
📌 BMI_500 이란?
BMI는 '나의 체질량 지수'를 숫자로 나타내는 것이며,
체질량지수는 자신의 몸무게(kg)를 키의 제곱(m)으로 나눈 값이다.
체질량지수는 근육량, 유전적 원인, 다른 개인적 차이를 반영하지 못하는 단점이 있음에도 불구하고
조사자들이나 의료인들이 가장 많이 쓰는 방법 중 하나이다.
📖 Tool / Satting
- Python
- Jupyter
- file (csv)
📖 File
https://drive.google.com/drive/folders/1jpuddMnA__gGkkccGeCfakk5_So-r1dG 에 가서 아래 파일을 다운받아서 같은 폴더 내로 파일 옮기기!
bmi_500.csv
📌 파일 불러오기
📖 파일 생성
import pandas as pd
import matplotlib.pyplot as plt📁 파일 읽어오기
tbl = pd.read_csv('bmi_500.csv', index_col='Label')
tbl.head()💻 출력

📖 데이터 정보확인
전체 row(데이터)수, 결측치 여부, 컬럼별 정보
tbl.info()💻 출력

기술통계 확인
tbl.describe()💻 출력

정답 데이터 저장
tbl.index.unique()📌 각 비만도 등급별로 시각화
📖 데이터 불러오기
'Normal'등급 데이터 가져오고,
tbl['컬럼명']
인덱서 - loc, iloc
tbl[행, 열]
tbl.인덱서[행] > 행 데이터만 추출 가능
tbl.loc['Normal']💻 출력
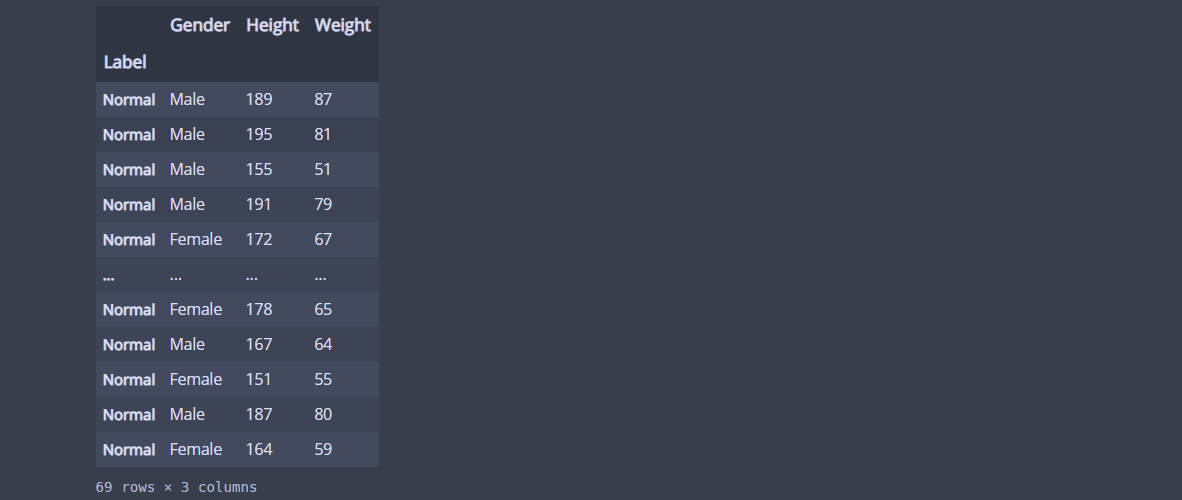
Normal'에서 Height 데이터 가져오기
tbl.loc['Normal']['Height']'Obesity'에서 'Weight'데이터 가져오기
tbl.loc['Obesity']['Weight']💻 출력

📌 함수 만들기
📖 함수 생성
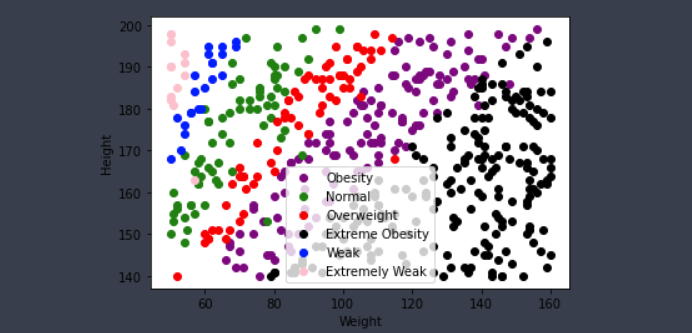
def myScatter(label, color):
tmp = tbl.loc[label]
plt.scatter(tmp['Weight'],
tmp['Height'],
c = color,
label = label)📊 그래프 확인
myScatter('Obesity', 'purple')
myScatter('Normal', 'green')
myScatter('Overweight', 'red')
myScatter('Extreme Obesity', 'black')
myScatter('Weak', 'blue')
myScatter('Extremely Weak', 'pink')
plt.legend()
plt.xlabel('Weight')
plt.ylabel('Height')
plt.show()💻 출력
📊 그래프 정보 추가
tbl.loc['Obesity']['Weight']
tbl.loc['Obesity']['Height']📌 모델링
📖 문제와 정답으로 분리
인덱스를 컬럼으로 리셋
tbl.reset_index(inplace=True)확인
tbl[['Height','Weight']]
📖 train(훈련셋)과 test(평가셋)분리 (7:3)
350, 150
X_train = X.iloc[:350, :]
X_test = X.iloc[350:, :]
y_train = y.iloc[:350]
y_test = y.iloc[350:]print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)💻 출력

📖 모델생성
✍ 입력
from sklearn.neighbors import KNeighborsClassifierKNN 모델 생성
knn_model = KNeighborsClassifier(n_neighbors=10)모델 학습(훈련)
knn_model.fit(X_train, y_train)💻 출력

✍ 예측입력
pre = knn_model.predict(X_test)평가
from sklearn import metrics #평가를 위한 모듈💻 출력


숨쉬는 돌멩이, 말하는 감자.