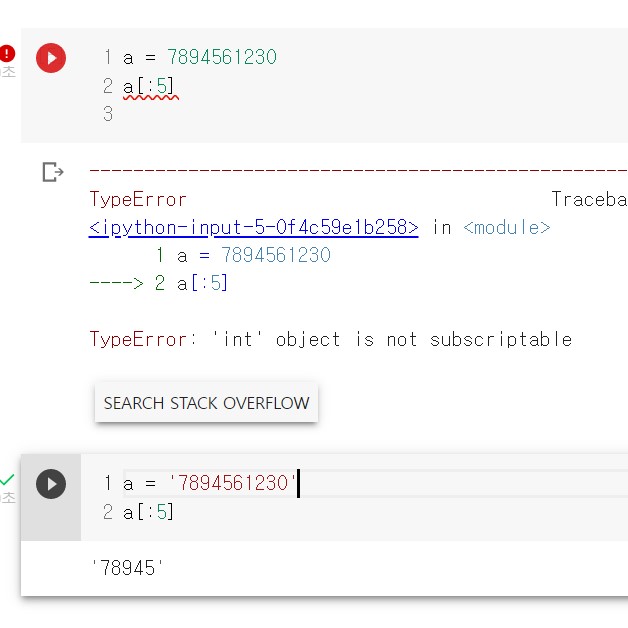
발생년월일시 데이터 형태: int -> str
따라서 발생년월일시에서 스플릿한 '발생시간' 컬럼 역시 str 형태이므로 int64로 바꾼다.
df = df.astype({'발생시간':'int64'})발생년월일시 컬럼의 데이터는 현재 '발생년월일시'로 구성된 구분자 없는 문자열의 형태이다. 가독성을 높이기 위해 날짜 형태로 데이터를 바꾼다.
이때 int와 str과 같이, 단순히 컴퓨터가 따옴표만 붙이고 떼서 형식을 바꾸는 것이 아니라 날짜 형태와 같이 구체적인 포맷으로 바꿀 때는 'astype'으로 처리 불가
df['발생년월일시'] = pd.to.datetime(df['발생년월일시'].str[:8],
