Abstract
논문에서는 어떤 임의의 사람이 주어진 오디오에 맞춰서 lip-syncing하는 talking face video 를 생성하는 문제를 다루고 있습니다. 이전의 작업들은 입술 움직임이 정확하게 임의의 identity에 맞춰서 morph하는 것들을 잘 못했는데, 논문에서는 강력한(powerful) lip-sync discriminator를 학습함으로써 이 문제를 해결하려고 하고 있습니다. 또한 Wav2Lip model을 제안해 잘 synced되는 video를 생성합니다.
Let's dive into paper! 😀
1. Introduction
💪 Contributions:
- We propose a novel lip-synchronization network, Wav2Lip, that is significantly more accurate than previous works for lip-syncing arbitrary talking face videos in the wild with arbitrary speech.
- We propose a new evaluation framework, consisting of new benchmarks and metrics, to enable a fair judgment of lip synchronization in unconstrained videos.
- We collect and release ReSyncED, a Real-world lip-Sync Evaluation Dataset to benchmark the performance of the lip-sync models on completely unseen videos in the wild.
- Wav2Lip is the first speaker-independent model to generate videos with lip-sync accuracy that matches the real synced videos. Human evaluations indicate that the generated videos of Wav2Lip are preferred over existing methods and un- synced versions more than 90% of the time.
2. Realated Work
2.1 Constrained Talking Face Generation from Speech
talking face generation 분야에서 constrained하다는 것은 '생성할 수 있는 객체(identities)의 범위' 또는 '제한된 단어(vocabulary)의 범위'를 말합니다.
2.2 Unconstrained Talking Face Generation from Speech
3. Accurate Speech-Driven Lip-Syncing For Videos In The Wild
Generating accurate lip-sync by learning from a well-trained lip-sync expert ❗️
논문에서 말하기를 위에서 언급한 기존의 방법들이 inaccurate한 비디오 lip-sync를 생성하는 이유는
