[논문정리] StyleGAN-V : A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2
논문
https://arxiv.org/abs/2112.14683
Abstract
비디오는 continuous한 events를 보여주지만 대부분의 video synthesis 프레임워크는 시간에 따라 discretely하게 다룹니다. 논문에서는 video를 time-continuous signals로 다루고, continuous-time video generator를 만들기 위해 neural representations으로 확장합니다.
이를 위해서, 먼저 positional embeddings의 관점으로 continuous motion representations을 디자인하고, sparse videos로 훈련시키고 적은 frames으로도 좋은 generator를 학습시킬 수 있다는 것을 증명했습니다. 그리고, 기존의 image + video discriminators pair를(2개의 discriminators) 다시 생각해서 frames 특징들을 concatenating하는 holistic한 discriminator를 제안합니다.
1. Introduction
최근 deep learning은 Image generation 분야가 아주 많이 연구되고 활용될 수 있게 했지만 Video generation은 사정이 다릅니다. 비디오 자체의 complex한 data distribution이 원인이 되기도 하고, 비디오를 discrete한 일련의 images로 다뤄서이기도 합니다. 이렇게 하기 위해서는 long high-resolution videos와 expensive conv3d-based 구조를 통해서 모델링을 해야합니다.
논문에서는 위와 같은 구조를 변형하고, videos를 그 자체의 natural form인 continuous signals , that map any time coordinate into an image frame 으로 다룹니다.
따라서, neural representation을 video generation domain으로 확장해 GAN 기반의 continuous video synthesis framework를 발전시켰다고 합니다.
이런 framework를 발전시키기 위해 3가지 challenges가 있었다고 하는데 해결방법과 함께 살펴봅시다.
-
sine/cosine positional embeddings은 주기적이고 입력 좌표에 종속적인 특징이 있는데, 이런 특징은 aperiodic하고 sample마다 다르게 나오는 video generation에 맞지 않습니다.
✨ SOLUTION : 비디오마다 다른 특징인 motion 정보를 담고 있는 time-varying wave parameters로 positional embeddings 을 발전시켰습니다. -
비디오는 infinite한 continuous signals로 인식되기 때문에, 실제 프레임워크에서 사용가능하게 적절한 샘플링 방식이 필요합니다.
✨ SOLUTION : 의미 있는 video generator를 학습하기 위해 필요한 샘플양을 살펴봅니다.이 필요한지에 대한 질문을 조사합니다. -
위와 같은 새로운 샘플링 방식에서 작동하도록 discriminator를 다시 설계해야 합니다.
✨ SOLUTION : 논문에서의 모델은 비디오당 무작위로 샘플링된 2-4개 프레임만 보기 때문에 기존의 conv3d를 conv2d 기반 모델로 대체합니다.
논문의 모델 이름은 StyleGAN-V 으로, image-based인 StyleGAN2 위에 설계했다고 합니다.
이 모델은 non-autoregressive 한 방식으로 임의의 long high frame-rate 비디오를 만들 수 있고 training efficiency 또한 좋다고 합니다.✨
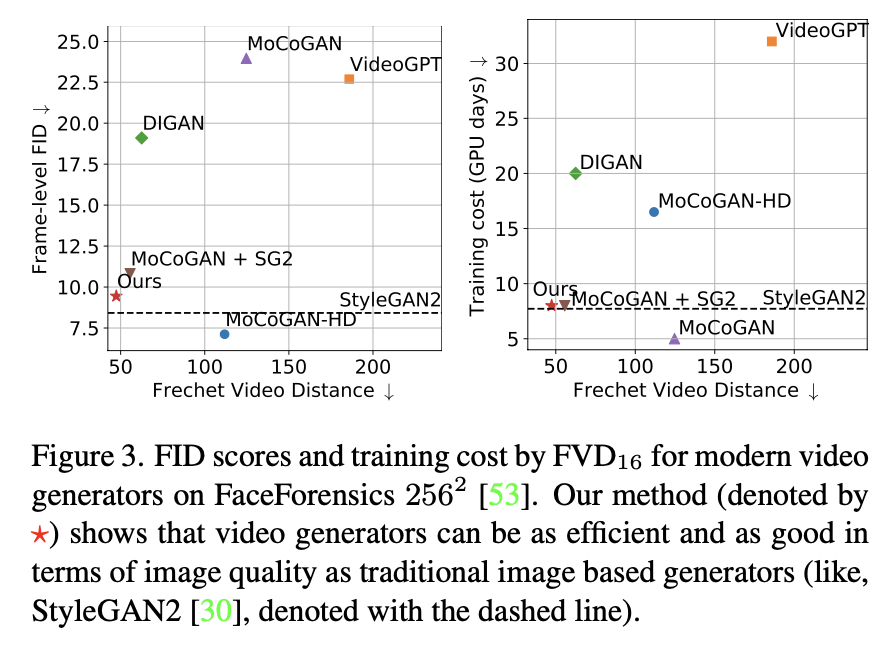
Figure 3을 보면 image-based인 StyleGAN2 모델보다 ≈5%정도 더 비싸지만 FID 측면에서 plain image quality는 ≈10% 정도만 떨어집니다. 그래서 video generator를 HQ datasets으로 쉽게 확장 가능하고 resolution에서 직접 학습할 수 있음을 알 수 있습니다.