format=%Y-%m-%d', errors = 'raise')
# errors = 'raise': null값이 이거나 index가 맞지 않는 등 적용할 수 없는 오류가
발생하면 알려주고 멈춰라. raise 대신 ignore 하면 그런 값이 나와도 무시하고 처리
df.info()아래와 같이 발생년월일시 컬럼의 데이터 형식이 바뀐 것을 확인할 수 있다.
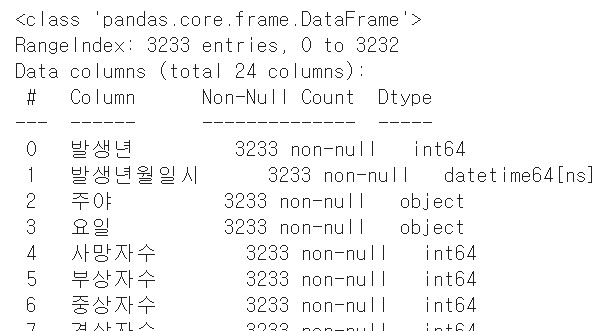
3. 차트 그리기
1) 날짜 및 시간별 사망 교통사고 현황(산점도)
fig = px.scatter(df, x = '발생년월일시', y='발생시간', color='발생지시도', hover_data['발생시간'])
fig.show()