- L1 reconstruction loss
- LipGAN에서의 discriminator loss
입니다.
3.1 Pixel-level Reconstruction loss is a Weak Judge of Lip-sync
소제목 그대로 pixel-level reconstruction loss는 lip-sync loss로 적합하지 않다는 건데,,
face reconstruction loss는 전체 이미지에 대해서 수행됩니다. 근데 거기에서 lip 부분은 전체 loss 중에 4%만 해당하기 때문에 모델이 lip 모양에 맞게 reconstruction되기 전에 이미지의 다른 부분에 맞춰서 optimized 되게 됩니다. 그래서, LipGAN에서 처럼 lip-sync를 판단하는 추가적인 discriminator가 필요한 것입니다. 😀
아래서 LipGAN discriminator를 살펴봅시다.
3.2 A Weak Lip-sync Discriminator
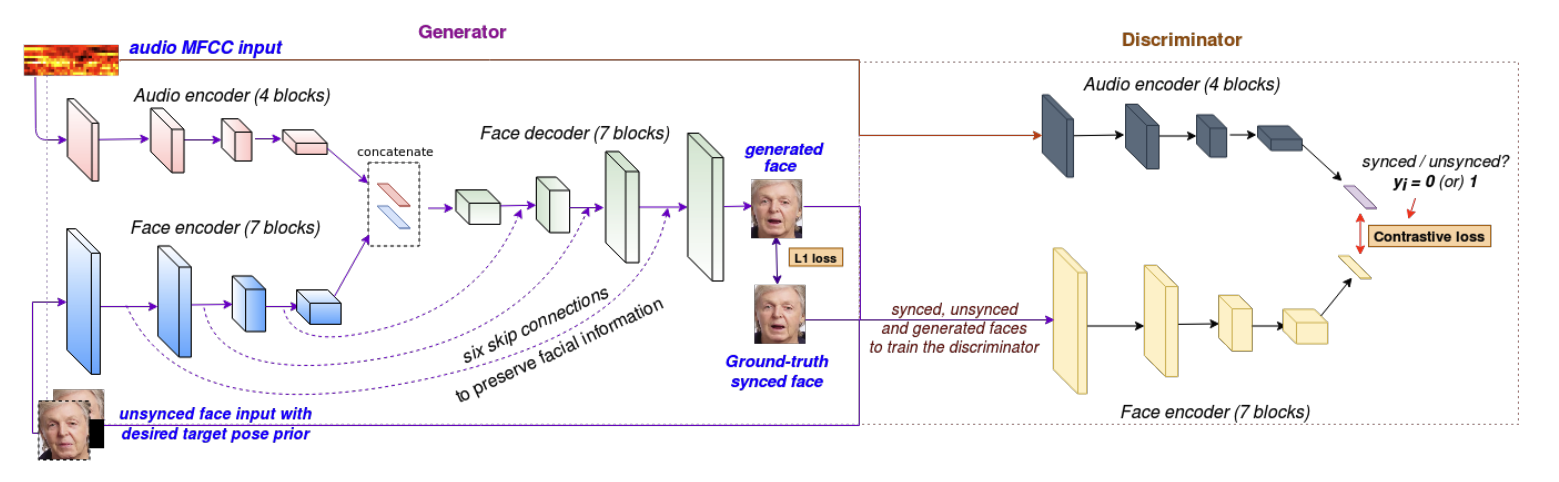
하지만 LipGAN의 lip-sync discriminator는 LRS2 데이터셋에서 off-sync audio-lip pairs를 detecting하는 정확도가 56%에 불과합니다. 본 논문의 discriminator는 91%인데요,,
이렇게 LipGAN의 weak한 discriminator와 본 논문의 discriminator가 다른 두가지 큰 차이점은
-
LipGAN discriminator는 discriminator 에서 한개의 frame만 사용한다.
-
LipGAN은 training 중에 생성된 이미지에 많은 artifact가 포함된다. 이런 이미지로 판별하면 모델이 audio-lip sync가 아닌 visual artifacts에 초점을 두게 되어서 정확도에 영향을 준다.
그래서 논문에서는 좀 더 강력한 discriminator를 제안합니다. 👊
3.3 A Lip-sync Expert Is All You Need
논문에서는 pre-trained 된 expert lip-sync discriminator를 제안합니다. 여기에서 SyncNet을 조금 변형해서 사용합니다.
3.3.1 Overview of SyncNet.
SyncNet input
3.3.2 Our expert lip-sync discriminator.
논문의 모델은 expert lip-sync discriminator를 학습시키기 위해 아래처럼 SyncNet을 변형했습니다.
-
Gray-scale images 대신 color images를 사용한다.
-
Residual skip connections 을 사용해 더 깊은 모델을 사용한다.
-
Cosine-similarity with binary cross-entropy loss function를 사용한다.( Compute a dot product between the ReLU-activated video and speech embeddings v, s to yield a single value between [0, 1] for each sample that indicates the probability that the input audio-video pair is in sync:)