2. Related work
Video synthesis
초기 Video synthesis는 주로 이전에 봤던 sequence가 주어졌을 때 future frames을 생성하는 video prediction 에 초점을 두었습니다. 다른 비슷한 연구로는 주어진 비디오의 frame rate을 증가 시키는 video interpolation이 있습니다.
✨ 이 논문에서는 video generation을 살펴보는데, 이전 프레임을 conditioning 하지 않고 video를 처음부터 synthesize하기 때문에 위의 연구들보다 challenging한 문제라고 할 수 있습니다.
video generation의 고전적인 방법들은 기본적으로 GANs을 기반으로 하고 있습니다. 논문에서는 MoCoGAN과 TGAN에서 generator의 input noise를 content code와 motion codes로 분해하는 방법을 이용합니다.
또한 최근에 high-resolution video synthesis을 연구하고 있지만, pretrained된 image generator의 latent space에서만 훈련시키는 방법을 사용하고 있습니다. StyleGAN-V는 extremely sparse videos로 훈련되어 다른 temporal resolutions에서 작동하는 pyramid of discriminators를 사용합니다.
그리고 최근 비디오 합성은 비싼 conv3d blocks을 decoder/encoder에 사용하고, 대부분의 GAN 기반 모델들은 image와 video 각각에서 작동하는 두개의 discriminators을 활용합니다.
논문에서는 프레임에서 뽑힌 feature vectors의 간단한 concatenation으로 temporal 정보를 종합하는 방식을 사용함으로써 state-of-the-art video generator를 구축했다고 합니다.
Neural Representations.
최근에는 images, videos, audios, 3D objects, scenes 등의 continuous signals을 neural networks를 통해서 표현하고 있습니다. 이 논문에서는 video generation에 neural representations을 적용해봅니다!
Concurrent works.
