강화학습 시리즈는 패스트캠퍼스 박준영 강사의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.
Review
우리는 지난 시간에 환경과 보상 함수에 대해 알고 있다는 가정하에서 (환경은 상태천이 함수를 의미한다.) Dynmaic Programming을 통해 최적 가치함수와 최적 정책을 찾을 수 있다는 것을 배웠다. Dynamic Programming은 매우 효율적이라는 장점이 있으나 현실 문제를 RL로 풀 때 사용하기 매우 어렵다.
그렇기 때문에 이번 시간에는 환경에 대한 조건이 없는 (Model-free) 상황에서 최적 가치와 최적 정책을 찾는 알고리즘들의 기초 베이스를 배울 것이다.
Template of Reinforcement Learning
강화학습에서 Agent는 환경과 지속적인 상호작용을 한다.
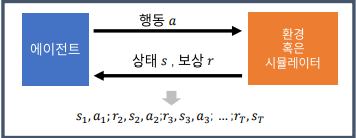
Rl의 목표는 최적 가치 함수와 최적 정책을 찾는 일이다. 최적 가치는 최적 정책을 찾으면 얻을 수 있다. (이전 내용 참조)
우리는 동적 계획법 시간에 정책 반복에 대해서 다룬 적이 있다. 정책 반복은 크게 정책 평가와 정책 개선으로 구성되어 있다.
정책 평가는 개선된 정책으로 가치 함수를 갱신
정책 개선은 개선된 가치 함수로 정책을 갱신
- 정책 평가의 식은 -축약사상을 만족하는 back-up operator이기 때문에 바나흐 고정점 정리에 의해 최적 가치에 수렴하는 것이 보장된다.
Model-free 에서도 이와 같은 아이디어로 최적 가치함수와 최적 정책을 찾아 나선다. 하지만 Dynamic Programming에서의 Policy Iteration과는 다르기 때문에 Generalized Policy Iteration이라고 부른다.
일반화된 정책 반복 (Generalized Policy Iteration)
- 임의의 방식을 적용해 계산(가치추산)
- 임의의 방식을 활용해 개선(정책개선)
가치 추산과 정책 개선을 어떻게 하냐에 따라 알고리즘의 특징이 달라진다.
먼저, 가치 추산에 어떤 종류가 있는지 알아보고 그 다음 정책 개선은 어떤 방법이 있는지 알아 보겠다.
가치 추산
가치 추산 Review
환경이 알려진 MDP에서는 Dynamic Programming을 이용해
가치를 개선 최적 가치 함수를 추산해 나갔다. 환경을 안다는 것은 을 안다는 것과 동치이다. 하지만 Model-free에서는 를 추정하지 않기 때문에 위 식을 사용할 수 없다.
Model-free RL에서는 가치를 추산하기 위해 크게 Monte-Carlo와 TD 방식을 사용한다.
Monte Carlo
가치 함수는 그 정의에서 확인할 수 있듯이 Expectatoin으로 정의된다.
(Episode가 끝나는 Terminal까지 지속한다는 의미)
Monte Carlo는 모집단의 확률 밀도 함수를 모를 때 Expectation을 추정하기 위해 사용되는 가장 대표적인 방법이고 최초 방문만 따질 것인가 모든 방문에서 따질 것인가에 따라 또 2가지로 나뉜다. 말로 하면 와닿지 않으니 예시를 들고 직접 계산하며 Monte Carlo 방식을 이해해보자.
(\gamma=1이라고 가정 계산의 편의를 위해)
First-Visit Monte Carlo Policy Evaluation
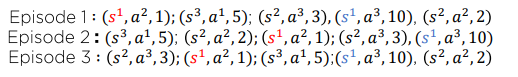
Episode 1:
Episode 2:
Episode 3:
Every-Visit Mlonte Carlo Policy Evaluation
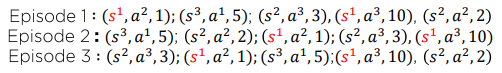
Episode1:
Episode2:
Episode3:
Monte Carlo 방식을 사용한다면 First-Visit Monte Carlo Policy Evaluation 보다는 Every-Visit Mlonte Carlo Policy Evaluation가 풍부한 데이터를 사용하기 때문에 더 많이 사용된다.