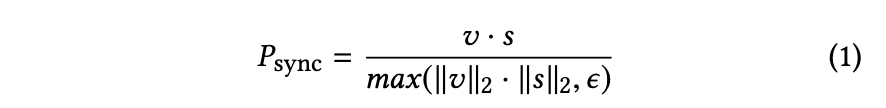
LRS2 test set에 대해
- batch size : 64
- = 5 frames
- Adam optimizer
- Initail leraning rate
→ 91% accurate를 보였습니다.
3.4 Generating Accurate Lip-sync by learning from a Lip-sync Expert
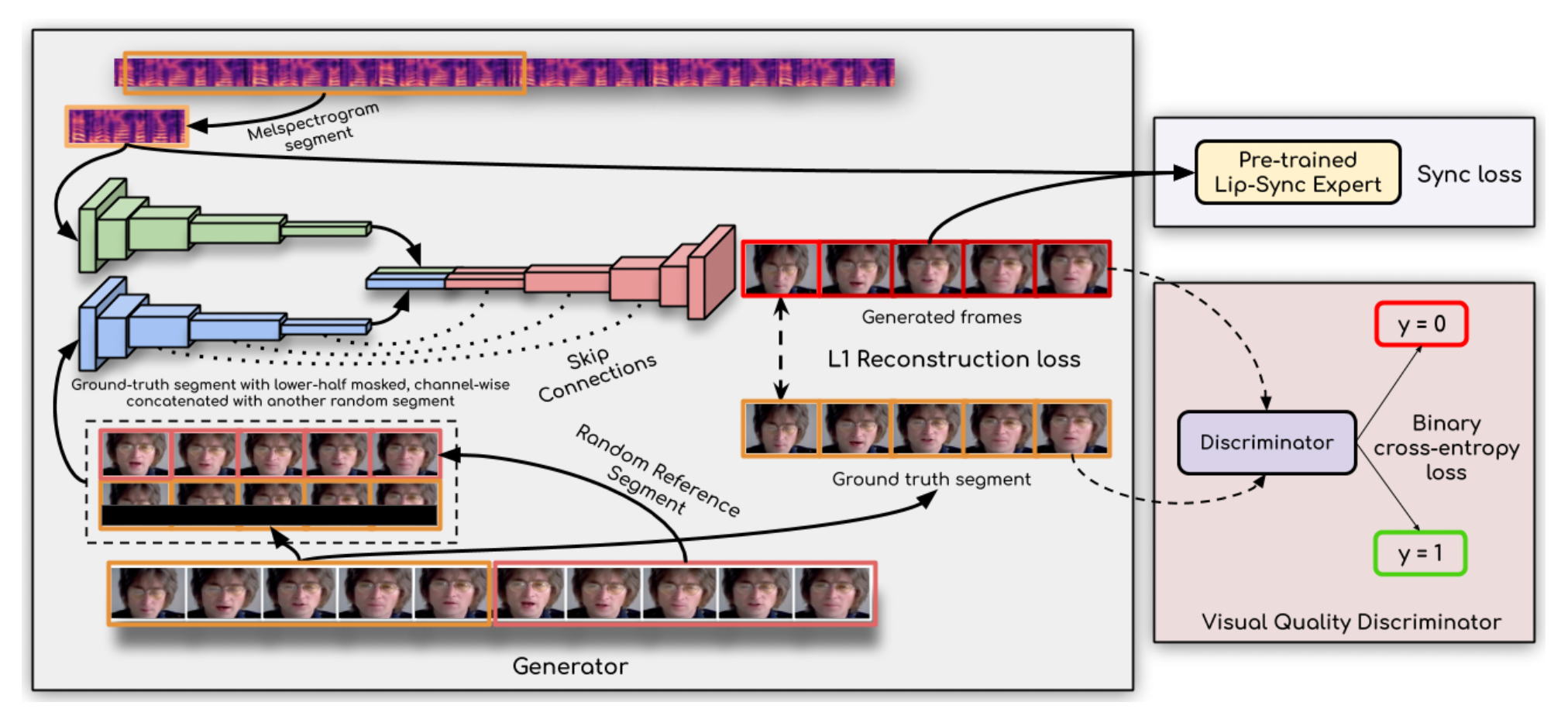
3.4.1 Generator Architecture Details.
Generator는 3개의 blocks으로 이뤄져있습니다.
-
Identity Encoder : Stack of residual convolutional layers that encode a random reference frame , concatenated with a pose-prior (target-face with lower-half masked) along the channel axis.
-
Speech Encoder : Stack of 2D-convolutions to encode the input speech segment which is then concatenated with the face representation.
-
Face Decoder : Stack of convolutional layers, along with transpose convolutions for upsampling.
Generator 는 generated frames 와 ground-truth frames 사이의 reconstruction loss를 minimize하도록 학습합니다.
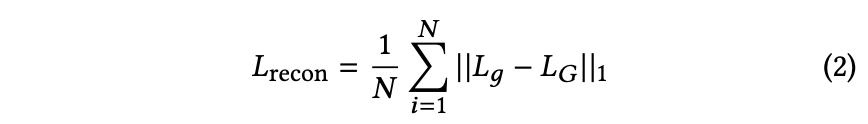
3.4.2 Penalizing Inaccurate Lip Generation.
Training 동안, pre-trined 된 expert discriminator는 contiguous frames을 처리해서, Generator 도 frames을 생성해야합니다. 그리고, pose 가 temporal하게 연속되기 위해 reference frames으로 랜덤하게 contiguous window를 샘플링합니다.
여기에서 generator가 각각의 frame을 독립적으로 생성하기 때문에, 의 입력 형태를 얻기 위해 reference frames을 주면서 batch 차원을 따라 time-steps을 쌓습니다. ( : batch-size, Height, Width) 그리고 생성된 frames을 expert discriminator에 줄때에도, time-steps은 channel 차원에 따라서도 concatenate됩니다.
그래서 expert discriminator의 input shape은 이 됩니다.(판별할때는 얼굴 아래부분만 사용함.) Geneator는 "expert syn-loss" 를 minimize하도록 훈련됩니다.