- DIGAN
- NeRV(Neural Representations for Videos)
3. Models
이제 모델 구조를 살펴봅시다! 모델은 neural representations을 기반으로 합니다. (representing signals as neural networks.)
- video : function (continuous in time )
- training dataset : set of subsampled signals {} {}
- : 전체 videos 수
- : j번째 frame의 time position
- : i번째 비디오의 frames 양
🥅 논문의 Goal은 subsampled 만 있는 video signals에 대해 generative model을 훈련하는 것❗️
모델은 StyleGAN2를 video synthesis를 위해 약간 변형했습니다.
-
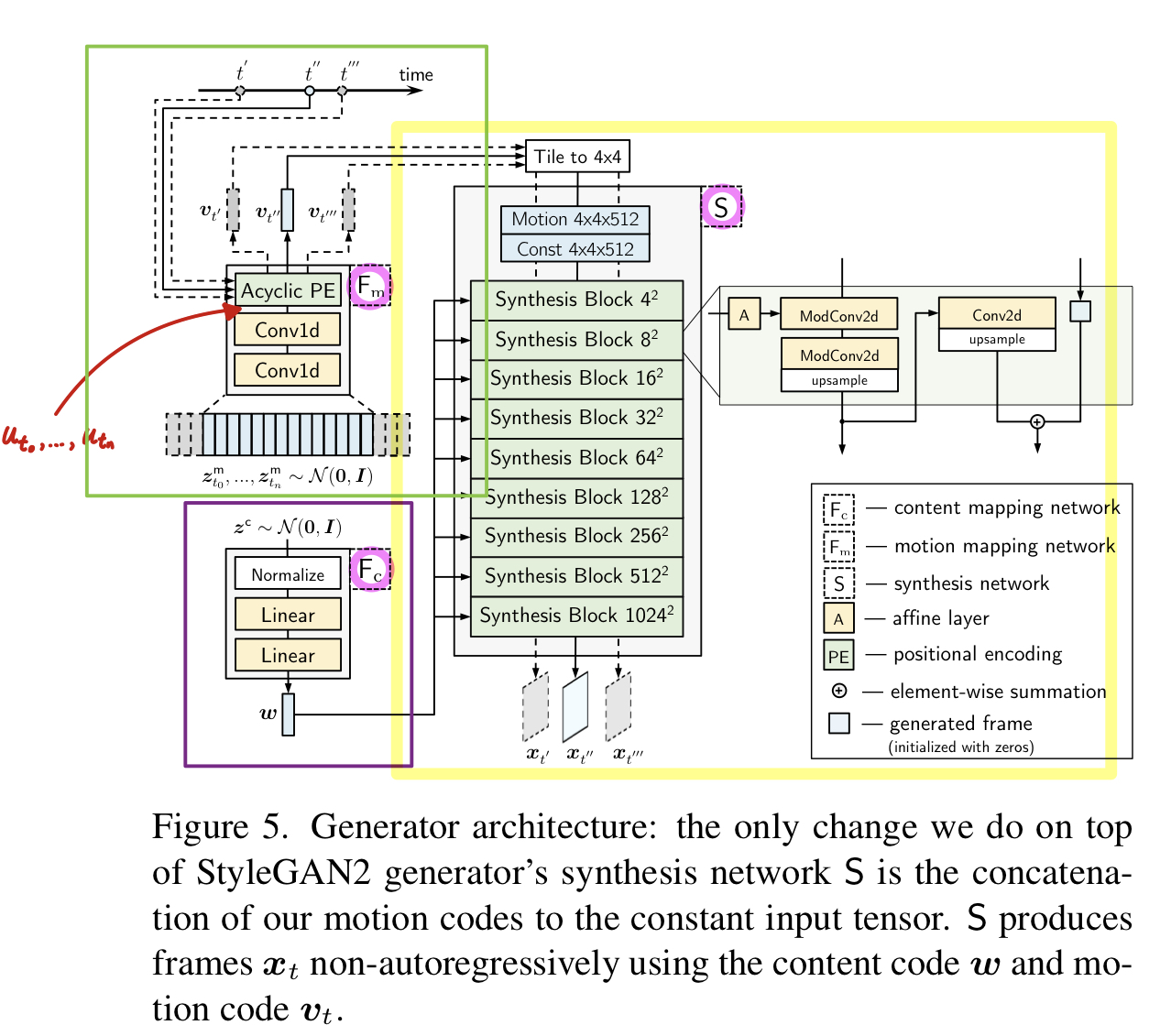
Generator는 MoCoGAN과 비슷하게, latent information를 content code motion trajectory 로 분리합니다. MoCoGAN 과 다른 점은, StyleGAN-V의 motion codes 는 time 에서 continuous 하다는 것으로 뒤에서 더 알아봅시다. 그리고 StyleGAN2의 generator 윗상단에서는 딱 하나 변형했는데 continuous motion codes 를 constant input tensor 와 concatenation하는 것입니다.
-
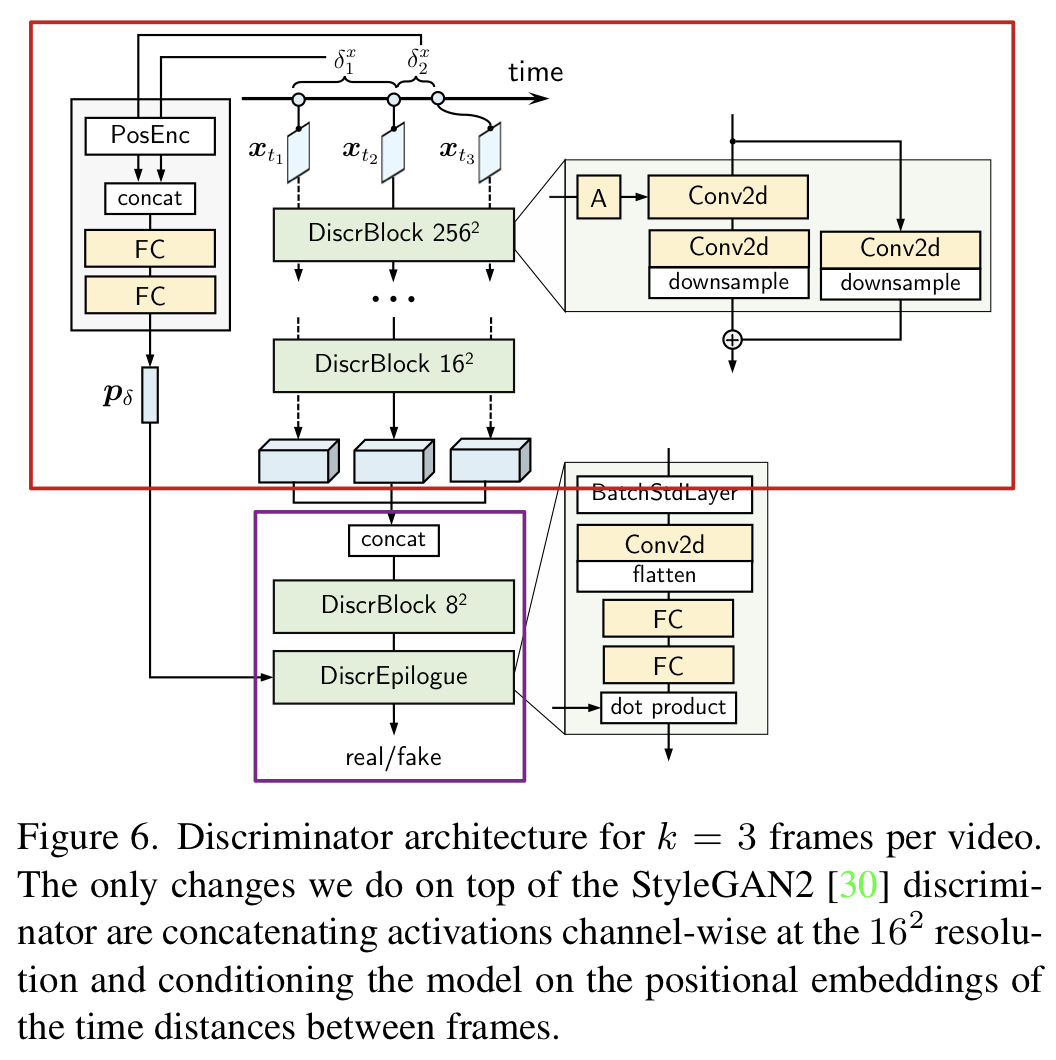
Discriminator model 는 sparsely sampled video의 프레임 을 입력으로 받은 후에 독립적으로 features 를 뽑고, global video descriptor 로 channel-wise해서 그런 features들을 concatenate 합니다. 그리고 real/fake 를 예측합니다.
- 다른 frame rates에서 더 쉽게 작동할 수 있도록 프레임 사이의 time distances 에 대해 D를 condition합니다.
3.1. Generator structure
Overview.
