[논문정리] MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
논문
https://arxiv.org/abs/2112.00431
Abstract
최근의 video-language research 관심이 높아지면서 large-scale datasets도 함께 발전되었다. 그와 비교해서 video-language grounding task를 위한 datasets에는 제한된 노력이 들었고, 최신 기술들은 대체로 hidden dataset biases에 overfit 되는 경향이 있다.
이 논문에서는 MAD(Movie Audio Descriptions), 기존 video datasets을 text annotations으로 보강하는 패러다임에서 벗어나 주류 영화의 사용 가능한 audio descriptions를 crawling 하고 aligning 하는 데 중점을 둔 새로운 benchmark, 를 제안한다.
1. Introduction
👀 Imagine you want to find the moment in time, in a movie, when your favorite actress is eating a Gumbo dish in a New Orleans restaurant.
film를 직접 scrubbing 하면서 그 순간을 찾으려고 할 수 있지만 이런 과정은 tedious & labor-intensive.😵
이런 natural language grounding 작업은 computer vision 커뮤니티에서 활발하게 연구되고 있고, 영화의 smart browsing 뿐만 아니라 smart video search, video editing 및 기억 장애 환자 지원에 이르기까지 다양한 실제 응용 프로그램에서 적용될 수 있다.
이러한 발전에도 불구하고, recent works have diagnosed hidden biases in the most common video-language grounding datasets.
💢 several grounding methods only learn location priors, to the point of disregarding the visual information and only using language cues for predictions.
최근 방법들이 new metrics or debiasing strategies 를 제안해 이 한계를 우회하려고 시도해도, 기존 grounding datasets가 진행 상황을 평가하기 위한 올바른 설정을 제공하는지 여부는 여전히 불확실하다.
🤔 WHY?
- video-language grounding 모델에 쓰이는 datasets는 원래 captioning or retrieval 을 위해 수집되었기 때문에 high-quality(and dense) language의 temporal localization을 요구하는 grounding task에는 알맞지 않다.
- language 에 대한 temporal anchors 는 시간적으로 편향되어 어떤 visual features으로부터도 학습하지 않고 결국 특정 행동에 대한 temporal priors 에 overfitting 되어 generalization 을 제한할 수 있다.
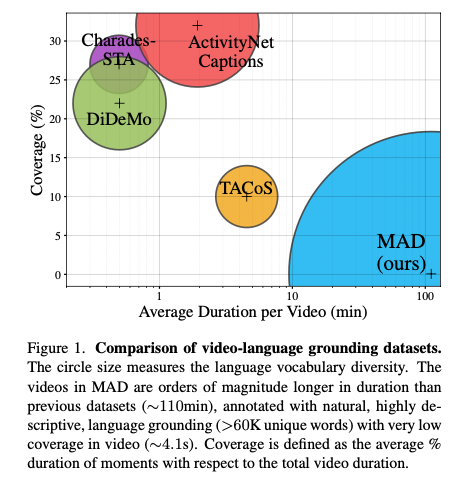
이 논문에서는 MAD(Movie Audio Descriptions)라는 새로운 large-scale dataset으로 이 한계를 다룬다.
✨ MAD(Movie Audio Descriptions)
- MAD는 text-to-video retrieval 를 조사할 수 있도록 audio descriptions를 활용하는 작업인 LSMDC dataset을 기반으로(and includes part of) 구축한다.
- LSMDC 와 비슷하게, 저자들은 crowd-sourced annotation platforms 에 의존하는 standard annotation pipelines 에서 출발하는데, 대신에 시각 장애가 있는 청중을 위해 영화에 대한 전문적이고 근거 있는 audio descriptions을 활용하는 scalable data collection strategy 를 채택했다.
As shown in Figure 2, MAD grounds these audio descriptions on long-form videos, bringing novel challenges to the video-language grounding task.

💡 Data collection approach
- transcribing the audio description track of a movie.
- automatically detecting and removing sentences associated with the actor’s speech.
- yielding an authentic “untrimmed video” setup where the highly descriptive sentences are grounded in long-form videos.
Figure 2 에서 보이는 것과 같이, MAD 에는 평균 110분 이상 길이의 비디오 와, 비디오에 균일하게 분포되어 있고 어휘의 다양성을 가장 많이 유지하는 short time segment 를 다루는 grounded annotations 가 포함되어 있다. MAD의 Video grounding 은 문장의 평균 적용 범위가 최근의 데이터셋 보다 훨씬 작기 때문에 비디오에 대한 더 자세한 이해가 필요하다.