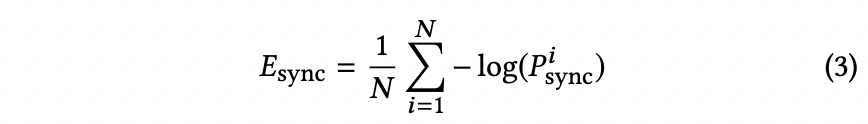
"expert discriminator’s weights remain frozen during the training of the generator."
3.5 Generating Photo-realistic Faces
expert lip-sync discriminator가 generator가 정확한 lip 모양을 만들도록 하긴 하지만 가끔 약간 blurry하거나 artifact를 포함한 결과들이 나오기도 합니다. 그래서 이걸 완화하기 위해 논문에서는 GAN처럼 visual quality discriminator 를 추가해서 생성된 얼굴에 대해서 학습시킵니다. 그래서 총 2개의 discriminator가 있는 것이죠. (lip-sync & visual quality discriminator)
Discriminator는 objective function 를 maximize하도록 훈련됩니다.
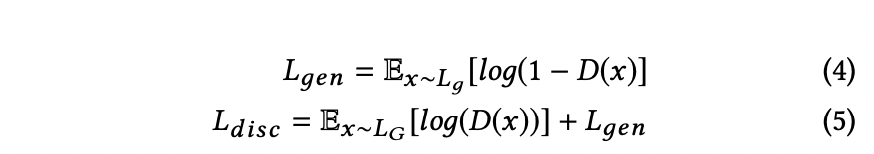
Generator는 아래 식을 maximize 하도록 훈련됩니다. (reconstruction loss + synchronization loss + adversarial loss)
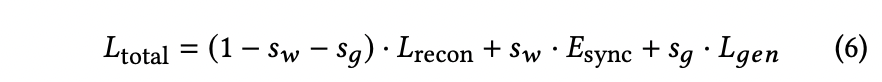
"Complete netwrok is optimized for both superior sync-accuracy and quality using two disjoint discriminators. "
Lip-GAN이랑 비슷하게 논문의 모델은 frame-by-frame 으로 talking face video를 생성합니다. 각 time-step의 visual input은 source frame에서의 crop된 face이고, pose prior로 사용하기 위해 아래부분이 masked된 동일한 crop된 face와 concat됩니다. 따라서 inference 중에 모델은 포즈를 변경할 필요가 없어서 artifact가 줄고, 해당 audio segment도 speech sub-network에 대한 입력으로 제공되고, 네트워크는 입 부분이 변형된 face crop을 생성합니다.
4. Quantitative Evaluation
4.1 Re-thinking the Evaluation Framework for Speech-driven Lip-Syncing in the Wild
논문에서는 이전의 lip-sync evaluation framework가 좋지 않다고 주장하는데 아래와 같은 이유를 대고 있습니다. (current frame을 reference로 주는게 아닌 video의 random한 frame을 reference로 쓰는것)
4.1.1 Does not reflect the real-world usage.
4.1.2 Inconsistent evaluation.
4.1.3 Does not support checking for temporal consistency.
4.1.4 Current metrics are not specific to lip-sync.
4.2 A Novel Benchmark and Metric for Evaluating Lip-Sync in the Wild
그래서 논문에서는 random하게 frames을 sampling합니다. 현재 프레임이 이미 음성과 sync되어서 입력 자체에서 lip 모양이 보여지기 때문입니다. 그리고 이전방법들은 샘플링된 speech에 대한 ground-truth lip shape을 사용할 수 없기 때문에 다른 프레임을 샘플링하는 대신 다른 speech segments를 샘플링하지 않았습니다.
4.2.1 A Metric to Measure the Lip-Sync Error.
We propose to use the pre-trained SyncNet available publicly to measure the lip-sync error between the generated frames and the randomly chosen speech segment.