Generator's three components (Fc 와 S는 StyleGAN2 에서 가져오고, S는 motion codes 를 일정한 input tensor에 tiling and concatenating 해줍니다. )
- : content mapping network
- : motion mapping network
- S : synthesis network .
Fc and S are borrowed from StyleGAN2 and we only modify S by tiling and concatenating motion codes to its constant input tensor.
🔥 Video Generating
먼저 content noise 를 샘플링하고, StyleGAN2처럼 latent code 로 transform합니다. (It is shared for all timesteps of a video.)
그리고 특정한 time location 에서 frame 를 generate 하기 위해 먼저 아래 3 step으로 motion code 를 계산합니다.
a. 먼저, equidistant trajectory noise 의 discrete sequence를 샘플링합니다. (positioned at distance from one another.) tokens 의 수는 condition 에 의해 결정된다. (it should be long enough to cover the desired timestep . )
b. 그리고, conv1d 기반의 motion mapping network Fm 으로 진행합니다. with a large kernel size into the sequence .
c. 그 후에, 사이에 있는 토큰 쌍을 취하고(i.e. for some and ) 다음에서 설명할 acyclic positional embedding 를 계산합니다.
This positional embedding serves as the motion code for our generator. 👏
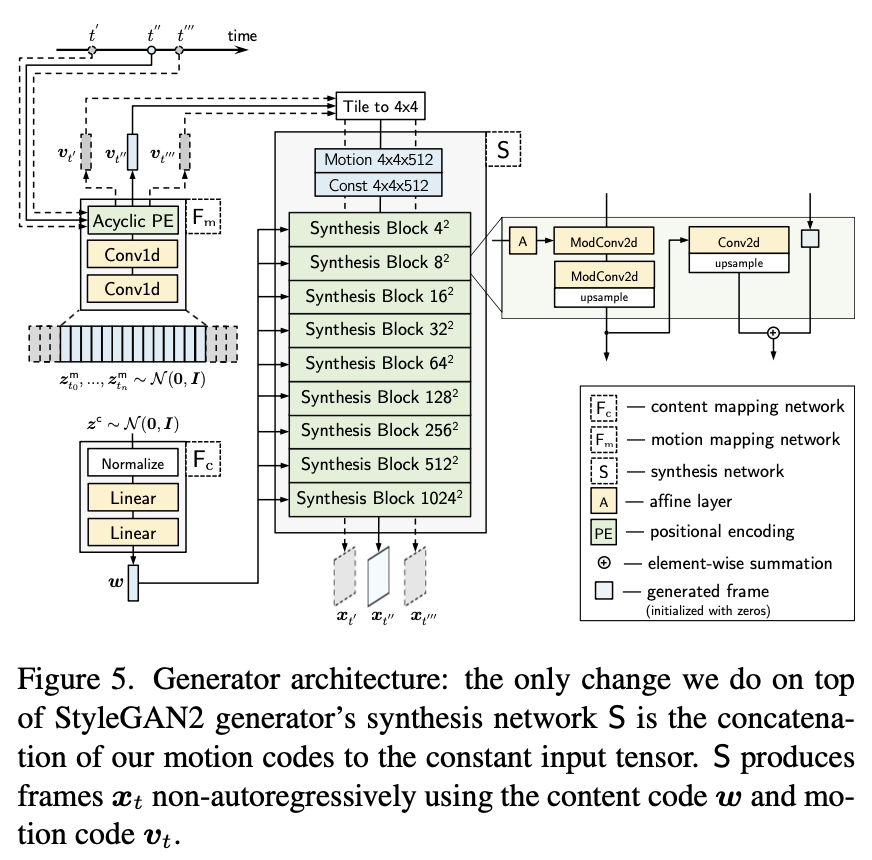
사실, 를 얻기 위해 모든 motion noise vectors 를 샘플링할 필요는 없고, 에 해당하는 것만 하면 됩니다. 이렇게 하면, generator는 non-autoregressively하게 프레임을 만들 수 있습니다.