# 날짜와 시간 간에 상관관계가 있는지 확인하는 차트로
범례를 클릭해 차트에서 지우면 지역별 차트를 파악 가능
# hover_data: 점 위에 마우스를 올리면 기본적으로 x와 y값이 출력되는데
'발생시간'을 추가로 설정해 함께 표시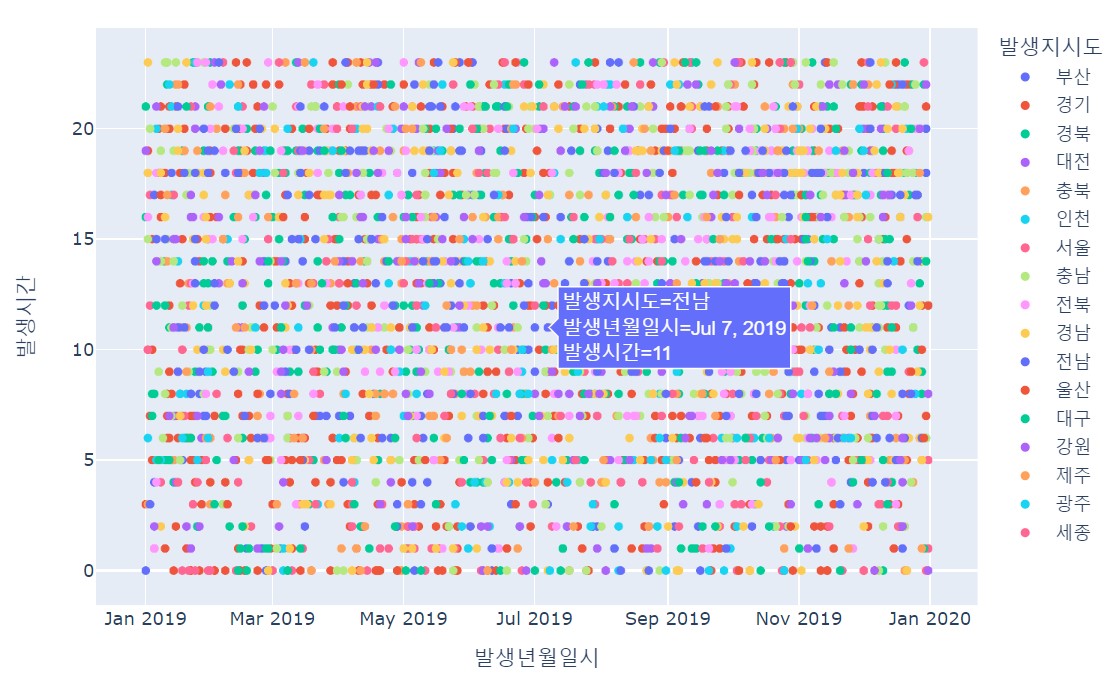
size 값을 '사망자수'로 설정하면, 교통사고 건에 대한 사망자수 크기에 따라 크고 작은 버블을 그린다. 하지만 만약 같은 날과 시간에 여러 건에 교통사고가 발생한 경우 데이터 순서에 따라 마지막으로 그려진 버블만 hover_data를 확인할 수 있다.
fig = px.scatter(df, x ='발생년월일시', y='발생시간', color='발생지시도', size='사망자수', hover_data=['발생시간'])