4.2.2 A Consistent Benchmark to Evaluate Lip-sync in the wild.
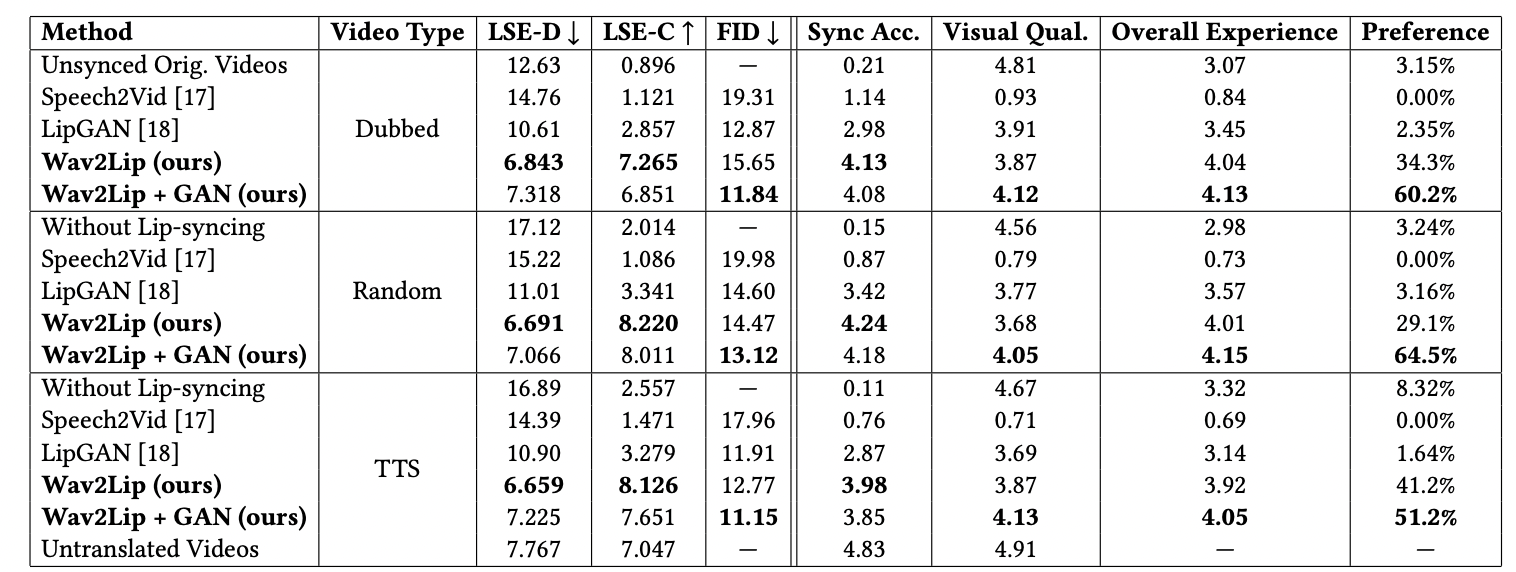
4.3 Comparing the Models on the New Benchmark
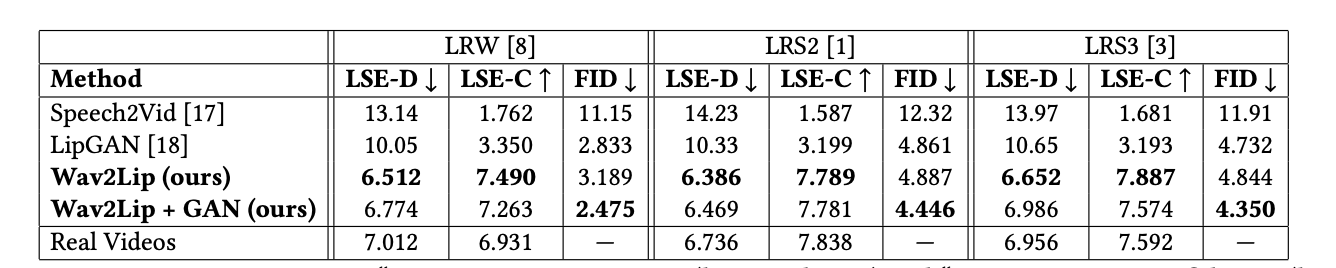
4.4 Real-World Evaluation
4.4.1 Curating ReSyncED.
4.4.2 Real-world Evaluation on ReSyncED.

5. Applications & Fair Use
6. Conclusion
- Proposed a novel approach to generate accurate lip-synced videos in the wild. - Highlighted two major reasons why current approaches are inaccurate while lip-syncing unconstrained talking face videos.
- Pre-trained, accurate lip-sync “expert" can enforce accurate, natural lip motion generation.
- Before evaluating our model, we re-examined the current quantitative evaluation framework and highlight several major issues.
- Proposed several new evaluation benchmarks and metrics, and also a real-world evaluation set.
- Wav2Lip model outperforms the current approaches by a large margin in both quantitative metrics and human evaluations.