Acyclic positional encoding.
기본적인 positional embeddings은 cyclic한테 기존의 application(image or scene representations)에서는 문제가 없었습니다. 하지만 video generation에서는 비디오가 특정 구간을 반복하는 cyclicity가 불필요한 특징입니다. 이 문제를 해결하기 위해 논문에서는 Acyclic positional encoding을 제안합니다.
sine-based positional embedding vector 는 아래와 같이 표현 될 수 있습니다.
- : element-wise vector multiplication
- : amplitudes
- periods
- : phases of the corresponding waves
- sine function is applied element-wise.
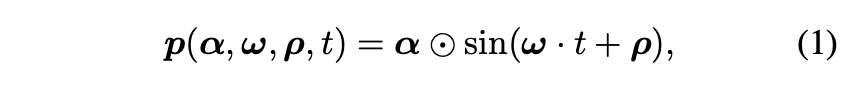
기본적으로 이러한 embeddings은 periodic하고 모든 입력에 대해 항상 동일합니다. 이는 natural videos에 다른 motions가 포함되고 일반적으로 aperiodic한 video synthesis에 적절하지 않습니다.
위의 문제를 해결하기 위해, motion noise 에서 아래와 같이 wave parameters를 계산합니다.
먼저 “raw” motion codes 를 에서 예측된 wave parameters 를 사용해 계산합니다:where
는 learnable weight matrices 입니다.
를 바로 motion codes로 사용하는 것은 이 값이 discontinuities 때문에 좋지 않은 결과를 냅니다. (Fig 9d).
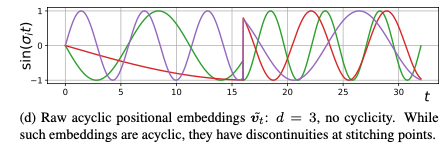
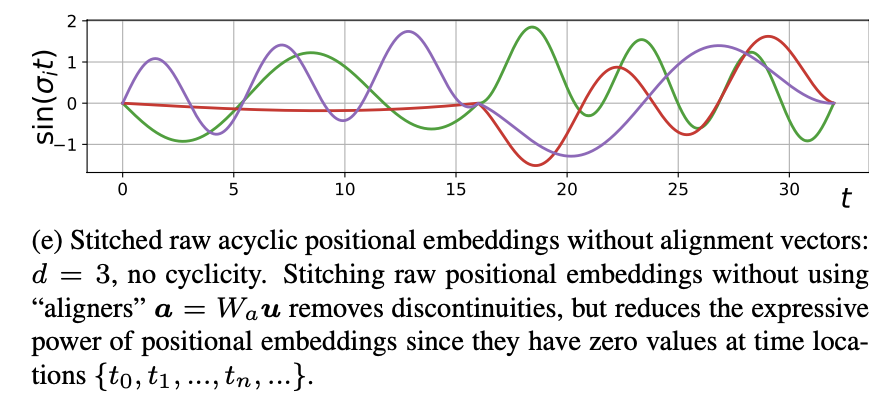
That’s why we “stitch” their start and end values via:
여기에서 는 learnable weight matrix 이고, 는 time position 을 사용해 와 사이의 element-wise linear interpolation한 것입니다.
Equation (4)의 first subtraction(노란밑줄)은 locations {}에서 0값으로 수렴할 수 있도록 positional embeddings을 바꿉니다.
이것은 positional embeddings의 expressive power를 제한하기 때문에 "alignment" vectors 를 추가해서 복원해줍니다.See Figure9 (e) for the visualization.