👊 Exciting challenges with MAD
- First, the video grounding task is now mapped into the domain of long form video, requiring a more nuanced understanding of the video and language modalities.
- Second, having longer videos means producing a larger number of segment proposals, which will make the localization problem far more challenging.
- Last, these longer sequences emphasize the necessity for efficient methods in inference and training, mandatory for real-world applications.
2. Related work
Video Grounding Benchmarks
대부분의 최근 video grounding datasets는 다른 computer vision 작업과 목적을 위해 만들어진 다음에 annotation을 달았기 때문에 여러 제한이 있다. ⇒ annotations contain distinct biases where language tokens are often coupled with specific temporal locations.❗️
😀 MAD는?
- MAD는 keywords가 특정한 temporal regions와 연관되어 있지 않고, annotation timestamps가 video의 지속 시간보다 훨씬 짧기 때문에 이러한 단점을 방지한다.
- 또한, Charades-STA와 달리 hyper-parameter tuning을 위한 official validation set를 정의한다.
- MAD covers a broad domain of actions, locations, and scenes.
- MAD는 광범위한 영화 장르에서 다양한 visual 및 liguistic content 집합을 받는다.
- MAD는 최대 3시간의 long-form 비디오에서 언어 기반 솔루션을 탐색할 수 있다.
Audio Descriptions
Similar to LSMDC(Large Scale Movie Description Challenge) dataset. But, MAD sizes the potential of movies’ audio descriptions for a new scenario: language grounding in videos.
3. Collecting the MAD Dataset
Independent strategies for creating the training and testing set.
- Training set : we aim at automatically collecting a large set of annotations
- Testing set : we re-purpose the manually refined annotations in LSMDC.
3.1 MAD Training set
MAD는 시각 장애인 청중들이 영화에 접근하기 쉽게 전문적으로 만들어진 audio descriptions 에 의존하고 있다. 이런 descriptions은 가장 관련있는 시각적 정보를 풍부한 이야기로 설명하는 것으로 구체화할 수 있고, 그래서 매우 descriptive하고 diverse한 언어를 채택한다.
전문적인 이야기꾼이 audio track을 큐레이트 하면 영화를 설명하기 위해 상당한 노력과 평균 30시간 정도의 작업 시간이 필요하다. 이에 비해 Amazon Mechanical Turk 서비스를 사용했던 이전의 dataset은 3시간 정도의 작업시간이 필요하다.
Data Crawling
모든 상업 영화가 audio description이 배포되지는 않기 때문에, 3rd party creator 로부터 얻을 수 있다.
(we crawl our audio descriptions from a large open- source and online repository)
💢 Problem is the audio descriptions can be mis-aligned with the original movie.
(from a delay in the recording of the audio description or from audio descriptions being created from different versions of the movie.)
Alignment and Cleanup
audio description track이 영화의 original audio를 포함하고 있기 때문에, 둘 사이의 overlapping segment의 cross-correlation을 maximizing 함으로써 misalignment를 해결 할 수 있다.
- : original audio signal
- : audio description signal
- : time delay between the two signals.
- : cross-correlation function
💡 The maximum of the cross-correlation function indicates the point in time where the signals exhibit the best alignment.
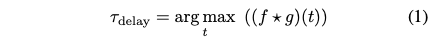
가 가능한 가장 좋은 alignment를 정의한다는 것을 확인하기 위해, 우리는 여러(i.e., 20) 균일하게 분산된 temporal windows 에 대해 synchronization strategy를 실행한다.
모든 windows 에 대해 추정된 delays가 20 samples distribution의 median을 기준으로 최대 $±$0.1초 범위 내에서 서로 일치하는지 확인하고, 이 기준을 만족하지 못하는 영화는 버린다.
Audio Transcriptions and Verification
두개의 audio tracks가 aligned 되고 나면, Microsoft's Azure Speech-to-Text 서비스를 사용해 audio description 파일을 transcribe 한다.
이 스텝에서, original video stream에 시간적으로 기반을 둔 문장을 가지고 있는데 여기에서 textual form의 audio description만 유지 한다.
3.2 From LSMDC to MAD Val/Test
MAD의 val/test sets 는 영화의 audio descriptions 에도 의존하고 있다. 저자들은 training에서 주석이 자동으로 생성되기 때문에, validation과 test splits에서의 noise를 minimize하도록 했다.