fig.show()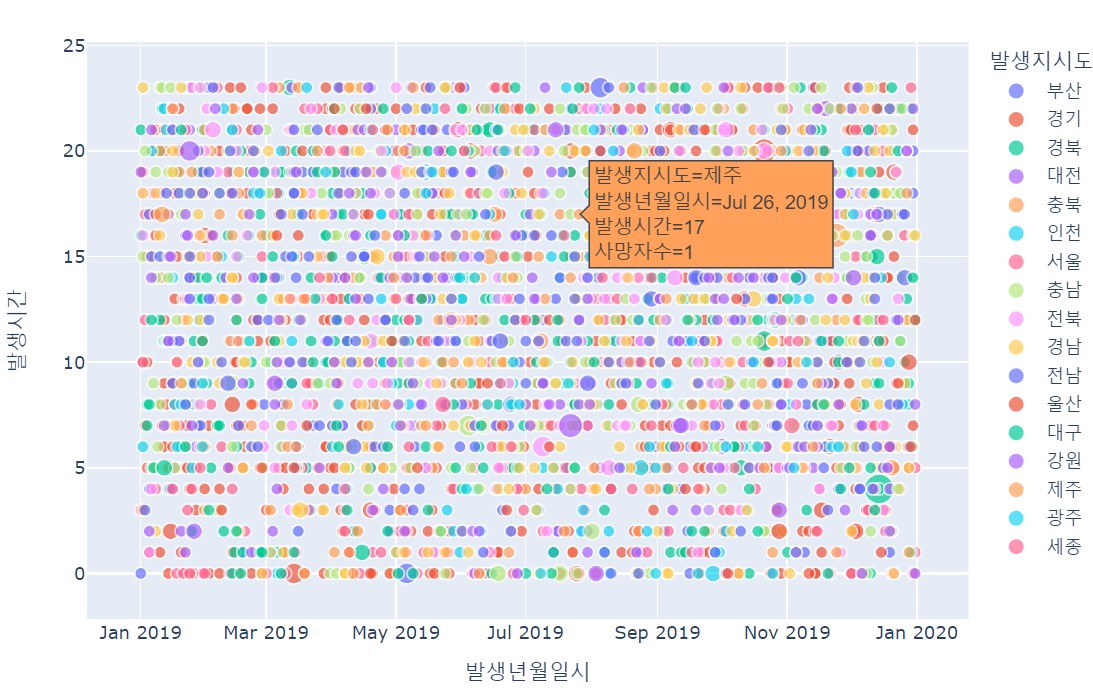2) 시간대별 사망 교통사고 현황(막대차트)
fig = px.bar(df, x='사망자수', y='발생시간', orientation='h', color ='발생시간')
fig.show()
#orientation 기본값(기재X)은 수직, h값을 넣으면 수평으로 그림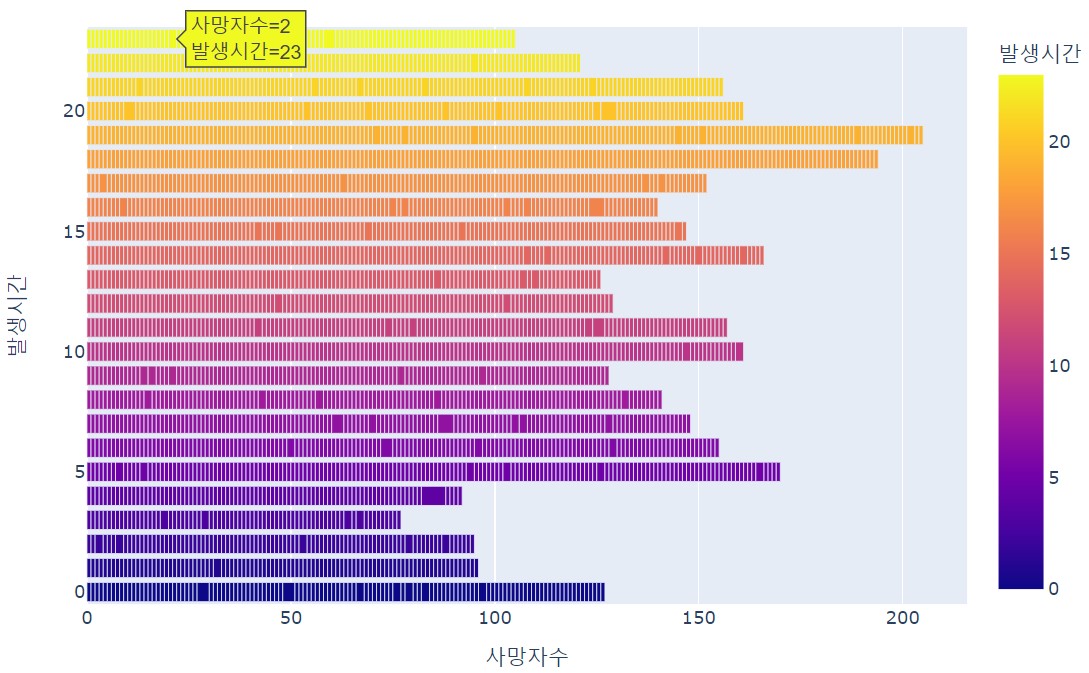
orientation 기재하지 않고 기본값인 수직으로 차트 그리기
fig = px.bar(df, x='발생시간', y='사망자수', color ='발생시간')