실제 적용할 때, periods를 아래와 같이 계산하면 더 유용하다고 합니다. (See Appx B and the source code for details.)
- : vector of ones
- : linearly-spaced scaling coefficients.
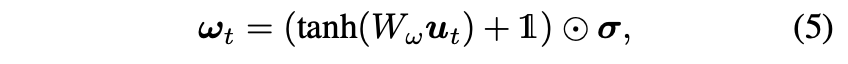
대신 continuous codes 를 바로 motion codes로 사용할 수도 있습니다. 이 방식 또한 이론적으로는 cyclicity를 제거하지만 실제 적용하면 좋지 않은 결과를 냅니다.(Look Table 2)
- distance 이 작으면, motion trajectory은 unnatural sharp transitions을 포함할 것입니다.
- distance 이 증가하면, 코드가 너무 느리게 변하기 때문에 G는 high-frequency motions (like blinking)을 알맞게 모델링하기 어려워질 것입니다.
3.2. Discriminator structure
최근의 video generator들은 2개의 discriminators를 사용하지만 본 논문에서는 frames 사이의 time distances 에 따라 결정되는 holistic한 discriminator 를 제안합니다.
- Discriminator’s Two parts
- feature extractor backbone : image frame 를 independently하게 3D feature vector 으로 embed.
- convolutional head : 모든 features를 concatenation 하고 , 출력값은 real/fake logits .
D의 입력값으로 프레임 사이의 time distances information 을 아래와 넣습니다.
- 먼저, positional encoding으로 encode하고, 2-layer MLP을 이용해 으로 전처리 해줍니다. 그리고 single vector 로 concatenate 합니다.
- 그 후에, projection discriminator strategy 를 사용하고 와 그에 대응하는 비디오 특징 벡터 사이의 간단한 내적으로 output logit을 계산합니다.
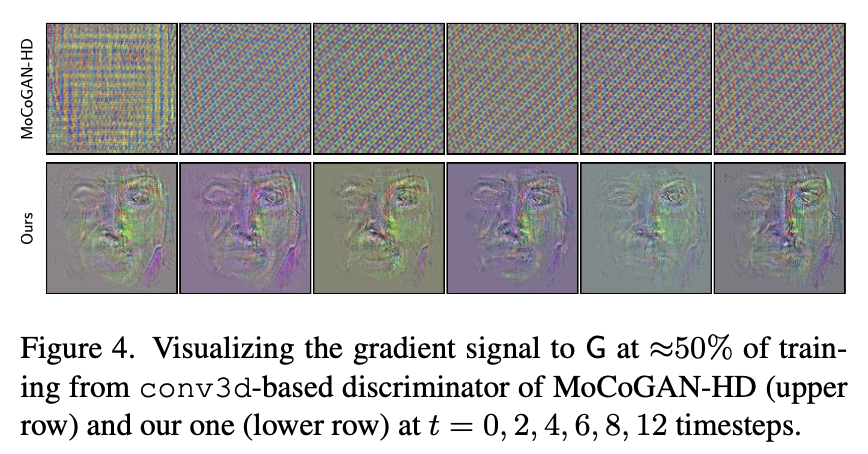
👍 위와 같은 디자인은 image와 video discriminators 두개를 다 사용하는 것보다 더 효율적이고, generator에게 더 유용한 정보의 learning signal을 줄 수 있습니다. (Figure 4).
3.3. Implicit assumptions of sparse training
probability distribution 을 학습하는 문제를 sparse training을 활용한다고 생각해봅시다. 즉, 최적화 과정의 반복문마다 vector 에서 랜덤하게 k개의 좌표를 고릅니다.
그러면 최적화의 목적은 joint 를 학습하는 것이 아닌, 가능한 모든 marginal distributions 를 학습하는 것과 동일합니다.
🤔 When does learning marginals allow to obtain the full joint distribution at the end? The following simple statement adds some clarity to this question.
A trivial but serviceable statement.
Let’s denote by a collection of sets of up to indices s.t. we have for all . In other words, is a set of up to indices . Then, can be represented as a product of marginals for if and only if there exists s.t. .
위 내용은 기초적이지만 (see the proof in Appx F) 유용하고 실용적인 intuition을 제공합니다. Video synthesis 의 경우, 프레임 에 대해 적절하게 예측하기에 충분한 이전 프레임이 최대 개 있는 경우에만 비디오당 프레임만 사용하여 video generations 을 학습할 수 있음을 의미합니다(see Appx F).
그리고 논문에서는 되게 적은 프레임도 좋은 예측 결과를 내기 충분하다고 주장합니다.