→ we avoid the automatic collection of data for these sets and resort to the data made available by the LSMDC dataset.
- LSMDC have clean language and precise temporal boundaries, but only made available as video chunks, not full movies.
- long-form video language grounding에서도 가능한 데이터를 만들기 위해 저자들은 LSMDC의 182개 videos에서 162개를 수집하고 audio descriptions도 수집했다.
- visual information까지 동기화 하기 위해 CLIP 사용
-
Use CLIP to extract five frame-level features per second for both the video chunks from LSMDC and our full-length movie and use cross-correlation score to compute delay.
→ In doing so, we obtain large and clean validation and test sets 😀
-
3.3 MAD Dataset Analysis
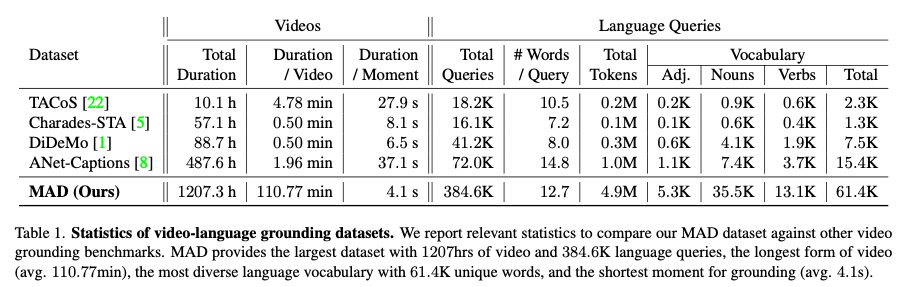
Scale and Scalability
- MAD is the largest dataset in video hours and number of sentences. (training, validation, and test sets consist of 488, 50, and 112 movies, respectively.)
- MAD’s videos are full movies which last 2 hours on average, in comparison other datasets spans just a few minutes.
Vocabulary Size
- Table 1 shows that MAD contains the largest set of adjectives, nouns, and verbs among all available benchmarks.
- The number of sentences in MAD training, validation, and test is 280.5K, 32.1K, and 72.0K, respectively.
Bias Analysis
- There is clear biases in current datasets: Charades-STA, DiDeMo, and ActivityNet-Captions. They are characterized by tall peaks at the beginning and end of the video, meaning that most temporal annotations start at the video’s start or finish at the video’s end.
- This bias is learned quickly by modern machine learning algorithms, resulting in trivial groundings that span a full video.
- MAD has an almost uniform histogram. This means that moments of interest can start and end at any point in the video.
- In Figure 3c, MAD is characterized by shorter moments on average, having a long tail distribution with moments that last up to one minute.
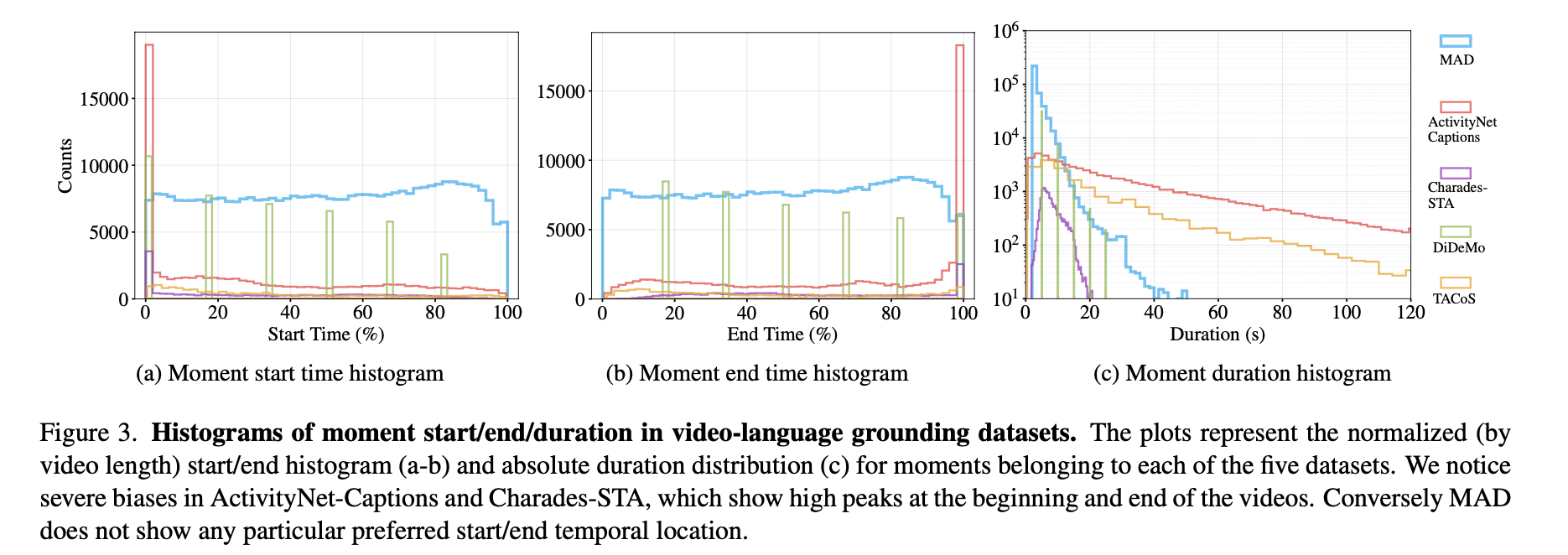
Figure 3 plots the histograms for start/end timestamps of moments in all grounding datasets.