fig.show() 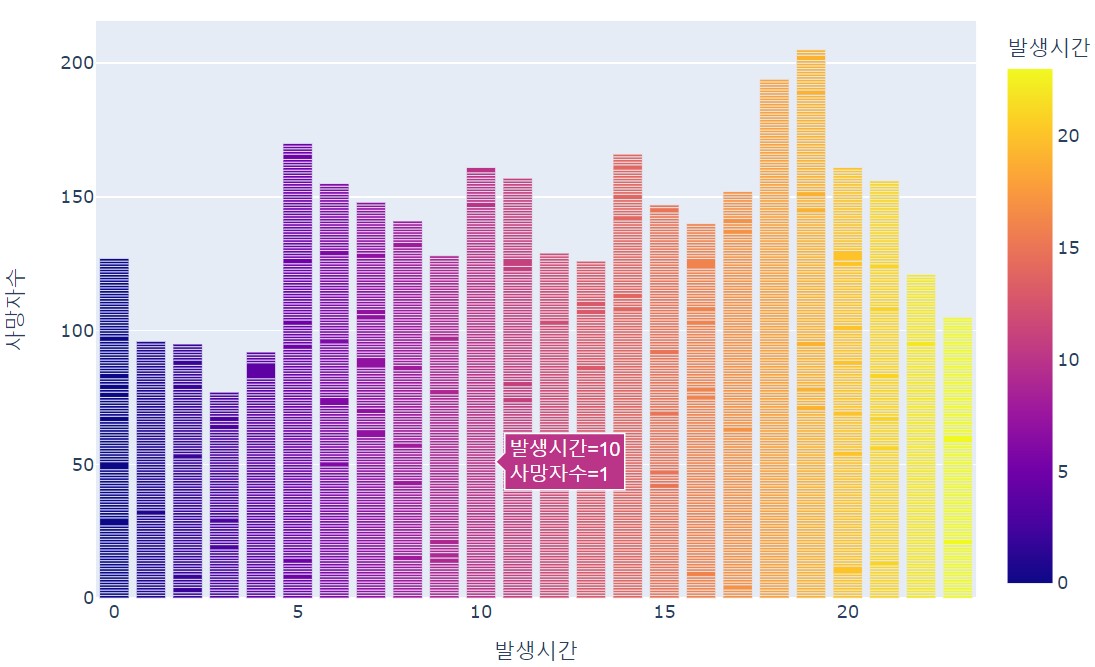
시도별 교통사고 사망자 현황
fig=px.bar(df, x='사망자수', y='발생지시도', orientation='h')
# 수직보다 수평으로 그리는 것이 차이를 더 확연하게 볼 수 있다.
fig.show()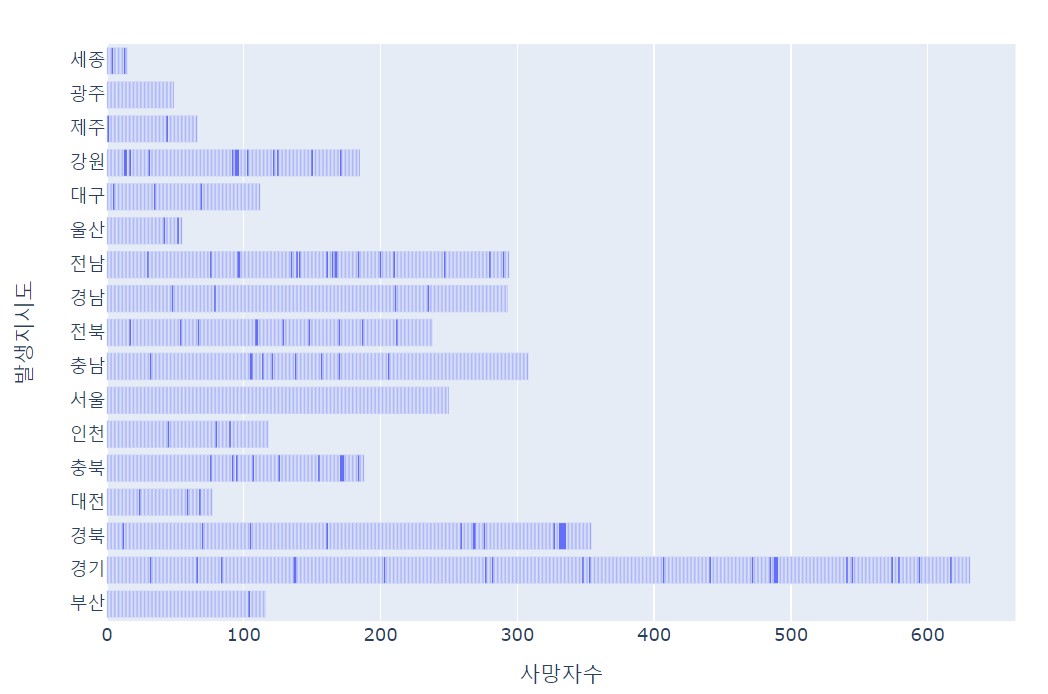
요일별 교통사고 사망자 현황
fig = px.bar(df, x = '사망자수', y='요일', color='요일', orientation='h')
fig.show()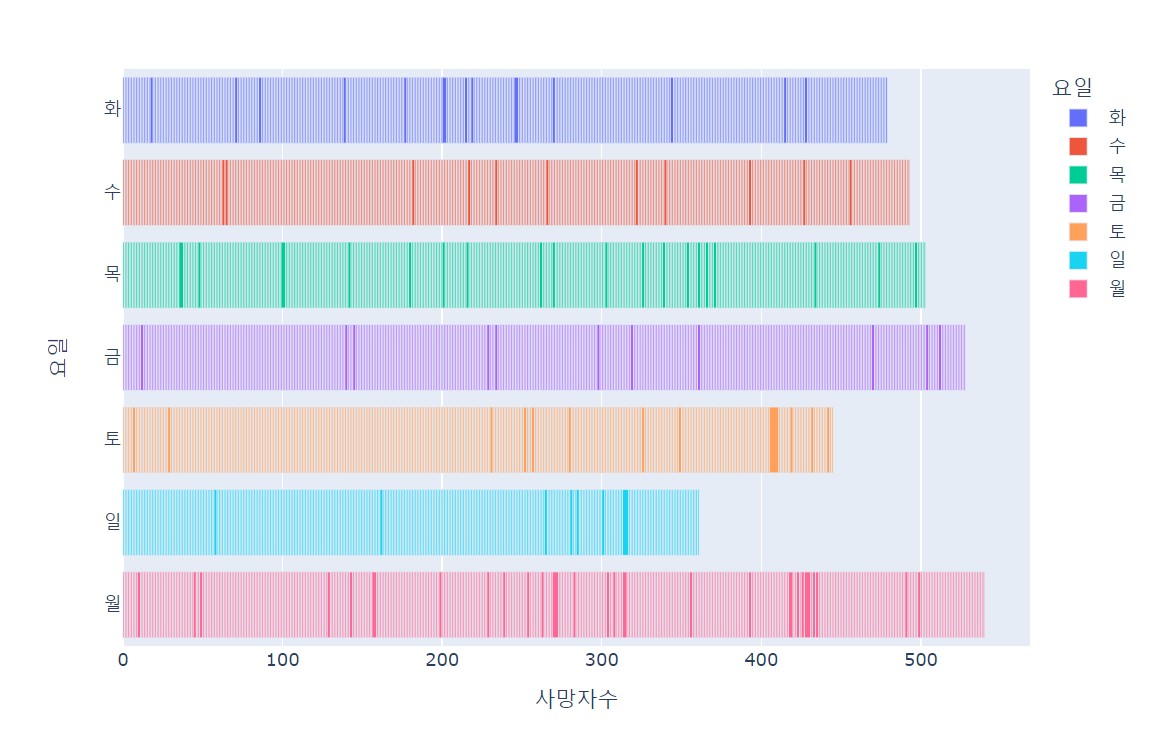
참고.너비 값을 (예시. width = 1500) 입력하면 차트의 가로 길이를 설정할 수 있다.
