강화학습
1.1. MDP - Bellman Equation
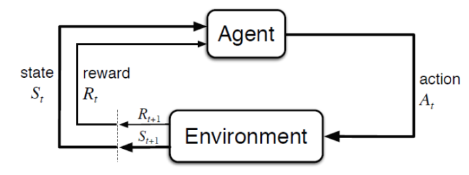
mdp에 대해서 살펴볼 예정.
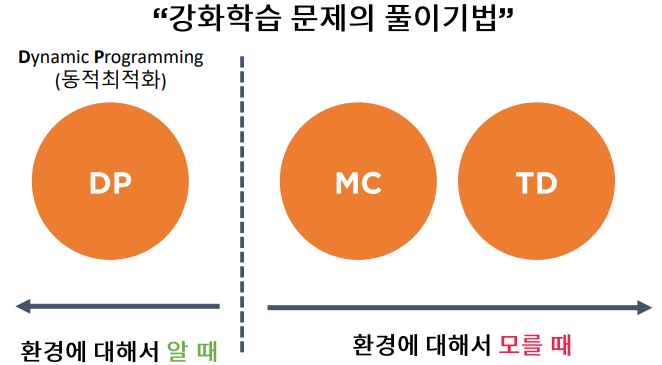
2.2-1 강화학습의 근간 동적 계획법
강화학습 시리즈는 패스트캠퍼스 박준영 강사의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.우리는 이전 시간에 MDP를 정의했고 최적 정책과 최적
3.2-2 비동기적 Dynamic Programming
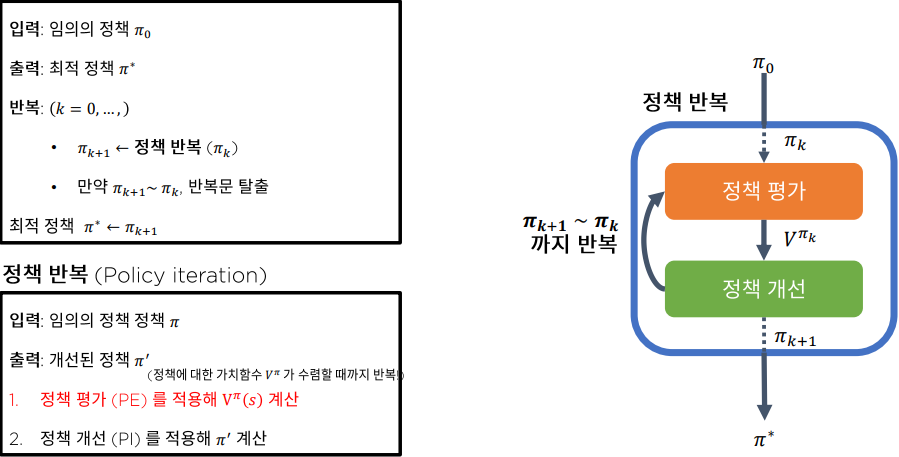
강화학습 시리즈는 패스트캠퍼스 박준영 강사의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.우리는 지난 시간에 정책 반복 알고리즘을 통해 최적 정
4.Model-free RL의 기초 -1 불확실한 세계에서 가치 추산하기
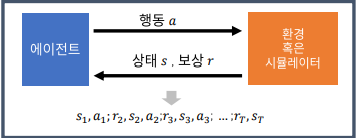
강화학습 시리즈는 패스트캠퍼스 박준영 강사의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.우리는 지난 시간에 환경과 보상 함수에 대해 알고 있다
5.Model-free RL의 기초 -2 모델 없이 정책 개선하기
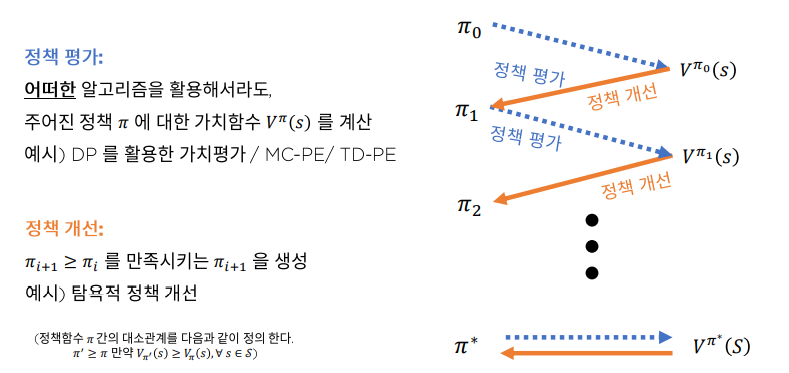
강화학습 시리즈는 패스트캠퍼스 박준영 강사님의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.우리는 이전 시간에 상태 천이 확률 함수 없이도 가치
6.Off-Policy Monte Carlo
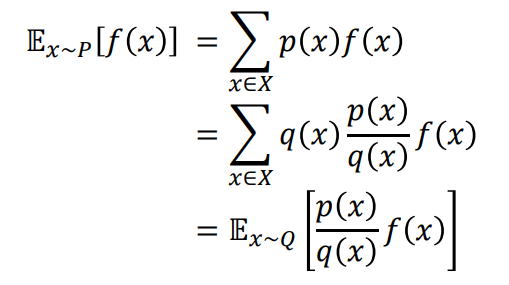
강화학습 시리즈는 패스트캠퍼스 박준영 강사님의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.Monte Carlo와 TD 방식으로 가치함수를 추정
7.Off-Policy TD Q-Learning
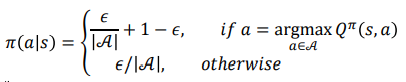
강화학습 시리즈는 패스트캠퍼스 박준영 강사님의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.$V(s)=\\sum\\limits{a \\in A(
8.DDPG - 구글은 신이고 딥마인드는 무적이다.

논문 출처: https://arxiv.org/pdf/1509.02971.pdf Background 보통 강화학습의 알고리즘을 테스트하기 위해 많이 사용하는 환경 툴이 Gym의 Cartpole-v1이다. Cartpole에서 Agent는 떨어지지 않기 위해 왼쪽 혹은