4. Experiments
We first describe the video grounding task in the MAD dataset along with its evaluation metrics and then report the performance of four selected baselines.
Task.
- video-language grounding task (aims to localize a temporal moment in the video that matches the query.)
Metric.
- Recall for ().
Baselines.
- Oracle
- Random Chance
- CLIP
- VLG-Net
4.1 Grounding Performance on MAD
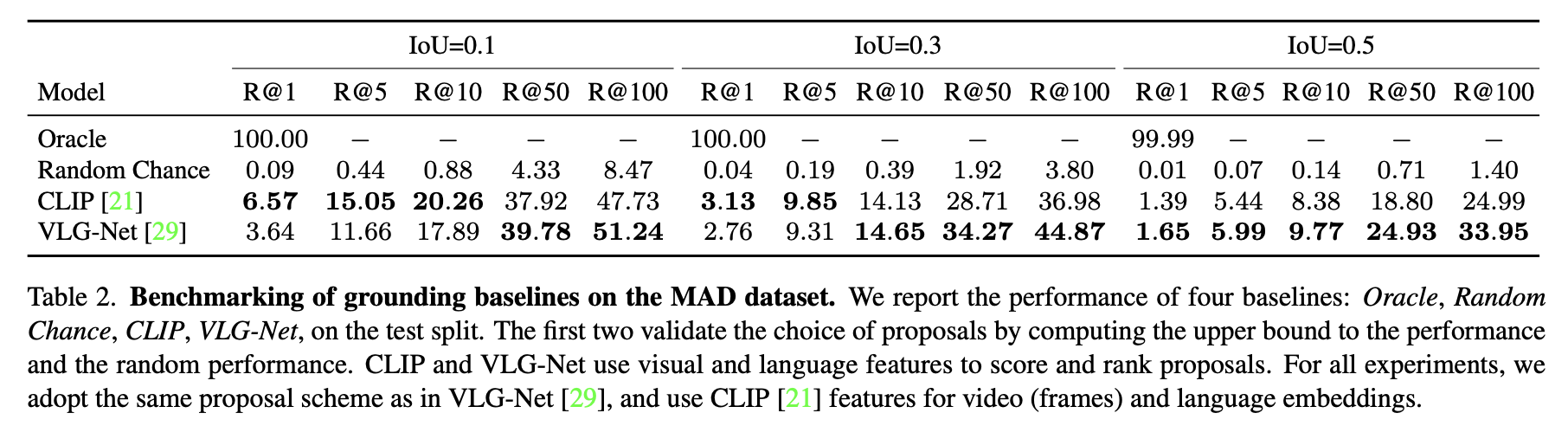
Table 2 summarizes the baseline performance on MAD.
- The Oracle evaluation achieves a perfect score across all metrics except for IoU=0.5. Only a negligible portion of the annotated moments cannot be correctly retrieved at a high IoU (0.5).
- The low performance of the Random Chance baseline reflects the difficulty of the task, given the vast pool of proposals extracted over a single video.
- The CLIP baseline is pre-trained for the task of text-to-image retrieval, and we do not fine-tune this model on the MAD dataset. Nevertheless, when evaluated in a zero-shot fashion, it results in a strong baseline for long- form grounding.