4. 대전지역 사망 교통사고 차트 그리기
1) 데이터 준비하기
기존 데이터프레임에서 발생지시도가 대전인 자료들만 추출하여 새로운 데이터프레임을 만든다.
dj_df = df[df['발생지시도']=='대전']
dj_df.head()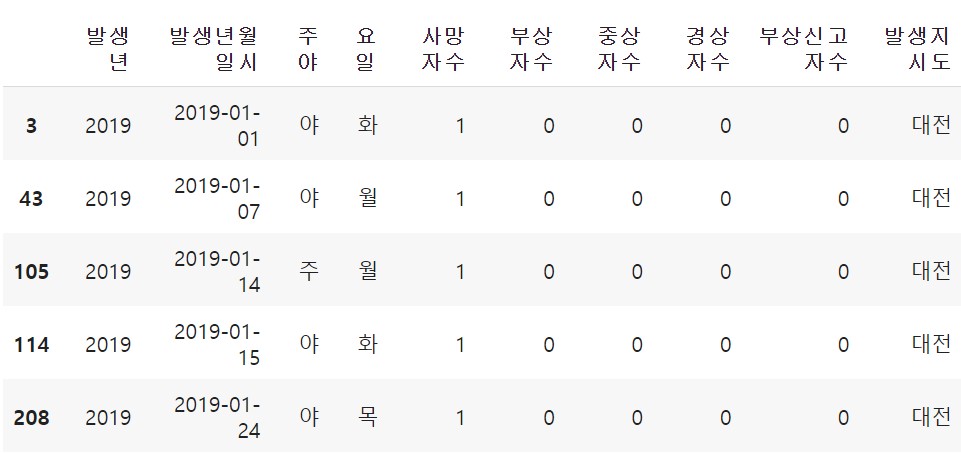
발생지시도가 대전인 교통사고 건만 추출한 데이터프레임이므로 index값 3, 43, 105, 114, 208,...와 같이 비연속적인 것을 알 수 있다.
대전지역 또한 전국의 교통사고 차트를 그린 것처럼 데이터프레임 이름만 바꾼 후 x와 y축의 값을 지정해주면 차트를 그릴 수 있다. (추가 설정은 선택사항)
2) 대전지역 발생지시군구의 사고유형별 사망 교통사고 현황
fig px.bar(dj_df, x='사고유형', y='사망자수', color='발생지시군구')
fig.show()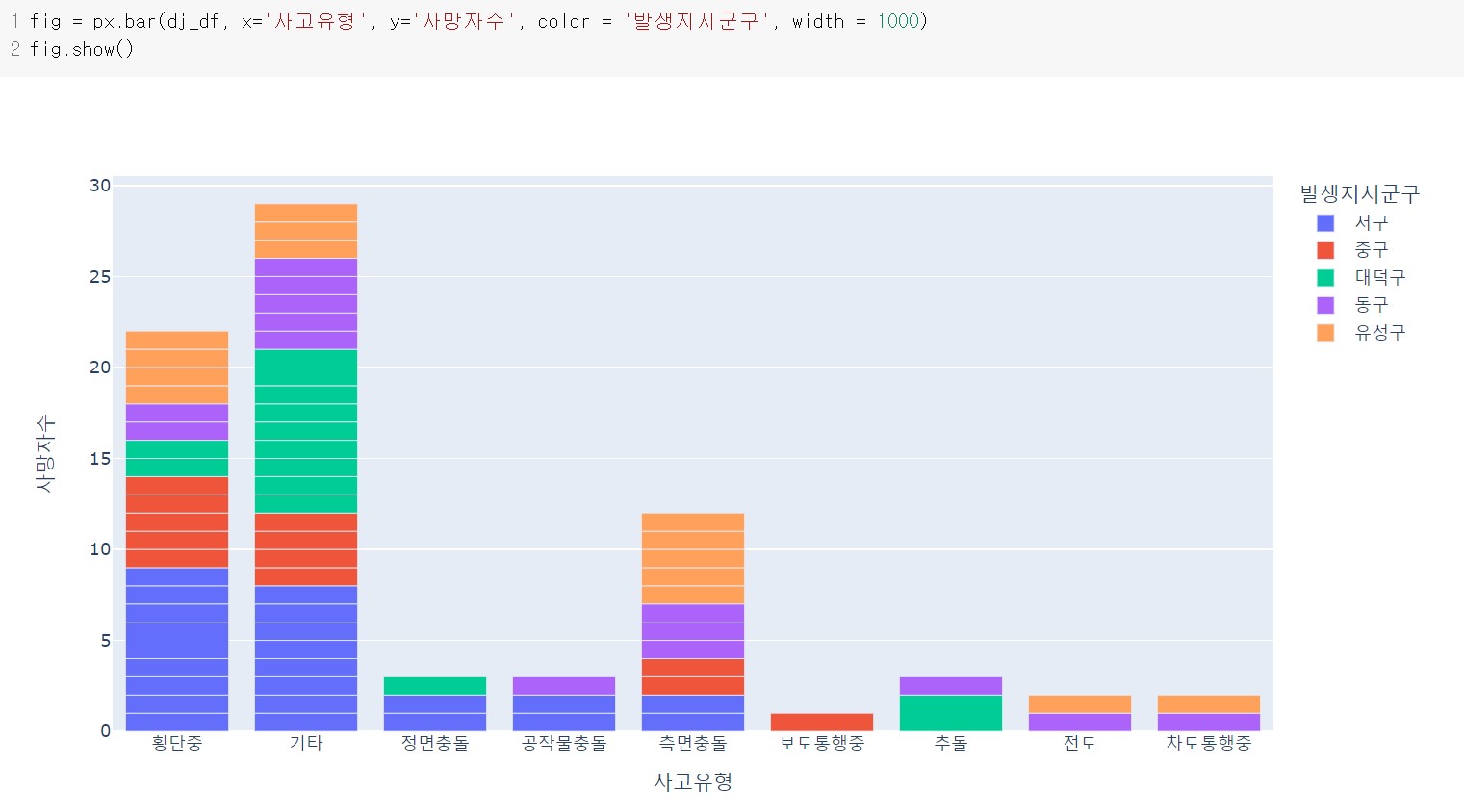
3) 지도를 활용하여 교통사고 현황 분석
제일 먼저 교통사고 자료를 그릴 지도를 불러온다.
import folium
map = folium.Map(location=[36.321665, 127.378953]) #대전시청의 좌표
# 지도를 그릴 때, 반드시 위도와 경도 값을 입력해야 한다. 위도 경도값을 가진 해당 지역을 먼저 그리고
확대, 축소 및 이동 시 점차적으로 그린다.(격자무늬 형태)
# 보통의 해당지역 중심지인 ~시청을 중심좌표로 설정한다.
mapCircleMarker의 위치: 교통사고 발생 좌표(위도,경도)