또한 maiximum time location T를 1024로 설정했는데 이전 방식(T = 64 )보다 좋습니다. 왜냐면 generator가 non-autoregressive하고, discriminator가 필요한 temporal information만 사용하기 때문입니다.
4. Experiments
5 benchmarks
- Face-Forensics
- SkyTimelapse
- UCF101
- RainbowJelly
- MEAD
Evaluation.
- Frechet Video Distance () : &
- Inception Score ()
5 Baselines.
- MoCoGAN
- MoCoGAN with the StyleGAN2 backbone (MoCoGAN-SG2)
- VideoGPT
- MoCoGAN-HD
- DIGAN
4.1. Main experiments
For the main evaluation, we train our method and all the baselines from scratch on the described datasets.
StyleGAN-V 와 MoCoGAN+SG2는 StyleGAN2와 동일한 optimization scheme을 사용했습니다. (loss function, Adam optimizer, R1 regularization) SkyTimelapse 는 , 나머지는 을 사용했습니다. (See other training details in Appx B.)
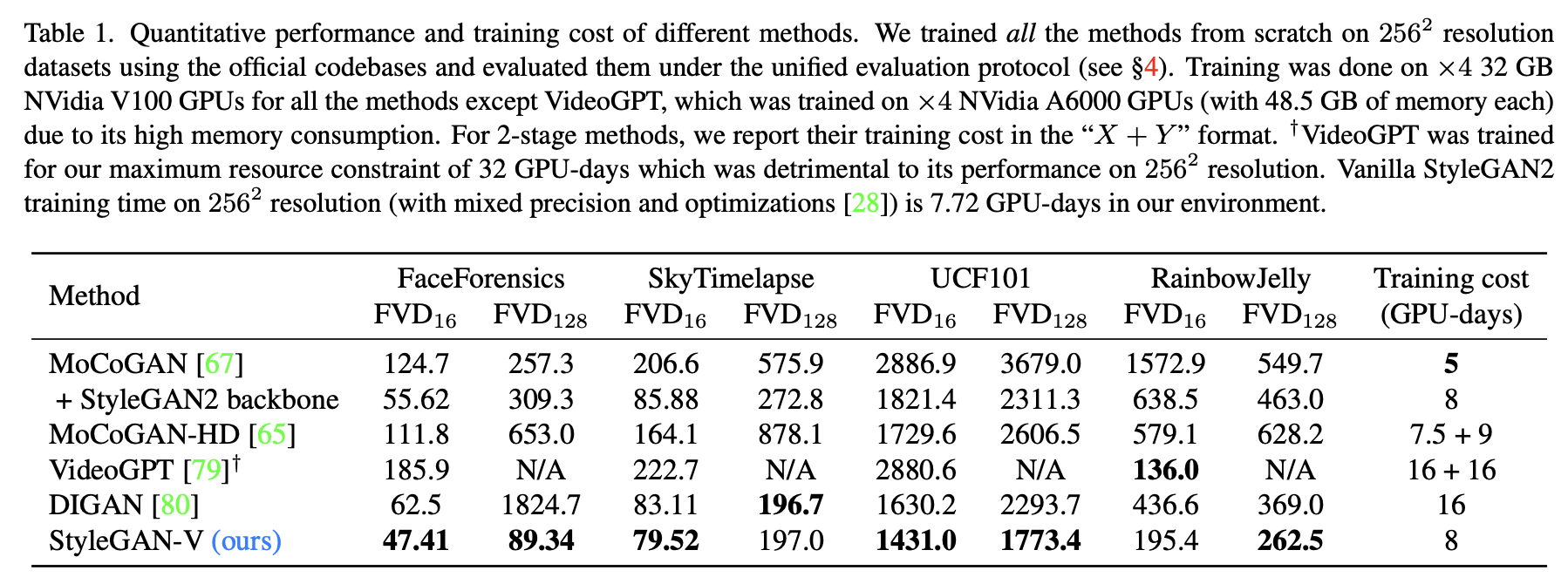
논문에서의 방식이 와 의 거의 모든 benchmarks에서 훨씬 좋은 성능을 낸다는 것을 Fig 1 과 Fig 7의 그림에서 알 수 있습니다. 한시간정도의 긴 비디오를 StyleGAN-V가 가장 잘 만들어냅니다.👍


4.2. Ablations
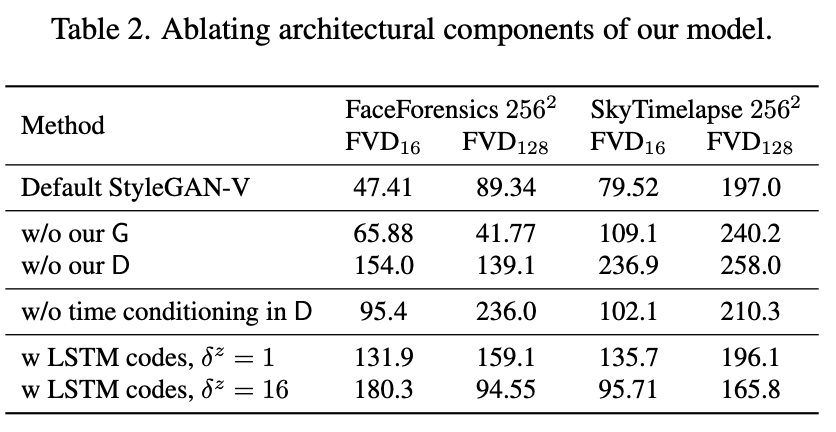
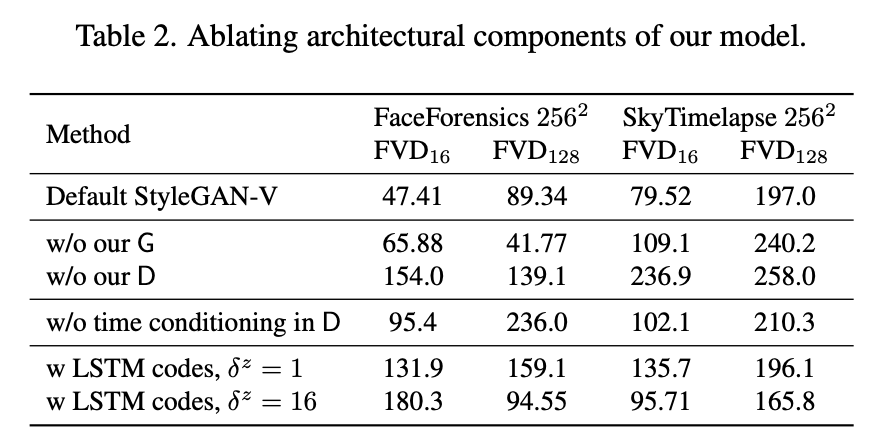