- Although VLG-Net is trained for the task at hand, it achieves comparable or better performance with respect to CLIP only when a strict IoU (IoU=0.5) is considered. However, it lags behind CLIP for most other metrics. We believe the shortcomings of VLG-Net are due to two factors.
- (i) This architecture was developed to ground sentences in short videos, where the entire frame-set can be compared against a sentence in a single forward pass.
- (ii) VLG-Net training procedure defines low IoU moments as negatives, thus favoring high performance only for higher IoUs.
4.2. The Challenges of Long-form Video Grounding
- Investigate how the performance changes when the evaluation is constrained over segments of the movie.
- Explore how methods behave as the size of the movie chunks changes.
- Split each video into non-overlapping windows (short videos), and assign the annotations to the short-video with the highest temporal overlap.
Short-video Setup
- The upper bound performance Oracle slightly decreases to 99.42% for IoU=0.5. This is a consequence of the division into short videos, which occasionally breaks down a few ground truth moments.
- The Random Chance baseline reports increased performance as the number of proposals generated is reduced. In particular for R@5-IoU=0.1, the performance increases from 0.44% to 15.69%, demonstrating that the short-video setup is less challenging compared to MAD’s original long-form configuration.
- In a similar trend, performance substantially increases for both CLIP and VLG-Net baselines, with the latter now obtaining the best performances, in all cases.
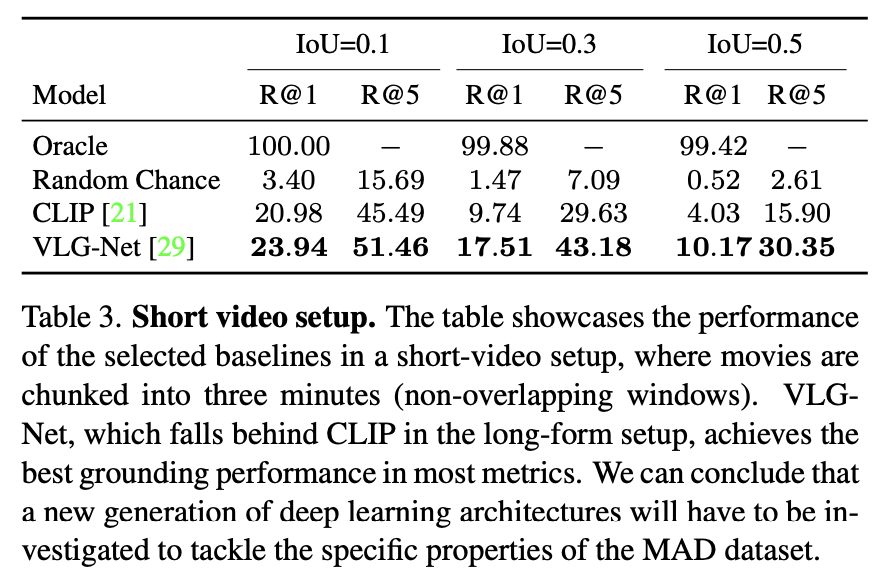
We set the short-video window length to three minute which is a candidate representative for short videos.
From Short- to Long-form Results.
The graph displays how the performance steadily drops as the window length increases, showing the challenging setup of long-form grounding enabled by MAD.
