강화학습 시리즈는 패스트캠퍼스 박준영 강사의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.
Intro - 정책 반복 알고리즘의 단점
우리는 지난 시간에 정책 반복 알고리즘을 통해 최적 정책과 최적 가치 함수를 찾을 수 있음을 배웠다.
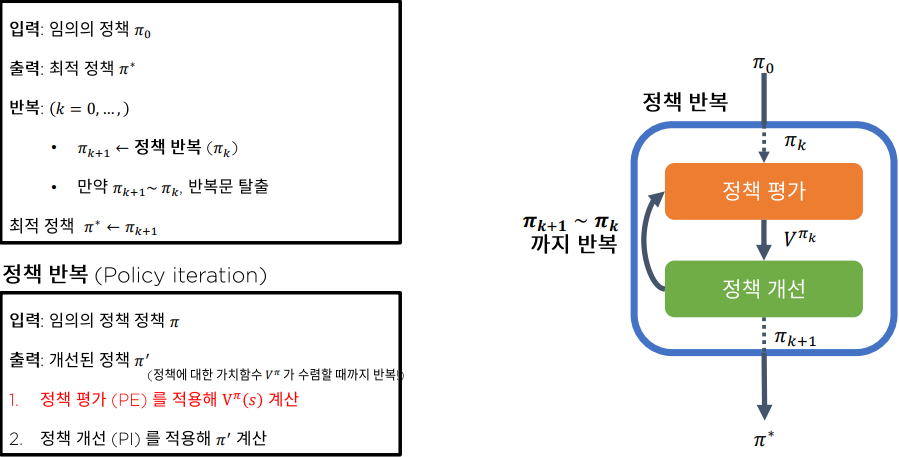
하지만 정책 반복 알고리즘은 2개의 Loop를 거쳐야 하기 때문에 계산상 비효율을 야기한다. (정책 평가 정책 개선 알고리즘 모두 상태 s에 대한 Loop를 가지고 있기 때문에 2개의 Loop문을 통과해야 한다.)
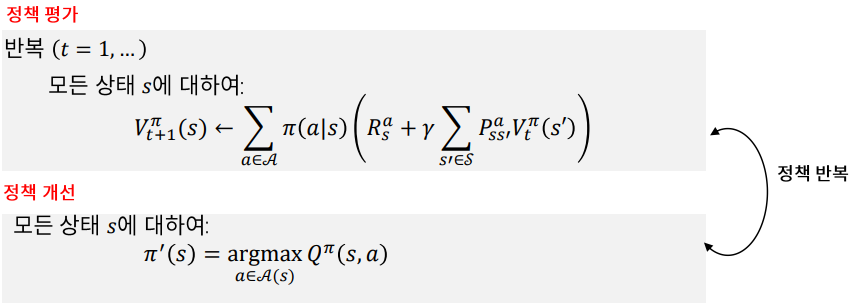
이런 문제를 해결하기 위해 두 가지 방식이 있는데 하나는 Value Iteration을 이용하는 방식이고 하나는 비동기적 동적 계획법을 사용하는 것이다.
Value Iteration
Value Iteration 알고리즘은 정책 평가와 정책 개선을 묶어 Loop를 1개만 돌면 되기 때문에 효율적이다.
Value Iteration 의 식은 -축양 사상을 만족하므로 V는 반드시 수렴하고 그 수렴값은 최적 가치 이다.

비동기적 DP 알고리즘
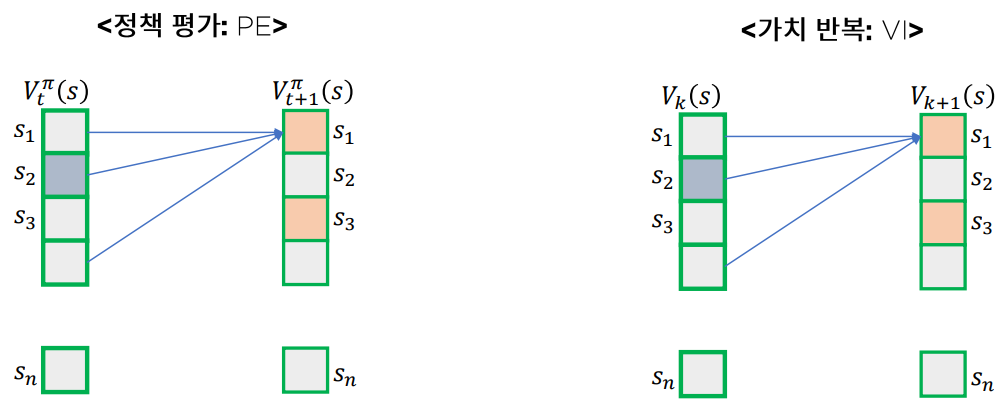
환경을 안다고 가정했을 때 동적 계획법을 이용하여 MDP를 풀 수 있다. 하지만 보는것과 같이 알고리즘을 실행하기 위해서는 State Space의 2배에 해당하는 메모리가 필요한데 State Space의 크기가 커질수록 비효율적이게 된다. 비동기적 DP 알고리즘은 이 문제를 해결할 수 있다.
In-place DP
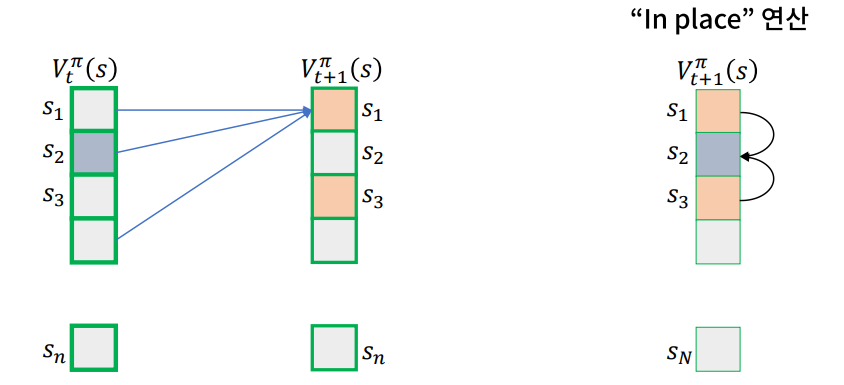
루프로 모든 s에 대해서 구하는 것이 아니라 현재 알고 있는 가장 새로운 값을 활용해 V를 갱신한다.
- 메모리 사용량이 절감된다.
- 일반적으로 수렴속도가 더 빠르다고 밝혀졌다.
Prioritized sweeping
Bellman Error (TD-Error)의 크기가 가장 큰 s 부터 업데이트 한다.
- Prioritized Memory Replay 방식이 이 방법을 사용하였다.
https://velog.io/@everyman123/PRIORITIZED-EXPERIENCE-REPLAY-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
Real-Time DP
강화학습의 에이전트가 현재 겪은 상황만 우선 업데이트 한다.
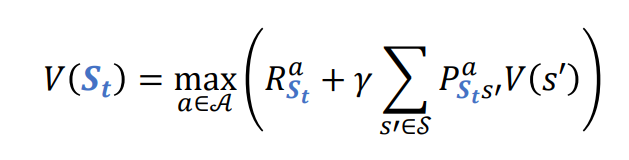
Conclusion
이 방식을 직접 사용하지는 않지만 많은 심층 강화학습 알고리즘은 위 방법들을 사용하였고 위 알고리즘들은 수렴하는 것이 밝혀졌다.