CircleMarker 크기: 교통사고 사망자수와 경상자수의 합계
dj_df = dj_df.astype({'사망자수':'float64'})
dj_df = dj_df.astype({'경상자수':'float64'})
# 사망자수와 경상자수의 원래 형태는 int(정수형)이었다. 하지만 CircleMarker의 크기는 기본적으로 R(radius)*
3.1415...이므로 실수형이다. 따라서 Marker의 크기에 대응시킬 사망자수와 경상자수 역시 실수형으로 바꿔주어야
오류가 발생하지 않는다. 따라서 딕셔너리 문법을 활용해 데이터 형태를 변경한다.이제 dj_df에 있는 모든 행을 지도 위에 더해주는데 이때, for문을 활용한다.
for dj_ac in dj_df.index:
cnt = dj_df['사망자수'][n] + dj_df['경상자수'][n]
folium.CircleMarker([dj_df['위도'][n],dj_df['경도'][n]], radius=cnt*10,
popup=dj_df['사망자수'][n]+dj_df['경상자수'][n], color='yellow',
fill_color='#3186CC').add_to(map)
map cnt는 CircleMarker의 크기를 설정하는 명령어이다. radius=cnt*10: 마커의 줌 값을 설정하는 것으로 기본 값은 10이고 숫자를 키울 수록 마커의 크기가 전체적으로 커진다. popup값은 마커를 클릭했을 때 팝업되는 창을 의미하는데 여기서는 사망자수와 경상자수의 합계치를 나타내도록 설정하였다.