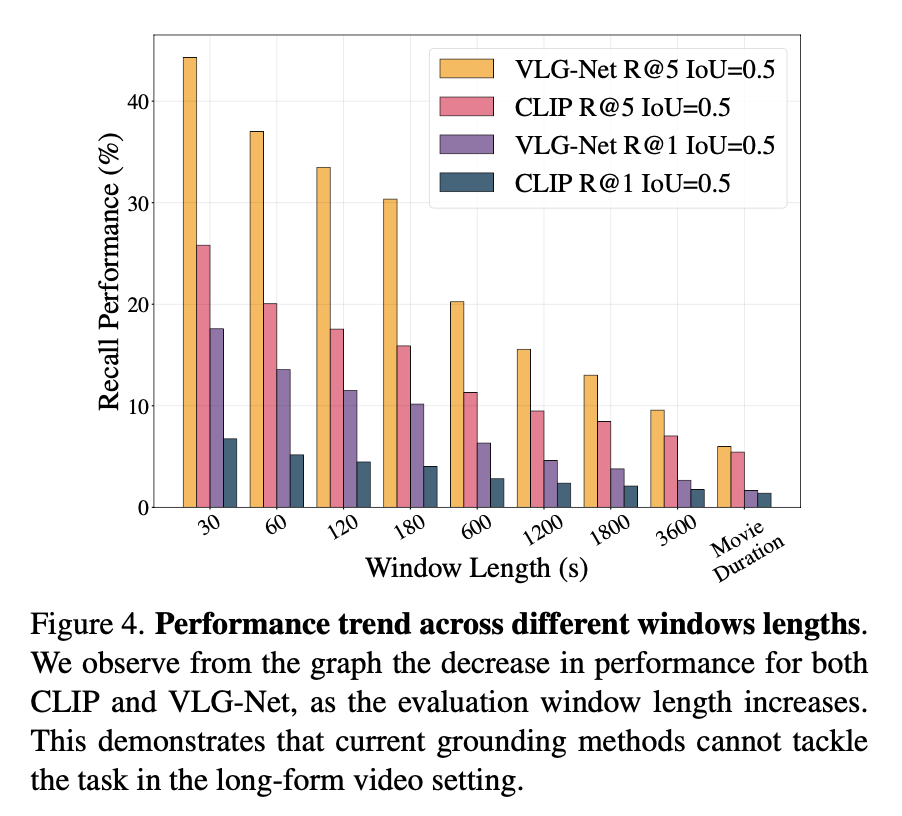
Figure 4 showcases the performance trend for the metrics R@{1, 5}-IoU=0.5, when the window length is changed from a small value (30 seconds) to the entire movie duration (average duration is 2hrs).
Takeaway
👀 VLG-Net could successfully outperform the zero-shot CLIP baseline when evaluated in a short-video setup.
→ Current state-of-the-art grounding methods are not ready to tackle the long-form setting proposed by MAD. It gives opportunities for the community to leverage previously developed techniques in a more challenging setting and potentially incorporate new constraints when designing deep learning architectures for this task.
5. Ablation Study
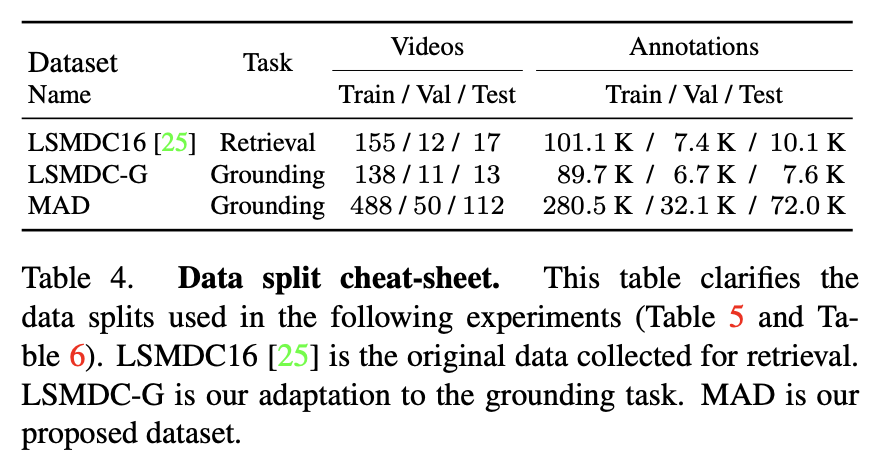
This section focuses on the empirical assessment of the quality of MAD training data.
- LSMDC16 refers to the original data for the task of text-to-video retrieval.
- LSMDC-G is our adaptation of this dataset for the grounding task and we could only retrieve 162 out of 182 movies.
Improving Grounding Performance with MAD Data.
We investigate the performance of VLG-Net in the long-form grounding setup when the training data change.