하지만 고정된 데이터를 가지고 가치를 추정하는 Offline-Learning(위 예시처럼)이 아니라 지속적으로 데이터가 생기는 Online-Learning이라면 위 방식은 매우 비효율적이다. 값을 모두 저장해야 하기 때문이다.
배치 산술평균을 온라인 평균기법으로 변환하는 방법을 배워보자.
온라인 평균

기존의 알고 있는 지식을 새로운 관측은 로 보면 된다. 이렇게 되면 가치 함수를 갱신하는 데 사용된 G_t는 이제 버려도 되기 때문에 메모리 효율이 증가한다. 온라인 평균은 확장되어 Incremental MC Policy Evaluation으로 정의된다.
Increemental MC Policy Evaluation
- G_t새롭게 알게된 지식
- V(s): 기존에 알고 있는 지식
*: Learning Rate
위 식과 차이점은 이 매우 작은 양수 값로 정의되었다. 실제 RL을 적용할 때 State Space의 크기가 매우 크기 때문에 Learning rate로 대체하였고 "적당히 작은 에 대해서 참값으로 수렴함이 증명이 되었다" Monte Carlo를 이용한다는 말은 바로 위 식을 이용해 가치함수를 추정해 간다는 말과 동치라고 생각해도 좋다.
우리는 Monte Carlo 방식을 활용하여 가치함수를 추정하는 방법에 대해서 알아보았으니 장단점에 대해서 짚고 TD 법으로 넘어가자
장점
- 환경에 대한 지식이 필요 없다.
- 모아서 평균이기 때문에 직관적이다.
- 데이터 수집이 Unbiased하기 때문에 참값에 충분히 많은 시뮬레이션이 보장된다면 수렴한다.
- 문제가 정확한 Markovian이 아니더라도 사용이 가능하다.
단점
- EPisode가 끝나야 가능하다.
- 오직 보상 정보만 사용한다.
- 많은 시뮬레이션이 필요하다.
- 편향이 적은 대신 분산이 크다. (강화학습은 조금의 변화가 누적되어 Episode 길이가 길어질 수록 Episode간 분산이 매우 커진다.)
Temporal Difference (TD) 정책 추정
Incrmental MC
MC의 단점은 G_t를 계산하기 위해서는 Episode가 끝나야 한다는 점이다. 이럴 필요 없이 G_T를 근사시켜 조금의 데이터만 가지고 Value Function을 갱신 추정해 나갈 수 있는 방법을 Temporal Difference 기법이라고 한다.,
Temporal Difference (TD)기법
이것을 TD-Target라고 한다.
를 TD-Error라고 하며
Increnetal MC는 다음과 같은 식으로 다시 정의된다.
이제 Episode가 끝나지 않더라도 훈련을 진행하며 지속적으로 가치함수를 갱신할 수 있다. 하지만 여기에도 단점이 있는데 그 내용은 MC 와 TD를 전반적으로 비교하는 파트에서 설명하겠다
TD 기법은 MC의 변형으로 Episode가 끝나지 않더라도 계속 훈련이 가능하게 하는 MC의 변형 부분이다. TD의 뿌리는 MC에서 기원한다.
MC vs TD

- MC 기법은 Episode의 Terminal까지 데이터를 수집해서 가치를 추산하기 때문에 편향은 없다. 하지만 앞에서 언급한 것처럼 Episode 길이가 클수록 데이터간 분산이 크기 때문에 수렴하기 위해서는 많은 데이터가 필요가하다. (많은 시뮬레이션 필요)
- TD 기법은 적은 데이터로 가치를 갱신하기 때문에 EPisode 길이가 상대적으로 MC보다 짧아 데이터간 분산이 적다. 하지만 많은 데이터를 참고하지 않기 때문에 알고리즘 자체에 Biased를 내재하기 때문에 참값에 수렴한다는 보장이 없다. (빠른 속도로 충분히 괜찮은 추정치를 얻을 수 있다.)