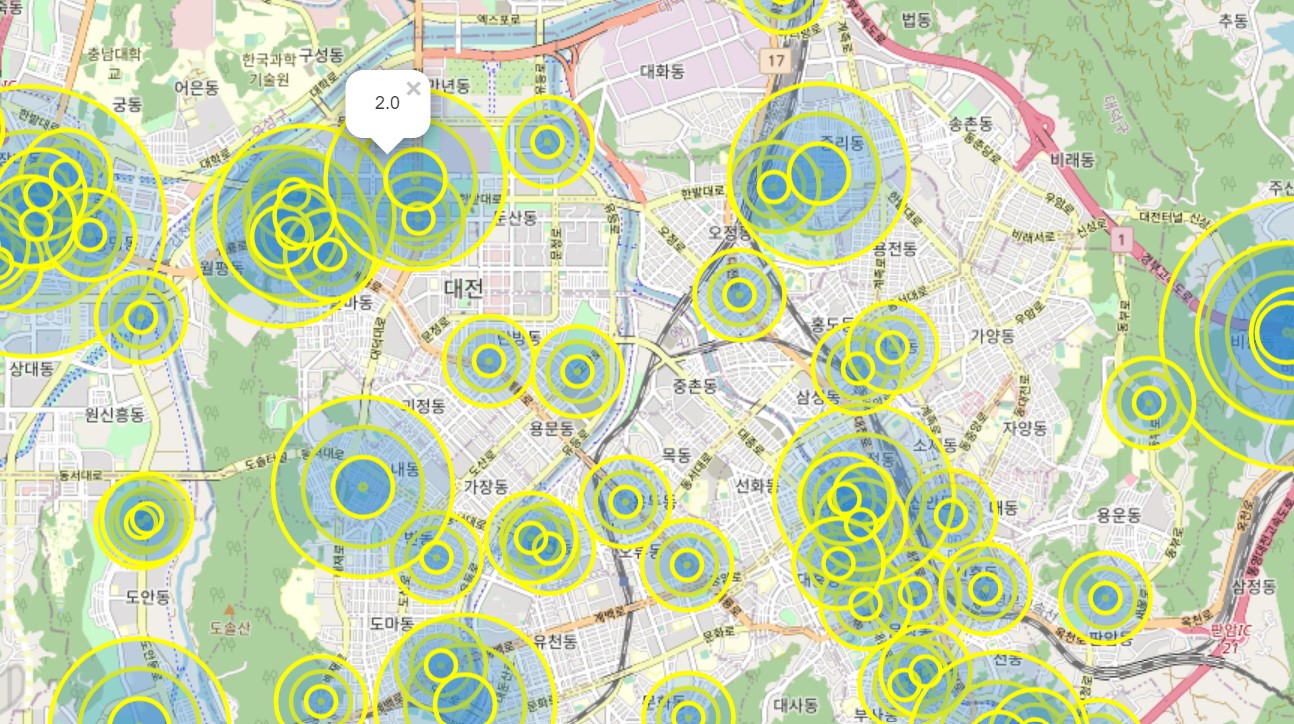
명령을 여러번 실행시킬수록 그 자리 위에 덧칠하는 셈이므로 만약 마커를 수정하고 싶다면 map설정을 새로이 한 후에 다시 그려야 한다.
4) 시각화한 지도를 HTML형태로 저장.
map.save('2016_대전 교통사고 현황.html')<참고> dj_df['사망자수']와 dj_df['사망자수'][n]의 차이
전자는 대전 데이터 프레임의 사망자수 컬럼에 있는 모든 행값을 가져오라는 의미이고,
후자는 대전 데이터 프레임의 사망자수 컬럼에 있는 n번째 인덱스 값을 가져오라는 의미