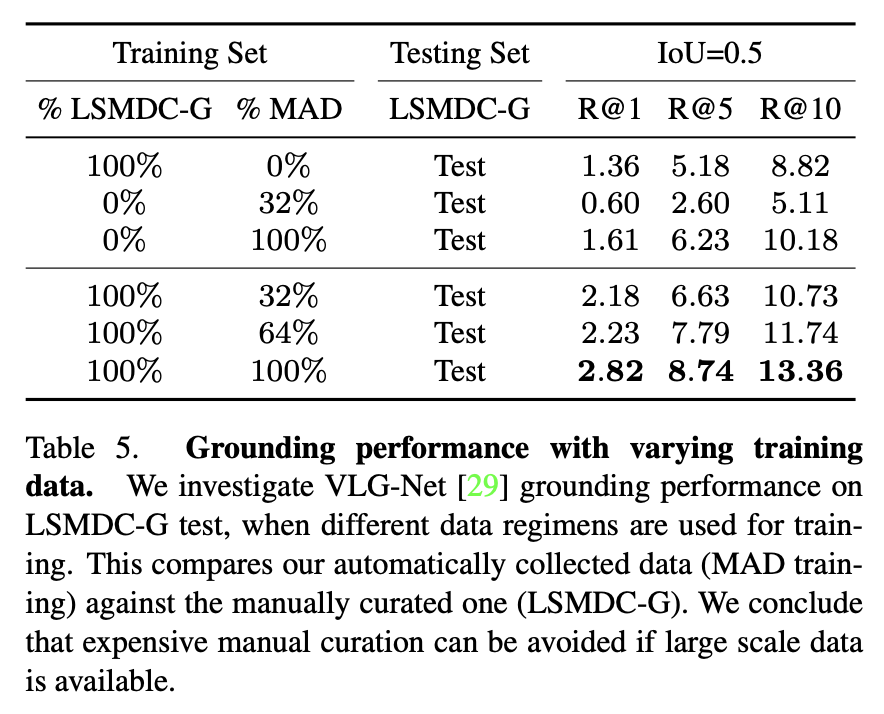
In these experiments (rows 4-6), the performance steadily increases.
→ These results suggest that current models for video grounding do benefit from larger-scale datasets, even though the automatically collected training data may be noisy.
→ Designing scalable strategies for automatic dataset collection is crucial, as the drawbacks of noisy data can be offset and even overcome with more training data.
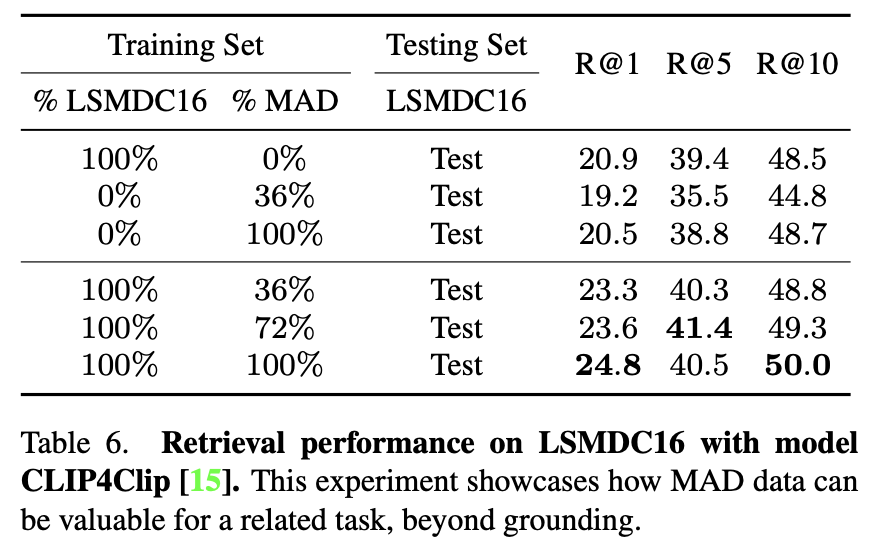
Improving Retrieval Performance with MAD Data.
We evaluate the possible contribution of our data in text-to-video retrieval.
We format our MAD data similarly to LSMDC16 and for this experiment, we use CLIP4Clip.
- We see that training with the whole LSMDC16 or MAD leads to a very similar performance.
- Pouring more data into the task boosts the performance, motivating the benefit of having a scalable dataset like MAD.
Takeaway.
😀 The MAD dataset is able to boost performance in two closely related tasks, video grounding and text-to-video retrieval.
6. Conclusion
- The paper presents a new video grounding benchmark called MAD, which builds on high-quality audio descriptions in movies.
- MAD alleviates the shortcomings of previous grounding datasets. Our automatic annotation pipeline allowed us to collect the largest grounding dataset to date.
- Our methodology comes with two main hypotheses and limitations: (i) Noise cannot be avoided but can be dealt with through scale. (ii) Due to copyright constraints, MAD’s videos will not be publicly released. However, we will provide all necessary features for our experiments’ reproducibility and promote future research in this direction.