정리하자면
MC 기법은 주어진 문제가 정확하게 Markovian이 아니어도 정확한 추산치를 계산할 수 있다. 하지만 효율이 떨어진다.
TD기법은 주어진 문제가 Markovian이 아니면 정확한 추산치를 계산 할 수 없다. 하지만 빠르게 그리고 괜찮은 추산치를 얻을 수 있다.
Graph Visualization
마지막으로 Dynmaic Programming과 MC 그리고 TD가 가치를 추정하는 방식을 시각호하여 직관적으로 받아들여보자.
-
Dynamic Programming
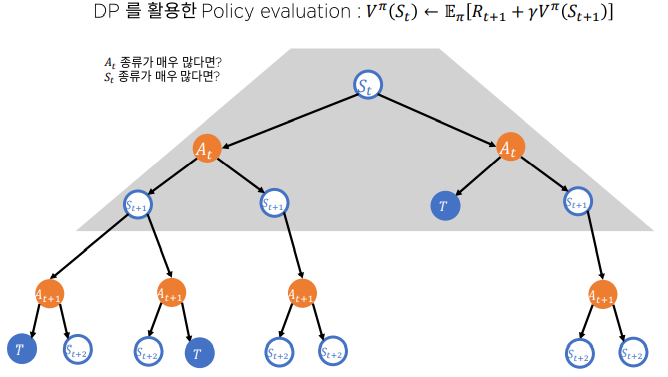
-
Monte Carlo
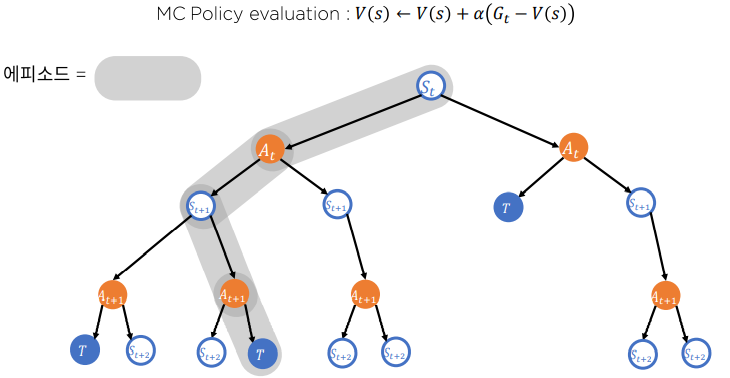
-
Temporal Difference
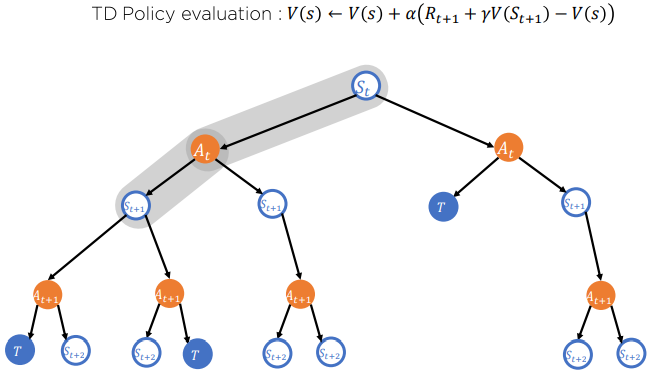
우리는 지금까지 가치를 추정하는 방법에 대하여 알아보았다. MDP 환경을 알고 있는 상황에서는 Dynamic Programming을 통해 가치를 추정할 수 있지만 환경에 대하여 모를 때 즉 Model-Free상황에서는 Monte-Carlo 방식과 TD 방식이 사용된다.
Monte Carlo
Temporal Differnce