👀 Look Table 2
- G 또는 D modules을 MoCoGAN+SG2 의 복사본으로 대체해서 실험을 진행했을때, 두 경우 모두 좋지 않은 short-term and long-term video quality를 보여줬습니다.
- time conditioning을 제거하는 것도 현재 작동 중인 temporal scale를 이해하는 D의 능력이 제한되기 때문에 성능이 저하되는 것을 알 수 있습니다.
- continuous motion codes 를 로 대체하면, 특히 motion code 사이의 distance 가 작을 때 LSTM이 성능을 낮춘다는 것을 알 수 있습니다.
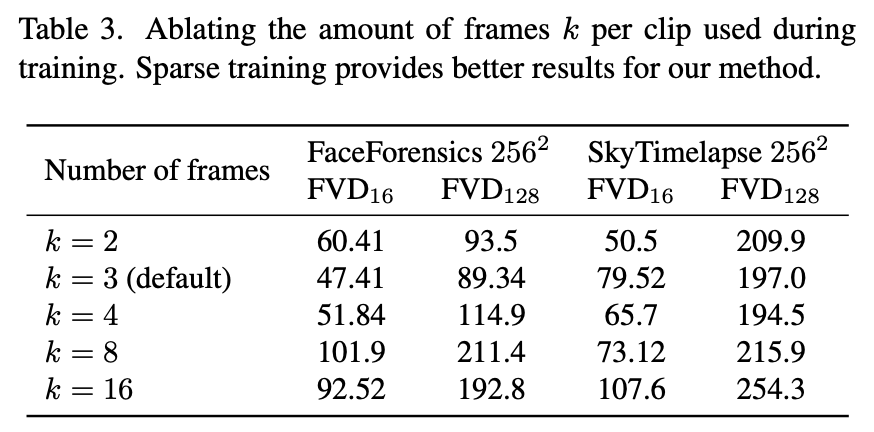
또 중요한 요소는 training 때 비디오당 몇개의 샘플들을 사용할 것인지 입니다.
→ 실험 진행 (Table 3)
4.3. Properties
- StyleGAN-V generator is able to generate arbitrarily long videos. (Figure 8)

- StyleGAN-V has the same latent space manipulation properties as StyleGAN2

- StyleGAN-V is the first one which is directly trainable on resolution.
- StyleGAN-V discriminator provides more informative learning signal to G.
5. Conclusion
이 논문은 video synthesis의 새로운 관점을 제시하고 neural representations을 통해 continuous video generator를 제안했습니다. positional embeddings으로 motion을 표현하고, sparse training 과 변형된 video discriminator를 보여줍니다. StyleGAN-V 모델의 좋은 성능을 보여줌으로써 video generation의 발전을 말합니다.
